手把手教你玩转Git
文章已托管到GitHub,大家可以去GitHub查看下载!并搜索关注微信公众号 码出Offer 领取各种学习资料!

Git应用
一、初识Git
1.1 Git的简史
同生活中的许多伟大事物一样,Git 诞生于一个极富纷争大举创新的年代。
Linus在1991年创建了开源的Linux,Linux 内核开源项目有着为数众多的参与者。 绝大多数的 Linux 内核维护工作都花在了提交补丁和保存归档的繁琐事务上(1991-2002年间)。 到 2002 年,整个项目组开始启用一个专有的分布式版本控制系统 BitKeeper 来管理和维护代码。 到了 2005 年,开发Samba的Andrew试图破解BitKeeper的协议,随后开发 BitKeeper 的商业公司同 Linux 内核开源社区的合作关系结束,他们收回了 Linux 内核社区免费使用 BitKeeper 的权力。 这就迫使 Linux 开源社区(特别是 Linux 的缔造者 Linus Torvalds)基于使用 BitKeeper 时的经验教训,Linus仅仅使用了两周的时间用C写出了Git,开发出自己的版本系统,一个月之内,Linux系统的源码已经由Git管理了。 他们对新的系统制订了若干目标:
- 速度
- 简单的设计
- 对非线性开发模式的强力支持(允许成千上万个并行开发的分支)
- 完全分布式
- 有能力高效管理类似 Linux 内核一样的超大规模项目(速度和数据量)
自诞生于 2005 年以来,Git 日臻成熟完善,在高度易用的同时,仍然保留着初期设定的目标。 它的速度飞快,极其适合管理大项目,有着令人难以置信的非线性分支管理系统。Git迅速成为最流行的分布式版本控制系统,尤其是2008年,GitHub网站上线了,它为开源项目免费提供Git存储,无数开源项目开始迁移至GitHub。
这时候是不是有很多小伙伴已经被Linus所惊讶到了呢?使用了两周时间用C写出了Git!
1.2 Git到底是什么?
Git是一个开源的
分布式版本控制系统,可以有效、高速地处理从很小到非常大的项目版本管理
1.3 什么是版本控制系统?
版本控制是指对软件开发过程中各种程序代码、配置文件及说明文档等文件变更的管理,是软件配置管理的核心思想之一。
1.3.1 版本控制系统的作用
版本控制最主要的功能就是追踪文件的变更。它将什么时候、什么人更改了文件的什么内容等信息忠实地了记录下来。每一次文件的改变,文件的版本号都将增加。除了记录版本变更外,版本控制的另一个重要功能是并行开发。软件开发往往是多人协同作业,版本控制可以有效地解决版本的同步以及不同开发者之间的开发通信问题,提高协同开发的效率。并行开发中最常见的不同版本软件的错误(Bug)修正问题也可以通过版本控制中分支与合并的方法有效地解决。
版本控制系统不仅为我们解决了实际开发中多人协同开发的问题,还提供了一些功能:检入检出控制 、分支和合并 、历史记录
检入检出控制:同步控制的实质是版本的检入检出控制。检入就是把软件配置项从用户的工作环境存入到软件配置库的过程,检出就是把软件配置项从软件配置库中取出的过程。检人是检出的逆过程。同步控制可用来确保由不同的人并发执行的修改不会产生混乱。分支与合并:版本分支(以一个已有分支的特定版本为起点,但是独立发展的版本序列)的人工方法就是从主版本——称为主干上拷贝一份,并做上标记。在实行了版本控制后,版本的分支也是一份拷贝,这时的拷贝过程和标记动作由版本控制系统完成。版本合并(来自不同分支的两个版本合并为其中一个分支的新版本)有两种途径,一是将版本A的内容附加到版本B中;另一种是合并版本A和版本B的内容,形成新的版本C。历史记录:版本的历史记录有助于对软件配置项进行审核,有助于追踪问题的来源。历史记录包括版本号、版本修改时间、版本修改者、版本修改描述等最基本的内容,还可以有其他一些辅助性内容,比如版本的文件大小和读写属性。 如果我们开发中的新版本发现不适合用户的体验,这时候就可以找到历史记录的响应版本号,回退到历史记录版本!
1.4 版本控制系统的分类(了解)
常见流行的分布式版本控制管理系统有Git
常见流行的集中式版本控制管理系统有CVS、SVN
| 代 | 网络 | 操作 | 并发性 | 示例 |
|---|---|---|---|---|
| 第一代 | 无 | 仅一个文件 | 锁定的 | RCS、SCCS |
| 第二代 | 集中式 | 多文件 | 提交之前合并 | CVS、SourceSafe、Subversion、Team Foundation Server |
| 第三代 | 分布式 | 变更的集合 | 合并之前提交 | Bazaar、Git、Mercurial |
1.5 分布式与集中式
1.5.1 集中式
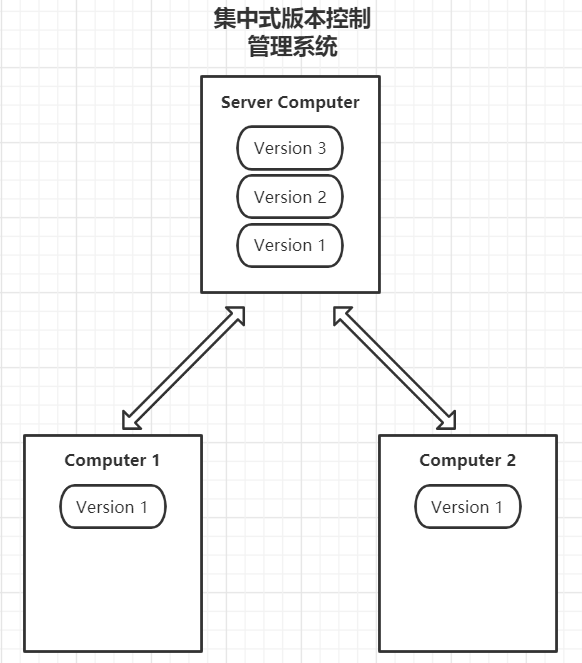
集中式系统是指由一台或多台主计算机组成的中心节点,数据集中存储于这个中心节点中,并且整个系统的所有业务单元都集中部署在这个中心节点上,系统的所有功能均由其集中处理。简单提了集中式的概念,那集中式版本控制也是如此。如图,我们需要合并版本、更新版本时,是将各个版本上传服务器实现集中式合并!
举例来说,集中式版本控制系统在公司中的使用,需要安装一个Server(服务器),然后各个使用版本控制系统的成员安装客户端,然后就是客户端连接服务器了,只有脸上这个服务器才能做版本控制,如果连不上那就不行了。
工作流程: 比较熟悉的SVN是集中式的版本控制系统,每次在进行版本控制之前,需要先从中央服务器(服务端)取出最新的版本,然后开始工作,工作完后推送给中央服务器。此时的中央服务器就好比是一个图书馆,如果你要修改一本书,需要先从图书馆借出来,然后回到自己家修改,改完之后,需要在送回到图书馆。
1.5.2 分布式
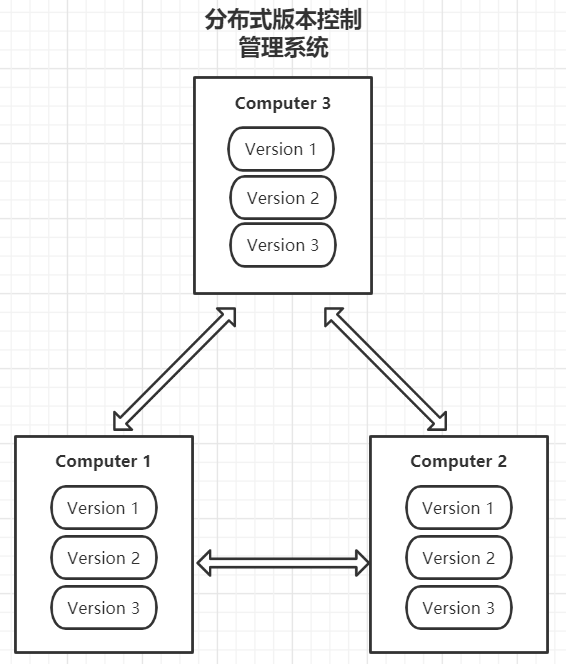
分布式系统是一个硬件或软件组件分布在不同的网络计算机上(本地化存储),彼此之间仅仅通过消息传递进行通信和协调的系统。又一次简单提了分布式的概念,那分布式版本控制更是如此。如图,我们需要合并版本、更新版本时,各台计算机都可以去实现彼此之间合并、更新,不再只依赖于一个中心节点,为我们开发提供了灵活与便捷!
举例来说,分布式版本控制系统在公司中的使用与集中式不同,各个成员需要安装一个Git客户端,而各个成员之间可以随时随地的实现版本控制(比如:两个人合并后,再与第三个人合并或者小组与小组之间合并进行版本控制),不再依赖于必须连接服务器才能实现,那么我们实现了各个小组之间的灵活控制后,最终还是得落到了服务器的手中。我们需要把各个成员、小组之间的版本控制结果,上传到服务器(GitHub)中进行最终合并!
工作流程: 分布式版本控制系统是没有“中央服务器”,每个人的电脑上都是一个完整的版本库,工作的时候,不再需要联网。开始工作前,在客户端克隆出完整的代码仓库,然后就可以在家、在公交车等等随心所欲地修改代码并提交了,提交到本地电脑,等到有网的时候就可以一次性地将本地仓库推送到远端仓库(临时中心服务器)中,这样一来,每个人都可以独立进行改动资料,并且所有的改动都是在完整资料信息的环境下进行的。
1.5.3 分布式与集中式的区别
集中式
- 有一个单一的集中管理的服务器,保存所有文件的修订版本,所有代码库。
- 对网络的依赖性强,必须联网才能工作,上传速度受网络状况、带宽影响。
- 客户端记录文件内容的具体差异,每次记录有哪些文件做了更新,以及更新了哪些行的什么内容。
缺点: 中央服务器的单点故障。 如果中央服务器发生宕机,所有客户端将无法提交更新、还原、对比等,也就无法协同工作。如果磁盘发生故障,信息尚无备份,还会有数据丢失的风险。
分布式
- 本地客户机进行操作,离线工作,快速。
- 安全性高,每个人电脑里都有完整的版本库,如果电脑发生了更换复制一份就可以。
- 原子性提交,提交不会被打断(git)。
- 工作模式非常灵活(传统的集中式工作流 + 特殊工作流 + 特殊工作流和集中式工作流的组合)。
缺点: 缺少权限管理、命令复杂混乱
1.6 Git的下载安装
Git官网下载:https://git-scm.com/
TortoiseGit官网下载:https://tortoisegit.org/
Git文档下载:https://git-scm.com/book/zh/v2
Git详细安装教程参考:https://blog.csdn.net/weixin_44170221/article/details/104490352
注意: 关于Git的可视化工具下载与否取决于自己,笔者不建议下载可视化工具,因为我们要大量使用并熟练使用命令来操作Git!
| Git客户端下载 | Git可视化工具下载 |
|---|---|
 |
 |
1.7 安装后测试
1.7.1 打开命令的两种方式
- Wins+R输入cmd打开Dos命令窗口
- 右键单击打开Git Bash Here窗口
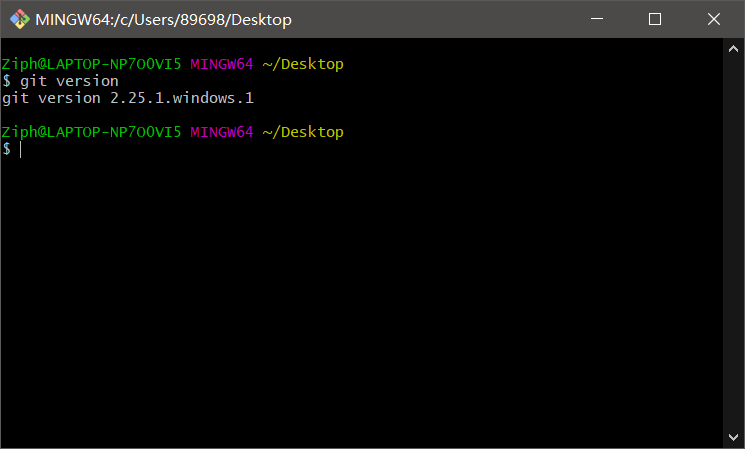
1.7.3 命令查看Git版本号
@查看Git版本号:
git version
1.7.2 提交版本控制人信息
安装后打开命令窗口,第一次需要提交我们的信息,这样可以让我们在版本控制的时候知道是谁做的这一次的版本控制。毕竟合并、更新代码等是一件很重要的事,万一缺失损坏了怎么办呢?是吧!
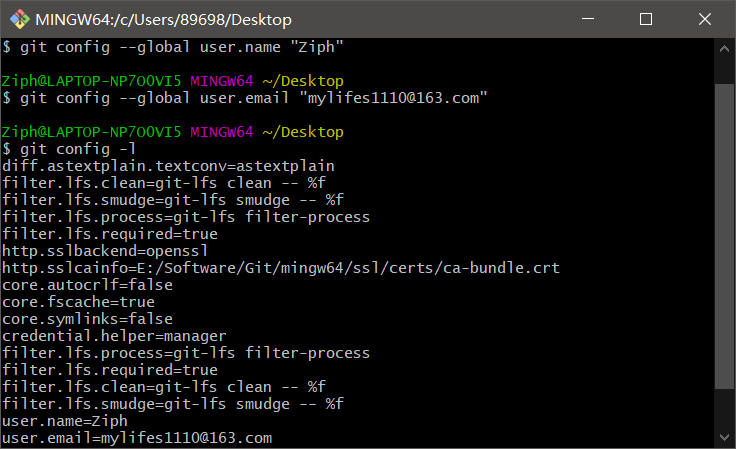
@提交信息版本操作者信息:
git config --global user.name "Ziph"【用户名】
git config --global user.email "mylifes1110@163.com"【邮箱】@查看信息:
git config -l
二、仓库
2.1 仓库是什么?
版本库又名仓库,英文名repository,你可以简单理解成一个目录,这个目录里面的所有文件都可以被Git管理起来,每个文件的修改、删除,Git都能跟踪,以便任何时刻都可以追踪历史,或者在将来某个时刻可以“还原”。
2.2 基本结构
工作区: 由我们使用命令
git init初始化的一个本地文件夹,而初始化后的这个文件夹就被称为工作区暂存区: 由我们使用命令
git add .把文件添加到暂存区,而被添加的位置则是工作区中.git目录中的index文件,所以这也叫做索引版本库: 工作区中会有一个隐藏的.git文件夹,这个不算是工作区,而是Git的版本库,版本库中记录了我们提交过的所有版本,也就是说版本库管理着我们的所有内容
分支: 版本库中包含若干分支,提交后的文件就会存储在分支中,而开始的时候版本库中只会有一个主分支master
| 基本结构 |
|---|
 |
| 工作区-版本库-暂存区-分支 |
 |
2.3 仓库基本命令操作
我们在使用git来管理本地仓库时,每次对工作区中的内容做的任何变化都需要add(添加)和commit(提交)操作来同步git版本库,只有做了添加和提交操作git才能管理我们的工作区。
@创建版本库: 创建或找到一个文件夹,打开命令窗口,执行
git init初始化本地工作区,在该工作区内会初始化生成一个.get目录,而该目录就是版本库,它保存着仓库的所有信息@添加一个文件: 在工作区中放入一个文件,然后在命令行窗口中执行
git add 文件名即可向工作区中添加一个文件@添加多个文件: 在工作区中放入多个文件,然后在命令行窗口中执行
git add 文件名1 文件名2 ...即可向工作区中添加多个文件@添加文件夹内容: 在工作区中放入一个文件夹,然而文件夹中有很多文件,打开命令行窗口执行
git add 文件夹名即可向工作区中添加该文件夹以及文件夹内的所有内容@添加工作区内所有内容: 如果工作区中有很多文件夹和文件,我们一个或多个添加很麻烦,我们可以使用
git add .命令来添加工作区中的所有内容@提交某些文件: 使用
git commit 文件名1 文件名2 -m "本次提交的描述信息",注意提交的描述信息是为了记录本次提交而方便查找,所以尽量能明确反映本次提交@提交所有文件: 使用
git commit -m "本次提交的描述信息"命令来提交文件,提交后的文件就由git来管理了。-m 后面双引号中的内容,这描述这次提交的信息,以便以后我们后续找到这次提交再做操作@修补提交: 提交后发现有问题,比如释忘记修改,⽐如提交描述不够详细等等。我们可以执行
git commit --amend -m"描述信息"来再次提交替换上次提交@添加并提交文件: 使用
git commit -a -m "本次添加并提交的描述信息"命令来自动添加和提交所有文件@删除文件: 使用命令
git rm 文件名来删除文件,并使用git commit 文件名 -m "描述信息"来提交这次删除的文件(了解即可)@文件删除和修改: 关于向git提交后的文件,删除和修改我们只需要重新提交即可。也就是说,我们挪动或删除了工作区中的文件或更改了工作区中的目录结构,都需要重新向git添加和提交你所变动的文件。
@文件状态: 关于如何查看我们添加或提交了哪些文件、还是只添加了文件没有把它提交。查看文件状态需要使用
git status命令查看文件的状态@查看该文件的改动情况: 使用
git diff 文件名命令来查看该⽂件的改动情况@帮助: 使用
git help commit或者git commit --help来获取命令的提示帮助
2.4 日志命令操作
我们的每次提交,git都会随着提交的变动来记录版本变化,所以你在工作区中的所有操作都会留下日志。
@查看所有提交日志: 使用
git log命令来显示从最早的提交点到当前提交点的所有日志@查看执行条数的提交日志: 使用
git log -数量命令来显示最近指定数量条的提交日志@简洁日志显示: 使用
git log --oneline命令来显示比较简洁的提交日志@查看最近的2次提交日志: 使用
git log --oneline -数量命令来简洁的显示最近的数量条的提交日志@图形化显示分支走向: 使用
git log --oneline --graph命令来图形化显示分支走向提交ID: git中的commitID是通过SHA1计算出来的⼀个⾮常⼤的数字,⽤⼗六进制表示,在分布式中保证唯一性。
而关于日志中显示的commitID,使用
git log命令显示的提交ID是很长的字符串,而使用git log --oneline命令来简洁显示的提交ID是一个7位的字符串。如果我们后续在使用commitID来操作的时候可以指定提交ID的前几位字符即可,只要在你所操作的几条commitID前几位字符不发生重复就可以使用,所以在我们使用ID的时候并不需要使用很长的ID来操作,而一般使用前7位
| 查看日志 |
|---|
 |
2.5 版本回退命令操作
每次修改文件并添加和提交。git都会记录一个版本,如果有需要可以回退到之前的数据版本状态
@回退上一个版本: 使用
git reset --hard HEAD~命令来回退到上一个版本@回退上上个版本: 使用
git reset --hard HEAD~~命令来回退到上上个版本@回退到上某数量个版本: 使用
git reset --hard HEAD~数量命令来回退到上某数量个版本@回退到某次提交时的版本: 使用
git reset --hard commitID命令来回退到某次提交时的版本注意: 回退的版本指定的commitID假如是22c4302cc866fbf5a3184b1fea6bd90b8c85255f,此时我们可以使用命令
git reset --hard 22c4302来回退到该提交ID时的版本,虽然commitID这么长,我们只需要保证唯一性来输入前几位commitID即可。要记住回退版本并不会删除任何版本,所以版本之间可以来回切换@细节: 发⽣版本回退后,通过
git log命令只能看到最原始提交点⾄当前提交点的⽇志。而git reflog可以看全部⽇志(包括版本回退的日志)
2.6 文件状态
切换至某个分支,在工作区操作该文件,文件状态会有以下几种:
| 文件状态 | 描述 |
|---|---|
| 未跟踪 | ⼯作区中新创建的⽂件,git中并未保存它的任何记录。使用git add .命令添加至暂存时即可建立跟踪状态 |
| 修改 | 已跟踪状态的文件,在工作区被修改了,则会变为修改状态 |
| 暂存 | 使用git add .命令添加到暂存区的文件处于暂存状态。每次暂存的是文件的当前状态,如果文件被修改过,则需要再次将该文件添加到暂存区。而每次提交,是将所有暂存区的文件提交 |
| 提交 | 使用git commit -m "描述"命令来提交文件,则该文件就将从暂存状态变为了已提交状态。每次提交,会增加一个版本,分支指针后移指向新版本 |
2.7 查看文件状态
我们可以使用
git status命令来时刻查看文件所在状态@细节: 可以使用
git diff命令来比对工作区内文件的变动状态@比对: 使用
git diff 文件名命令来比对工作区和暂存区(若暂存区没有则比对分支)@比对工作区与分支的最新结果: 使用
git diff HEAD -- 文件名命令来比对工作区和分支的最新结果@比对暂存区与分支的最新结果: 使用
git diff --staged 文件名命令来比对暂存区与分支的最新结果注意:
git diff HEAD -- 文件名命令--与文件名之间必须要有一个空格,不要写错!
| 无文件放入工作区、无add、无commit(没有任何文件状态) |
|---|
 |
| 将一个名为test.txt文件放入工作区、无add、无commit(未跟踪状态) |
 |
| 将test.txt文件add到暂存区、无commit(暂存状态) |
 |
| 将test.txt文件commit提交到master主分支(提交状态) |
 |
| 修改test.txt文件内容、无add、无commit(修改状态) |
 |
| 将处于修改状态的文件add并commit提交后再次查看文件状态就无任何文件状态了! |
2.8 撤销修改命令操作
@工作区撤销: 执行
git checkout -- 文件名命令可以撤销到最近一次git add或git commit的状态工作区撤销内部流程: 你执行了工作区撤销命令,如果暂存区有此文件,则将暂存区中的文件恢复到工作区中;如果暂存区没有此文件,则将分支中的文件恢复到工作区中
@暂存区撤销: 先执行
git reset HEAD 文件名命令将该文件移除暂存区,后执行git checkout -- 文件名命令回退到上一个版本暂存区撤销场景: 如果在工作区中修改了文件并发送到了暂存区中,但文件中有需要撤销的内容
三、分支
3.1 分支概述
- 每一个被git管理的仓库都会有一个默认的主分支(master分支)
- 分⽀中接收
git commit提交的内容,为⼀个⼀个不断向前发展的提交点。每个提交点都保存了⼀个版本- 每个分⽀,都有⼀个指针,指针默认指向最近⼀次提交的版本
- ⼯作区中的内容,初始状态,就是指针所指向的版本状态
- 基于指针指向的版本代码,在⼯作区中做进⼀步的编码,功能完成后,即可
git commit,在分⽀中形成新的提交点。然后再在⼯作区中,添加新代码,功能完成,再 git commit,⼜形成新的提交点,指针再次后移。如此反复,不断开发,不断记录版本。- 当有需要时,可以回退指针到某个提交点,在⼯作区中即可得到之前的某个版本的代码
| 分支效果图 |
|---|
 |
3.2 多分支
为什么要使用多分支呢?那么我们就需要了解几个场景了
场景1: 在编写一个功能代码时,需要一周的时间,在一周时间内可能会有多次提交,但最后的时候我们中间提交点的代码中发现有问题存在,那这些存在问题的提交点就掺杂在master主分支,使主分支变得十分混乱
场景2: 在编写一个功能代码时,有一个新的思路,但不确定能否最总实现预期功能效果,只能试着编写,最后发现达不到预期功能结果,则中间提交过的很多提交点都无效了,也使得主分支变得十分混乱
场景3: 如果该项目是多人协同开发,master主分支有错误或无效的提交点会影响其他人的开发进度
注意: 实际开发中master分⽀尽量只存放稳定的代码提交,保证master分⽀稳定,有效。因为这样保证了我们的开发进度不会受到影响
解决方案1: ⼀直不提交,等所有都写完后,提交⼀次。虽然可以保护master分⽀,但开发过程中缺乏版本控制点,易丢失⼯作
解决方案2: 在需要编写新功能时,新建⼀个开发⽤的分⽀,所有改动都在该分⽀上提交,在功能完整实现后,将该分⽀的最终内容合并到master分⽀。这样,既保证开发中有多个版本可以控制,⼜保证master分⽀是稳定,有效的
| 多分支效果图 |
|---|
 |
3.3 多分支基本命令操作
@创建分支: 使用
git branch 分支名命令创建分支,会与当前分支保持同样的数据状态,即新分支和当前分支指向同一个提交点@切换分支: 使用
git checkout 分支名命令切换分支,切换分支后工作区中显示当前分支内容(切换分支实际上是切换了分支的指针,让指针指向了所要切换到分支)@查看当前分支: 使用
git branch命令来查看当前分支@查看当前分支详细信息: 使用
git branch -vv命令查看分支详细信息,分支信息则是所跟踪的远程分支信息以及是否领先远程分支等等@合并分支: 如果新分支编写完成后,先使用
git branch master命令切换到master分支,再使用git merge 新分支名命令将新分支合并到master分支。此次合并就是将master的指针移到了新分支的位置,等价于快速合并
@查看当前合并分支: 分支合并后可以使用git branch --merged命令查看被当前分⽀合并了的分⽀@删除分支: 将分支合并后,如果新分支不再继续使用,可以先使用
git branch --merged命令查看合并分支以确认我们即将删除的分支的确是无用分支后,再使用git branch -d 分支名命令删除需要删除的无用分支。
3.4 解决分支冲突
场景: 创建一个新分支(见图1);切换到新分支,并在文件中添加一些信息并提交(见图2);切换到master分支,并在文件中也添加一些信息并提交(见图3);在master分支中合并新分支。此时合并分支中会出现冲突(见图4)
分支冲突原因: 两个分支对同一个文件做了改动,所以在合并时git会无法确定保留哪个分支上的数据
@终止合并分支: 当出现分支冲突时可以使用
git merge --abort命令来终止合并分支@避免因为空⽩导致冲突: 在合并分支时,如果有空白内容有可能会出现分支冲突现象,所以此时可以使用
git merge 分支名 -Xignore-all-space命令来避免因为空白而导致的分支冲突解决分支冲突: 需要找到提交两个分支的人一起讨论最终保留哪些数据,讨论后将最终要保留的数据在一个的分支中提交。此时便解决了合并时发生的分支冲突问题,合并完成后某个分支将不再使用可以使用
git branch -d 分支名命令来删除无用分支注意: 解决冲突要么保留其中的一方,要么达成协议商讨双方手动合并,无论如何记得删除
<<<< ==== >>>>这些符号
| 分支冲突效果图 |
|---|
 |
| 分支冲突错误提示信息: |
Auto-merging test.txt CONFLICT (content): Merge conflict in test.txt Automatic merge failed; fix conflicts and then commit the result. |
合并冲突后git将双方对文件的改动都保留了,并使用<<<<、======、>>>>>做了分隔 |
 |
3.5 快照
git在保存每个版本时( 对应提交点 ),并不是复制所有⽂件,没有改动的⽂件只是记录⼀个链接。
解释: 首先看V1版本内有三个文件。我们将A、C文件做了修改并提交便生成了V2版本。这时内部是怎么操作的呢?其实git在内部复制了A、C两个需要修改的文件到V2版本中并做了修改,而虚线框中的B文件并没有发生任何修改,其git内部就以链接的形式在V2版本用引用了B文件,减少了重复文件的环节,大大提高了Git的效率。以此类推,以后的版本虚线框内也都是引用的上个版本的文件
| 快照效果图 |
|---|
 |
3.6 合并方式
分支的合并方式有两种快速合并 和三方合并
- 快速合并内部流程: 一个人在主分支上拉出了一个新分支为newBr并提交了一次(移动了一次指针)。如果合并这两个分支,在快速合并中只需要移动master分支的指针指向newBr分支即可实现合并
- 三方合并内部流程: 在三方合并中从开始分叉的那个提交点开始,分别将该提交点更新的部分数据合并至master和newBr分支,合并后就三个分支就剩下了俩个分支。则剩下的master分支和newBr分支将合并为一个新的提交点,而这个由三方合并成的新提交点为最终合并成功的那个master分支
注意: 以下例图并不严谨,只为传达思想!
| 快读合并效果图 |
|---|
 |
| 三方合并效果图 |
 |
四、远程仓库(Github)
4.1 获取SSH key
git本地仓库和GitHub或码云之间传输,建议设置SSH key,避免在传输中反复输入密码
设置SSH key: 执行
ssh-keygen -t rsa -C "邮箱"命令后的每一步都按Enter键确定就好,知道命令执行结束(-C 后面的内容随意写就行,这只是作为title而已)命令执行完毕后,会在你电脑的
C:\Users\主机名\.ssh目录下生成密钥文件。id_rsa是私钥,不能泄露出去。id_rsa.pub是公钥,可以放⼼地告诉任何⼈。随后注册登录GitHub,在账户设置中选择
SSH Keys,在Title中随意填写内容,在Key中填写id_rsa.pub文件中的所有内容在GitHub中添加好自己的公钥,这样和Git服务器通信时(clone,push,pull)git服务器就可以识别出你的身份了!
4.2 注册登录并设置SSHKey
GitHub官网地址: https://github.com/
| 注册GitHub账号(Sign up) |
|---|
 |
| 登录GitHub(Sign in) |
 |
| 右侧头像点击打开Setting设置 |
 |
| 在Setting中创建SSH Key |
 |
| 添加SSH Key |
 |
4.3 创建远程仓库(主四步骤)
首先在GitHub中创建远程仓库,其次就是将本地仓库关联到远程仓库,这里如果做关联的话是需要执行一些命令的,虽然在GitHub创建仓库的时候已经提示命令,但是由于我想到有很多小伙伴会不清楚怎么看和执行这些命令,所以我在图中已经标注。为了全面些,我也会把这些命令罗列到下方并作以解释!
@添加自述文件: 如果是本地仓库是空的,我们需要创建一个自述文件(README.md),也就是说创建一个文件放入到本地仓库中,执行
git add .和git commit -m "add a README.md"(最好仓库中不是空的!)@关联远程仓库: 关联远程仓库只需要执行
git remote add 关联别名 仓库地址命令即可(注意:别名是可以自己取名设置的,但是不要忘记就好,因为后续push的时候会用到)@上传到GitHub远程仓库: 执行
git push 关联别名 master命令将文件上传到GitHub服务器的主master分支上传到GitHub远程仓库后,我们就可以正常的在GitHub查看所上传的文件。设置一次关联后,我们在本地仓库上传到GitHub远程仓库都需要
add -> commit -> push@查看关联的所有远程仓库: 执行
git remote -v命令查看关联的所有远程仓库@查看关联后远程仓库分支和本地仓库分支的对应关系: 执行
git remote show 关联别名命令查看@删除关联: 执行
git remote remove 关联别名命令删除关联@重命名关联别名: 执行
git remote rename 原关联别名 新关联别名命令重命名关联别名
| 右侧头像点击 + 后打开New repository |
|---|
 |
| 创建仓库 |
 |
| 本地仓库关联GitHub服务器 |
 |
| 做完以上步骤就可以在GitHub上看到我们所上传的文件了! |
4.4 上传命令操作(push)
将本地仓库的文件上传到关联的GitHub远程仓库中显示(注意:push的文件是必须commit提交过的!)
将本地仓库的文件上传到关联的GitHub远程仓库中显示(注意:push的文件是必须commit提交过的!)
push操作需要关联仓库,也就是说必须有权限来对GitHub远程仓库做操作,而且需要在你pull之后没人push过
@上传到GitHub远程仓库: 执行
git push 关联别名 master命令来将本地仓库的文件上传到GitHub远程仓库显示(注意:我们是可以指定上传的分支的!)@本地存在分支上传GitHub分支: 执行
git push 关联别名 本地仓库分支:GitHub仓库分支命令会将本地仓库存在分支上传到GitHub分支@本地存在多分支上传到GitHub多分支: 执行
git push 关联别名 本地仓库分支1:GitHub仓库分支1 本地仓库分支2:GitHub仓库分支2命令来实现一次性实现上传指定多个分支
4.5 拉取远程操作(fetch、merge)
拉取远程仓库的新内容到本地仓库和版本库,但是这个操作并没有合并到本地库的分⽀中,需要通过⼿动合并分支来实现。此操作并不常用,了解即可!
@拉取远程仓库分支: 执行
git fetch 关联别名 master命令来拉取master分支下的内容@手动合并本地库分支: 执行
git merge 关联别名/master命令来手动合并本地库分支下的内容上面两个命令可以将GitHub服务器上的最新状态同步到本地仓库中
@拉取所有分支: 执行
git fetch 关联别名命令来拉取GitHub服务器所有分支下的内容(合并分支如下)@手动合并所有分支内容: 执行
git checkout 分支1命令来切换分支并执行git merge 关联别名/分支1合并拉取该分支的内容,并以此类推合并各个分支@比较拉取内容中的分支和本地分支中的不同: 首先执行
git checkout 分支命令来切换到想要比较并拉取的分支,再执行git diff 关联别名/分支命令来比较拉取的内容中的分支和本地分支的不同
4.6 下载操作(pull)
首先下载操作等价于拉取远程的新内容,并合并到当前分支的操作
@下载远程内容: 可以执行
git pull 关联别名 master命令来完成对远程仓库主分支内容的下载操作,该操作省略了本地仓库分支(当前分支),默认的将远程仓库master主分支上的内容下载到了本地仓库的master主分支@下载远程内容的完整写法:
git pull 关联别名 远程仓库分支:本地仓库分支(当前分支)
4.7 克隆操作(clone)
将GitHub远程仓库的所有内容下载到本地,该方式自动搭建了本地与GitHub远程仓库的关联
@clone操作1: 执行命令
git clone SSH地址将远程仓库clone到本地,已设置key,不用命令@clone操作2: 执行命令
git clone HTTPS地址将远程仓库clone到本地,该方式需要输入GitHub口令细节1: clone只在初次从git服务器下载项⽬时执⾏⼀次,后续在需要同步应该执⾏pull或fetch
细节2: 当执⾏
git clone命令时,默认配置下远程 Git 仓库中的每⼀个⽂件的每⼀个版本都将被拉取下来
五、标签
5.1 为什么要打标签
其实在我们做项目的时候是少不了遇见很多问题的,有可能在这个版本的问题发布出现了问题,但是到了后面的几个版本都没有得到解决。而项目往往不会因为这些问题而终止项目的上传。为了让所有人能了解该版本中的问题而使用标签作为标记
注意: 以下所使用的v1.1.0等等标签是标签名,小伙伴们可以根据自己的需求来打标签
5.2 打标签
@创建轻量标签: 使用
git tag v1.1.0命令来创建轻量标签@创建附加备注的轻量标签: 使用
git tag -a v1.1.1 -m "说明文字"命令来创建附注标签,而创建标签会自动打在最近的提交点上@为以前的提交点打标签: 如果为以前的提交点打标签就需要使用
git log命令去查看commitID,再根据commitID执行git tag -a v1.1.1 "commitID"来为该提交点打标签
5.3 查看标签
@查看所有分支上的所有标签: 执行
git tag命令来查看@查看标签名以“v1.1”开头的标签: 执行
git tag "v1.1*"命令来查看@显示标签及其对应的提交信息: 执行
git show v1.1.0命令来显示标签及其对应的提交信息
5.4 共享标签
标签不会随提交点⼀起 提交到远程服务器,需要单独push。而pull时,标签会⼀同被下载到本地
@同步一个标签“v1.1.1”到GitHub服务器: 执行
git push 关联别名 v1.1.1命令来同步标签@同步所有标签到GitHub服务器: 执行
git push 关联别名 --tags命令来同步所有标签
5.5 删除标签
标签删除需要在本地和远程分别删除
@在本地删除标签: 执行
git tag -d v1.1.1命令来删除本地标签@删除远程库中的标签: 执行
git push 关联别名 :refs/tags/v1.1.1命令来删除远程库中的所有标签
5.6 标签的使用
标签的主要作用是用于发布版本,假设我们已经为各个版本打了标签“v1.0”、“v2.0”等等。现在需要v1.0版本,就可以分离一个指针指向v1.0版本的提交点位置
@原分离头指针: 执行
git checkout v1.0版本的commitID命令来使头指针指向该commitID的提交点@标签分离头指针: 执行
git checkout v1.0命令来使头指针 指向该提交点注意: 分离头指针只是一个临时指针,它不归属任何分支,使用标签显然比使用commitID方便,最后随意切一个分支,分离头指针消失,就像之前什么都没有发生过一样
六、别名
有一些指令感觉会比较麻烦,就可以定义别名来执行命令,简化书写。下面列举一个常用的命令来实现别名的简化
@简化commit命令书写: 执行
git config --global alias.comt "commit -m"命令来简化commit -m命令,设置这种简化命令之后以后执行git comt "描述信息"命令就等价于执行了git commit -m "描述信息"命令@删除别名简化: 执行
git config --global --unset alias.comt命令来删除我们创建的简化commit的别名,删除后使用comt则就会失效
七、IDEA关联Git
7.1 关联Git
| 设置关联Git |
|---|
 |
7.2 创建仓库
在IDEA中创建仓库之前,我们需要创建设置一个忽略文件(.gitignore)。至于为什么呢?那是因为我们在项目中会有很多文件不必上传,就比如db.properties配置文件、.idea文件、所有的.class文件等等,所以这个忽略文件就可以帮我们在上传服务器的时候忽略这些没有必要的文件,忽略后的文件不会放在版本库中管理
| 设置忽略文件 |
|---|
 |
| 初始化一个仓库 |
 |
 |
7.3 提交
| 选择提交菜单,提交一个版本 |
|---|
 |
| 选择提交文件,定义提交信息 |
|---|
 |
| 之后会有些友好提示,可以忽略,点击“commit”即可 |
 |
7.4 创建分支
| 点击右下角链接,创建新分支 |
|---|
 |
| 新建分支 |
 |
| 查看当前分支 |
 |
7.5 上传到远程仓库
| 先创建一个仓库,随后选择push菜单 |
|---|
 |
| 定义远程仓库地址 |
 |
| 开始push操作 |
 |
| push成功后 ,弹窗提示 |
 |
7.6 复制到本地仓库
| 找到GitHub或码云上的开源项目后复制链接,点击克隆菜单 |
|---|
 |
| 输入如远程仓库地址 |
 |
| 打开项目 |
 |
| 打开项目,选项 |
 |
7.7 更新本地项目
注意:如果远程仓库有更新,则你的本地项目也需要一起更新。
| 选择pull菜单 |
|---|
 |
| 执行pull操作 |
 |
| 更新日志显示 |
 |
7.8 IDEA中冲突解决
| 冲突出现,弹窗中可以选择如下 |
|---|
 |
| 也可以直接修改冲突文件,然后commit即可 |
 |
八、多人协同开发
8.1 项目经理
- 由项目经理负责创建一个远程仓库,初始仓库中什么都没有,而库的名称建议和项⽬同名
- 管理员会在IDEA中创建⼀个空项⽬,其中包含 .gitignore⽂件 。并在项⽬根⽬录下执行
git init建⽴本地库,并建⽴dev开发分⽀- 管理员将本地库同步到远程库,执行命令
git push 远程库地址 master:master dev:dev操作- 将项目组中的其他人员拉入远程仓库的开发人员列表中,此操作是赋予开发人员对远程仓库push等等的权限
- master分⽀设置为 protected分⽀,只有管理员有权限将代码合并到其中。dev分⽀设置为 常规分⽀所有开发⼈员都可以其中合并代码
注意: 管理员拉开发人员进入开发人员列表在仓库的设置中设置
8.2 开发人员
- 开始的时候开发人员需要将项目使用IDEA或命令行clone远程仓库,获取项目。clone操作自动关联远程仓库并建立了本地仓库
- 获得项⽬时,本地库中只显示master分⽀,需要执⾏
git checkout dev即可获得dev分⽀- 后续的开发中,都要在dev分⽀上进⾏。开发完⼀个功能并测试通过后就可以
git add .并git commit -m "描述信息"提交到本地的dev分⽀中,然后git push远程库地址的dev分支并同步到远程dev分⽀中- 如果在
git push远程库时,有⼈⽐你早⼀步git push,GitHub服务器将拒绝你的git push操作。(乐观锁原理)不过很简单,你需要先git pull远程库的dev分支后再git push即可
手把手教你玩转Git的更多相关文章
- 手把手教你玩转Git分布式版本控制系统! (转载)
目录 Git诞生历史 Git环境准备 Git安装部署 Git常用命令 Git基本操作 Git管理分支结构 Git管理标签 GitLab安装部署 GitHub托管服务 Git客户端工具 Git诞生历史 ...
- 手把手教你玩转Git分布式版本控制系统!
目录 Git诞生历史 Git环境准备 Git安装部署 Git常用命令 Git基本操作 Git管理分支结构 Git管理标签 GitLab安装部署 GitHub托管服务 Git客户端工具 1 Git诞生历 ...
- 知识全聚集 .Net Core 技术突破 | 我用C#手把手教你玩微信自动化一
知识全聚集 .Net Core 技术突破 | 我用C#手把手教你玩微信自动化一 教程 01 | 模块化方案一 02 | 模块化方案二 03 | 简单说说工作单元 其他教程预览 分库分表项目实战教程 G ...
- 手把手教你玩转SOCKET模型之重叠I/O篇(下)
四. 实现重叠模型的步骤 作 了这么多的准备工作,费了这么多的笔墨,我们终于可以开始着手编码了.其实慢慢的你就会明白,要想透析重叠结构的内部原理也许是要费点功夫,但是只是学会 如何来使用它,却 ...
- 转:变手把手教你玩转SOCKET模型之重叠I/O篇
手把手教你玩转SOCKET模型之重叠I/O篇 “身为一个初学者,时常能体味到初学者入门的艰辛,所以总是想抽空作点什么来尽我所能的帮助那些需要帮助的人.我也希望大家能把自己的所学和他人一起分享,不要去鄙 ...
- 手把手教你玩转 CSS3 3D 技术
css3的3d起步 要玩转css3的3d,就必须了解几个词汇,便是透视(perspective).旋转(rotate)和移动(translate).透视即是以现实的视角来看屏幕上的2D事物,从而展现3 ...
- 手把手教你玩转CSS3 3D技术
手把手教你玩转 CSS3 3D 技术 要玩转css3的3d,就必须了解几个词汇,便是透视(perspective).旋转(rotate)和移动(translate).透视即是以现实的视角来看屏幕上 ...
- 完毕port(CompletionPort)具体解释 - 手把手教你玩转网络编程系列之三
手把手叫你玩转网络编程系列之三 完毕port(Completion Port)具体解释 ...
- 手把手教你玩微信小程序跳一跳
最近微信小程序火的半边天都红了,虽然不会写,但是至少也可以仿照网上大神开发外挂吧!下面手把手教妹纸们(汉纸们请自觉的眼观耳听)怎么愉快的在微信小游戏中获得高分. 废话不多说,咱们这就发车了!呸!咱们这 ...
随机推荐
- nginx下通过子路径配置多个vue单页应用的方法
千辛万苦在Stack Overflow上找来的,记下吧. https://stackoverflow.com/q/31519505/13651734 我的需求是 首页:/ 项目a:/aaa 项目 b: ...
- 从linux源码看socket(tcp)的timeout
从linux源码看socket(tcp)的timeout 前言 网络编程中超时时间是一个重要但又容易被忽略的问题,对其的设置需要仔细斟酌.在经历了数次物理机宕机之后,笔者详细的考察了在网络编程(tcp ...
- InnoDB存储引擎的事务
事务的任务是保证一系列更新语句的原子性,锁的任务是解决并发访问可能导致的数据不一致问题.如果事务与事务之间存在并发操作,此时可以通过隔离级别实现事务的隔离性,从而实现数据的并发访问. 1 原子性(At ...
- 2.使用nexus3配置docker私有仓库
1,配置走起 1,创建blob存储 登陆之后,先创建一个用于存储镜像的空间. 定义一个name,下边的内容会自动补全. 然后保存. 注意:实际生产中使用,建议服务器存储500G或以上. 2,创建一个h ...
- Vue项目实战之改动饿了吗购物小球动画
html:没有写v-on: afterEnter函数了,因为执行不到,原因是enter的done: <div class="ball-container"><tr ...
- flex弹性模型
flex模型是w3c最新提出的一种盒子模型,很好的解决了普通模型的一些弊端. 一.比较两种盒子模型: demo: 给div添加边框,观察他们的区别 <body> <div class ...
- TensorFlow从0到1之浅谈感知机与神经网络(18)
最近十年以来,神经网络一直处于机器学习研究和应用的前沿.深度神经网络(DNN).迁移学习以及计算高效的图形处理器(GPU)的普及使得图像识别.语音识别甚至文本生成领域取得了重大进展. 神经网络受人类大 ...
- (七)POI-读取excel,遍历一个工作簿
原文链接:https://blog.csdn.net/class157/article/details/92816169,https://blog.csdn.net/class157/article/ ...
- Linux下如何查看硬件信息?
我们在 Linux 下进行开发时,有时也需要知道当前的硬件信息,比如:CPU几核?使用情况?内存大小及使用情况?USB设备是否被识别?等等类似此类问题.下面良许介绍一些常用的硬件查看命令. lshw ...
- Java字符串类型详解
Java 字符串类主要有String.StringBuffer.StringBuilder.StringTokenizer 1.字符串类型底层都是使用char数组进行实现. 2.从jdk1.7以后,S ...