初识Elastic search—附《Elasticsearch权威指南—官方guide的译文》
本文作为Elastic search系列的开篇之作,简要介绍其简要历史、安装及基本概念和核心模块。
- 简史
Elastic search基于Lucene(信息检索引擎,ES里一个index—索引,一个索引指向一个或者多个分片—shards,一个分片就是一个Lucene实例)。
ES的诞生于04年,Shay Banon—据传刚失业又新婚,祸不单行(港蓉蒸蛋糕,蒸的吗),在Lucene的基础上为他去伦敦学厨师的老婆做的食谱搜索。一不小心,搞出了ES,然而老婆大人的食谱搜索却遥遥无期,估计Shay在家键盘跪烂。
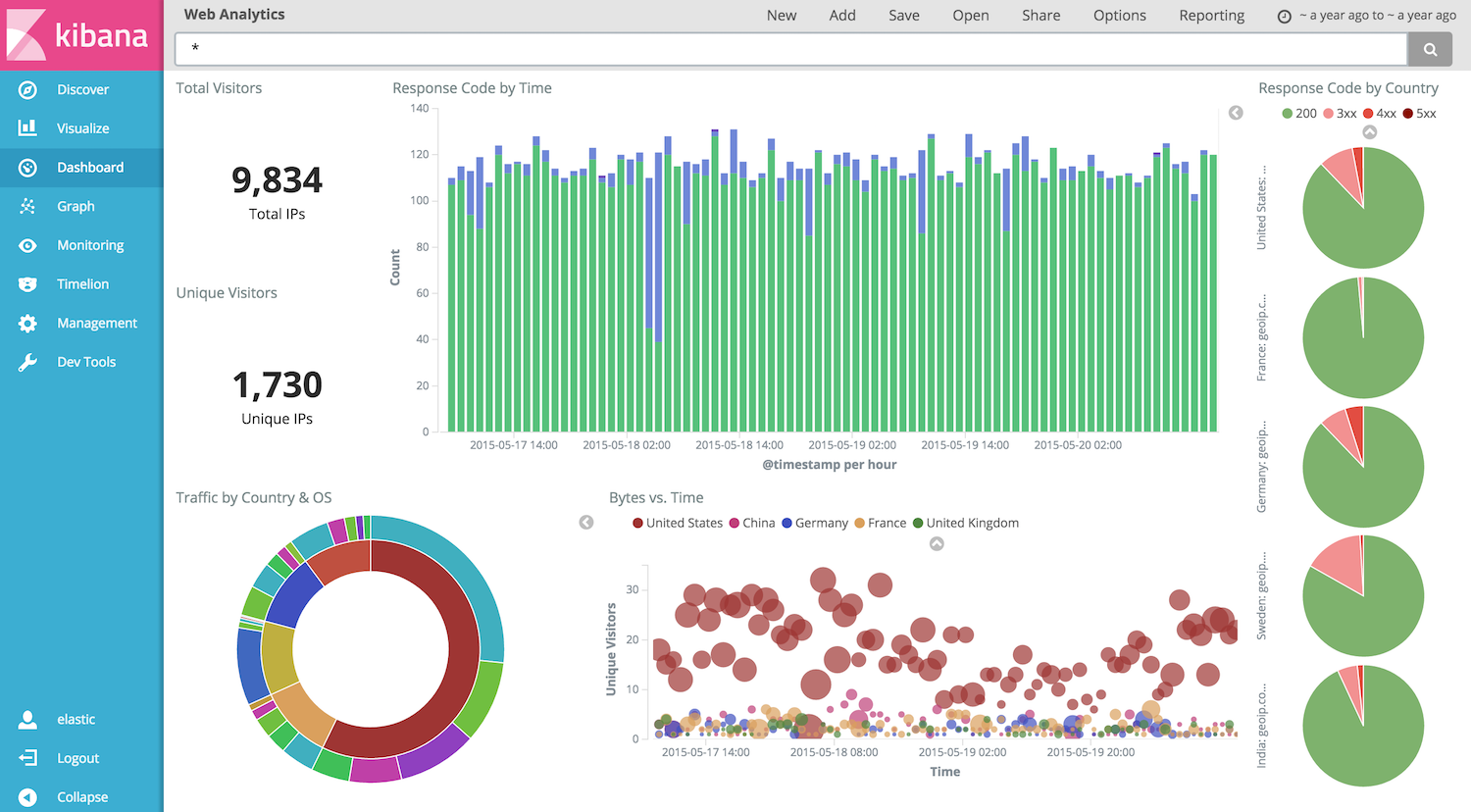
然后呢,官网出了个Kibana (ELK—Elasticsearch, logstash, kibana三剑客之一,另外Elastic认证了解一下——截止目前国内考过的不足500人),一个web应用程序,用图表啊、地图啊等面板来可视化数据(图像天然具有亲和力,详见 Guide, 初步的安装及说明详见附录5),如下图:
- 安装
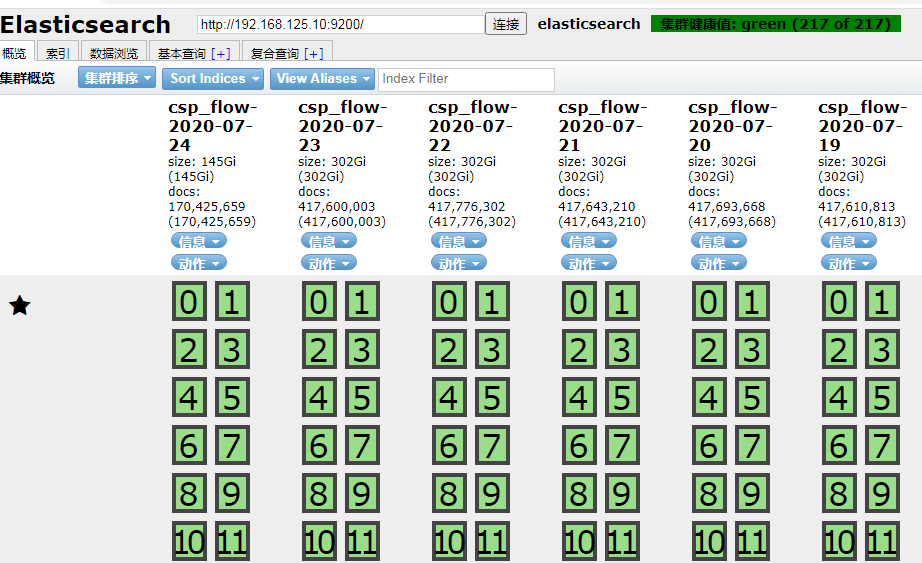
windows上安装Elastic search 请参考附注2 链接(需要安装IK分词器,以更好的支持汉语分词;安装elasticsearch-head ,简单的可视化的web客户端,可支持基本的查询操作或者通过DSL检索结果——为支持它,需要装Node.js; node.js 又需要集成 npm 和 grunt)
elasticsearch-head 效果如下图:
- 核心概念
Elastic Search是一个实时分布式搜索和分析引擎,处理大数据相当的擅长。Stackoverflow、Github、Wiki以及英国卫报等在全文检索、代码搜索(Github超过1300亿行)、地理位置查询、社交网络实时数据等领域均广泛深入的使用了ES,国内的字节跳动、腾讯、阿里均有相关应用。目前认为其核心概念包括:
- Score
就是根据一套规则和算法,满足搜索条件的文档,其中相关信息的匹配度(或称之为相关度),打分越高,则匹配度越高,搜索结果按打分高低(匹配度)倒叙展示。如下图的一个搜索结果:
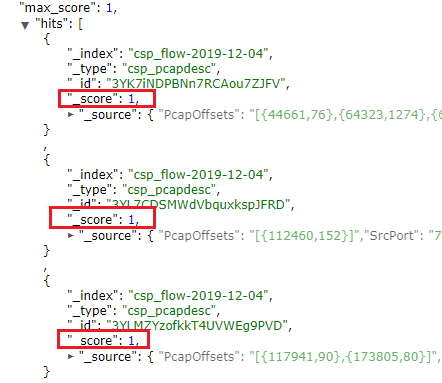
具体的Score,涉及到Norm(归一化)和Boost(可以设置field和document的Boot—相当于权重的概念)
- 集群(Cluster)、节点(Node)和分片(shards)
集群即多台物理机构成,每个物理机包含多个节点(其中只有一个Master Node),每个节点包含多个分片,每个分片可以有0个或多个复制分片做必要的数据冗余。其分布式特性,通过底层的如下操作自动完成:
(1)将你的文档分区到不同的容器或者分片(shards)中,它们可以存在于一个或多个节点中。
(2)将分片均匀的分配到各个节点,对索引和搜索做负载均衡。 冗余每一个分片,防止硬件故障造成的数据丢失。
(3)将集群中任意一个节点上的请求路由到相应数据所在的节点。
(4)无论是增加节点,还是移除节点,分片都可以做到无缝的扩展和迁移。
- 索引(Index)
Elastic Search使用倒排索引(Inverted Index)来做快速的全文搜索(不同于一般数据库的索引,用B-Tree来实现)。具体倒排索引原理,可能需要单独的一篇博客来说明
- 分词(analysis)
分析(analysis)是这样一个过程:
(1)首先,表征化一个文本块为适用于倒排索引单独的词(term)
(2)然后标准化这些词为标准形式,提高它们的“可搜索性”或“查全率”
这个工作是分析器(analyzer)完成的。一个分析器(analyzer)包含如下三个功能:
字符过滤器
首先字符串经过字符过滤器(character filter),它们的工作是在表征化(译者注:这个词叫做断词更合适)前处理字符串。 字符过滤器能够去除HTML标记,或者转换 "&" 为 "and" 。
分词器
下一步,分词器(tokenizer)被表征化(断词)为独立的词。一个简单的分词器(tokenizer)可以根据空格或逗号将单词分开 (译者注:这个在中文中不适用)。
表征过滤
最后,每个词都通过所有表征过滤(token filters),它可以修改词(例如将 "Quick" 转为小写),去掉词(例如停用词 像 "a" 、 "and"``"the" 等等),或者增加词(例如同义词像 "jump" 和 "leap" )
- 字段共享
ES本质上和关系型数据库还是有差别,并不能和DB的各个概念完全对应。默认同名的Fields在整个Indices共享,因此你不能在Type里定义同名的多个Filelds,导致删除数据只能整个索引一起删除,而不能单单删除一个Type
- 基础知识
- 文档
Elastic search是面向文档的,文档归属于一种类型(type),而这些type存在(索引)index里。传统关系数据库和ES的简单对比如下图(6.0版本后默认支持single type,涉及字段共享的优化):
| Relational DB | Databases | Tables | Rows | Columns |
| ElasticSearch | Indices | Types | Documents | Fields |
2.检索文档
支持HTTP的GET、PUT、HEAD、DELETE(由于字段共享等原因,ES目前不支持删除表,只能整个索引一起删除)、POST操作,如下图(故可直接用postman、SoapUI、Chrome插件ElasticSearch Head 等工具发http请求来查询文档):

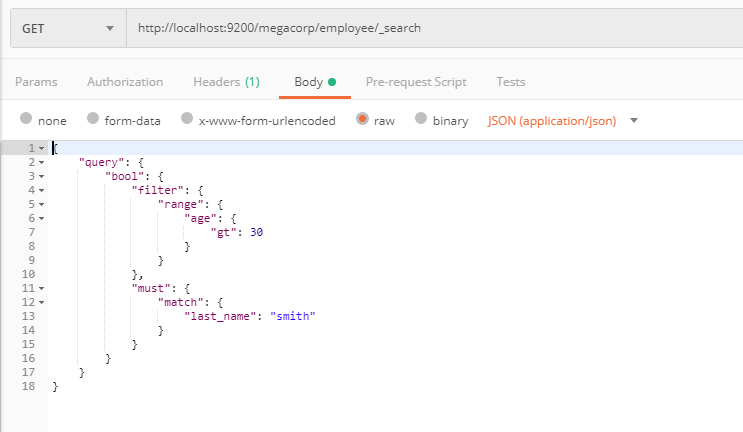
ES提供丰富灵活的查询语句(另外Elasticsearch-sql插件可以自动将sql语句翻译为DSL)——Query DSL(基本的语法有filter,bool—包括should【类似于Or】、must【类似于and】, term—精确匹配, match,range,exists,missing等),有了它构建复杂、强大的查询都不事儿,如下图(用postman,查询 age > 30 且 last_name = "smith"):
3. 字段数据类型
官方文档:Mapping types
- 核心数据类型 (只列工作中常用的):
| Data Types | Values |
| String | text, keyword |
| 数值类型(Numberic dataTypes) | long, integer, short, byte, double, float |
| 日期类型 | date |
| 布尔类型 | boolean |
| 范围类型 | integer_range, float_range, long_range, double_range, date_range |
| 二进制类型 | binary |
- 复杂数据类型
| Data Types | Values |
| 数组类型 | 不需要特殊的数据类型支持 |
| Object type | object — 代表单个json |
| 嵌套类型 | nested — 代表一组json |
- 地理相关的数据类型
| Data Types | Values |
| 坐标点类型 | geo_point用来表征经纬度 |
| 地理图形类型 | geo_shape用来表征复杂的形状,如多边形 |
- 专门的数据类型
| Data Types | Values |
| IP类型 | ip — 用于IPv4和IPv6(项目中高频使用) |
| token数量类型 | token_count — 统计字符串中token的数量 |
- 尾声
(1)ES不支持Join,但支持aggregations,类似于SQL的group by
(2)通过Merge segments可以提高查询速度,最后Merge成的Segments个数越小,查询时间提高的越快。Merge segments过程比较耗费磁盘和CPU,所以建议凌晨执行该操作
(3)ES支持将各种数据库的数据导入,主要通过logstash;ES之间的数据拷贝,可以用elasticdump
致敬 Doug Cutting (Lucene、Nutch 、Hadoop之父)

谈到成功,Cutting认为他的成功主要归功于两点:
- 对自己工作的热情(Cutting在大学时就开始做Infrastracture类的程序,还用 Lisp为Emacs贡献过代码,他非常喜欢自己的程序被千万人使用的感觉)
- 目标不要定得过大,要踏踏实实,一步一个脚印
附:
1) 官网guide 及对应中文版 — Elasticsearch: 权威指南(pdf下载)
2) Elasticsearch6.4.0-windows环境部署安装
4) Hadoop 十岁生日时 Doug Cutting的讲话
*******************************************************************************
精力有限,想法太多,专注做好一件事就行
- 我只是一个程序猿。5年内把代码写好,技术博客字字推敲,坚持零拷贝和原创
- 写博客的意义在于打磨文笔,训练逻辑条理性,加深对知识的系统性理解;如果恰好又对别人有点帮助,那真是一件令人开心的事
*******************************************************************************
初识Elastic search—附《Elasticsearch权威指南—官方guide的译文》的更多相关文章
- Elasticsearch: 权威指南(官方教程)
<Elasticsearch 权威指南>中文版 序言 前言 基础入门 深入搜索 处理人类语言 聚合 地理位置 数据建模 管理.监控和部署
- Elasticsearch 权威指南
Elasticsearch 权威指南 http://fuxiaopang.gitbooks.io/learnelasticsearch/content/index.html
- Elasticsearch 权威指南 NESTAPI地址
Elasticsearch 权威指南:http://fuxiaopang.gitbooks.io/learnelasticsearch/content/index.html NEST:http://n ...
- elasticsearch权威指南
elasticsearch权威指南 https://elasticsearch.cn/book/elasticsearch_definitive_guide_2.x/
- Elasticsearch权威指南(中文版)
Elasticsearch权威指南(中文版) 下载地址: https://pan.baidu.com/s/1bUGJmwS2Gp0B32xUyXxCIw 扫码下面二维码关注公众号回复100010 获取 ...
- elastic search book [ ElasticSearch book es book]
谁在使用ELK 维基百科, github都使用 ELK (ElasticSearch es book) ElasticSearch入门 Elasticsearch入门,这一篇就够了==>http ...
- elasticsearch 权威指南入门阅读笔记(一)
相关文档 esapi:https://es.xiaoleilu.com/010_Intro/10_Installing_ES.html https://esdoc.bbossgroups.co ...
- ElasticSearch权威指南学习(分布式搜索)
查询阶段 在初始化查询阶段(query phase),查询被向索引中的每个分片副本(原本或副本)广播. 每个分片在本地执行搜索并且建立了匹配document的优先队列(priority queue). ...
- Elasticsearch: 权威指南 » 深入搜索 » 多字段搜索 » 多数字段 good
跨字段实体搜索 » 多数字段编辑 全文搜索被称作是 召回率(Recall) 与 精确率(Precision) 的战场: 召回率 ——返回所有的相关文档:精确率 ——不返回无关文档.目的是在结果的 ...
随机推荐
- springboot @Cacheable 基本使用
加入依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>sp ...
- IDEA2019版中文汉化包
废话不多说,上才艺 E G M~~~~~ 2020版的IDEA大佬可以无视........ 1.打开IDEA文件目录 2.打开lib目录--将汉化版复制到该目录下 3.打开IDEA查看效果 高铁链 ...
- springboot的jar为何能独立运行
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- [强化学习]Part1:强化学习初印象
引入 智能 人工智能 强化学习初印象 强化学习的相关资料 经典书籍推荐:<Reinforcement Learning:An Introduction(强化学习导论)>(强化学习教父Ric ...
- 计算机网络之DNS协议
DNS( Domain Name System)是“域名系统”的英文缩写,是一种组织成域层次结构的计算机和网络服务命名系统,它用于TCP/IP网络,它所提供的服务是用来将主机名和域名转换为IP地址的工 ...
- 入门大数据---Spark_Streaming整合Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- JavaScript中__proto__与prototype的关系(转)
一.所有构造器/函数的__proto__都指向Function.prototype,它是一个空函数(Empty function) 1 2 3 4 5 6 7 8 9 Number.__proto__ ...
- Dynamics CRM 365 不用按钮工具,直接用js脚本控制按钮的显示隐藏
Dynamics CRM 365 不用按钮工具,直接用js脚本控制按钮的显示隐藏: try { // 转备案按钮 let transferSpecialRequestButton = parent.p ...
- Spring — 循环依赖
读完这篇文章你将会收获到 Spring 循环依赖可以分为哪两种 Spring 如何解决 setter 循环依赖 Spring 为何是三级缓存 , 二级不行 ? Spring 为啥不能解决构造器循环依赖 ...
- 让IE下载跟迅雷一样快?
网络上搜的没试过... 修改IE支持多线程即可: HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Internet Settin ...