K 均值算法-如何让数据自动分组
公号:码农充电站pro
主页:https://codeshellme.github.io
之前介绍到的一些机器学习算法都是监督学习算法。所谓监督学习,就是既有特征数据,又有目标数据。
而本篇文章要介绍的K 均值算法是一种无监督学习。
与分类算法相比,无监督学习算法又叫聚类算法,就是只有特征数据,没有目标数据,让算法自动从数据中“学习知识”,将不同类别的数据聚集到相应的类别中。
1,K 均值算法
K 均值的英文为K-Means,其含义是:
- K:表示该算法可以将数据划分到K 个不同的组中。
- 均值:表示每个组的中心点是组内所有值的平均值。
K 均值算法可以将一个没有被分类的数据集,划分到K 个类中。某个数据应该被划分到哪个类,是通过该数据与群组中心点的相似度决定的,也就是该数据与哪个类的中心点最相似,则该数据就应该被划分到哪个类中。
关于如何计算事物之间的相似度,可以参考文章《计算机如何理解事物的相关性》。
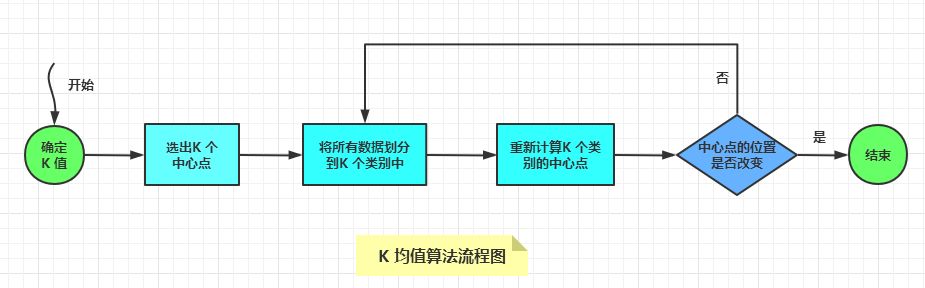
使用K 均值算法的一般步骤是:
- 确定K 值是多少:
- 对于K 值的选择,可以通过分析数据,估算数据应该分为几个类。
- 如果无法估计确切值,可以多试几个K 值,最终将划分效果最好的K 值作为最终选择。
- 选择K 个中心点:一般最开始的K 个中心点是随机选择的。
- 将数据集中的所有数据,通过与中心点的相似度划分到不同的类别中。
- 根据类别中的数据平均值,重新计算每个类别中心点的位置。
- 循环迭代第3,4步,直到中心点的位置几乎不再改变,分类过程就算完毕。
2,K 均值算法的实现
K 均值算法是一个聚类算法,sklearn 库中的 cluster 模块实现了一系列的聚类算法,其中就包括K 均值算法。
来看下KMeans 类的原型:
KMeans(
n_clusters=8,
init='k-means++',
n_init=10,
max_iter=300,
tol=0.0001,
precompute_distances='deprecated',
verbose=0,
random_state=None,
copy_x=True,
n_jobs='deprecated',
algorithm='auto')
可以看KMeans 类有很多参数,这里介绍几个比较重要的参数:
- n_clusters: 即 K 值,可以随机设置一些 K 值,选择聚类效果最好的作为最终的 K 值。
- init:选择初始中心点的方式:
- init='k-means++':可加快收敛速度,是默认方式,也是比较好的方式。
- init='random ':随机选择中心点。
- 也可以自定义方式,这里不多介绍。
- n_init:初始化中心点的运算次数,默认是 10。如果 K 值比较大,可以适当增大 n_init 的值。
- algorithm:k-means 的实现算法,有auto,full,elkan三种。
- 默认是auto,根据数据的特点自动选择用full或者elkan。
- max_iter:算法的最大迭代次数,默认是300。
- 如果聚类很难收敛,设置最大迭代次数可以让算法尽快结束。
下面对一些二维坐标中的点进行聚类,看下如何使用K 均值算法。
3,准备数据点
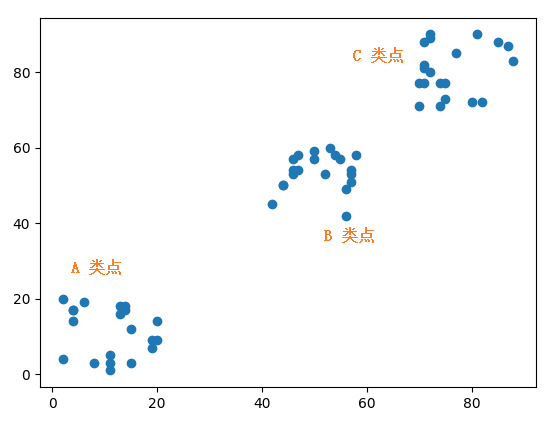
下面是随机生成的三类坐标点,每类有20 个点,不同类的点的坐标在不同的范围内:
- A 类点:Ax 表示A 类点的横坐标,Ay 表示A 类点的纵坐标。横纵坐标范围都是 (0, 20]。
- B 类点:Bx 表示B 类点的横坐标,By 表示B 类点的纵坐标。横纵坐标范围都是 (40, 60]。
- C 类点:Cx 表示C 类点的横坐标,Cy 表示C 类点的纵坐标。横纵坐标范围都是 (70, 90]。
Ax = [20, 6, 14, 13, 8, 19, 20, 14, 2, 11, 2, 15, 19, 4, 4, 11, 13, 4, 15, 11]
Ay = [14, 19, 17, 16, 3, 7, 9, 18, 20, 3, 4, 12, 9, 17, 14, 1, 18, 17, 3, 5]
Bx = [53, 50, 46, 52, 57, 42, 47, 55, 56, 57, 56, 50, 46, 46, 44, 44, 58, 54, 47, 57]
By = [60, 57, 57, 53, 54, 45, 54, 57, 49, 53, 42, 59, 54, 53, 50, 50, 58, 58, 58, 51]
Cx = [77, 75, 71, 87, 74, 70, 74, 85, 71, 75, 72, 82, 81, 70, 72, 71, 88, 71, 72, 80]
Cy = [85, 77, 82, 87, 71, 71, 77, 88, 81, 73, 80, 72, 90, 77, 89, 88, 83, 77, 90, 72]
我们可以用 Matplotlib 将这些点画在二维坐标中,代码如下:
import matplotlib.pyplot as plt
plt.scatter(Ax + Bx + Cx, Ay + By + Cy, marker='o')
plt.show()
画出来的图如下,可看到这三类点的分布范围还是一目了然的。
关于如何使用 Matplotlib 绘图,可以参考文章《如何使用Python 进行数据可视化》。
4,对数据聚类
下面使用K 均值算法对数据点进行聚类。
创建K 均值模型对象:
from sklearn.cluster import KMeans
# 设置 K 值为 3,其它参数使用默认值
kmeans = KMeans(n_clusters=3)
准备数据,共三大类,60 个坐标点:
train_data = [
# 前20 个为 A 类点
[20, 14], [6, 19], [14, 17], [13, 16], [8, 3], [19, 7], [20, 9],
[14, 18], [2, 20], [11, 3], [2, 4], [15, 12], [19, 9], [4, 17],
[4, 14], [11, 1], [13, 18], [4, 17], [15, 3], [11, 5],
# 中间20 个为B 类点
[53, 60], [50, 57], [46, 57], [52, 53], [57, 54], [42, 45], [47, 54],
[55, 57], [56, 49], [57, 53], [56, 42], [50, 59], [46, 54], [46, 53],
[44, 50], [44, 50], [58, 58], [54, 58], [47, 58], [57, 51],
# 最后20 个为C 类点
[77, 85], [75, 77], [71, 82], [87, 87], [74, 71], [70, 71], [74, 77],
[85, 88], [71, 81], [75, 73], [72, 80], [82, 72], [81, 90], [70, 77],
[72, 89], [71, 88], [88, 83], [71, 77], [72, 90], [80, 72],
]
拟合模型:
kmeans.fit(train_data)
对数据进行聚类:
predict_data = kmeans.predict(train_data)
查看聚类结果,其中的0,1,2 分别代表不同的类别:
>>> print(predict_data)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
通过观察最终的聚类结果predict_data,可以看到,前,中,后20 个数据分别被分到了不同的类中,也非常符合我们的预期,说明K 均值算法的聚类结果还是很不错的 。
因为本例中的二维坐标点的分布界限非常明显,所以最终的聚类结果非常不错。
5,总结
本篇文章主要介绍了K 均值算法的原理,及sklearn 库对它的实现,并且演示了如何使用K 均值算法对二维数据点进行聚类。
(本节完。)
推荐阅读:
欢迎关注作者公众号,获取更多技术干货。

K 均值算法-如何让数据自动分组的更多相关文章
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
- K均值算法
为了便于可视化,样本数据为随机生成的二维样本点. from matplotlib import pyplot as plt import numpy as np import random def k ...
- K均值算法-python实现
测试数据展示: #coding:utf-8__author__ = 'similarface''''实现K均值算法 算法摘要:-----------------------------输入:所有数据点 ...
- spark Bisecting k-means(二分K均值算法)
Bisecting k-means(二分K均值算法) 二分k均值(bisecting k-means)是一种层次聚类方法,算法的主要思想是:首先将所有点作为一个簇,然后将该簇一分为二.之后选择能最大程 ...
随机推荐
- P1098 字符串的展开
P1098 字符串的展开 刷新三观的模拟题 题意描述 太长了自己去看吧. 算法分析 模拟题分析你*呀! 写这篇题解的唯一原因是:三目运算符用的好的话,可以让百行大模拟变成30行水题. 代码实现 #in ...
- ajax传值出现乱码问题
第一种:前台传值到后台,浏览器控制台打印正常,controller接收后成了乱码. 后台controller层加上两行转换代码 name=URLDecoder.decode(name,"ut ...
- martini-拓扑映射
如何为一个新的分子创建拓扑文件? 这是martini应用的关键.http://jerkwin.github.io/2016/08/31/Martini%E5%B8%B8%E8%A7%81%E9%97% ...
- UNP——第二章,端口号,套接字对,TCP,UDP输出
1.端口号 端口号用于区分使用相同协议的进程. TCP69 与 UDP69 是不同的. 端口号范围 0 - 65535, 其中 0- 1023 是保留端口. 2.套接字对 TCP服务通过套接字对,唯一 ...
- linux用户的增删改查(useradd/id/usermod/userdel)
与用户(user)相关的配置文件: /etc/passwd 注:用户(user)的配置文件: /etc/shadow 注:用户(user)影子口令文件: 与用户组(group)相关的配置文件: / ...
- Java(三)常用类
@ 目录 Java常用类 一.字符串相关的类 1.String类 2.StringBuffer类 3.StringBuilder类 二.JDK8以前的日期时间API 1.java.lang.Syste ...
- Python_编码错误解决办法 python3 UnicodeEncodeError: 'gbk' codec can't encode character '\xXX' in position XX
先说解决办法:头部加几行代码 import io import sys sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb1803 ...
- 如何调整MathType公式的字体大小
作为一名理科生,想必大家都在为编辑公式而烦恼,在Word中要想完美插入公式,还真不是那么简单的.首先要使用专业的公式编辑器MathType,其次还要对公式的大小进行修改,这样才能看起来是相融合的文章. ...
- css3系列之linear-gradient() repeating-linear-gradient() 和 radial-gradient() repeating-radial-gradient()
linear-gradient() (线性渐变) repeating-linear-gradient() (重复的线性渐变) radial-gradient() (镜像渐变) repeatin ...
- 对于AQS的理解
1.JUC包中的 CountDownLatch.CyclicBarrier.ReentrantLock和Semaphore都是基于AQS(AbstractQuenedSynchronizer)实现的 ...