Spark UDAF实现举例 -- average pooling
1.UDAF定义
spark中的UDF(UserDefinedFunction)大家都不会陌生, UDF其实就是将一个普通的函数, 包装为可以按 行 操作DataFrame中指定Columns的函数.
例如, 对某一列的所有元素进行+1操作, 它对应mapreduce操作中的map操作. 这种操作有的主要特点是:
- 行与行之间的操作是独立的, 可以非常方便的并行计算
- 每一行的操作完成后, map的任务就完成了, 直接将结果返回就行, 它是一种”无状态的“
但是UDAF(UserDefinedAggregateFunction)则不同, 由于存在聚合(Aggregate)操作, 它对应mapreduce操作中的reduce操作. SparkSQL中有很多现成的聚合函数, 常用的sum, count, avg等等都是. 这种操作的主要特点是:
- 每一轮reduce之间可以是并行, 但是多轮reduce的执行是串行的, 下一轮依靠前一轮的结果, 它是一种“有状态的”, 需要记录中间的计算结果
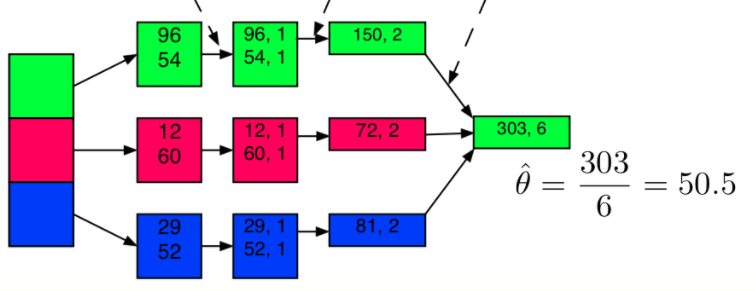
分析上图, 96 => (96, 1)这一步是一个map操作, 给每个样本添加一个1, 表示它的数量. 它们之间的计算是独立的, 也不影响数据的行数. 然后(96, 1)和(54, 1)求和, 得到(150, 2), 它是一轮reduce的其中一个中间结果, 等三个中间结果都结束了, 才能继续后续的reduce, 得到最终的reduce结果(303, 6), 因此完整的reduce需要记录并不断更新中间结果.
2.向量平均(average pooling)
向量平均是个很常用的操作, 比如我们现在有1000个64维的向量, 想要求这1000个点的中心点. 通常来说我们不会用64列float column去存储一个向量, 因此无法使用原生的avg函数.
下面介绍如何自定义一个avgvector函数, 去处理array[float] column的平均值计算问题. 通过这个例子学会如何在spark下实现自定义的聚合函数
2.1 average的并行化
average算法非常简单, 求个和, 然后除以样本个数就好了. 它的并行化也很好理解
- reduce的过程只进行sum的累积和样本数num的累积, 在最后一步将sum/num
因此我们的在reduce的过程中, 需要时刻记录当前task处理的样本的个数, 和它们的和.
由于这样的原因, 不像UDF只需要定义一个函数就可以, UDAF通常需要定义一个类, 用来保存中间结果
2.2 代码实现
// 从基类UserDefinedAggregateFunction继承
class VectorMean64 extends UserDefinedAggregateFunction {
// 定义输入的格式
// 这个函数将会处理的那一列的数据类型, 因为是64维的向量, 因此是Array[Float]
override def inputSchema: org.apache.spark.sql.types.StructType =
StructType(StructField("vector", ArrayType(FloatType)) :: Nil)
// 这个就是上面提到的状态
// 在reduce过程中, 需要记录的中间结果. vector_count即为已经统计的向量个数, 而vector_sum即为已经统计的向量的和
override def bufferSchema: StructType =
StructType(
StructField("vector_count", IntegerType) ::
StructField("vector_sum", ArrayType(FloatType)) :: Nil)
// 最终的输出格式
// 既然是求平均, 最后当然还是一个向量, 依然是Array[Float]
override def dataType: DataType = ArrayType(FloatType)
override def deterministic: Boolean = true
// 初始化
// buffer的格式即为bufferSchema, 因此buffer(0)就是向量个数, 初始化当然是0, buffer(1)为向量和, 初始化为零向量
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0
buffer(1) = Array.fill[Float](64)(0).toSeq
}
// 定义reduce的更新操作: 如何根据一行新数据, 更新一个聚合buffer的中间结果
// 一行数据是一个向量, 因此需要将count+1, 然后sum+新向量
// addTwoEmb为向量相加的基本实现
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0) = buffer.getInt(0) + 1
val inputVector = input.getAs[Seq[Float]](0)
buffer(1) = addTwoEmb(buffer.getAs[Seq[Float]](1), inputVector)
}
// 定义reduce的merge操作: 两个buffer结果合并到其中一个bufer上
// 两个buffer各自统计的样本个数相加; 两个buffer各自的sum也相加
// 注意: 为什么buffer1和buffer2的数据类型不一样?一个是MutableAggregationBuffer, 一个是Row
// 因为: 在将所有中间task的结果进行reduce的过程中, 两两合并时是将一个结果合到另外一个上面, 因此一个是mutable的, 它们两者的schema其实是一样的, 都对应bufferSchema
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getInt(0) + buffer2.getInt(0)
buffer1(1) = addTwoEmb(buffer1.getAs[Seq[Float]](1), buffer2.getAs[Seq[Float]](1))
}
// 最终的结果, 依赖最终的buffer中的数据计算的到, 就是将sum/count
override def evaluate(buffer: Row): Any = {
val result = buffer.getAs[Seq[Float]](1).toArray
val count = buffer.getInt(0)
for (i <- result.indices) {
result(i) /= (count + 1)
}
result.toSeq
}
// 向量相加
private def addTwoEmb(emb1: Seq[Float], emb2: Seq[Float]): Seq[Float] = {
val result = Array.fill[Float](emb1.length)(0)
for (i <- emb1.indices) {
result(i) = emb1(i) + emb2(i)
}
result.toSeq
}
解释可以参考上面的代码注释. 核心就是定义四个模块:
- 中间结果的格式 - bufferSchema
- 将一行数据更新到中间结果buffer中 - update
- 将两个中间结果buffer合并 - merge
- 从最后的buffer计算需要的结果 - evaluate
2.3 使用
// 注册一下, 使其可以在Spark SQL中使用
spark.udf.register("avgVector64", new VectorMean64)
spark.sql("""
|select group_id, avgVector64(embedding) as avg_embedding
|from embedding_table_name
|group by group_id
""".stripMargin)
// 当然不注册也可以用, 只是不能在SQL中用, 可以直接用来操作DataFrame
val avgVector64 = new VectorMean64
val df = spark.sql("select group_id, embedding from embedding_table_name")
df.groupBy("group_id").agg(avgVector64(col("embedding")))
参考
https://docs.databricks.com/spark/latest/spark-sql/udaf-scala.html
Spark UDAF实现举例 -- average pooling的更多相关文章
- 深度学习方法(十):卷积神经网络结构变化——Maxout Networks,Network In Network,Global Average Pooling
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 最近接下来几篇博文会回到神经网络结构 ...
- 深度拾遗(06) - 1X1卷积/global average pooling
什么是1X1卷积 11的卷积就是对上一层的多个feature channels线性叠加,channel加权平均. 只不过这个组合系数恰好可以看成是一个11的卷积.这种表示的好处是,完全可以回到模型中其 ...
- Global Average Pooling Layers for Object Localization
For image classification tasks, a common choice for convolutional neural network (CNN) architecture ...
- 深度学习基础系列(十)| Global Average Pooling是否可以替代全连接层?
Global Average Pooling(简称GAP,全局池化层)技术最早提出是在这篇论文(第3.2节)中,被认为是可以替代全连接层的一种新技术.在keras发布的经典模型中,可以看到不少模型甚至 ...
- Network in Network(2013),1x1卷积与Global Average Pooling
目录 写在前面 mlpconv layer实现 Global Average Pooling 网络结构 参考 博客:blog.shinelee.me | 博客园 | CSDN 写在前面 <Net ...
- spark UDAF
感谢我的同事 李震给我讲解UDAF 网上找到的大部分都只有代码,但是缺少讲解,官网的的API有讲解,但是看不太明白.我还是自己记录一下吧,或许对其他人有帮助. 接下来以一个求几何平均数的例子来说明如何 ...
- 理解Spark SQL(三)—— Spark SQL程序举例
上一篇说到,在Spark 2.x当中,实际上SQLContext和HiveContext是过时的,相反是采用SparkSession对象的sql函数来操作SQL语句的.使用这个函数执行SQL语句前需要 ...
- 自定义spark UDAF
官网链接 样例代码: import java.util.ArrayList; import java.util.List; import org.apache.spark.sql.Dataset; i ...
- 转:Spark User Defined Aggregate Function (UDAF) using Java
Sometimes the aggregate functions provided by Spark are not adequate, so Spark has a provision of ac ...
随机推荐
- android studio问题备注
androidTestCompile 'com.android.support:support-annotations:25.3.1'configurations.all { resolutionSt ...
- 老猿学5G扫盲贴:R15/R16中计费架构和计费原则涉及的规范文档
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 一.概述 在R16的32.240文档对应规范为3G ...
- Python模块是否支持自定义属性使用双下划线开头和结尾?
我们知道在Python中,变量名类似__xxx__的,也就是以双下划线开头并且以双下划线结尾的变量和方法,是特殊变量,特殊变量是可以直接访问的,不是私有变量,所以,一般实例变量和类变量以及方法不能用_ ...
- 第9.4节 Python中用readline读取二进制文件方式打开文件
在<第9.3节 Python的文件内容读取:readline>中介绍了使用readline读取文件的处理,readline除了使用文本文件方式打开文件读外,也可以读取二进制方式打开的文件, ...
- PyQt(Python+Qt)学习随笔:部件的minimumSize、minimumSizeHint之间的区别与联系
1.minimumSize是一个部件设置的最小值,minimumSizeHint是部件Qt建议的最小值: 2.minimumSizeHint是必须在布局中的部件才有效,如果是窗口,必须窗口设置了布局才 ...
- HTTP接口传输数据常用的方式
Get方式是从服务器上获取数据,在数据查询时,建议用Get方式:如商品信息接口.搜索接口等 Post方式是向服务器传送数据,做数据添加.修改或删除时,建议用Post方式,如登录注册接口等. 1.GET ...
- python-列表list和元组tuple
list Python内置的一种数据类型是列表:list.list是一种有序的集合,可以随时添加和删除其中的元素. 比如,列出班里所有同学的名字,就可以用一个list表示: >>> ...
- 《深入理解计算机系统》实验一 —Data Lab
本文是CSAPP第二章的配套实验,通过使用有限的运算符来实现正数,负数,浮点数的位级表示.通过完成这13个函数,可以使我们更好的理解计算机中数据的编码方式. 准备工作 首先去官网Lab Assig ...
- pl/sql12;pl/sql14激活注册码
搜集的plsql 12激活码: Product Code(产品编号):4t46t6vydkvsxekkvf3fjnpzy5wbuhphqz serial Number(序列号):601769 pass ...
- I am George1123!
我是 George1123,一名来自浙江省,杭州市的初三爆菜 \(\tt oier\) . 以下是蒟蒻逊逊的 OJ 账号: 洛谷 loj uoj bzoj spoj 彩蛋:Welcome to my ...