AQS源码深入分析之独占模式-ReentrantLock锁特性详解
本文基于JDK-8u261源码分析
相信大部分人知道AQS是因为ReentrantLock,ReentrantLock的底层是使用AQS来实现的。还有一部分人知道共享锁(Semaphore/CountDownLatch/CyclicBarrier)也是由AQS来实现的。也就是说AQS中有独占和共享两种模式。但你以为这就是AQS的全部了吗?其实不然。AQS中还有第三种模式:条件队列。像Java中的阻塞队列(ArrayBlockingQueue、LinkedBlockingQueue等)就是由AQS中的条件队列来实现的。而上面所说的独占模式和共享模式是由AQS中的CLH队列来实现的。
所以本系列的AQS源码分析将会分为三篇文章来推送(独占模式/共享模式/条件队列),并且会深入到每一行源码进行分析,希望能给你带来一个全面的AQS认识。那么首先本篇文章就来分析一下AQS中独占模式的实现吧。
1 简介
AQS全称AbstractQueuedSynchronizer,是一个能多线程访问共享资源的同步器框架。作为Doug Lea大神设计出来的又一款优秀的并发框架,AQS的出现使得Java中终于可以有一个通用的并发处理机制。并且可以通过继承它,实现其中的方法,以此来实现想要的独占模式或共享模式,抑或是阻塞队列也可以通过AQS来很简单地实现出来。
一些常用的并发工具类底层都是通过继承AQS来实现的,比如:ReentrantLock、Semaphore、CountDownLatch、ArrayBlockingQueue等(这些工具类也都是Doug Lea写的)。
Doug Lea是我们学习Java并发框架绕不开的神级人物,以下是他个人的履历
纽约州立大学奥斯威戈分校的计算机科学教授,现任计算机科学系主任,他专门研究并发编程和并发数据结构的设计。他是Java Community Process执行委员会的成员,JSR 166的主席, 美国计算机协会会士,欧洲计算机领域重量级奖项达尔-尼加德奖得主
信息来自wiki百科:https://en.wikipedia.org/wiki/Doug_Lea
扯回正题,AQS中有几个重要的概念:
state:用来记录可重入锁的上锁次数;
exclusiveOwnerThread:AQS继承了AbstractOwnableSynchronizer,而其中有个属性exclusiveOwnerThread,用来记录当前独占锁的线程是谁;
CLH同步队列:FIFO双向链表队列,此CLH队列是原CLH的变种,由原来的不断自旋改为了阻塞机制。队列中有头节点和尾节点两个指针,尾节点就是指向最后一个节点,而头节点为了便于判断,永远指向一个空节点,之后才是第一个有数据的节点;
条件队列:能够使某些线程一起等待某个条件具备时,才会被唤醒,唤醒后会被放到CLH队列中重新争夺锁资源。
AQS定义资源的访问方式有两种:
独占模式:只有一个线程能够获取锁,如ReentrantLock;
共享模式:多个线程可以同时获取到锁,如Semaphore、CountDownLatch和CyclicBarrier。
AQS中使用到了模板方法模式,提供了一些方法供子类来实现,子类只需要实现这些方法即可,至于具体的队列的维护就不需要关心了,AQS已经实现好了。
1.1 Node
上面所说的CLH队列和条件队列的节点都是AQS的一个内部类Node构造的,其中定义了一些节点的属性:
1 static final class Node {
2 /**
3 * 标记节点为共享模式
4 */
5 static final Node SHARED = new Node();
6 /**
7 * 标记节点为独占模式
8 */
9 static final Node EXCLUSIVE = null;
10 /**
11 * 标记节点是取消状态,CLH队列中等待超时或者被中断的线程,需要从CLH队列中去掉
12 */
13 static final int CANCELLED = 1;
14 /**
15 * 该状态比较特殊,如果该节点的下一个节点是阻塞状态,则该节点处于SIGNAL状态
16 * 所以该状态表示的是下一个节点是否是阻塞状态,而不是表示的本节点的状态
17 */
18 static final int SIGNAL = -1;
19 /**
20 * 该状态的节点会被放在条件队列中
21 */
22 static final int CONDITION = -2;
23 /**
24 * 用在共享模式中,表示节点是可以唤醒传播的。CLH队列此时不需要等待前一个节点释放锁之后,该节点再获取锁
25 * 共享模式下所有处于该状态的节点都可以获取到锁,而这个传播唤醒的动作就是通过标记为PROPAGATE状态来实现
26 */
27 static final int PROPAGATE = -3;
28 /**
29 * 记录当前节点的状态,除了上述四种状态外,还有一个初始状态0
30 */
31 volatile int waitStatus;
32 /**
33 * CLH队列中用来表示前一个节点
34 */
35 volatile Node prev;
36 /**
37 * CLH队列中用来表示后一个节点
38 */
39 volatile Node next;
40 /**
41 * 用来记录当前被阻塞的线程
42 */
43 volatile Thread thread;
44 /**
45 * 条件队列中用来表示下一个节点
46 */
47 Node nextWaiter;
48
49 //...
50 }
1.2 CLH队列
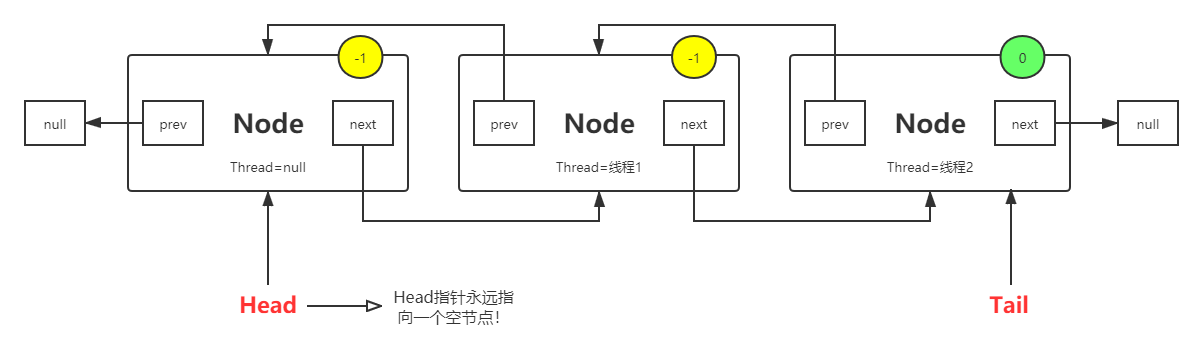
这里需要注意的一点是,CLH队列中的head指针永远会指向一个空节点。如果当前节点被剔除掉,而后面的节点变成第一个节点的时候,此时就会清空该节点里面的内容(waitStatus不会被清除),将head指针指向它。这样做的目的是为了方便进行判断。
2 ReentrantLock概览
独占模式就是只有一个线程能获取到锁资源,独占模式用ReentrantLock来举例,ReentrantLock内部使用sync来继承AQS,有公平锁和非公平锁两种:
1 public class ReentrantLock implements Lock, Serializable {
2
3 //...
4
5 /**
6 * 内部调用AQS
7 */
8 private final Sync sync;
9
10 /**
11 * 继承AQS的同步基础类
12 */
13 abstract static class Sync extends AbstractQueuedSynchronizer {
14 //...
15 }
16
17 /**
18 * 非公平锁
19 */
20 static final class NonfairSync extends Sync {
21 //...
22 }
23
24 /**
25 * 公平锁
26 */
27 static final class FairSync extends Sync {
28 //...
29 }
30
31 /**
32 * 默认创建非公平锁对象
33 */
34 public ReentrantLock() {
35 sync = new NonfairSync();
36 }
37
38 /**
39 * 创建公平锁或者非公平锁
40 */
41 public ReentrantLock(boolean fair) {
42 sync = fair ? new FairSync() : new NonfairSync();
43 }
44
45 //...
46 }
公平与非公平锁区别
AQS设计了队列给所有未获取到锁的线程进行排队,那为什么选择队列而不使用Set或者List结构呢?因为队列具有FIFO先入先出特性,即天然具备公平特性,因此在ReentrantLock里才有公平与非公平这两种特性存在。
3 非公平锁
3.1 lock方法
ReentrantLock的非公平锁方式下的lock方法:
1 /**
2 * ReentrantLock:
3 */
4 public void lock() {
5 sync.lock();
6 }
7
8 final void lock() {
9 /*
10 首先直接尝试CAS方式加锁,如果成功了,就将exclusiveOwnerThread设置为当前线程
11 这也就是非公平锁的含义,每一个线程在进行加锁的时候,会首先尝试加锁,如果成功了,
12 就不用放在CLH队列中进行排队阻塞了
13 */
14 if (compareAndSetState(0, 1))
15 setExclusiveOwnerThread(Thread.currentThread());
16 else
17 //否则失败的话就进CLH队列中进行阻塞
18 acquire(1);
19 }
3.2 acquire方法
在上面的lock方法中,如果加锁失败了,就会进入到acquire方法中进行排队。但首先还是会尝试获取一次资源:
1 /**
2 * AbstractQueuedSynchronizer:
3 */
4 public final void acquire(int arg) {
5 //首先尝试获取资源,如果失败了的话就添加一个新的独占节点,插入到CLH队列尾部
6 if (!tryAcquire(arg) &&
7 acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
8 /*
9 因为本方法不是响应中断的,所以如果当前线程中断后被唤醒,就在此处继续将中断标志位重新置为true
10 (selfInterrupt方法内部就一句话:“Thread.currentThread().interrupt();”),而不是会抛异常
11 (需要使用者在调用lock方法后首先通过isInterrupted方法去进行判断,是否应该执行接下来的业务代码)
12 */
13 selfInterrupt();
14 }
15
16 /**
17 * ReentrantLock:
18 * 第6行代码处:
19 * 尝试获取资源
20 */
21 protected final boolean tryAcquire(int acquires) {
22 return nonfairTryAcquire(acquires);
23 }
24
25 final boolean nonfairTryAcquire(int acquires) {
26 //acquires = 1
27 final Thread current = Thread.currentThread();
28 int c = getState();
29 //如果当前没有加锁的话
30 if (c == 0) {
31 //尝试CAS方式去修改state为1
32 if (compareAndSetState(0, acquires)) {
33 //设置当前独占锁拥有者为当前线程
34 setExclusiveOwnerThread(current);
35 return true;
36 }
37 }
38 //当前state不为0,则判断当前线程是否是之前加上锁的线程
39 else if (current == getExclusiveOwnerThread()) {
40 //如果是的话,说明此时是可重入锁,将state+1
41 int nextc = c + acquires;
42 //如果+1之后为负数,说明此时数据溢出了,抛出Error
43 if (nextc < 0)
44 throw new Error("Maximum lock count exceeded");
45 setState(nextc);
46 return true;
47 }
48 return false;
49 }
3.3 addWaiter方法
如果tryAcquire方法还是获取不到资源,就会调用addWaiter方法来在CLH队列中新增一个节点:
1 /**
2 * AbstractQueuedSynchronizer:
3 * 在CLH队列中添加一个新的独占尾节点
4 */
5 private Node addWaiter(Node mode) {
6 //把当前线程构建为一个新的节点
7 Node node = new Node(Thread.currentThread(), mode);
8 Node pred = tail;
9 //判断当前尾节点是否为null?不为null说明此时队列中有节点
10 if (pred != null) {
11 //把当前节点用尾插的方式来插入
12 node.prev = pred;
13 //CAS的方式将尾节点指向当前节点
14 if (compareAndSetTail(pred, node)) {
15 pred.next = node;
16 return node;
17 }
18 }
19 //如果队列为空,将队列初始化后插入当前节点
20 enq(node);
21 return node;
22 }
23
24 private Node enq(final Node node) {
25 /*
26 高并发情景下会有很多的CAS失败操作,而下面的死循环确保节点一定要插进队列中。上面的代码和
27 enq方法中的代码是类似的,也就是说上面操作是为了做快速修改,如果失败了,在enq方法中做兜底
28 */
29 for (; ;) {
30 Node t = tail;
31 //如果尾节点为null,说明此时CLH队列为空,需要初始化队列
32 if (t == null) {
33 //创建一个空的Node节点,并将头节点CAS指向它
34 if (compareAndSetHead(new Node()))
35 //同时将尾节点也指向这个新的节点
36 tail = head;
37 } else {
38 //如果CLH队列此时不为空,则像之前一样用尾插的方式插入该节点
39 node.prev = t;
40 if (compareAndSetTail(t, node)) {
41 t.next = node;
42 return t;
43 }
44 }
45 }
46 }
3.4 acquireQueued方法
本方法是AQS中的核心方法,需要特别注意:
1 /**
2 * AbstractQueuedSynchronizer:
3 * 注意:本方法是整个AQS的精髓所在,完成了头节点尝试获取锁资源和其他节点被阻塞的全部过程
4 */
5 final boolean acquireQueued(final Node node, int arg) {
6 boolean failed = true;
7 try {
8 boolean interrupted = false;
9 for (; ; ) {
10 //获取当前节点的前一个节点
11 final Node p = node.predecessor();
12 /*
13 如果前一个节点是头节点,才可以尝试获取资源,也就是实际上的CLH队列中的第一个节点
14 队列中只有第一个节点才有资格去尝试获取锁资源(FIFO),如果获取到了就不用被阻塞了
15 获取到了说明在此刻,之前的资源已经被释放了
16 */
17 if (p == head && tryAcquire(arg)) {
18 /*
19 头指针指向当前节点,意味着该节点将变成一个空节点(头节点永远会指向一个空节点)
20 因为在上一行的tryAcquire方法已经成功的情况下,就可以释放CLH队列中的该节点了
21 */
22 setHead(node);
23 //断开前一个节点的next指针,这样它就成为了一个孤立节点,等待被GC
24 p.next = null;
25 failed = false;
26 return interrupted;
27 }
28 /*
29 走到这里说明要么前一个节点不是head节点,要么是head节点但是尝试加锁失败。此时将队列中当前
30 节点之前的一些CANCELLED状态的节点剔除;前一个节点状态如果为SIGNAL时,就会阻塞当前线程
31 这里的parkAndCheckInterrupt阻塞操作是很有意义的。因为如果不阻塞的话,那么获取不到资源的
32 线程可能会在这个死循环里面一直运行,会一直占用CPU资源
33 */
34 if (shouldParkAfterFailedAcquire(p, node) &&
35 parkAndCheckInterrupt())
36 //只是记录一个标志位而已,不会抛出InterruptedException异常。也就是说不会响应中断
37 interrupted = true;
38 }
39 } finally {
40 if (failed)
41 //如果tryAcquire方法中state+1溢出了,就会取消当前线程获取锁资源的请求
42 cancelAcquire(node);
43 }
44 }
45
46 /**
47 * 第22行代码处:
48 * 将node节点置为新的head节点,同时将其中的thread和prev属性置空
49 * (注意:这里并不会清空waitStatus值)
50 */
51 private void setHead(Node node) {
52 head = node;
53 node.thread = null;
54 node.prev = null;
55 }
56
57 /**
58 * 第34行代码处:
59 */
60 private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
61 int ws = pred.waitStatus;
62 if (ws == Node.SIGNAL)
63 //如果前一个节点的状态是SIGNAL,意味着当前节点可以被安全地阻塞
64 return true;
65 if (ws > 0) {
66 /*
67 从该节点往前寻找一个不是CANCELLED状态的节点(也就是处于正常阻塞状态的节点),
68 遍历过程中如果遇到了CANCELLED节点,会被剔除出CLH队列等待GC
69 */
70 do {
71 node.prev = pred = pred.prev;
72 } while (pred.waitStatus > 0);
73 pred.next = node;
74 } else {
75 /*
76 如果前一个节点的状态是初始状态0或者是传播状态PROPAGATE时,CAS去修改其状态为SIGNAL,
77 因为当前节点最后是要被阻塞的,所以前一个节点的状态必须改为SIGNAL
78 走到这里最后会返回false,因为外面还有一个死循环,如果最后还能跳到这个方法里面的话,
79 如果之前CAS修改成功的话就会直接走进第一个if条件里面,返回true。然后当前线程被阻塞
80 CAS失败的话会再次进入到该分支中做修改
81 */
82 compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
83 }
84 return false;
85 }
86
87 /**
88 * 第35行代码处:
89 * 阻塞当前节点,后续该节点如果被unpark唤醒的时候,会从第97行代码处唤醒往下执行,返回false
90 * 可能线程在等待的时候会被中断唤醒,本方法就返回了true。这个时候该线程就会处于一种不正确的状态
91 * 返回回去后会在第37行代码处设置中断位为true,并最终返回回去。注意到下面的第110行代码处使用的是
92 * Thread.interrupted方法,也就是在返回true之后会清空中断状态,所以需要在上面的acquire方法
93 * 中、调用selfInterrupt方法里面的interrupt方法来将中断标志位重新置为true
94 */
95 private final boolean parkAndCheckInterrupt() {
96 //当前线程会被阻塞到这行代码处,停止往下运行,等待unpark唤醒
97 LockSupport.park(this);
98 /*
99 通过上面的解释,可能会觉得下面的Thread.interrupted方法有点多余,需要清除中断标志位,最后
100 还会将中断标志位重新置为true。那么此时为什么不直接调用isInterrupted方法呢?不用清除中断标
101 志位就行了啊?其实这里使用Thread.interrupted方法是有原因的:LockSupport.park的实现会调用
102 native方法,通过查看底层的HotSpot源码中的park方法可知:如果在调用park方法时发现当前中断标
103 志位已经为true了,此时就会直接return退出本方法了(同时不会清除中断标志位),也就不会再进
104 行后续的挂起线程的操作了。也就是说,如果是中断唤醒,假如没有这里的Thread.interrupted方法
105 来清除中断标志位,那么可能下一次加锁失败还是会走进当前park方法,而此时的中断标志位仍然为
106 true。但是如上面所说,进入park方法中并不会被阻塞,也就是此时的park方法会失效,会不断在
107 acquireQueued方法中自旋,造成CPU飙高的现象出现。所以这里的Thread.interrupted方法清除中断
108 标志位是为了让后续调用的park方法能继续被成功阻塞住
109 */
110 return Thread.interrupted();
111 }
3.5 cancelAcquire方法
当出现异常的时候,就会调用cancelAcquire方法来处理异常,同时还有一些其他的收尾工作。其中很重要的一点是:如果是需要唤醒的节点发生了异常,那么此时需要唤醒下一个节点,以此来保证唤醒动作能够一直传播下去。
1 /**
2 * AbstractQueuedSynchronizer:
3 * 取消当前线程获取锁资源的请求,并完成一些其他的收尾工作
4 */
5 private void cancelAcquire(Node node) {
6 //非空校验
7 if (node == null)
8 return;
9
10 //节点里面的线程清空
11 node.thread = null;
12
13 /*
14 从该节点往前寻找一个不是CANCELLED状态的节点(也就是处于正常阻塞状态的节点),
15 相当于在退出前再做次清理工作。遍历过程中如果遇到了CANCELLED节点,会被剔除出
16 CLH队列等待GC
17 这里的实现逻辑是和shouldParkAfterFailedAcquire方法中是类似的,但是有一点
18 不同的是:这里并没有pred.next = node,而是延迟到了后面的CAS操作中
19 */
20 Node pred = node.prev;
21 while (pred.waitStatus > 0)
22 node.prev = pred = pred.prev;
23
24 /*
25 如果上面遍历时有CANCELLED节点,predNext就指向pred节点的下一个CANCELLED节点
26 如果上面遍历时没有CANCELLED节点,predNext就指向自己
27 */
28 Node predNext = pred.next;
29
30 /*
31 将状态改为CANCELLED,也就是在取消获取锁资源。这里不用CAS来改状态是可以的,
32 因为改的是CANCELLED状态,其他节点遇到CANCELLED节点是会跳过的
33 */
34 node.waitStatus = Node.CANCELLED;
35
36 if (node == tail && compareAndSetTail(node, pred)) {
37 //如果当前节点是最后一个节点的时候,就剔除当前节点,将tail指针指向前一个节点
38 compareAndSetNext(pred, predNext, null);
39 } else {
40 int ws;
41 //走到这里说明当前节点不是最后一个节点
42 if (pred != head &&
43 ((ws = pred.waitStatus) == Node.SIGNAL ||
44 (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
45 pred.thread != null) {
46 /*
47 如果head指针指向的不是pred节点,并且前一个节点是SIGNAL状态(或者可以设置为SIGNAL状态),
48 并且前一个节点的thread没被清空的话,那么只需要将pred节点和当前节点的后面一个节点连接起来就行了
49 */
50 Node next = node.next;
51 if (next != null && next.waitStatus <= 0)
52 /*
53 这里只是设置了pred节点的next指针,而没有设置next.prev = pred。但无妨,在后续的操作中,
54 如果能走到shouldParkAfterFailedAcquire方法中,会再去修正prev指针的
55 */
56 compareAndSetNext(pred, predNext, next);
57 } else {
58 /*
59 而如果head指针指向的是pred节点(或者pred节点的thread是为null的),那么就去唤醒当前节点的
60 下一个可以被唤醒的节点,以保证即使是在发生异常的时候,CLH队列中的节点也可以一直被唤醒下去
61 当然,如果前一个节点本身就是SIGNAL状态,也是需要唤醒下一个节点的
62 */
63 unparkSuccessor(node);
64 }
65
66 /*
67 node.next指向自己,断开该节点,同时要保证next指针一定要有值,
68 因为后续在条件队列的isOnSyncQueue方法中会判断节点是否在CLH队列中
69 其中有一条就是以判断node.next是否为null为准则,如果不为null,就说明
70 该节点还在CLH队列中
71 */
72 node.next = node;
73 }
74 }
3.6 unparkSuccessor方法
不光上面的cancelAcquire方法会调用到本方法,unlock方法中也会调用本方法来唤醒下一个节点:
1 /**
2 * AbstractQueuedSynchronizer:
3 * 唤醒下一个可以被唤醒的节点
4 */
5 private void unparkSuccessor(Node node) {
6 int ws = node.waitStatus;
7 /*
8 如果当前节点状态是SIGNAL或者PROPAGATE,将其CAS设置为初始状态0
9 因为后续会唤醒第一个被阻塞的节点,所以这里节点的状态如果还是SIGNAL就不正确了,
10 因为SIGNAL表示的是下一个节点是阻塞状态
11 */
12 if (ws < 0)
13 compareAndSetWaitStatus(node, ws, 0);
14
15 //s是当前节点的下一个节点
16 Node s = node.next;
17 //如果下一个节点为null,或者状态为CANCELLED
18 if (s == null || s.waitStatus > 0) {
19 s = null;
20 //从CLH队列的尾节点向前遍历到该节点为止,找到该节点往后第一个处于正常阻塞状态的节点
21 for (Node t = tail; t != null && t != node; t = t.prev)
22 if (t.waitStatus <= 0)
23 s = t;
24 }
25 //如果找到了或者遍历之前的下一个节点本身就处于正常阻塞状态的话,就唤醒它
26 if (s != null)
27 LockSupport.unpark(s.thread);
28 }
3.7 unlock方法
ReentrantLock的unlock方法:
1 /**
2 * ReentrantLock:
3 */
4 public void unlock() {
5 sync.release(1);
6 }
7
8 /**
9 * AbstractQueuedSynchronizer:
10 */
11 public final boolean release(int arg) {
12 //释放一次锁,如果没有可重入锁的话,就进入到下面的if条件中
13 if (tryRelease(arg)) {
14 Node h = head;
15 /*
16 如果头节点存在且下一个节点处于阻塞状态的时候就唤醒下一个节点
17 因为在之前加锁方法中的shouldParkAfterFailedAcquire方法中,会将前一个节点的状态置为SIGNAL
18 所以这里判断waitStatus不为0就意味着下一个节点是阻塞状态,然后就可以唤醒了
19 如果为0就没有必要唤醒,因为下一个节点本身就是处于非阻塞状态
20 */
21 if (h != null && h.waitStatus != 0)
22 unparkSuccessor(h);
23 return true;
24 }
25 return false;
26}
27
28 /**
29 * ReentrantLock:
30 * 第13行代码处:
31 */
32 protected final boolean tryRelease(int releases) {
33 //c = state - 1
34 int c = getState() - releases;
35 //如果当前线程不是上锁时的线程,则抛出异常
36 if (Thread.currentThread() != getExclusiveOwnerThread())
37 throw new IllegalMonitorStateException();
38 boolean free = false;
39 //如果减完1后的state是0的话,也就是没有可重入锁发生的情况,则可以将独占锁拥有者设置为null
40 if (c == 0) {
41 free = true;
42 setExclusiveOwnerThread(null);
43 }
44 //设置state为减完1后的结果
45 setState(c);
46 return free;
47 }
4 公平锁
ReentrantLock的公平锁和非公平锁实现上的区别寥寥无几,只有lock方法和tryAcquire方法是不同的(包括unlock解锁方法的实现都是一样的),也就是FairSync类中覆写的两个方法。所以下面就来看一下这两个方法的实现。
4.1 lock方法
1 /**
2 * ReentrantLock:
3 */
4 final void lock() {
5 /*
6 可以看到在公平锁模式下,只是调用了acquire方法而已。而在非公平锁模式下,会首先执行
7 compareAndSetState,如果CAS失败才调用acquire方法。这个意思也就是说:非公平锁
8 模式下的每个线程在加锁时会首先尝试加一下锁,去赌一下此时是否释放锁了。如果释放了,
9 那么此时的这个线程就能抢到锁,相当于插队了(这也就是“非公平”的含义)。如果没抢到就
10 继续去CLH队列中排队。而公平锁模式下的每个线程加锁时都只是会去乖乖排队而已
11 */
12 acquire(1);
13 }
4.2 tryAcquire方法
1 /**
2 * ReentrantLock:
3 * 可以看到公平锁模式下的tryAcquire方法和非公平锁模式下的nonfairTryAcquire方法的区别
4 * 仅仅是多调用了一次hasQueuedPredecessors方法,其他都是一样的。所以下面就来看一下该
5 * 方法的实现
6 */
7 protected final boolean tryAcquire(int acquires) {
8 final Thread current = Thread.currentThread();
9 int c = getState();
10 if (c == 0) {
11 if (!hasQueuedPredecessors() &&
12 compareAndSetState(0, acquires)) {
13 setExclusiveOwnerThread(current);
14 return true;
15 }
16 } else if (current == getExclusiveOwnerThread()) {
17 int nextc = c + acquires;
18 if (nextc < 0)
19 throw new Error("Maximum lock count exceeded");
20 setState(nextc);
21 return true;
22 }
23 return false;
24 }
4.3 hasQueuedPredecessors方法
在上面tryAcquire方法中的第11行代码处会调用hasQueuedPredecessors方法,所以下面来看一下其实现:
1 /**
2 * ReentrantLock:
3 * 本方法是用来判断CLH队列中是否已经有不是当前线程的其他节点,
4 * 因为CLH队列都是FIFO的,head.next节点一定是等待时间最久的,
5 * 所以只需要跟它比较就行了。这里也就是在找CLH队列中是否有线程
6 * 的等待获取锁的时间比当前线程的还要长。如果有的话当前线程就
7 * 不会继续后面的加锁操作(这里再次体现“公平”的含义),没有
8 * 才会尝试加锁
9 */
10 public final boolean hasQueuedPredecessors() {
11 Node t = tail;
12 Node h = head;
13 Node s;
14 /*
15 <1>首先判断head和tail是否不等,如果相等的话有两种情况:head和tail都为null,或者是head和tail
16 都指向那个空节点(当最后仅剩下两个节点的时候(一个空节点和一个真正等待的节点),此时再唤醒节点
17 的话,CLH队列中此时就会仅剩一个空节点了)。不管属于哪种,都代表着此时的CLH队列中没有在阻塞着的
18 节点了,那么这个时候当前线程就可以尝试加锁了;
19 <2.1>如果此时CLH队列中有节点的话,那么就判断一下head.next是否为空。我能想到的一种极端场景是:
20 假设此时CLH队列中仅有一个空节点(head和tail都指向它),就在此刻一个新的节点需要进入CLH队列里,
21 它走到了addWaiter方法中,在执行完了compareAndSetTail后,但是还没执行下面的“pred.next = node;”
22 之前,那么当前线程获取到的tail和head之间就仅有一个prev指针相连,而next指针此时还没有进行连接
23 那么此时获取到的head.next就是null了,这种情况下当前线程也不会尝试加锁,而是去CLH队列中排队
24 (这种情况下虽然h.next是null,但是是有一个等待时间比当前线程还久的节点的,只不过它的指针还没有
25 来得及连接上而已。所以当前节点会继续去排队,以此体现“公平”的含义);
26 <2.2>如果此时CLH队列中有节点,并且不属于上面第2.1条件中的特殊情况的话,还会去判断head.next
27 是否是当前线程。这个时候出现的场景就是:当前线程会在CLH队列中的head.next处,然后当前线程会再次在
28 本方法中进行判断。那么这是怎么发生的呢?一种可能的情况是:当之前持有锁的线程执行完毕释放了之后,
29 这个时候的队头节点会被唤醒,从而走到acquireQueued方法中的tryAcquire方法处,然后再走到本方法中
30 这个时候的当前线程就是被唤醒的这个线程,所以s.thread != Thread.currentThread()这个条件不成立,
31 此时当前线程就可以尝试加锁了。如果head.next不是当前线程,也就是当前线程不是等待时间最久的那个线程
32 此时就不会去加锁而是去排队去了(再次体现“公平”的含义)
33 */
34 return h != t &&
35 ((s = h.next) == null || s.thread != Thread.currentThread());
36 }
下一篇将继续分析AQS中共享模式的实现,敬请关注。原创文章,未得准许,请勿转载,翻版必究要吐槽Doug Lea的请在下面排好队
更多内容请关注微信公众号:奇客时间
AQS源码深入分析之独占模式-ReentrantLock锁特性详解的更多相关文章
- AQS源码深入分析之共享模式-你知道为什么AQS中要有PROPAGATE这个状态吗?
本文基于JDK-8u261源码分析 本篇文章为AQS系列文的第二篇,前文请看:[传送门] 第一篇:AQS源码深入分析之独占模式-ReentrantLock锁特性详解 1 Semaphore概览 共享模 ...
- Java并发系列[2]----AbstractQueuedSynchronizer源码分析之独占模式
在上一篇<Java并发系列[1]----AbstractQueuedSynchronizer源码分析之概要分析>中我们介绍了AbstractQueuedSynchronizer基本的一些概 ...
- AQS源码深入分析之条件队列-你知道Java中的阻塞队列是如何实现的吗?
本文基于JDK-8u261源码分析 1 简介 因为CLH队列中的线程,什么线程获取到锁,什么线程进入队列排队,什么线程释放锁,这些都是不受我们控制的.所以条件队列的出现为我们提供了主动式地.只有满足指 ...
- jquery源码解析:jQuery静态属性对象support详解
jQuery.support是用功能检测的方法来检测浏览器是否支持某些功能.针对jQuery内部使用. 我们先来看一些源码: jQuery.support = (function( support ) ...
- Apache Spark源码走读之13 -- hiveql on spark实现详解
欢迎转载,转载请注明出处,徽沪一郎 概要 在新近发布的spark 1.0中新加了sql的模块,更为引人注意的是对hive中的hiveql也提供了良好的支持,作为一个源码分析控,了解一下spark是如何 ...
- STL 源码分析《5》---- lower_bound and upper_bound 详解
在 STL 库中,关于二分搜索实现了4个函数. bool binary_search (ForwardIterator beg, ForwardIterator end, const T& v ...
- bootstrap源码之滚动监听组件scrollspy.js详解
其实滚动监听使用的情况还是很多的,比如导航居于右侧,当主题内容滚动某一块的时候,右侧导航对应的要高亮. 实现功能 1.当滚动区域内设置的hashkey距离顶点到有效位置时,就关联设置其导航上的指定项 ...
- Spring源码解析二:IOC容器初始化过程详解
IOC容器初始化分为三个步骤,分别是: 1.Resource定位,即BeanDefinition的资源定位. 2.BeanDefinition的载入 3.向IOC容器注册BeanDefinition ...
- AngularJS源码解析4:Parse解析器的详解
$ParseProvider简介 此服务提供者也是angularjs中用的比较多的,下面我们来详细的说下这个provider. function $ParseProvider() { var cach ...
随机推荐
- php 图片转base4的格式
<?php $url = '1.jpg'; $base64_img = base64_encode(file_get_contents($url));//将图片转base64编码 $imgArr ...
- 优雅的在React组件中注册事件
前言 在React的开发中,我们经常需要在 window 上注册一些事件, 比如按下 Esc 关闭弹窗, 按上下键选中列表内容等等.比较常见的操作是在组件 mount 的时候去 window 上监听一 ...
- 前端er,你真的会用 async 吗?
async 异步函数 不完全使用攻略 前言 现在已经到 8012 年的尾声了,前端各方面的技术发展也层出不穷,VueConf TO 2018 大会 也发布了 Vue 3.0的计划.而在我们(我)的日常 ...
- mysql-18-function
#函数 /* 存储过程:可以有0个或多个返回,适合批量插入.批量更新 函数:有且仅有一个返回,适合处理数据后返回一个结果 */ #一.创建语法 /* create function 函数名(参数列表) ...
- 日志分析平台ELK之日志收集器filebeat
前面我们了解了elk集群中的logstash的用法,使用logstash处理日志挺好的,但是有一个缺陷,就是太慢了:当然logstash慢的原因是它依赖jruby虚拟机,jruby虚拟机就是用java ...
- Linux设置主机名称与host映射
uname -n :查看host对应的域名 2.在 /etc/hostname 删除原来的重新配置需要的域名 3.在 /etc/hosts 中添加域名和映射ip 4.重启系统 5.其他主机 ...
- ElasticSearch 索引 VS MySQL 索引
前言 这段时间在维护产品的搜索功能,每次在管理台看到 elasticsearch 这么高效的查询效率我都很好奇他是如何做到的. 这甚至比在我本地使用 MySQL 通过主键的查询速度还快. 为此我搜索了 ...
- DM8数据库备份还原的原理及应用
(本文部分内容摘自DM产品技术支持培训文档,如需要更详细的文档,请查询官方操作手册,谢谢) 一.原理 1.DM8备份还原简介 1.1.基本概念 (1)表空间与数据文件 ▷ DM8表空间类型: ▷ SY ...
- MySql 关闭 bin 和 log 日志
mysql 的 bin 和 .log 日志文件会非常占用磁盘空间和 IO,修改 mysql 配置文件可以关闭这两种日志的记录. 关闭 bin 日志,将下面三项配置注释掉: #log_bin = mys ...
- Activiti6.0获取下一节点任务的心路历程
在我的开发任务中,我被分配了一个像下一个节点审批人发送短信的任务,这个任务看起来非常的简单,但在开发过程中遇到了许多的坑,在这里进行记录,如果你想要快速知道结果,请看代码版本(3). 首先,就是获取下 ...