MPI聚合函数
MPI聚合通信
- MPI_Barrier
int MPI_Barrier(
MPI_Comm comm
);
所有在该通道的函数都执行完后,才开始其他步骤。

0进程在状态T1调用MPI_Barrier函数,并在该位置挂起,等待其他进程到达。最后在T4状态同时进行。
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank, nprocs;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Barrier(MPI_COMM_WORLD);
printf("Hello,world,I am %d of %d\n", rank, nprocs);
MPI_Finalize();
return 0;
}
- MPI_Bcast
int MPI_Bcast(
void *buffer,
int count,
MPI_Datatype datatype,
int root,
MPI_Comm comm
);
广播函数,root表示要广播的进程。发送和接收进程都需要写该函数。
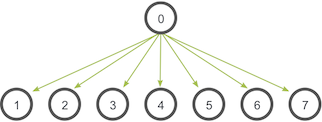
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank,nproc;
int ibuf;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) ibuf = 8888;
else ibuf = 0;
MPI_Bcast(&ibuf, 1, MPI_INT, 0, MPI_COMM_WORLD);
if (rank != 0)
{
printf("rank = %d ibuf = %d\n", rank, ibuf);
}
MPI_Finalize();
return 0;
}
- MPI_Gather
int MPI_Gather(
void *sendbuf,
int sendcnt,
MPI_Datatype sendtype,
void *recvbuf,
int recvcnt,
MPI_Datatype recvtype,
int root,
MPI_Comm comm
);
每个进程(包括root进程)都要发送buffer给root进程,root进程接收到这些buffer并且按照顺序排好序。
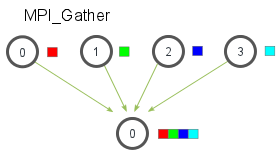
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank, nproc;
int isend, irecv[32];
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
isend = rank + 1;
MPI_Gather(&isend, 1, MPI_INT, irecv, 1, MPI_INT, 0, MPI_COMM_WORLD);
if (rank == 0)
{
for (int i = 0; i < nproc; i++)
{
printf("%d \n", irecv[i]);
}
}
MPI_Finalize();
return 0;
}
- MPI_Gatherv
int MPI_Gatherv(
void *sendbuf,
int sendcnt,
MPI_Datatype sendtype,
void *recvbuf,
int *recvcnts,
int *displs,// 接收的数据放在说明位置,即位移。
MPI_Datatype recvtype,
int root,
MPI_Comm comm
);
是MPI_Gather函数的一个扩展,recvcnts是数组,允许每个进程的数量不同,而且每个进程的位置更灵活。
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
//这里为了简单,假设有4个进程。
int send_buffer[6];
int recv_buffer[6];
int rank, nproc;
int receive_counts[4] = { 0,1,2,3 };
int receive_disp[4] = { 0,0,1,3 };//偏移数组
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
//初始化数据
for (int i = 0; i < rank; i++)
{
send_buffer[i] = rank;
recv_buffer[i] = rank+1;
}
MPI_Gatherv(send_buffer, rank, MPI_INT, recv_buffer, receive_counts, receive_disp, MPI_INT, 0, MPI_COMM_WORLD);
if (rank == 0)
{
for (int i = 0; i < 6; i++)
{
printf("[%d]", recv_buffer[i]);
}
}
MPI_Finalize();
return 0;
}
- MPI_Scatter
int MPI_Scatter(
void *sendbuf,
int sendcnt,
MPI_Datatype sendtype,
void *recvbuf,
int recvcnt,
MPI_Datatype recvtype,
int root,
MPI_Comm comm
);
MPI_Scatter与MPI_Bcast非常相似,都是一对多的通信方式,不同的是后者的0号进程将相同的信息发送给所有的进程,而前者则是将一段array 的不同部分发送给所有的进程。
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
#define MAX_PRO 10//最大进程数
int main(int argc, char* argv[])
{
int rank, nproc;
int table[MAX_PRO][MAX_PRO];
int row[MAX_PRO];
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0)
{
for (int i = 0; i < nproc; i++)
{
for (int j = 0; j < MAX_PRO; j++)
{
table[i][j] = i + j;
}
}
}
MPI_Scatter(&table[0][0], MAX_PRO, MPI_INT, &row[0], MAX_PRO, MPI_INT, 0, MPI_COMM_WORLD);
if (rank != 0)
{
for (int i = 0; i < MAX_PRO; i++)
{
printf("%d ", row[i]);
}
printf("processs of %d\n",rank);
}
MPI_Finalize();
return 0;
}
- MPI_Alltoall
int MPI_Alltoall(
void *sendbuf,
int sendcount,
MPI_Datatype sendtype,
void *recvbuf,
int recvcount,
MPI_Datatype recvtype,
MPI_Comm comm
);
当前进程向其他每个进程(包括自己)要发送数据,都是发送sendbuf中的数据。接收到不同进程的数据。

例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank, nproc;
int send[1];
int recv[10];
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
send[0] = rank*rank;
for (int i = 0; i < 10; i++)
{
recv[i] = 0;
}
MPI_Alltoall(&send, 1, MPI_INT, recv, 1, MPI_INT, MPI_COMM_WORLD);
if (rank == 0)
{
for (int i = 0; i < 10; i++)
{
printf("%d ", recv[i]);
}
}
MPI_Finalize();
return 0;
}
MPI归约操作
- MPI_Reduce
int MPI_Reduce(
void *sendbuf,
void *recvbuf,
int count,
MPI_Datatype datatype,
MPI_Op op,
int root,
MPI_Comm comm
);
MPI_Op有如下类型:
| 运算操作符 | 描述 | 运算操作符 | 描述 |
|---|---|---|---|
| MPI_MAX | 最大值 | MPI_LOR | 逻辑或 |
| MPI_MIN | 最小值 | MPI_BOR | 位与 |
| MPI_SUM | 求和 | MPI_LXOR | 逻辑异或 |
| MPI_PROD | 求积 | MPI_BXOP | 位异或 |
| MPI_LAND | 逻辑与 | MPI_MINLOC | 计算一个全局最小值 |
| MPI_BAND | 位与 | MPI_MAXLOC | 计算一个全局最大值 |
将通信子内各进程的同一个变量参与规约计算,并向指定的进程输出计算结果。
例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank, nproc;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
int send = rank;
int recv;
MPI_Reduce(&send, &recv, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
if (rank == 0)
{
printf("%d", recv);
}
MPI_Finalize();
return 0;
}
- MPI_Scan
int MPI_Scan(
void *sendbuf,
void *recvbuf,
int count,
MPI_Datatype datatype,
MPI_Op op,
MPI_Comm comm
);
前缀和函数 MPI_Scan(),将通信子内各进程的同一个变量参与前缀规约计算,并将得到的结果发送回每个进程,使用与函数 MPI_Reduce() 相同的操作类型。

例子:
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char* argv[])
{
int rank, nproc;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
int send = rank;
int recv;
MPI_Scan(&send, &recv, 1, MPI_INT, MPI_SUM, MPI_COMM_WORLD);
printf("the %d process is %d", rank, recv);
MPI_Finalize();
return 0;
}
- MPI_Reduce_scatter
int MPI_Reduce_scatter(
void *sendbuf,
void *recvbuf,
int *recvcnts,
MPI_Datatype datatype,
MPI_Op op,
MPI_Comm comm
);
将规约结果分片发送到各进程.
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<time.h>
int main(int argc, char** argv)
{
int* sendbuf, recvbuf, * recvcounts;
int size, rank;
MPI_Comm comm;
MPI_Init(&argc, &argv);
comm = MPI_COMM_WORLD;
MPI_Comm_size(comm, &size);
MPI_Comm_rank(comm, &rank);
sendbuf = (int*)malloc(size * sizeof(int));
for (int i = 0; i < size; i++)
sendbuf[i] = i;
recvcounts = (int*)malloc(size * sizeof(int));
for (int i = 0; i < size; i++)
recvcounts[i] = 1;
MPI_Reduce_scatter(sendbuf, &recvbuf, recvcounts, MPI_INT, MPI_SUM, comm);
printf("the %d process is %d", rank, recvbuf);
MPI_Finalize();
return 0;
}
MPI聚合函数的更多相关文章
- 可以这样去理解group by和聚合函数
写在前面的话:用了好久group by,今天早上一觉醒来,突然感觉group by好陌生,总有个筋别不过来,为什么不能够select * from Table group by id,为什么一定不能是 ...
- TSQL 聚合函数忽略NULL值
max,min,sum,avg聚合函数会忽略null值,但不代表聚合函数不返回null值,如果表为空表,或聚合列都是null,则返回null.count 聚合函数忽略null值,如果聚合列都是null ...
- SQL Server 聚合函数算法优化技巧
Sql server聚合函数在实际工作中应对各种需求使用的还是很广泛的,对于聚合函数的优化自然也就成为了一个重点,一个程序优化的好不好直接决定了这个程序的声明周期.Sql server聚合函数对一组值 ...
- Mongodb学习笔记四(Mongodb聚合函数)
第四章 Mongodb聚合函数 插入 测试数据 ;j<;j++){ for(var i=1;i<3;i++){ var person={ Name:"jack"+i, ...
- sql语句 之聚合函数
聚合分析 在访问数据库时,经常需要对表中的某列数据进行统计分析,如求其最大值.最小值.平均值等.所有这些针对表中一列或者多列数据的分析就称为聚合分析. 在SQL中,可以使用聚合函数快速实现数据的聚 ...
- oracle数据库函数之============‘’分析函数和聚合函数‘’
1分析函数 分析函数根据一组行来进行聚合计算,用于计算完成狙击的累积排名等,分析函数为每组记录返回多个行 rank_number() 查询结果按照次序排列,不存在并列和站位的情况,可以用于做Oracl ...
- ORACLE 自定义聚合函数
用户可以自定义聚合函数 ODCIAggregate,定义了四个聚集函数:初始化.迭代.合并和终止. Initialization is accomplished by the ODCIAggrega ...
- sql 聚合函数、排序方法详解
聚合函数 count,max,min,avg,sum... select count (*) from T_Employee select Max(FSalary) from T_Employee 排 ...
- SQL Server 自定义聚合函数
说明:本文依据网络转载整理而成,因为时间关系,其中原理暂时并未深入研究,只是整理备份留个记录而已. 目标:在SQL Server中自定义聚合函数,在Group BY语句中 ,不是单纯的SUM和MAX等 ...
随机推荐
- PHP fstat() 函数
定义和用法 fstat() 函数返回关于一个打开的文件的信息. 该函数将返回一个包含下列元素的数组: [0] 或 [dev] - 设备编号 [1] 或 [ino] - inode 编号 [2] 或 [ ...
- PHP ftp_ssl_connect() 函数
定义和用法 ftp_ssl_connect() 函数打开一个安全的 SSL-FTP 连接. 当连接打开,您就可以在服务器运行 FTP 函数. 语法 ftp_ssl_connect(host,port, ...
- luogu P4606 [SDOI2018]战略游戏
LINK:战略游戏 一道很有价值的题目.这道题 一张无向联通图 每次询问给出K个关键点 问摧毁图中哪个点可以使得这K个关键的两两之间有一对不能联通 去掉的这个点不能是关键点 求方案数. 可以发现 当K ...
- 修改当前项目maven仓库地址
pom.xml中修改 <repositories> <repository> <id>nexus-aliyun</id> <name>Nex ...
- Java课堂总结
通过重载函数,来实现对不同类型的参数运算.
- SpringBoot设置跨域的几种方式
什么是跨域? 浏览器从一个域名的网页去请求另一个域名的资源时,域名.端口.协议任一不同,都是跨域 原因: 由于浏览器的同源策略, 即a网站只能访问a网站的内容,不能访问b网站的内容. 注意: 跨域问题 ...
- spring boot中集成Redis
1 pom.xml文件中添加依赖 <dependency> <groupId>org.springframework.boot</groupId> <arti ...
- JQuery的turn.js实现翻书效果
前言: hello大家好~好久没更博了……今天来和大家分享下JQ的turn.js,下面我先来简单介绍下我们今天的主角turn.js. Turn.js是一个JavaScript库,它集合了HTML5的所 ...
- C#设计模式之17-中介者模式
中介者模式(Mediator Pattern) 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/419 访问. 中介者模式 ...
- C#LeetCode刷题之#665-非递减数列( Non-decreasing Array)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3732 访问. 给定一个长度为 n 的整数数组,你的任务是判断在最 ...