IO - 同步,异步,阻塞,非阻塞 (亡羊补牢篇)【转】
同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别?
详细请看下链接:
IO - 同步,异步,阻塞,非阻塞 (亡羊补牢篇)
为了方便阅读,我重新编版,摘抄如下:
当你发现自己最受欢迎的一篇blog其实大错特错时,这绝对不是一件让人愉悦的事。
《IO - 同步,异步,阻塞,非阻塞 》是我在开始学习epoll和libevent的时候写的,主要的思路来自于文中的那篇link 。写完之后发现很多人都很喜欢,我还是非常开心的,也说明这个问题确实困扰了很多人。随着学习的深入,渐渐的感觉原来的理解有些偏差,但是还是没引起自己的重视,觉着都是一些小错误,无伤大雅。直到有位博友问了一个问题,我重新查阅了一些更权威的资料,才发现原来的文章中有很大的理论错误。我不知道有多少人已经看过这篇blog并受到了我的误导,鄙人在此表示抱歉。俺以后写技术blog会更加严谨的。
一度想把原文删了,最后还是没舍得。毕竟每篇blog都花费了不少心血,另外放在那里也可以引以为戒。所以这里新补一篇。算是亡羊补牢吧。
言归正传!!!
同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别?这个问题其实不同的人给出的答案都可能不同,比如wiki,就认为asynchronous IO和non-blocking IO是一个东西。这其实是因为不同的人的知识背景不同,并且在讨论这个问题的时候上下文(context)也不相同。所以,为了更好的回答这个问题,我先限定一下本文的上下文。
本文讨论的背景是Linux环境下的network IO。
本文最重要的参考文献是Richard Stevens的“UNIX Network Programming Volume 1, Third Edition: The Sockets Networking ”,6.2节“I/O Models ”,Stevens在这节中详细说明了各种IO的特点和区别,如果英文够好的话,推荐直接阅读。Stevens的文风是有名的深入浅出,所以不用担心看不懂。本文中的流程图也是截取自参考文献。
Stevens在文章中一共比较了五种IO Model:
- blocking IO
- nonblocking IO
- IO multiplexing
- signal driven IO
- asynchronous IO
由于signal driven IO在实际中并不常用,所以我这只提及剩下的四种IO Model。
再说一下IO发生时涉及的对象和步骤。
对于一个network IO (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段:
1、 等待数据准备 (Waiting for the data to be ready)
2、 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
记住这两点很重要,因为这些IO Model的区别就是在两个阶段上各有不同的情况。
一、blocking IO
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:

当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
二、non-blocking IO
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
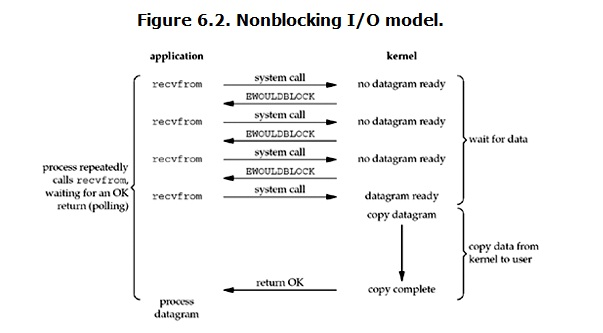
从图中可以看出,当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
所以,用户进程其实是需要不断的主动询问kernel数据好了没有。
三、IO multiplexing
IO multiplexing这个词可能有点陌生,但是如果我说select,epoll,大概就都能明白了。有些地方也称这种IO方式为event driven IO。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
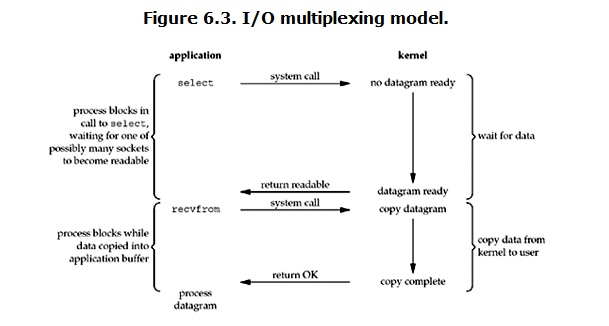
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。这个图和blocking IO的图其实并没有太大的不同,事实上,还更差一些。因为这里需要使用两个system call (select 和 recvfrom),而blocking IO只调用了一个system call (recvfrom)。但是,用select的优势在于它可以同时处理多个connection。(多说一句。所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)
在IO multiplexing Model中,实际中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
四、Asynchronous I/O
linux下的asynchronous IO其实用得很少。先看一下它的流程:

用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
为了方便大家理解下面说的内容,我特此将这个图提前放在这里,大家可以先对照着上面四张图,进一步梳理自己的理解,看和下面博主说的是否一致:
各个IO Model的比较如图所示:

到目前为止,已经将四个IO Model都介绍完了。现在回过头来回答最初的那几个问题:blocking和non-blocking的区别在哪,synchronous IO和asynchronous IO的区别在哪?
先回答最简单的这个:blocking vs non-blocking。前面的介绍中其实已经很明确的说明了这两者的区别。调用blocking IO会一直block住对应的进程直到操作完成,而non-blocking IO在kernel还准备数据的情况下会立刻返回。
在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。Stevens给出的定义(其实是POSIX的定义)是这样子的:
A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
An asynchronous I/O operation does not cause the requesting process to be blocked;
两者的区别就在于synchronous IO做”IO operation”的时候会将process阻塞。按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。有人可能会说,non-blocking IO并没有被block啊。这里有个非常“狡猾”的地方,定义中所指的”IO operation”是指真实的IO操作,就是例子中的recvfrom这个system call。non-blocking IO在执行recvfrom这个system call的时候,如果kernel的数据没有准备好,这时候不会block进程。但是,当kernel中数据准备好的时候,recvfrom会将数据从kernel拷贝到用户内存中,这个时候进程是被block了,在这段时间内,进程是被block的。而asynchronous IO则不一样,当进程发起IO 操作之后,就直接返回再也不理睬了,直到kernel发送一个信号,告诉进程说IO完成。在这整个过程中,进程完全没有被block。
经过上面的介绍,会发现non-blocking IO和asynchronous IO的区别还是很明显的。在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
最后,再举几个不是很恰当的例子来说明这四个IO Model:
有A,B,C,D四个人在钓鱼:
A用的是最老式的鱼竿,所以呢,得一直守着,等到鱼上钩了再拉杆;
B的鱼竿有个功能,能够显示是否有鱼上钩,所以呢,B就和旁边的MM聊天,隔会再看看有没有鱼上钩,有的话就迅速拉杆;
C用的鱼竿和B差不多,但他想了一个好办法,就是同时放好几根鱼竿,然后守在旁边,一旦有显示说鱼上钩了,它就将对应的鱼竿拉起来;
D是个有钱人,干脆雇了一个人帮他钓鱼,一旦那个人把鱼钓上来了,就给D发个短信。
-----------------------
个人觉得这个例子还是挺好理解的,单纯就理解楼主说的问题,还可以举例做饭等例。
真心感谢原博主!!!
Over...
IO - 同步,异步,阻塞,非阻塞 (亡羊补牢篇)【转】的更多相关文章
- 【转载】高性能IO设计 & Java NIO & 同步/异步 阻塞/非阻塞 Reactor/Proactor
开始准备看Java NIO的,这篇文章:http://xly1981.iteye.com/blog/1735862 里面提到了这篇文章 http://xmuzyq.iteye.com/blog/783 ...
- 关于IO的同步,异步,阻塞,非阻塞
上次写了一篇文章:Unix IO 模型学习.恰巧在这次周会的时候,@fp1203 (goldendoc成员之一) 正好在讲解poll和epoll的底层实现.中途正好讨论了网络IO的同步.异步.阻塞.非 ...
- 谈谈对不同I/O模型的理解 (阻塞/非阻塞IO,同步/异步IO)
一.关于I/O模型的问题 最近通过对ucore操作系统的学习,让我打开了操作系统内核这一黑盒子,与之前所学知识结合起来,解答了长久以来困扰我的关于I/O的一些问题. 1. 为什么redis能以单工作线 ...
- 哪5种IO模型?什么是select/poll/epoll?同步异步阻塞非阻塞有啥区别?全在这讲明白了!
系统中有哪5种IO模型?什么是 select/poll/epoll?同步异步阻塞非阻塞有啥区别? 本文地址http://yangjianyong.cn/?p=84转载无需经过作者本人授权 先解开第一个 ...
- 高性能IO设计模式之阻塞/非阻塞,同步/异步解析
提到高性能,我想大家都喜欢这个,今天我们就主要来弄明白在高性能的I/O设计中的几个关键概念,做任何事最重要的第一步就是要把概念弄的清晰无误不是么?在这里就是:阻塞,非阻塞,同步,异步. OK, 现在来 ...
- Python之路(第三十六篇)并发编程:进程、同步异步、阻塞非阻塞
一.理论基础 进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一.操作系统的其他所有内容都是围绕进程的概念展开的. 即使可以利用的cpu只有一个(早期的 ...
- 操作系统介绍-操作系统历史,IO,进程的三态,同步异步阻塞非阻塞
1.操作系统历史 2.进程,IO,同步异步阻塞非阻塞 操作系统历史: 手工操作: 1946年第一台计算机诞生--20世纪50年代中期,计算机工作还在采用手工操作方式.此时还没有操作系统的概念. 手工操 ...
- linux基础编程:IO模型:阻塞/非阻塞/IO复用 同步/异步 Select/Epoll/AIO(转载)
IO概念 Linux的内核将所有外部设备都可以看做一个文件来操作.那么我们对与外部设备的操作都可以看做对文件进行操作.我们对一个文件的读写,都通过调用内核提供的系统调用:内核给我们返回一个file ...
- 理解同步,异步,阻塞,非阻塞,多路复用,事件驱动IO
以下是IO的一个基本过程 先理解一下用户空间和内核空间,系统为了保护内核数据,会将寻址空间分为用户空间和内核空间,32位机器为例,高1G字节作为内核空间,低3G字节作为用户空间.当用户程序读取数据的时 ...
- (转)同步异步,阻塞非阻塞 和nginx的IO模型
同步异步,阻塞非阻塞 和nginx的IO模型 原文:https://www.cnblogs.com/wxl-dede/p/5134636.html 同步与异步 同步和异步关注的是消息通信机制 (sy ...
随机推荐
- powershell中的cmdlet命令
Add-Computer 向域或工作组中添加计算机. Add-Content 向指定的项中添加内容,如向文件中添加字词. Add-History 向会话历史记录追加条目. Add-Member 向 W ...
- Python编程小技巧(一)
在使用Tkinter编写代码的时候,有时候会忘记某个组件的参数是什么或者忘记某个参数怎么拼写的,此时可以通过如下方式查询组件的参数列表,以按钮组件为例: 1 # -*- coding:utf-8 -* ...
- Java程序入门
编写Java源程序 在d:\day01 目录下新建文本文件,完整的文件名修改为HelloWorld.java ,其中文件名为HelloWorld ,后缀名必须为.java . 用记事本打开 在文件中键 ...
- Python设计模式面向对象编程
前言 本篇文章是基于极客时间王争的<设计模式之美>做的总结和自己的理解. 说到面向对象编程,作为一个合格的Pythoner,可以说信手拈来.毕竟在Python里"万物都是对 ...
- node集群(cluster)
使用例子 为了让node应用能够在多核服务器中提高性能,node提供cluster API,用于创建多个工作进程,然后由这些工作进程并行处理请求. // master.js const cluster ...
- 2、剑指offer-字符串——替换空格
**题目描述** **请实现一个函数,将一个字符串中的每个空格替换成"%20".例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy. ...
- 【PostgreSQL】PostgreSQL数据库浅析
前言 工作中数据库用的不多,大部分都是简单查询一下了事,某项目中突然要求后端进行比较全面的数据库操作,现对自己学到的东西做一下总结. 简介 废话不多说,上官网地址: PostgreSQL 9.4.4 ...
- 【SVN】windows 下的SVN常见问题及其解决方法
1.能提交和更新,但SVN查看log时提示:找不到路径 'svn/XXXX' 双击以清除错误信息 勾选这个选项就好了.因为该路径是通过重命名或者拷贝过来的,倘若不选中,SVN便会尝试同时从当前文件的拷 ...
- 扩展欧几里得(exgcd)及其应用
定义 扩展欧几里得算法是用来在已知一组 \((a,b)\) 的时,求解一组 \((x,y)\) 使得 \[ax+by=gcd(a,b) \] 思想 and 板子 根据相关的知识可以得到 \[gcd(a ...
- cdq分治 笔记
算法讲解 这个算法用于解决三维偏序问题. 三维偏序:给定 \(n\) 个三元组: \((a_i,b_i,c_i)\),求同时满足满足 \(a_i\le a_j,b_i\le b_j,c_i\le c_ ...