Linux服务器以及系统性能排查常用命令
一、在Linux系统中排查CPU故障的方法和技巧
1、top命令
Linux内部命令,可以查看实时的CPU的使用情况,也可以查看CPU最近一段时间CPU的使用情况
Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用情况
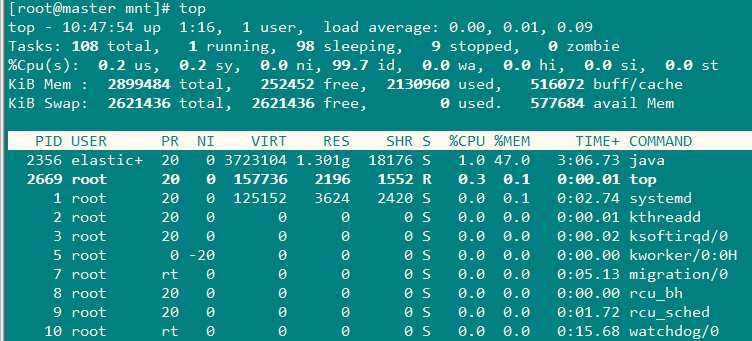
top命令参数详解:
统计信息区前五行是系统整体的统计信息。
第一行:
是任务队列信息,同uptime命令的执行结果。其参数详解如下:
top - 10:47:54 up 1:16, 1 user, load average: 0.00, 0.01, 0.09
10:47:54 :当前时间
up 1:16 :系统运行时间,格式为时:分
1 user :当前登录用户数
load average: 0.00, 0.01, 0.09 :系统负载,即任务队列的平均长度。三个数值分别为1分钟、5分钟、15分钟前到现在的平均值。
第二、三行为进程和CPU信息。当有多个CPU时,这些内容可能会超过两行,内容如下:
Tasks: 108 total, 1 running, 98 sleeping, 9 stopped, 0 zombie
108 total :进程总数 ;
1 running :正在运行的进程数 ;
98 sleeping :睡眠的进程数 ;
9 stopped :停止的进程数 ;
0 zombie:僵尸进程数
%Cpu(s): 0.2 us, 0.2 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
0.2 us :用户空间占用CPU百分比 ;
0.2 sy :内核空间占用CPU百分比;
0.0 ni :用户进程空间内改变过优先级的进程占用CPU百分比;
99.7 id :空闲CPU百分比;
0.0 wa :等待输入输出的CPU时间百分比;
0.0 hi :硬件CPU中断占用百分比;
0.0 si :软中断占用百分比;
0.0 st :虚拟机占用百分比 ;
第四、五行为内存信息,内容如下:
KiB Mem : 2899484 total, 252452 free, 2130960 used, 516072 buff/cache
2899484 total :物理内存总量
252452 free :空闲内存总量
2130960 used :使用的物理内存总量
516072 buff/cache :用作内核缓存的内存量
KiB Swap: 2621436 total, 2621436 free, 0 used. 577684 avail Mem
2621436 total :交换器总量
2621436 free,:空闲交换区总量
0 used :使用的交换区总量
577684 avail Mem :缓冲的交换区总量,内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,该数值即为这些内容已存在于内存中的交换区的大小,相应的内存再次被换出时可不必再对交换区写入。
怎么看内存有多少空闲呢?
totalfree =(252452 free :空闲内存总量)+(516072 buff/cache :用作内核缓存的内存量)+(577684 avail Mem)
第六行:
PID USER PR NI VIRI RES SHR S %CPU %MEM TIME+ COMMAND
PID:进程id USER:进程所有者的用户名 PR:优先级 NI:nice值。负值表示高优先级,正值表示低优先级
VIRI:进程使用的虚拟内存总量,单位KB。VIRI=SWAP+RES RES:进程使用的、未被换出的物理内存大小,单位KB,RES=CODE+DATA
SHR:共享内存大小,单位KB %CPU:上次更新到现在的CPU时间占用百分比 %MEM:进程使用的物理内存百分比
TIME +:进程使用的CPU时间总计,单位1/100秒 COMMAND:命令名/命令行
TOP命令使用(后跟参数详解)
top [-] [d] [p] [q] [c] [C] [S] [s] [n]
参数说明:
d:指定每两次屏幕信息刷新之间的时间间隔。例如:top -d 2 屏幕每两秒刷新
p:通过指定监控进程ID来仅仅监控某个进程的状态。例如:top -p 1 仅仅监控PID为1 的进程状态
q :该选项将使top没有任何延迟的进行刷新
S :指定累计模式
s :使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。
i :使top不显示任何闲置或者僵死进程。 例如:top i
top -d 2 //每隔2秒显式所有进程的资源占用情况
top -c //每隔5秒显式进程的资源占用情况,并显示进程的命令行参数(默认只有进程名)
top -p 12345 -p 6789//每隔5秒显示pid是12345和pid是6789的两个进程的资源占用情况
top -d 2 -c -p 123456 //每隔2秒显示pid是12345的进程的资源使用情况,并显式该进程启动的命令行参数
# top -b -d 2.5 -n 5 > performace.txt
注:要将内容输出到文件中,必须使用-b,表示批处理选项
b. TOP命令如何快速按%CPU、%MEM、TIME+列排序
a). %CPU:使用大写字母按键:P
b). %MEM:使用大写字母按键:M
c). TIME+:使用大写字母按键: T
注:TOP默认排序为倒序,如果确实需要升序排序,可以使用大写字母按键:R
c. TOP命令中显示其它列值、将两列互换等
a). 选择显示列或隐藏列:使用小写字母按键:f
c). 交换列显示顺序:使用小写字母按键: o
b). 选择需要排序的列:使用大写字母按键:F
jstack pid命令查看当前java进程的堆栈状态uptime
dmesg | tail
vmstat 1
mpstat -P ALL 1
pidstat 1
iostat -xz 1
free -m
sar -n DEV 1
sar -n TCP,ETCP 1
top
1、uptime
该命令可以大致的看出计算机的整体负载情况,load average后的数字分别表示计算机在1分钟、5分钟、15分钟内的平均负载。
$ uptime
23:51:26 up 21:31, 1 user, load average:30.02, 26.43, 19.02
#如果1分钟的平均负载很高,15分钟的很低 ==>系统正在执行高负载命令,大量消耗CPU
参数解释:
23:51:26:系统当前时间 up 21:31:系统运行时间 1 user :用户总连接数 load average:30.02, 26.43, 19.02:系统平均负载,指在特定时间间隔内运行队列中的平均进程数
2、dmesg | tail
$ dmesg | tail
[1880957.563150] perl invoked oom-killer: gfp_mask=0x280da, order=0, oom_score_adj=0 [...]
[1880957.563400] Out of memory: Kill process 18694 (perl) score 246 or sacrifice child
[1880957.563408] Killed process 18694 (perl) total-vm:1972392kB, anon-rss:1953348kB, file-rss:0kB
[2320864.954447] TCP: Possible SYN flooding on port 7001. Dropping request. Check SNMP counters.
上面的例子中,显示进程18694 因引内存越界被kill掉以及TCP request被丢弃的错误。通过dmesg可以快速判断是否有导致系统性能异常的问题。
3、vmstat 1
打印进程、内存、交换分区、IO和CPU等的统计信息。
[root@master mnt]# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 2008 95144 0 239124 0 0 16 5 88 139 1 0 99 0 0
0 0 2008 94524 0 239092 0 0 0 0 247 400 1 1 99 0 0
0 0 2008 94524 0 239092 0 0 0 0 185 331 0 0 100 0 0
0 0 2008 94540 0 239092 0 0 0 0 175 322 0 0 100 0 0
0 0 2008 94492 0 239092 0 0 0 0 206 349 0 0 99 0 0
vmstat第一行输出表示从开机到vmstat运行时的平均值,而不是前一秒数据。除第一次以外,剩余的都是1秒统计一次。所以我们可以跳过第一行,观察后面几行的情况。
检查下面各列:
r:等待CPU的进程数。该指标能更好地判断CPU是否饱和,因为它不包括I/O,简单地说,r值高于CPU数时就意味着饱和。
free:空闲的内存 千字节数,free -m:能更清楚地说明空闲内存的状态。
si、so、Swap-ins、Swap-outs。如果他们不为0,就意味着内存已经不足,开始动用交换空间的存粮了。
us、sy、id、wa、st:它们是所有CPU的使用百分比。它们分别表示user time、system time(处于内核态的时间)、idle、wait I/O和steal time
(被其它租户,或者是租户自己的Xen隔离设备驱动域(isolated driver domain),所占用的时间)。
通过相加us和sy的百分比,你可以确定CPU是否处于忙碌状态。一个持续不变的wait I/O意味着瓶颈在硬盘上,这种情况往往伴随着CPU的空闲,因为任务都卡在磁盘I/O上了。你可以把wait I/O当作CPU空闲的另一种形式,它额外给出了CPU空闲的线索。
I/O处理同样会消耗系统时间。一个高于20%的平均系统时间,往往值得进一步发掘:也许系统花在I/O的时太长了。
在上面的例子中,CPU基本把时间花在用户态里面,意味着跑在上面的应用占用了大部分时间。此外,CPU平均使用率在90%之上。这不一定是个问题;检查下“r”列,看看是否饱和了。
4、mpstat -P ALL 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
07:38:49 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
07:38:50 PM all 98.47 0.00 0.75 0.00 0.00 0.00 0.00 0.00 0.00 0.78
07:38:50 PM 0 96.04 0.00 2.97 0.00 0.00 0.00 0.00 0.00 0.00 0.99
07:38:50 PM 1 97.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 2.00
07:38:50 PM 2 98.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00
07:38:50 PM 3 96.97 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3.03
[...]
这个命令显示每个CPU的时间使用百分比,你可以用它来检查CPU是否存在负载不均衡。单个过于忙碌的CPU可能意味着整个应用只有单个线程在工作。
5、pidstat 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
07:41:02 PM UID PID %usr %system %guest %CPU CPU Command
07:41:03 PM 0 9 0.00 0.94 0.00 0.94 1 rcuos/0
07:41:03 PM 0 4214 5.66 5.66 0.00 11.32 15 mesos-slave
07:41:03 PM 0 4354 0.94 0.94 0.00 1.89 8 java
07:41:03 PM 0 6521 1596.23 1.89 0.00 1598.11 27 java
07:41:03 PM 0 6564 1571.70 7.55 0.00 1579.25 28 java
07:41:03 PM 60004 60154 0.94 4.72 0.00 5.66 9 pidstat
07:41:03 PM UID PID %usr %system %guest %CPU CPU Command
07:41:04 PM 0 4214 6.00 2.00 0.00 8.00 15 mesos-slave
07:41:04 PM 0 6521 1590.00 1.00 0.00 1591.00 27 java
07:41:04 PM 0 6564 1573.00 10.00 0.00 1583.00 28 java
07:41:04 PM 108 6718 1.00 0.00 0.00 1.00 0 snmp-pass
07:41:04 PM 60004 60154 1.00 4.00 0.00 5.00 9 pidstat
pidstat看上去就像top,不过top的输出会覆盖掉之前的输出,而pidstat的输出则添加在之前的输出的后面。这有利于观察数据随时间的变动情况,也便于把你看到的内容复制粘贴到调查报告中。
上面的例子表明,CPU主要消耗在两个java进程上。%CPU列是在各个CPU上的使用量的总和;1591%意味着java进程消耗了将近16个CPU。
6、iostat -zx 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
73.96 0.00 3.73 0.03 0.06 22.21
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvda 0.00 0.23 0.21 0.18 4.52 2.08 34.37 0.00 9.98 13.80 5.42 2.44 0.09
xvdb 0.01 0.00 1.02 8.94 127.97 598.53 145.79 0.00 0.43 1.78 0.28 0.25 0.25
xvdc 0.01 0.00 1.02 8.86 127.79 595.94 146.50 0.00 0.45 1.82 0.30 0.27 0.26
dm-0 0.00 0.00 0.69 2.32 10.47 31.69 28.01 0.01 3.23 0.71 3.98 0.13 0.04
dm-1 0.00 0.00 0.00 0.94 0.01 3.78 8.00 0.33 345.84 0.04 346.81 0.01 0.00
dm-2 0.00 0.00 0.09 0.07 1.35 0.36 22.50 0.00 2.55 0.23 5.62 1.78 0.03
[...]
这个命令可以弄清块设备(磁盘)的状况,包括工作负载和处理性能。注意以下各项:
r/s,w/s,rkB/s,wkB/s:分别表示每秒设备读次数,写次数,读的KB数,写的KB数。它们描述了磁盘的工作负载。也许性能问题就是由过高的负载所造成的。
await:I/O平均时间,以毫秒作单位。它是应用中I/O处理所实际消耗的时间,因为其中既包括排队用时也包括处理用时。如果它比预期的大,就意味着设备饱和了,或者设备出了问题。
avgqu-sz:分配给设备的平均请求数。大于1表示设备已经饱和了。(不过有些设备可以并行处理请求,比如由多个磁盘组成的虚拟设备)
%util:设备使用率。这个值显示了设备每秒内工作时间的百分比,一般都处于高位。低于60%通常是低性能的表现(也可以从await中看出),不过这个得看设备的类型。接近100%通常意味着饱和。
如果某个存储设备是由多个物理磁盘组成的逻辑磁盘设备,100%的使用率可能只是意味着I/O占用
请牢记于心,disk I/O性能低不一定是个问题。应用的I/O往往是异步的(比如预读(read-ahead)和写缓冲(buffering for writes)),所以不一定会被阻塞并遭受延迟。
7、free -m
total used free shared buffers cached
Mem: 245998 24545 221453 83 59 541
-/+ buffers/cache: 23944 222053
Swap: 0 0 0
右边的两列显示:
buffers:用于块设备I/O的缓冲区缓存
cached:用于文件系统的页缓存
它们的值接近于0时,往往导致较高的磁盘I/O(可以通过iostat确认)和糟糕的性能。上面的例子里没有这个问题,每一列都有好几M呢。
比起第一行,-/+ buffers/cache提供的内存使用量会更加准确些。Linux会把暂时用不上的内存用作缓存,一旦应用需要的时候立刻重新分配给它。所以部分被用作缓存的内存其实也算是空闲内存,第二行以此修订了实际的内存使用量。为了解释这一点, 甚至有人专门建了个网站: linuxatemyram。
如果你在Linux上安装了ZFS,正如我们在一些服务上所做的,这一点会变得更加迷惑,因为ZFS它自己的文件系统缓存不算入free -m。有时系统看上去已经没有多少空闲内存可用了,其实内存都待在ZFS的缓存里呢。
8、sar -n DEV 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
12:16:48 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
12:16:49 AM eth0 18763.00 5032.00 20686.42 478.30 0.00 0.00 0.00 0.00
12:16:49 AM lo 14.00 14.00 1.36 1.36 0.00 0.00 0.00 0.00
12:16:49 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
12:16:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
12:16:50 AM eth0 19763.00 5101.00 21999.10 482.56 0.00 0.00 0.00 0.00
12:16:50 AM lo 20.00 20.00 3.25 3.25 0.00 0.00 0.00 0.00
12:16:50 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
这个命令可以用于检查网络流量的工作负载:rxkB/s和txkB/s,以及它是否达到限额了。上面的例子中,eth0接收的流量达到22Mbytes/s,也即176Mbits/sec(限额是1Gbit/sec)
我们用的版本中还提供了%ifutil作为设备使用率(接收和发送两者中的最大值)的指标。我们也可以用Brendan的nicstat计量这个值。一如nicstat,sar显示的这个值不一定是对的,在这个例子里面就没能正常工作(0.00)。
- IFACE ,网络接口名称;
- rxpck/s ,每秒接收到包数;
- txpck/s ,每秒传输的报数;(transmit packages)
- rxkB/s ,每秒接收的千字节数;
- txkB/s ,每秒发送的千字节数;
- rxcmp/s ,每秒接收的压缩包的数量;
- txcmp/s ,每秒发送的压缩包的数量;
- rxmcst/s,每秒接收的组数据包数量;
9、sar -n TCP,ETCP 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
12:17:19 AM active/s passive/s iseg/s oseg/s
12:17:20 AM 1.00 0.00 10233.00 18846.00
12:17:19 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
12:17:20 AM 0.00 0.00 0.00 0.00 0.00
12:17:20 AM active/s passive/s iseg/s oseg/s
12:17:21 AM 1.00 0.00 8359.00 6039.00
12:17:20 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
12:17:21 AM 0.00 0.00 0.00 0.00 0.00
这个命令显示一些关键TCP指标的汇总。其中包括:
active/s:本地每秒创建的TCP连接数(比如concept()创建的)
passive/s:远程每秒创建的TCP连接数(比如accept()创建的)
retrans/s:每秒TCP重传次数
主动连接数(active)和被动连接数(passive)通常可以用来粗略地描述系统负载。可以认为主动连接是对外的,而被动连接是对内的,虽然严格来说不完全是这个样子。(比如,一个从localhost到localhost的连接)
重传是网络或系统问题的一个信号;它可能是不可靠的网络(比如公网)所造成的,也有可能是服务器已经过载并开始丢包。在上面的例子中,每秒只创建一个新的TCP连接。
10、top
在第一点已经介绍
Linux服务器以及系统性能排查常用命令的更多相关文章
- 检查Linux服务器性能的关键十条命令
检查Linux服务器性能的关键十条命令 概述 通过执行以下命令,可以在1分钟内对系统资源使用情况有个大致的了解. uptime dmesg | tail vmstat 1 mpstat -P ALL ...
- linux下维护服务器之常用命令
linux下维护服务器之常用命令! 第1套如下: 正则表达式: 1.如何不要文件中的空白行和注释语句: [root@localhost ~]# grep -v '^$' 文件名 |grep -v '^ ...
- Linux 系统基础优化和常用命令
目录 Linux 系统基础优化和常用命令 软连接 tar解压命令 gzip命令 netstart命令 ps命令 kill命令 killall命令 SELinux功能 iptables防火墙 Linux ...
- 运维 07 Linux系统基础优化及常用命令
Linux系统基础优化及常用命令 Linux基础系统优化 引言没有,只有一张图. Linux的网络功能相当强悍,一时之间我们无法了解所有的网络命令,在配置服务器基础环境时,先了解下网络参数设定命令 ...
- Linux的简单介绍和常用命令的介绍
Linux的简单介绍和常用命令的介绍 本说明以Ubuntu系统为例 Ubuntu系统的安装自行百度,或者参考http://www.cnblogs.com/CoderJYF/p/6091068.html ...
- 【Docker】(3)---linux部署Docker、Docker常用命令
linux部署Docker.Docker常用命令 本次部署Linux版本:CentOS 7.4 64位. 说明: 因为Docker是基于Linux 64bit的 所以Docker要求64位的系统且内核 ...
- Linux服务器,服务管理--systemctl命令详解,设置开机自启动
Linux服务器,服务管理--systemctl命令详解,设置开机自启动 syetemclt就是service和chkconfig这两个命令的整合,在CentOS 7就开始被使用了. 摘要: syst ...
- Linux操作系统安全-OpenSSL工具常用命令介绍
Linux操作系统安全-OpenSSL工具常用命令介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.OpenSSL开源项目有三个组件 openssl: 多用途的命令行工具,包 ...
- Linux查看文件大小5个常用命令
1. 前言 Linux 系统有非常好用的命令,功能也非常丰富,如果你对命令行工具熟悉,可以非常高效率完成维护工具.本文主要介绍Linux系统中,用于查看文件大小的命令. Linux 查看文件大小5个常 ...
随机推荐
- 第11.5节 Python正则表达式搜索任意字符匹配及元字符“.”(点)功能介绍
在re模块中,任意字符匹配使用"."(点)来表示, 在默认模式下,点匹配除了换行的任意字符.如果指定了搜索标记re.DOTALL ,它将匹配包括换行符的任意字符.关于搜索标记的含义 ...
- day013|python之模块02&目录01
1 from...import 1.1 概念 1.1.1 首次导入模块会发生的事 会触发模块的运行,产生一个模块的名称空间 将运行模块文件过程中产生的名字丢到模块额名称空间 在当前名称空间产生一个名字 ...
- 微信端video去除最顶层播放
https://x5.tencent.com/tbs/guide/video.html 给video标签添加属性 x5-video-player-type="h5"
- 安卓实用工具箱v4.3几百种小功能
款多功能实用工具箱.提供了从日常.图片.查询.设备.辅助.提取.优惠券.趣味游戏等多方面的功能,操作简单,即点即用,避免您下载超多应用的难题,且应用体积轻巧,界面简洁.已去除广告! 下载地址:http ...
- yum install nginx-没有可用软件包 nginx。
1. 错误提示 Centos 7下安装nginx,使用yum install nginx,报错提示没有可用的软件包.具体错误提示如下: 已加载插件:fastestmirror, product-id, ...
- Day1 数据类型
整数 十六进制和八进制使用0作为前缀,如 0x12f , 010浮点数 可以用科学计数法来表示很大或者很小的浮点数,如 1.23x10^9 可以写作 1.23e9 或者12.3e8 ,0.000012 ...
- Mysql锁机制--悲观锁和乐观锁
1. 悲观锁简介 悲观锁(Pessimistic Concurrency Control,缩写PCC),它指的是对数据被外界修改持保守态度,因此,在整个数据处理过程中, 将数据处于锁定状态.悲观锁的实 ...
- 关于Java Integer和Long直接比较
Integer和Long不能直接equals比较会返回False Long.class源码 ` public boolean equals(Object obj) { if (obj instance ...
- ATS push cache 测试
测试 ATS 注入缓存 参考了: http://serverfault.com/questions/471684/push-content-to-apache-traffic-servers-cach ...
- 网站开发学习Python实现-Django项目部署-同步之前写的博客(6.2.2)
@ 目录 1.说明 2.思路 3.代码 关于作者 1.说明 之前写的博客都在csdn和博客园中 要将博客同步到自己的博客网站中 因为都是使用markdown格式书写的,所以直接爬取上传就完事 2.思路 ...