scrapy 基础组件专题(九):scrapy-redis 源码分析
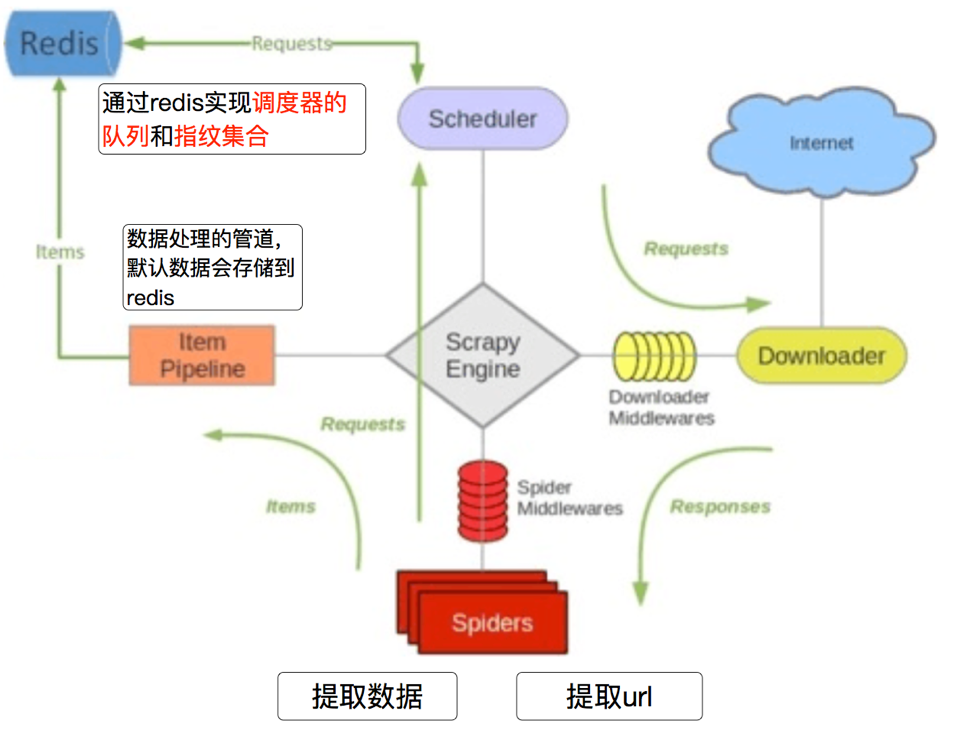
下面我们来看看,scrapy-redis的每一个源代码文件都实现了什么功能,最后如何实现分布式的爬虫系统:

connection.py 连接得配置文件
defaults.py 默认得配置文件
dupefilter.py 去重规则
picklecompat.py 格式化
pipelines.py 序列化变成字符串
queue.py 队列
scheduler.py 调度器
spiders.py 爬虫
utils.py 把字节转换成字符串
connect.py
import six from scrapy.utils.misc import load_object from . import defaults # Shortcut maps 'setting name' -> 'parmater name'.
SETTINGS_PARAMS_MAP = {
'REDIS_URL': 'url',
'REDIS_HOST': 'host',
'REDIS_PORT': 'port',
'REDIS_ENCODING': 'encoding',
} def get_redis_from_settings(settings):
"""Returns a redis client instance from given Scrapy settings object. This function uses ``get_client`` to instantiate the client and uses
``defaults.REDIS_PARAMS`` global as defaults values for the parameters. You
can override them using the ``REDIS_PARAMS`` setting. Parameters
----------
settings : Settings
A scrapy settings object. See the supported settings below. Returns
-------
server
Redis client instance. Other Parameters
----------------
REDIS_URL : str, optional
Server connection URL.
REDIS_HOST : str, optional
Server host.
REDIS_PORT : str, optional
Server port.
REDIS_ENCODING : str, optional
Data encoding.
REDIS_PARAMS : dict, optional
Additional client parameters. """
params = defaults.REDIS_PARAMS.copy()
params.update(settings.getdict('REDIS_PARAMS'))
# XXX: Deprecate REDIS_* settings.
for source, dest in SETTINGS_PARAMS_MAP.items():
val = settings.get(source)
if val:
params[dest] = val # Allow ``redis_cls`` to be a path to a class.
if isinstance(params.get('redis_cls'), six.string_types):
params['redis_cls'] = load_object(params['redis_cls']) return get_redis(**params) # Backwards compatible alias.
from_settings = get_redis_from_settings def get_redis(**kwargs):
"""Returns a redis client instance. Parameters
----------
redis_cls : class, optional
Defaults to ``redis.StrictRedis``.
url : str, optional
If given, ``redis_cls.from_url`` is used to instantiate the class.
**kwargs
Extra parameters to be passed to the ``redis_cls`` class. Returns
-------
server
Redis client instance. """
redis_cls = kwargs.pop('redis_cls', defaults.REDIS_CLS)
url = kwargs.pop('url', None)
if url:
return redis_cls.from_url(url, **kwargs)
else:
return redis_cls(**kwargs)
connect文件引入了redis模块,这个是redis-python库的接口,用于通过python访问redis数据库,主要是实现连接redis数据库的功能(返回的是reids库的Redis对象或者StrictRedis对象,这俩都是可以直接用来进行数据操作的对象)。这些连接接口在其他文件中经常被用到。其中,我们可以看到,要想连接到redis数据库,和其他数据库差不多,需要一个ip地址、端口号、用户名密码(可选)和一个整型的数据库编号,同时我们还可以再scrapy的settings文件中配置套接字的超时时间、等待时间等。
picklecompat.py
"""A pickle wrapper module with protocol=-1 by default.""" try:
import cPickle as pickle # PY2
except ImportError:
import pickle def loads(s):
return pickle.loads(s) def dumps(obj):
return pickle.dumps(obj, protocol=-1)
这里实现了loads和dumps两个函数,其实就是实现了一个serializer,因为redis数据库不能存储复杂对象(value部分只能是字符串,字符串列表,字符串集合和hash,key部分只能是字符串),所以我们存啥都要先串行化成文本才行。这里使用的就是python的pickle模块,一个兼容py2和py3的串行化工具。这个serializer主要用于一会的scheduler存reuqest对象,至于为什么不实用json格式,我也不是很懂,item pipeline的串行化默认用的就是json。
pipeline.py
from scrapy.utils.misc import load_object
from scrapy.utils.serialize import ScrapyJSONEncoder
from twisted.internet.threads import deferToThread from . import connection, defaults default_serialize = ScrapyJSONEncoder().encode class RedisPipeline(object):
"""Pushes serialized item into a redis list/queue Settings
--------
REDIS_ITEMS_KEY : str
Redis key where to store items.
REDIS_ITEMS_SERIALIZER : str
Object path to serializer function. """ def __init__(self, server,
key=defaults.PIPELINE_KEY,
serialize_func=default_serialize):
"""Initialize pipeline. Parameters
----------
server : StrictRedis
Redis client instance.
key : str
Redis key where to store items.
serialize_func : callable
Items serializer function. """
self.server = server
self.key = key
self.serialize = serialize_func @classmethod
def from_settings(cls, settings):
params = {
'server': connection.from_settings(settings),
}
if settings.get('REDIS_ITEMS_KEY'):
params['key'] = settings['REDIS_ITEMS_KEY']
if settings.get('REDIS_ITEMS_SERIALIZER'):
params['serialize_func'] = load_object(
settings['REDIS_ITEMS_SERIALIZER']
) return cls(**params) @classmethod
def from_crawler(cls, crawler):
return cls.from_settings(crawler.settings) def process_item(self, item, spider):
return deferToThread(self._process_item, item, spider) def _process_item(self, item, spider):
key = self.item_key(item, spider)
data = self.serialize(item)
self.server.rpush(key, data)
return item def item_key(self, item, spider):
"""Returns redis key based on given spider. Override this function to use a different key depending on the item
and/or spider. """
return self.key % {'spider': spider.name}
pipeline文件实现了一个item pipieline类,和scrapy的item pipeline是同一个对象,通过从settings中拿到我们配置的REDIS_ITEMS_KEY作为key,把item串行化之后存入redis数据库对应的value中(这个value可以看出出是个list,我们的每个item是这个list中的一个结点),这个pipeline把提取出的item存起来,主要是为了方便我们延后处理数据。
queue.py
支持三种队列, 都继承自Base类
1. FIFO Queue
使用了redis的list结构
class FifoQueue(Base):
def __len__(self):
"""返回队列长度大小"""
return self.server.llen(self.key) def push(self, request):
"""发送请求到队列左边"""
self.server.lpush(self.key, self._encode_request(request)) def pop(self, timeout=0):
"""从队列右边抛出请求"""
if timeout > 0:
data = self.server.brpop(self.key, timeout)
if isinstance(data, tuple):
data = data[1]
else:
data = self.server.rpop(self.key)
if data:
return self._decode_request(data)
2. PriorityQueue
使用了redis的有序集合结构
class PriorityQueue(Base):
def __len__(self):
"""返回队列内长度大小"""
return self.server.zcard(self.key)
def push(self, request):
"""放入请求到zset中"""
data = self._encode_request(request)
score = -request.priority
self.server.execute_command('ZADD', self.key, score, data)
def pop(self, timeout=0):
"""从zset中抛出请求. 此处不支持timeout参数"""
pipe = self.server.pipeline()
pipe.multi()
pipe.zrange(self.key, 0, 0).zremrangebyrank(self.key, 0, 0)
results, count = pipe.execute()
if results:
return self._decode_request(results[0])
使用redis的sorted set实现, 如果在spider脚本中需要指定priority的话, 一定要在settings中来声明使用的是PriorityQueue.
3. LIFO Queue
后入先出, 使用list结构实现
class LifoQueue(Base):
"""Per-spider LIFO queue.""" def __len__(self):
"""Return the length of the stack"""
return self.server.llen(self.key) def push(self, request):
"""Push a request"""
self.server.lpush(self.key, self._encode_request(request)) def pop(self, timeout=0):
"""Pop a request"""
if timeout > 0:
data = self.server.blpop(self.key, timeout)
if isinstance(data, tuple):
data = data[1]
else:
data = self.server.lpop(self.key) if data:
return self._decode_request(data)
和先进先出队列基本一样, 实现了栈结构
该文件实现了几个容器类,可以看这些容器和redis交互频繁,同时使用了我们上边picklecompat中定义的serializer。这个文件实现的几个容器大体相同,只不过一个是队列,一个是栈,一个是优先级队列,这三个容器到时候会被scheduler对象实例化,来实现request的调度。比如我们使用SpiderQueue最为调度队列的类型,到时候request的调度方法就是先进先出,而实用SpiderStack就是先进后出了。
我们可以仔细看看SpiderQueue的实现,他的push函数就和其他容器的一样,只不过push进去的request请求先被scrapy的接口request_to_dict变成了一个dict对象(因为request对象实在是比较复杂,有方法有属性不好串行化),之后使用picklecompat中的serializer串行化为字符串,然后使用一个特定的key存入redis中(该key在同一种spider中是相同的)。而调用pop时,其实就是从redis用那个特定的key去读其值(一个list),从list中读取最早进去的那个,于是就先进先出了。
这些容器类都会作为scheduler调度request的容器,scheduler在每个主机上都会实例化一个,并且和spider一一对应,所以分布式运行时会有一个spider的多个实例和一个scheduler的多个实例存在于不同的主机上,但是,因为scheduler都是用相同的容器,而这些容器都连接同一个redis服务器,又都使用spider名加queue来作为key读写数据,所以不同主机上的不同爬虫实例公用一个request调度池,实现了分布式爬虫之间的统一调度。
dupefilter.py
scrapy默认使用了集合结构来进行去重, 在scrapy-redis中使用redis的集合(set)进行了替换, 请求指纹的计算方法还是用的内置的.
def request_seen(self, request):
"""获取请求指纹并添加到redis的去重集合中去"""
fp = self.request_fingerprint(request) # 得到请求的指纹
added = self.server.sadd(self.key, fp) # 把指纹添加到redis的集合中
return added == 0 def request_fingerprint(self, request):
return request_fingerprint(request) # 得到请求指纹
去重指纹计算使用的是sha1算法, 计算值包括请求方法, url, body等信息
这个文件看起来比较复杂,重写了scrapy本身已经实现的request判重功能。因为本身scrapy单机跑的话,只需要读取内存中的request队列或者持久化的request队列(scrapy默认的持久化似乎是json格式的文件,不是数据库)就能判断这次要发出的request url是否已经请求过或者正在调度(本地读就行了)。而分布式跑的话,就需要各个主机上的scheduler都连接同一个数据库的同一个request池来判断这次的请求是否是重复的了。
在这个文件中,通过继承BaseDupeFilter重写他的方法,实现了基于redis的判重。根据源代码来看,scrapy-redis使用了scrapy本身的一个fingerprint接request_fingerprint,这个接口很有趣,根据scrapy文档所说,他通过hash来判断两个url是否相同(相同的url会生成相同的hash结果),但是当两个url的地址相同,get型参数相同但是顺序不同时,也会生成相同的hash结果(这个真的比较神奇。。。)所以scrapy-redis依旧使用url的fingerprint来判断request请求是否已经出现过。这个类通过连接redis,使用一个key来向redis的一个set中插入fingerprint(这个key对于同一种spider是相同的,redis是一个key-value的数据库,如果key是相同的,访问到的值就是相同的,这里使用spider名字+DupeFilter的key就是为了在不同主机上的不同爬虫实例,只要属于同一种spider,就会访问到同一个set,而这个set就是他们的url判重池),如果返回值为0,说明该set中该fingerprint已经存在(因为集合是没有重复值的),则返回False,如果返回值为1,说明添加了一个fingerprint到set中,则说明这个request没有重复,于是返回True,还顺便把新fingerprint加入到数据库中了。
DupeFilter判重会在scheduler类中用到,每一个request在进入调度之前都要进行判重,如果重复就不需要参加调度,直接舍弃就好了,不然就是白白浪费资源。
spider.py
spider空闲的时候会从start_urls队列中读取url, 默认一次读取CONCURRENT_REQUESTS个url, 可以在settings中设置REDIS_START_URLS_BATCH_SIZE来改变每次的读取数量, 一般我会在使用的时候增大这个值, 可以降低spide进入idle的次数, 从而适当提升抓取性能
def setup_redis(self, crawler=None):
"""初始化了redis参数, 包括使用的种子url的key, 批量读取url的数量等信息"""
......
# 当spider空闲的时候会触发该信号, 调用spider_idle函数
crawler.signals.connect(self.spider_idle, signal=signals.spider_idle) def spider_idle(self):
"""空闲的时候触发该函数, 尝试请求下一批url. 有url的时候会直接请求, 最后都会抛出异常, 防止spider被关闭, 然后等待新的url过来"""
self.schedule_next_requests()
raise DontCloseSpider
spider的改动也不是很大,主要是通过connect接口,给spider绑定了spider_idle信号,spider初始化时,通过setup_redis函数初始化好和redis的连接,之后通过next_requests函数从redis中取出strat url,使用的key是settings中REDIS_START_URLS_AS_SET定义的(注意了这里的初始化url池和我们上边的queue的url池不是一个东西,queue的池是用于调度的,初始化url池是存放入口url的,他们都存在redis中,但是使用不同的key来区分,就当成是不同的表吧),spider使用少量的start url,可以发展出很多新的url,这些url会进入scheduler进行判重和调度。直到spider跑到调度池内没有url的时候,会触发spider_idle信号,从而触发spider的next_requests函数,再次从redis的start url池中读取一些url。
总结:
crapy-redis的总体思路:这个工程通过重写scheduler和spider类,实现了调度、spider启动和redis的交互。
实现新的dupefilter和queue类,达到了判重和调度容器和redis的交互,因为每个主机上的爬虫进程都访问同一个redis数据库,所以调度和判重都统一进行统一管理,达到了分布式爬虫的目的。
当spider被初始化时,同时会初始化一个对应的scheduler对象,这个调度器对象通过读取settings,配置好自己的调度容器queue和判重工具dupefilter。
每当一个spider产出一个request的时候,scrapy内核会把这个reuqest递交给这个spider对应的scheduler对象进行调度,scheduler对象通过访问redis对request进行判重,如果不重复就把他添加进redis中的调度池。当调度条件满足时,scheduler对象就从redis的调度池中取出一个request发送给spider,让他爬取。当spider爬取的所有暂时可用url之后,scheduler发现这个spider对应的redis的调度池空了,于是触发信号spider_idle,spider收到这个信号之后,直接连接redis读取strart url池,拿去新的一批url入口,然后再次重复上边的工作
scrapy 基础组件专题(九):scrapy-redis 源码分析的更多相关文章
- Redis源码分析:serverCron - redis源码笔记
[redis源码分析]http://blog.csdn.net/column/details/redis-source.html Redis源代码重要目录 dict.c:也是很重要的两个文件,主要 ...
- redis源码分析之事务Transaction(下)
接着上一篇,这篇文章分析一下redis事务操作中multi,exec,discard三个核心命令. 原文地址:http://www.jianshu.com/p/e22615586595 看本篇文章前需 ...
- redis源码分析之有序集SortedSet
有序集SortedSet算是redis中一个很有特色的数据结构,通过这篇文章来总结一下这块知识点. 原文地址:http://www.jianshu.com/p/75ca5a359f9f 一.有序集So ...
- Redis源码分析系列
0.前言 Redis目前热门NoSQL内存数据库,代码量不是很大,本系列是本人阅读Redis源码时记录的笔记,由于时间仓促和水平有限,文中难免会有错误之处,欢迎读者指出,共同学习进步,本文使用的Red ...
- redis源码分析之发布订阅(pub/sub)
redis算是缓存界的老大哥了,最近做的事情对redis依赖较多,使用了里面的发布订阅功能,事务功能以及SortedSet等数据结构,后面准备好好学习总结一下redis的一些知识点. 原文地址:htt ...
- redis源码分析之事务Transaction(上)
这周学习了一下redis事务功能的实现原理,本来是想用一篇文章进行总结的,写完以后发现这块内容比较多,而且多个命令之间又互相依赖,放在一篇文章里一方面篇幅会比较大,另一方面文章组织结构会比较乱,不容易 ...
- Redis源码分析(intset)
源码版本:4.0.1 源码位置: intset.h:数据结构的定义 intset.c:创建.增删等操作实现 1. 整数集合简介 intset是Redis内存数据结构之一,和之前的 sds. skipl ...
- Redis源码分析(dict)
源码版本:redis-4.0.1 源码位置: dict.h:dictEntry.dictht.dict等数据结构定义. dict.c:创建.插入.查找等功能实现. 一.dict 简介 dict (di ...
- 【SpringCloud技术专题】「Eureka源码分析」从源码层面让你认识Eureka工作流程和运作机制(上)
前言介绍 了解到了SpringCloud,大家都应该知道注册中心,而对于我们从过去到现在,SpringCloud中用的最多的注册中心就是Eureka了,所以深入Eureka的原理和源码,接下来我们要进 ...
- scrapy 基础组件专题(十四):scrapy CookiesMiddleware源码
一 Scrapy框架--cookie的获取/传递/本地保存 1. 完成模拟登陆2. 登陆成功后提取出cookie,然后保存到本地cookie.txt文件中3. 再次使用时从本地的cookie.txt中 ...
随机推荐
- Dedecms 目标仿站的学习视频
目标网站首页的初步仿制(实站仿站)http://vodcdn.video.taobao.com/player/ugc/tb_ugc_bytes_core_player_loader.swf 目标网站首 ...
- 分享我在前后端分离项目中Gitlab-CI的经验
长话短说,今天分享我为前后端分离项目搭建Gitlab CI/CD流程的一些额外经验. Before Gitlab-ci是Gitlab提供的CI/CD特性,结合Gitlab简单友好的配置界面,能愉悦的在 ...
- Modern C++
microsoft: Modern C++ 目录 1. auto 关键字 2. 智能指针(smart pointers) 3. std::string & std::string_view 4 ...
- 小师妹学JavaIO之:用Selector来发好人卡
目录 简介 Selector介绍 创建Selector 注册Selector到Channel中 SelectionKey selector 和 SelectionKey 总的例子 总结 简介 NIO有 ...
- 【Java入门】JDK安装和环境变量配置(Win7版)
系统环境:Windows7 x64 安装JDK和JRE版本:1.8.0_191 1.下载JDK安装包 Oracle官网下载网址:https://www.oracle.com/technetwork/j ...
- LR脚本信息函数-lr_get_master_host_name
lr_get_master_host_name() 返回Controller主机的名称. char * lr_get_master_host_name(); lr_get_master_host_na ...
- mysql日期和时间类型
TIME 类型 TIME 类型用于只需要时间信息的值,在存储时需要 3 个字节.格式为 HH:MM:SS.HH 表示小时,MM 表示分钟,SS 表示秒. TIME 类型的取值范围为 -838:59:5 ...
- cc4a-c++类定义与struct定义方式代码示范
cc4a-c++类定义与struct定义方式代码示范 #include <iostream> #include <string> using namespace std; st ...
- XP系统无法进入界面 不断的反复重启-解决方法
XP系统无法进入界面 不断的反复重启-解决方法 XP系统无法进入界面 不断的反复重启-解决方法 一般都是非正常关机导致磁盘受到损坏.需要修复磁盘. 1.插入带PE的u盘,进入PE系统后 2.win+R ...
- set dict tuple 内置方法
今日内容 * 元祖及内置方法* 字典及内置方法* 集合及内置方法* 字符编码 元祖tuple 与列表类似可以存多个值,但是不同的是元祖本身不能被修改 ```python一:基本使用:tuple 1 用 ...