(转载)微软数据挖掘算法:Microsoft 神经网络分析算法原理篇(9)
前言
本篇文章继续我们的微软挖掘系列算法总结,前几篇文章已经将相关的主要算法做了详细的介绍,我为了展示方便,特地的整理了一个目录提纲篇:大数据时代:深入浅出微软数据挖掘算法总结连载,有兴趣的童鞋可以点击查阅,在开始Microsoft 神经网络分析算法之前,本篇我们先将神经网络分析算法做一个简单介绍,此算法由于其本身的复杂性,所以我打算在开始之前先将算法原理做一个简单的总结,因为本身该算法就隶属于高等数学的研究范畴,我们对算法的推断和验证过程不做研究,只介绍该算法特点以及应用场景,且个人技术能力有限,不当之处还望勿喷。
算法起源
在思维学中,人类的大脑的思维分为:逻辑思维、直观思维、和灵感思维三种基本方式。
而神经网络就是利用其算法特点来模拟人脑思维的第二种方式,它是一个非线性动力学系统,其特点就是信息分布式存储和并行协同处理,虽然单个神经元的结构及其简单,功能有限,但是如果大量的神经元构成的网络系统所能实现的行为确实及其丰富多彩的。其实简单点讲就是利用该算法来模拟人类大脑来进行推理和验证的。
我们先简要的分析下人类大脑的工作过程,我小心翼翼的在网上找到了一张勉强看起来舒服的大脑图片
嗯,看着有那么点意思了,起码看起来舒服点,那还是在19世纪末,有一位叫做:Waldege的大牛创建了神经元学活,他说人类复杂的神经系统是由数目繁多的神经元组成,说大脑皮层包括100亿个以上的神经元,每立方毫米源数万个,汗..我想的是典型的大数据。他们相互联系形成神经网络,通过感官器官和神经来接受来自身体外的各种信息(在神经网络算法中我们称:训练)传递中枢神经,然后经过对信息的分析和综合,再通过运动神经发出控制信息(比如我在博客园敲文字),依次来实现机体与外部环境的联系。
神经元这玩意跟其它细胞一样,包括:细胞核、细胞质和细胞核,但是它还有比较特殊的,比如有许多突起,就跟上面的那个图片一样,分为:细胞体、轴突和树突三分部。细胞体内有细胞核,突起的作用是传递信息。树突的作用是作为引入输入信息的突起,而轴突是作为输出端的突起,但它只有一个。
也就是说一个神经元它有N个输入(树突),然后经过信息加工(细胞核),然后只有一个输出(轴突)。而神经元之间四通过树突和另一个神经元的轴突相联系,同时进行着信息传递和加工。我去...好复杂....
我们来看看神经网络的原理算法公式
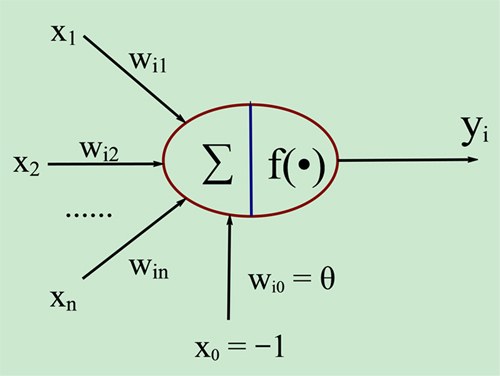
中间那个圆圆的就是细胞核了,X1、X2、X3....Xn就是树突了,而Yi就是轴突了....是不是有那么点意思了,嗯...我们的外界信息是通过神经元的树突进行输入,然后进过细胞核加工之后,经过Yi输出,然后输出到其它神经元...
但是这种算法有着它自身的特点,就好像人类的大脑神经元一样,当每次收到外界信息的输入,不停的刺激的同时会根据信息的不同发生自身的调节,比如:通过不断的训练运动员学会了远动,不停的训练学会了骑自行车....等等吧这些人类的行为形成,其本质是通过不停的训练数百亿脑神经元形成的。而这些行为的沉淀之后就是正确结果导向。
同样该算法也会通过X1、X2、X3....Xn这些元素不停的训练,进行自身的参数的调整来适应,同样训练次数的增加而形成一个正确的结果导向。这时候我们就可以利用它的自身适应过程产生正确的结果,而通过不断的训练使其具备学习功能,当然,该算法只是反映了人脑的若干基本特性,但并非生物系统的逼真描述,只是某种简单的模仿、简化和抽象。
该算法不同数字计算机一样,会按照程序的一步一步地执行运算,而是能够自身适应环境、总结规律、完成某种运算、识别或控制过程,而这就是机器人的起源...人工智能的基础。
神经网络算法原理
由于神经网络算法的设计面太大,我们此处暂且只分析Microsoft神经网络算法的原理,在Microsoft神经网络算法中,我们可以简化成下面这个图片:
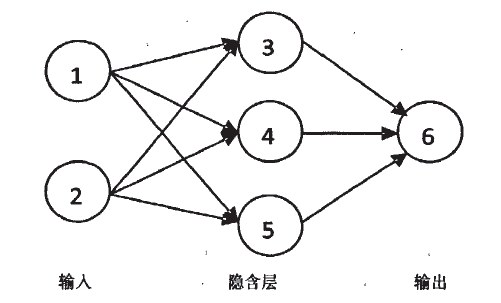
Microsoft神经网络使用的由最多三层神经元组成的“多层感知器”网络,分别为:输入层、可选隐含层和输出层。
输入层:输入神经元定义数据挖掘模型所有的输入属性值以及概率。
隐含层:隐藏神经元接受来自输入神经元的输入,并向输出神经元提供输出。隐藏层是向各种输入概率分配权重的位置。权重说明某一特定宿儒对于隐藏神经元的相关性或重要性。输入所分配的权重越大,则输入值也就越重要。而这个过程可以描述为学习的过程。权重可为负值,表示输入抑制而不是促进某一特定结果。
输出层:输出神经元代表数据挖掘模型的可预测属性值。
数据从输入经过中间隐含层到输出,整个过程是一个从前向后的传播数据和信息的过程,后面一层节点上的数据值从与它相连接的前面节点传来,之后把数据加权之后经过一定的函数运算得到新的值,继续传播到下一层节点。这个过程就是一个前向传播过程。
而当节点输出发生错误时,也就是和预期不同,神经网络就要自动“学习”,后一层节点对前一层节点一个“信任”程度(其实改变的就是连接件的权重),采取降低权重的方式来惩罚,如果节点输出粗粗哦,那就要查看这个错误的受那些输入节点的影响,降低导致出错的节点连接的权重,惩罚这些节点,同时提高那些做出正确建议节点的连接的权重。对那些受到惩罚的节点而说,也用同样的方法来惩罚它前面的节点,直到输入节点而止。这种称为:回馈。
而我们学习的过程就是重复上面的介绍的流程,通过前向传播得到输入值,用回馈法进行学习。当把训练集中的所有数据运行过一遍之后,则称为一个训练周期。训练后得到神经网络模型,包含了训练集中相应值和受预测值影响变化的规律。
在每个神经元中的隐含层中都有着复杂的函数,并且这些都非线性函数,并且类似生物学神经网络的基本传输特征,这些函数称之为:激活函数,即:输入值发生细微的变化有时候会产生较大的输出变化。
当然Microsot神经网络算法使用的函数是这样的:

其中a是输入值,而O是输出值。
处理反向传播,计算误差,更新权值时输出层所用的误差函数为交叉熵
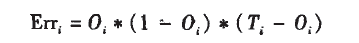
上述公式中Oi是输出神经元i的输出,而Ti是基于训练样例的该输出神经元实际值。
隐含神经元的误差是基于下一层的神经元的误差和相关权值来计算的。公式为:

其中Oi是输出神经元i的输出,该单元有j个到下一层的输出。Erri是神经元i的误差,Wij是这两个神经元之间的权值。
一旦计算出每个神经元的误差,则下一步是使用以下方法来调整网络中的权值。
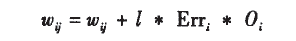
其中l为0-1范围内的数,称之为学习函数。
其实以上函数应用的激活函数还是挺简单的。有兴趣的可以进行详细的研究和公式的推算,咱这里只是简要分析,列举算法特点。
Microsoft神经网络分析算法特点
经过上面的原理分析,我们知道了神经网络算法分为了:输入层、隐含层、输出层三层方式连接,其中隐含层是可选的,也就是说在Microsoft神经网络算法中如果不经过隐含层,则输入将会直接从输入层中的节点传递到输出层中的节点。
输入层特点:如果输入层如果为离散值,那么输入神经元通常代表输入属性的单个状态。如果输入数据包含Null值,则缺失的值也包括在内。具有两个以上状态的离散输入属性值会生成一个输入神经元,如果存在NUll值,会自动再重新的生成一个输入的神经元,用以处理Null值,一个连续的输入属性将生成两个输入神经元:一个用于缺失的状态、一个用以连续属性自身的值。输入神经元可向一个多多个神经元提供输入。
隐含层特点:隐含神经元接受来自输入神经元的输入,并向输出神经元提供输出。存在激活函数供其使用改变阀值。
输出层特点:输出神经如果对于离散输入属性,输出神经元通常代表可预测可预测属性的单个预测状态,其中包括缺失的Null值。
如果挖掘模型包含一个或多个仅用于预测的属性,算法将创建一个代表所有这些属性的单一网络,如果挖掘模型包含一个或多个同时用于输入和预测的属性,则该算法提供程序将为其中每个属性构建一个网络。
对于具有离散值的输入属性和可预测属性,每个输入或输出神经元各自表示单个状态。对于具有连续值的输入属性和可预测属性,每个输入或输出神经元分别表示该属性值的范围和分布。
算法提供程序通过接受之前保留的定性数据集也就是事例集合并将维持数据中的每个事例的实际已知值与网络的预测进行比较。即通过一个“批学习”的过程来迭代计算的整个网络,并且改变的输入权重。该算法处理了整个事例集合之后,将检查每个神经元的预测值和实际值。该算法将计算错误程度(如果错误),并且调整与神经输入关联的权重,并通过一个“回传”的过程从输出神经元返回到输出神经元。然后,该算法对整个事例集合重复该过程。经过以上的层层沉淀我们的算法就算从一个不懂的“婴儿”逐渐成长成“成人”,而这个结果就是我们那它来发掘和预测的工具。
神经网络分析算法应用场景
神经网络研究内容广泛,非本篇文章所能涵盖,而且它反映了多学科交叉技术领域的特点。研究工作集中以下领域:
(1)生物原型研究。从生理学、心理学、脑科学、病理学等生物科学方面研究神经细胞、神经网络、神经系统的生物原型结构及其功能机理。
我去....这那是我这个码农层面研究的事,上面说的种种如果有兴趣童鞋可以继续深入研究,随便一块玩好了都可以升官加禄,衣食无忧......
回归正题,我们还是来看看我们的Microsoft 神经网络分析算法在数据挖掘领域的应用那些:
- 营销和促销分析,如评估直接邮件促销或一个电台广告活动的成功情况。
根据历史数据预测股票升降、汇率浮动或其他频繁变动的金融信息。
分析制造和工业流程。
文本挖掘。
分析多个输入和相对较少的输出之间的复杂关系的任何预测模型。
其实它的应用场景是最广泛的,比如当我们拿到一堆数据的时候,针对一个目标无从下手毫无头绪的时候,Microsoft 神经网络分析算法就是该应用的最佳场景了,因为其利用“人脑”的特点去茫茫的数据海洋中去发掘有用的信息。比如:BOSS把公司的数据库扔给你了...让你分析下公司为啥不挣钱...或者说啥子原因导致的不盈利...这时候该算法就应该出场了。
不过从最近的市场中发现,该算法的在"文本挖掘"中特别火,而且更在微软中得到充分利用,比如当前的:微软小冰,各种平台下的语音识别,并且就连苹果这样的孤傲的公司也在慢慢的臣服于该算法的魅力下,有兴趣可以查看本篇文章:http://www.yeeworld.com/article/info/aid/4039.html
结语
本篇文章到此结束了,满篇的只是简要的介绍了神经网络算法的一些基础和原理,当然因为该算法的高大上我暂且不做深入分析,只是记住其典型的应用场景即可,下一篇的文章我们将通过微软的VS工具使用该算法做一个详细的数据挖掘应用方法介绍。有兴趣的可以提前关注。
原文地址:(原创)大数据时代:基于微软案例数据库数据挖掘知识点总结(Microsoft 神经网络分析算法原理篇)
(转载)微软数据挖掘算法:Microsoft 神经网络分析算法原理篇(9)的更多相关文章
- (转载)微软数据挖掘算法:Microsoft 神经网络分析算法(10)
前言 有段时间没有进行我们的微软数据挖掘算法系列了,最近手头有点忙,鉴于上一篇的神经网络分析算法原理篇后,本篇将是一个实操篇,当然前面我们总结了其它的微软一系列算法,为了方便大家阅读,我特地整理了一篇 ...
- (转载)微软数据挖掘算法:Microsoft 目录篇
本系列文章主要是涉及内容为微软商业智能(BI)中一系列数据挖掘算法的总结,其中涵盖各个算法的特点.应用场景.准确性验证以及结果预测操作等,所采用的案例数据库为微软的官方数据仓库案例(Adventure ...
- (转载)微软数据挖掘算法:Microsoft 线性回归分析算法(11)
前言 此篇为微软系列挖掘算法的最后一篇了,完整该篇之后,微软在商业智能这块提供的一系列挖掘算法我们就算总结完成了,在此系列中涵盖了微软在商业智能(BI)模块系统所能提供的所有挖掘算法,当然此框架完全可 ...
- (转载)微软数据挖掘算法:Microsoft Naive Bayes 算法(3)
介绍: Microsoft Naive Bayes 算法是一种基于贝叶斯定理的分类算法,可用于探索性和预测性建模. Naïve Bayes 名称中的 Naïve 一词派生自这样一个事实:该算法使用贝叶 ...
- (转载)微软数据挖掘算法:Microsoft顺序分析和聚类分析算法(8)
前言 本篇文章继续我们的微软挖掘系列算法总结,前几篇文章已经将相关的主要算法做了详细的介绍,我为了展示方便,特地的整理了一个目录提纲篇:大数据时代:深入浅出微软数据挖掘算法总结连载,有兴趣的童鞋可以点 ...
- (转载)微软数据挖掘算法:Microsoft 关联规则分析算法(7)
前言 本篇继续我们的微软挖掘算法系列总结,前几篇我们分别介绍了:微软数据挖掘算法:Microsoft 决策树分析算法(1).微软数据挖掘算法:Microsoft 聚类分析算法(2).微软数据挖掘算法: ...
- (转载)微软数据挖掘算法:Microsoft 时序算法之结果预测及其彩票预测(6)
前言 本篇我们将总结的算法为Microsoft时序算法的结果预测值,是上一篇文章微软数据挖掘算法:Microsoft 时序算法(5)的一个总结,上一篇我们已经基于微软案例数据库的销售历史信息表,利用M ...
- (转载)微软数据挖掘算法:Microsoft 时序算法(5)
前言 本篇文章同样是继续微软系列挖掘算法总结,前几篇主要是基于状态离散值或连续值进行推测和预测,所用的算法主要是三种:Microsoft决策树分析算法.Microsoft聚类分析算法.Microsof ...
- (转载)微软数据挖掘算法:Microsoft 聚类分析算法(2)
介绍: Microsoft 聚类分析算法是一种"分段"或"聚类分析"算法,它遍历数据集中的事例,以将它们分组到包含相似特征的分类中. 在浏览数据.标识数据中的异 ...
随机推荐
- GDI+中发生一般性错误 Winform Image.Save(mstream, ImageFormat.Png)引发
在处理图片时,读取本地图像文件,进行另存时发生GDI+中发生一般性错误 . 具体情况如下: 用OpenFileDialog打开图像文件,文件名为filename StreamReader sr = n ...
- TypeError: filter() got an unexpected keyword argument 'XXX'
Flask使用SQLAlchemy查询报如下错误: TypeError: filter() got an unexpected keyword argument 'XXX' 出错原因: 查询错误,应该 ...
- 痞子衡嵌入式:恩智浦i.MX RT1xxx系列MCU硬件那些事(2.6)- 串行NOR Flash下载算法(MCUXpresso IDE篇)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是MCUXpresso IDE开发环境下i.MXRT的串行NOR Flash下载算法设计. 在i.MXRT硬件那些事系列之<在串行N ...
- @component的作用详细介绍
最近项目要采用spring boot在学习的spring boot 的过程中第一次见到@component注解,特意在网上搜索下,摘录在此方便日后查阅. 1.@controller 控制器(注入服务) ...
- Sql语句模糊查询字符串的两种写法
Sql语句模糊查询有两种写法,一种是在jdbcTemplate的查询方法参数里拼接字符串%,一种是在Sql语句里拼接%字符串. public class IsNameDaoImpl implement ...
- 免费的java代码混淆,程序加密
java代码可以反编译,特别是放在客户端的程序很用被剽窃,盗用.保护程序一般都有以下几个方法: 1.将class文件加密,这个是最安全的,但也费事儿,因为要重写classloader来解密class文 ...
- Spring Boot 2.x基础教程:实现文件上传
文件上传的功能实现是我们做Web应用时候最为常见的应用场景,比如:实现头像的上传,Excel文件数据的导入等功能,都需要我们先实现文件的上传,然后再做图片的裁剪,excel数据的解析入库等后续操作. ...
- docker frps 内网穿透容器化服务
准备 域名解析 将frp.xx.com解析到服务器ip,将泛域名 *.frp.xx.com解析到frp.xx.com即可 https证书申请 泛域名证书现在可以用acme.sh申请Let's Encr ...
- 如何在Linux(CentOS7)环境搭建 Jenkins 服务器环境
最近,我自己要亲手搭建一套完整的企业级 CI/CD 环境,这个环节里面涉及了很多内容,没有办法把这么多的内容都放在一篇文章里,所以 Jenkins 的安装和Java 的 JDK 安装我就是分了两篇文章 ...
- JS 字符串比较"=="与"==="区别
最近课程油js的课程,课后习题有道关于下面 1 类似的一道题,叫比较然后判断结果,最开始看了网上的知识点,还是有点不太懂,个人感觉模模糊糊的(当然我自己菜,是正常的),就用依稀还记得的java对象与引 ...