GaussDB(DWS)应用实战:对被视图引用的表进行DDL操作
摘要:GaussDB(DWS)是从Postgres演进过来的,像Postgres一样,如果表被视图引用的话,特定场景下,部分DDL操作是不能直接执行的。
背景说明
GaussDB(DWS)是从Postgres演进过来的,像Postgres一样,如果表被视图引用的话,特定场景下,部分DDL操作是不能直接执行的,比如修改被视图引用的字段的类型,删除表等,而新增字段是可以操作,主要原因是视图引用了表的字段,修改的话视图也需要变化。下面稍微演示一下这部分内容,被视图引用的表进行DDL操作会有什么表现。然后再看看怎么操作才能修改表字段等。
生成实验内容
建2个测试表,3个测试视图,建的SQL语句如下,注意所有视图都是使用了t1的字段,没有使用t2的字段。
CREATE TABLE t1 (id int,name varchar(20));
CREATE TABLE t2 (id int,name varchar(20));
CREATE OR REPLACE VIEW v1 as select * from t1;
CREATE OR REPLACE VIEW v2 as select a.* from t1 a inner join t2 b on a.id = b.id;
CREATE OR REPLACE VIEW v3 as select a.* from v1 a inner join v2 b on a.id = b.id inner join t1 c on a.id = c.id;一、删除表
DROP TABLE t1;
DROP TABLE t2;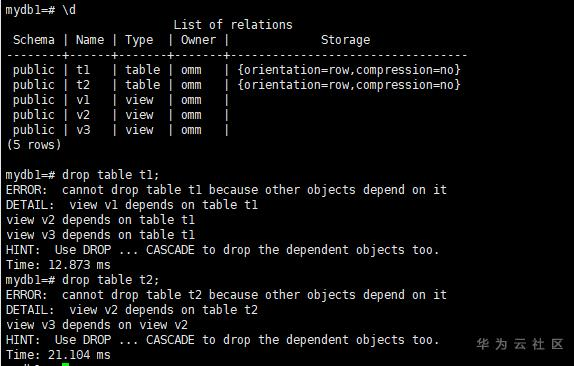
从执行结果提示来看,DROP TABLE是没有执行成功的,因为有视图依赖。可以通过DROP ...CASCADE来一起将依赖的视图删除,但是一般情况下我们不想将视图删除。
二、修改字段
ALTER TABLE T1 MODIFY NAME VARCHAR(30);
ALTER TABLE T2 MODIFY NAME VARCHAR(30);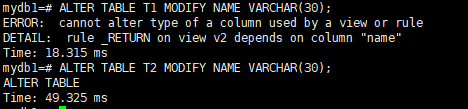
从执行结果的提示来看,t1表修改字段类型失败了,因为视图v2使用了这个字段,而t2表修改成功了,因为没有视图使用到t2的字段,虽然视图里面使用了t2表,但只是用来关联,视图的字段并没有使用t2表的字段,所以t2表的字段类型能修改成功。
为了后面实验能顺利实现目标,此处修改v2的视图,让其获取t2的字段
ALTER TABLE T2 MODIFY NAME VARCHAR(20);
CREATE OR REPLACE VIEW v2 as select b.* from t1 a inner join t2 b on a.id = b.id;三、新增字段
ALTER TABLE t1 ADD COMMENT VARCHAR(30);
ALTER TABLE t2 ADD COMMENT VARCHAR(30);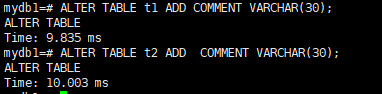
新增字段没有任何限制,因为视图建立的时候,没办法引用还没有的字段。我们审视视图的定义CREATE VIEW v1 AS SELECT * FROM t1; 那此时v1会有新增的字段信息吗?答案是否定的,视图需要重新刷新才会有新增的字段
select * from v2;
CREATE OR REPLACE VIEW v2 as select a.* from t1 a inner join t2 b on a.id = b.id;
select * from v2;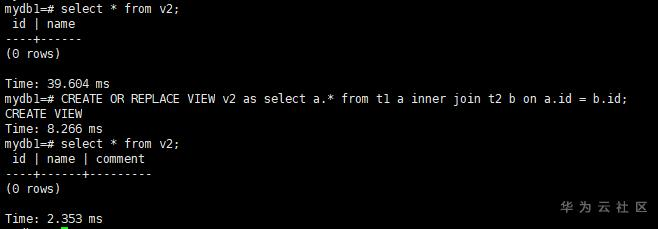
如何修改被视图引用的表定义?
那么问题来了,怎么样才能修改类似上面修改字段的修改被视图引用的表的定义呢?
我觉得可以分以下几步
备份视图定义到文本->备份表定义到文本->文本中修改表定义->备份表(ALTER TABLE XX RENAME TO XX_BAK)->新增修改后的表->插入数据->备份视图文本刷新视图
其中比较难获取的一个内容是,表被哪些视图引用?这里面需要使用pg_rewrite获取引用关系,以及with recursive .. as 循环获取。
一、备份视图定义到文本
先获取表设计到哪些视图,这个SQL稍微有点复杂,这里分几步来说明
通过pg_rewrite拿到表与视图的依赖关系
select c.nspname as schemaname,b.relname,rel_oid,b.relkind,d.oid as ori_oid,d.relname ori_name
from (
select unnest(regexp_matches(ev_action::text,':relid (\d+)', 'g'))::oid rel_oid,ev_class --rel_oid 被依赖对象 ,ev_class 视图名称
from pg_rewrite
union
select unnest(regexp_matches(ev_action::text,':resorigtbl (\d+)','g'))::oid,ev_class
from pg_rewrite
) deptbl --pg_write获取依赖关系
inner join pg_class b --被依赖对象获取表名等信息
on deptbl.rel_oid = b.oid
inner join pg_namespace c
on b.relnamespace = c.oid
inner join pg_class d --视图获取视图名等信息,且用于排除pg_write获取的自身对象,即rel_oid <> ev_class
on deptbl.ev_class = d.oid
and deptbl.rel_oid <> d.oid
where b.relname = 't2'; --指定表名t2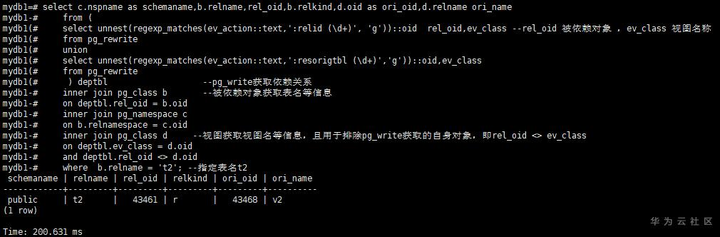
通过with recursive xx as循环语句获取所有相关视图
with recursive rec_view as (
select c.nspname as schemaname,b.relname,rel_oid,b.relkind,d.oid as ori_oid,d.relname ori_name
,0 as level --level防止死循环
from (
select unnest(regexp_matches(ev_action::text,':relid (\d+)', 'g'))::oid rel_oid,ev_class --rel_oid 被依赖对象 ,ev_class 视图名称
from pg_rewrite
union
select unnest(regexp_matches(ev_action::text,':resorigtbl (\d+)','g'))::oid,ev_class
from pg_rewrite
) deptbl --pg_write获取依赖关系
inner join pg_class b --被依赖对象获取表名等信息
on deptbl.rel_oid = b.oid
inner join pg_namespace c
on b.relnamespace = c.oid
inner join pg_class d --视图获取视图名等信息,且用于排除pg_write获取的自身对象,即rel_oid <> ev_class
on deptbl.ev_class = d.oid
and deptbl.rel_oid <> d.oid
where b.relname = 't2' --指定表名t2
union all
select c.nspname,b.relname,deptbl.rel_oid,b.relkind,d.oid as ori_oid,d.relname ori_name,level+1
from (
select unnest(regexp_matches(ev_action::text,':relid (\d+)', 'g'))::oid rel_oid,ev_class
from pg_rewrite
union
select unnest(regexp_matches(ev_action::text,':resorigtbl (\d+)','g'))::oid,ev_class
from pg_rewrite
) deptbl
inner join pg_class b
on deptbl.rel_oid = b.oid
inner join pg_namespace c
on b.relnamespace = c.oid
inner join pg_class d
on deptbl.ev_class = d.oid
and deptbl.rel_oid <> d.oid
inner join rec_view e --循环语句关联条件
on deptbl.rel_oid = e.ori_oid
where level <=10 --level防止死循环
)
select * from rec_view;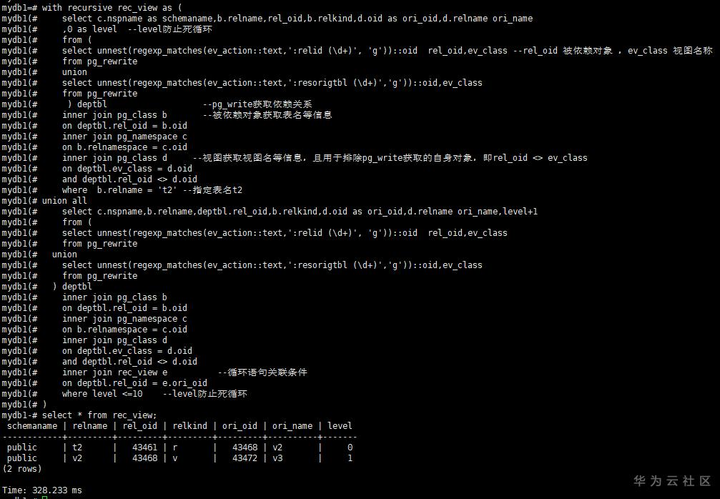
从结果看,t2所以相关视图是v2,v3两个视图。
拿到视图清单后,我们将v2,v3两个视图备份到文本中,使用gs_dump的方式。
gs_dump mydb1 -s -t v2 -t v3 -c -f view.ddl -p 25308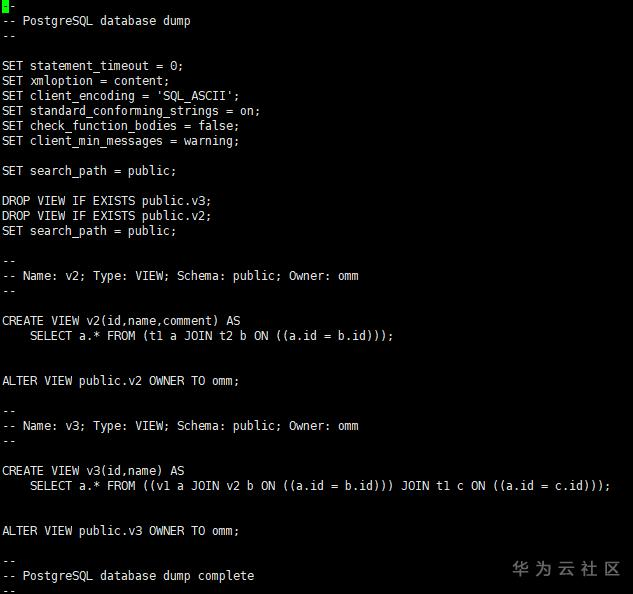
二、备份表定义到文本->文本中修改表定义->备份表(ALTER TABLE XX RENAME TO XX_BAK)->新增修改后的表并插入数据
备份表定义到文本:使用gs_dump将t2的表结构导出到文件
文本中修改表定义:将name的字段类型从原来的varchar(30)修改为varchar(50)
备份表(ALTER TABLE XX RENAME TO XX_BAK):在文本中增加ALTER TABLE RENAME动作
新增修改后的表并插入数据:在文本中增加插入数据SQL
gs_dump mydb1 -s -t t2 -f t2.ddl -p 25308上述内容修改后,结果如下图
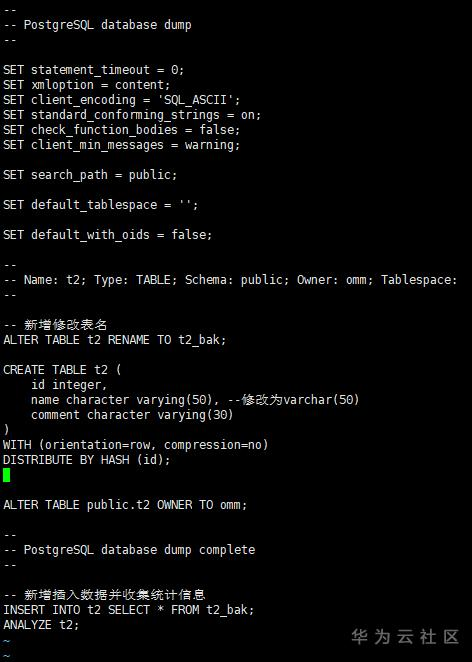
执行该文本语句
gsql -d mydb1 -p 25308 -r -f t2.ddl三、刷新视图
执行导出的v2,v3视图
gsql -d mydb1 -p 25308 -r -f view.ddl然后检查t2表是否修改了定义,并查看视图是否能够查询
\d t2
select * from v2;
select * from v3;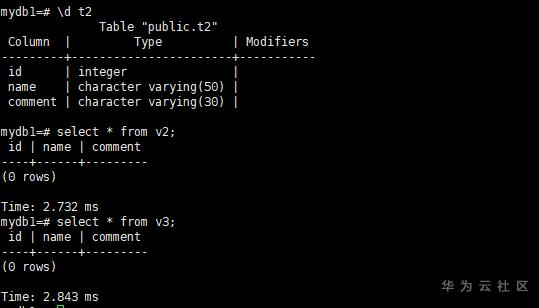
总结
因为视图使用表时会产生依赖关系,在修改被视图依赖的表的定义时,特定情况下是没办法修改的,这里我认为可以通过以下步骤来实现:备份视图定义到文本->备份表定义到文本->文本中修改表定义->备份表(ALTER TABLE XX RENAME TO XX_BAK)->新增修改后的表->插入数据->备份视图文本刷新视图
其中备份视图定义这一步,需要先知道你需要修改的表的相关视图是什么。这个查询的过程需要使用pg_rewrite表和with recursive xx as递归获取相关视图。获取到相关视图备份下来以后,剩下的步骤就比较简单了。
GaussDB(DWS)应用实战:对被视图引用的表进行DDL操作的更多相关文章
- 十八般武艺玩转GaussDB(DWS)性能调优:SQL改写
摘要:本文将系统介绍在GaussDB(DWS)系统中影响性能的坏味道SQL及SQL模式,帮助大家能够从原理层面尽快识别这些坏味道SQL,在调优过程中及时发现问题,进行整改. 数据库的应用中,充斥着坏味 ...
- 十八般武艺玩转GaussDB(DWS)性能调优:路径干预
摘要:路径生成是表关联方式确定的主要阶段,本文介绍了几个影响路径生成的要素:cost_param, scan方式,join方式,stream方式,并从原理上分析如何干预路径的生成. 一.cost模型选 ...
- 十八般武艺玩转GaussDB(DWS)性能调优(三):好味道表定义
摘要:表结构设计是数据库建模的一个关键环节,表定义好坏直接决定了集群的有效容量以及业务查询性能,本文从产品架构.功能实现以及业务特征的角度阐述在GaussDB(DWS)的中表定义时需要关注的一些关键因 ...
- 从数据仓库双集群系统模式探讨,看GaussDB(DWS)的容灾设计
摘要:本文主要是探讨OLAP关系型数据库框架的数据仓库平台如何设计双集群系统,即增强系统高可用的保障水准,然后讨论一下GaussDB(DWS)的容灾应该如何设计. 当前社会.企业运行当中,大数据分析. ...
- GaussDB(DWS)应用实践丨负载管理与作业排队处理方法
摘要:本文用来总结一些GaussDB(DWS)在实际应用过程中,可能出现的各种作业排队的情况,以及出现排队时,我们应该怎么去判断是否正常,调整一些参数,让资源分配与负载管理更符合当前的业务:或者在作业 ...
- 详解GaussDB(DWS) 资源监控
摘要:本文主要着重介绍资源池资源监控以及用户资源监控. 本文分享自华为云社区<GaussDB(DWS)资源监控之用户.队列资源监控>,作者: 一只菜菜鸟. GaussDB(DWS)资源监控 ...
- 详解GaussDB(DWS) explain分布式执行计划
摘要:本文主要介绍如何详细解读GaussDB(DWS)产生的分布式执行计划,从计划中发现性能调优点. 前言 执行计划(又称解释计划)是数据库执行SQL语句的具体步骤,例如通过索引还是全表扫描访问表中的 ...
- 由两个问题引发的对GaussDB(DWS)负载均衡的思考
摘要:GaussDB(DWS)的负载均衡通过LVS+keepAlived实现.对于这种方式,需要思考的问题是,CN的返回结果是否会经过LVS,然后再返回给前端应用?如果经过LVS,那么,LVS会不会成 ...
- 探索GaussDB(DWS)的过程化SQL语言能力
摘要:在当前GaussDB(DWS)的能力中主要支持两种过程化SQL语言,即基于PostgreSQL的PL/pgSQL以及基于Oracle的PL/SQL.本篇文章我们通过匿名块,函数,存储过程向大家介 ...
随机推荐
- C#LeetCode刷题之#35-搜索插入位置(Search Insert Position)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3979 访问. 给定一个排序数组和一个目标值,在数组中找到目标值, ...
- Vue 过滤器 Filter传递参数
给日期类型过滤器设置不同格式 dayjs是一款轻量级的日期操作库 https://day.js.org/en import Vue from 'vue' import dayjs from 'dayj ...
- Linux-Centos 用crontab定时运行python脚本详细步骤
服务器总是要定时运行某个程序,而我在解决这个问题的时候遇到很多困难, 特此记录下来. 1.编辑crontab配置 crontab -e 服务器一般会安装好crontab,若没有安装请按命令安装 yum ...
- 【POJ3071】Football - 状态压缩+期望 DP
Description Consider a single-elimination football tournament involving 2n teams, denoted 1, 2, …, 2 ...
- 【算法•日更•第二十七期】基础python
▎前言 看到这个题目,你一定会很好奇,为什么学打NOIP的要学习python?其实python对我们是很有用的! NOIP虽然不支持使用python提交代码,但是在NOILinux上天生自带pytho ...
- 【有向图】强连通分量-Tarjan算法
好久没写博客了(都怪作业太多,绝对不是我玩的太嗨了) 所以今天要写的是一个高大上的东西:强连通 首先,是一些强连通相关的定义 //来自度娘 1.强连通图(Strongly Connected Grap ...
- PythonCrashCourse 第十章习题
在文本编辑器中新建一个文件,写几句话来总结一下你至此学到的Python知识,其中每一行都以"In Python you can"打头.将这个文件命名为 learning_pytho ...
- Centos7第一安装后无法联网
- 什么?Java9这些史诗级更新你都不知道?Java9特性一文打尽!
「MoreThanJava」 宣扬的是 「学习,不止 CODE」,本系列 Java 基础教程是自己在结合各方面的知识之后,对 Java 基础的一个总回顾,旨在 「帮助新朋友快速高质量的学习」. 当然 ...
- Spark on Yarn运行时加载的jar包
spark on yarn运行时会加载的jar包有如下: spark-submit中指定的--jars $SPARK_HOME/jars下的jar包 yarn提供的jar包 spark-submit通 ...