物体检测丨从R-CNN到Mask R-CNN
这篇blog是我刚入目标检测方向,导师发给我的文献导读,深入浅出总结了object detection two-stage流派Faster R-CNN的发展史,读起来非常有趣。我一直想翻译这篇博客,在知乎上发现已经有人做过了,而且翻译的很好,我将其转载到这里。
这里贴一下我对R-CNN、Fast R-CNN、Faster R-CNN、Mask R-CNN的对比,看完下面的文章后不妨回来看看我的总结,有问题的地方欢迎讨论。

以下内容转载自CNN图像分割简史:从R-CNN到Mask R-CNN(译)
原文A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN
在Athelas中可以看到,卷积神经网络(Convolutional Neural Networks,CNNs)应用非常广泛,不仅仅是用于解决分类问题。这篇博文主要介绍如何利用CNNs进行图像实例分割。
自从Alex Krizhevsky, Geoff Hinton, and Ilya Sutskever赢得ImageNet 2012,CNNs开始成为图像分类任务中的黄金准则。事实上,CNNs之后不断提升ImageNet比赛中的图像分类精度,甚至超过了人类的水准。
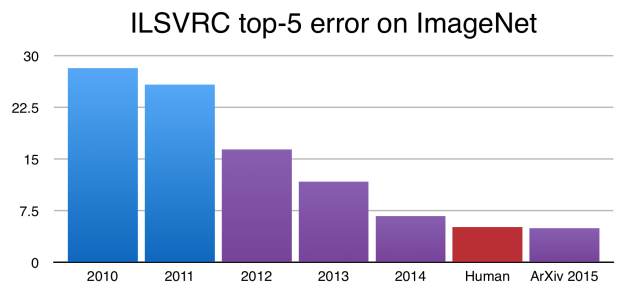
图1 在ImageNet挑战中,CNNs当前已经达到优于人类的水平,上图中Y轴表示ImageNet的错误率。
虽然分类结果非常惊人,但图像分类任务相对于人类视觉理解任务的复杂性和多样性来说是非常简单的。

图2 分类任务中的图像示例,一般图像构图完整且只包含一个物体
图像分类任务中的一张图像一般只关注一个目标,从而预测图像是什么(如图2所示)。但是我们在观察周围世界时要完成非常复杂的事情。

图3 现实生活中的场景一般包含各种各样相互重叠的不同目标、背景和动作
现实世界中的复杂场景一般存在相互重叠的目标和不同背景,我们在观察时不仅能够分辨不同的目标,而且可以识别不同目标的边界、差异以及他们之间的(空间)关系。

图4 图像分割任务的目标是对图像中的不同物体进行分类,并识别其边界。(源于:[1703.06870] Mask R-CNN)
CNNs是否可以帮助我们完成如此复杂的任务?也就是说,给定一张复杂的图像,我们是否可以利用CNNs识别图像中的不同目标以及他们的边界呢?Ross Girshick和他的同事近几年的研究表明,答案是当然可以!
本文目标
本博文涵盖目标检测和分割中所用主要技术背后的知识,以及这些技术的演化过程,特别是R-CNN(Regional CNN)(CNNs最初应用于检测和分割问题的方法)及其派生Fast R-CNN和Faster R-CNN,最后我们会讲述Facebook Research最新提出的Mask R-CNN,对这类目标检测问题扩展到像素级图像分割。本博文中引用的论文如下:
- R-CNN: [1311.2524] Rich feature hierarchies for accurate object detection and semantic segmentation
- Fast R-CNN: [1504.08083] Fast R-CNN
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- Mask R-CNN: [1703.06870] Mask R-CNN
2014: R-CNN - An Early Application of CNNs to Object Detection

图5 目标检测算法(如R-CNN)识别图像中主要物体的位置和类别
受Toronto大学Hinton实验室研究成果的启发,UC Berkeley大学Jitendra Malik教授的团队提出当今看来不可避免的问题:
Krizhevsky等的研究成果如何才能扩展到目标检测?
目标检测任务从图像中找到不同的物体并对其进行分类(如图5所示)。Ross Girshick (a name we’ll see again)、Jeff Donahue和Trevor Darrel团队发现目标检测问题可以借助于Krizhevsky的成果并在PASCAL VOC数据集(ImageNet挑战中的目标检测数据集)中进行测试,文中提到:
这篇论文首次表明了在PASCAL VOC数据集上的目标检测任务中,CNNs能够获得比传统特征(如HOG特征等)好很多的性能。
接下来我们一起理解一下Regions CNNs(R-CNN)工作的架构。
理解R-CNN
R-CNN的目标是从图像中正确识别出主要的物体(采用bounding box进行标注):
- 输入:图像
- 输出:图像中每个物体的Bounding Box+标签
如何找出这些bounding box呢?R-CNN采用我们直觉上认为的方式:给出一堆图像可能的box,然后判断这些box是否和物体相关。

图6 Selective Search方法采用不同尺寸的窗口进行滑动,并查找那些相近纹理、颜色或亮度的相邻像素。(源于:https://www.koen.me/research/pub/uijlings-ijcv2013-draft.pdf)
R-CNN采用Selective Search的方法给出region proposals。从高层理解,Selective Search通过不同尺寸的窗口在图像中进行滑动(如图6所示),对于每个尺寸方法采用纹理、颜色或亮度对邻近的像素进行聚合,从而识别物体。
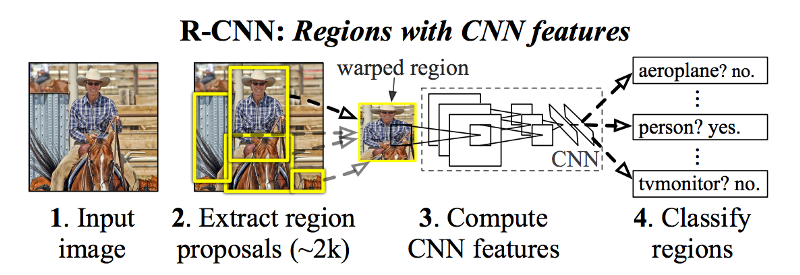
图7 获取region proposals集合之后,R-CNN采用AlexNet的修改版本判断这些region proposals是否是有效的region。(源于:[1311.2524] Rich feature hierarchies for accurate object detection and semantic segmentation)
获得region proposals集合之后,R-CNN将这些区域变换为标准的方形尺寸,并采用AlexNet的修改版本判断其是否是有效region(如图7所示)。
在CNN的最后一层,R-CNN增加了一个简单的分类器Support Vector Machine(SVM),用于判断区域是否是物体,以及物体的类别。
精化Bounding Box
现在已经找到Box中的物体,接下来是否可以tighten bounding box(进一步调整物体边界,使其更贴近物体周围),从而获取物体的真实范围呢?当然,这也是R-CNN的最后一步,R-CNN对region proposals进行简单的线性回归,从而生成tighten之后的Bounding Box做为最终结果。回归模型的输入和输出如下:
- 输入:物体在图像中的sub-regions
- 输出:sub-resions中物体的新Bounding Box坐标
总结一下,R-CNN的步骤如下:
- 生成regions proposals集合作为Bounding Box;
- 采用预训练的AlexNet+SVM判断Bouding Box对应图像的物体类型;
- 对已分类物体的Bounding Box进行线性回归,输出Box对应的tighter bounding boxes。
2015: Fast R-CNN - Speeding up and Simplifying R-CNN
R-CNN效果非常好,但是效率太低了,主要的原因:
- 对于每张图像的每个region proposal都需要进行前向的CNN(AlexNet)计算,大概每张图像需要2000次的前向CNN;
- 方法中的三个模型是分别训练的——CNN提取图像特征、分类器预测类别、回归模型tighten bounding box的边界,这也导致流程不易训练。
2015年,R-CNN的作者Ross Girshick解决了上述两个问题,并提出了Fast R-CNN的算法,接下来介绍一下Fast R-CNN。
RoI(Region of Interest)Pooling
Ross Girshick发现,每张图像的proposed regions总是朴素重叠的,从而导致重复的CNN前向计算(可能达到2000次)。他的想法非常简单——为什么不每张图像计算一次CNN,为2000个proposed regions找到一种计算共享的方法?
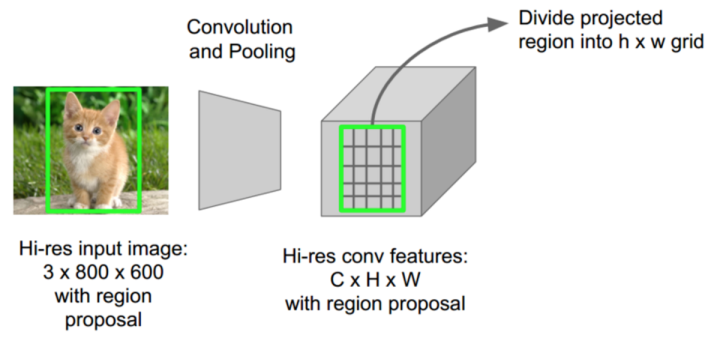
图8 在RoIPool方法中,采用一次CNN前向计算提取整幅图像的特征图,图像中每个region的特征则从上述特征图中提取。(源于:Stanford’s CS231N slides by Fei Fei Li, Andrei Karpathy, and Justin Johnson)
Fast R-CNN采用RoIPool(Region of Interest Pooling)解决此问题。作为方法的核心,RoIPool分享整幅图像的CNN前向计算给不同的regions。如图8所示,特别注意每个区域的CNN特征如何从CNN的特征图像中选择对应区域特征的。接下来对每个区域的特征进行pool操作(一般采用max pooling)。这样的话我们只需要一次原始图像的CNN前向计算,而非R-CNN中的2000次!
Combine All Models into One Network
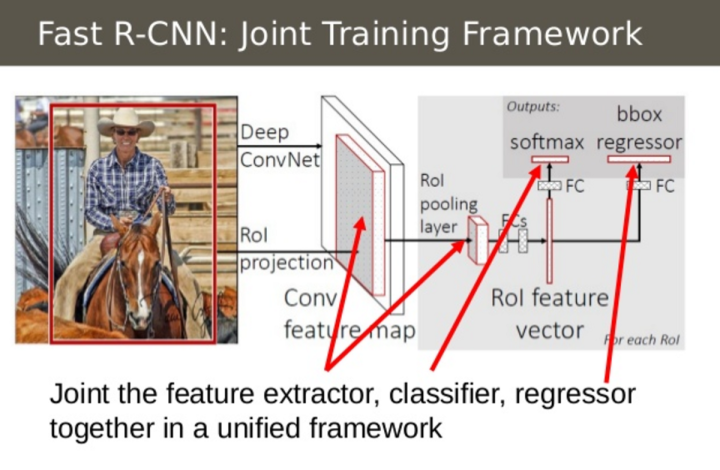
图9 Fast R-CNN将CNN、分类器和边界线性回归融合到一个单独的网络中。(源于:https://www.slideshare.net/simplyinsimple/detection-52781995)
Fast R-CNN第二个想法是将CNN、分类和边界线性回归的训练融合到一个单独的网络中。不像R-CNN中的特征提取(CNN)、分类(SVM)和边界tighten(回归)分别采用三个不同的模型,Fast R-CNN采用一个单独网络实现上述三个步骤。
图9展示了具体融合的过程,Fast R-CNN采用softmax layer取代了SVM分类器作为CNN网络的类别输出层,方法增加了一个平行于softmax layer的linear regression layer作为网络的边界坐标输出层,这样所有的输出需要来自于同一个网络!整个模型的输入和输出如下:
- 输入:图像以及region proposals
- 输出:每个区域对应物体的类别以及物体的tighter bounding boxes
2016: Faster R-CNN - Speeding Up Region Proposal
经过上述的改进,Fast R-CNN仍然存在一个瓶颈——region proposer。目标检测方法的第一步就是生成用于测试的潜在bouding box集合或者regions of interest,Fast R-CNN中采用的Selective Search速度非常慢,这也是限制整个算法效率的主要瓶颈。
2015年中,微软的研究团队(Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun)提出一种Faster R-CNN的方法,使得region proposal非常高效。
Faster R-CNN的想法来源于region proposals的特征计算依赖于图像的特征(采用CNN一次性计算整幅图像的特征),那么为何不重用这些相同的CNN特征进行region proposals,从而取代单独的selective search算法呢?
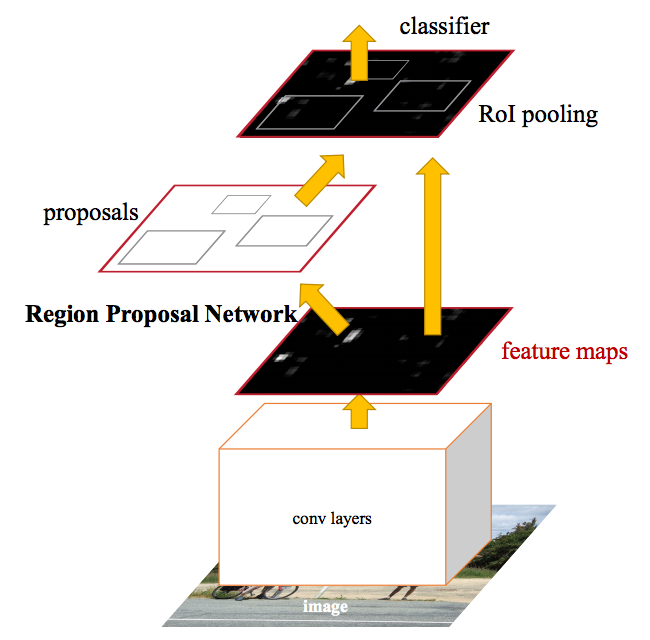
图10 Faster R-CNN方法中采用一个单独的CNN进行region proposals和分类。(源于:Towards Real-Time Object Detection with Region Proposal Networks)
实际上,这就是Faster R-CNN方法的核心。图10描述了单独CNN完成region proposals和分类的过程。这样只需要训练一个CNN,region proposals的计算基本可以忽略。文中描述:
我们发现用于检测区域的卷积特征图(类似于Fast R-CNN)同样可以用来生成region proposals(因此使得region proposals变得毫不费力)。
模型的输入和输出如下:
- 输入:图像(不需要region proposals)
- 输出:图像中物体的类别及其对应的bounding box坐标
How the Regions are Generated
接下来讨论一下Faster R-CNN如何从CNN特征图中生成region proposals。Faster R-CNN在CNN特征的上层增加了一个全卷积网络,即Region Proposal Network.
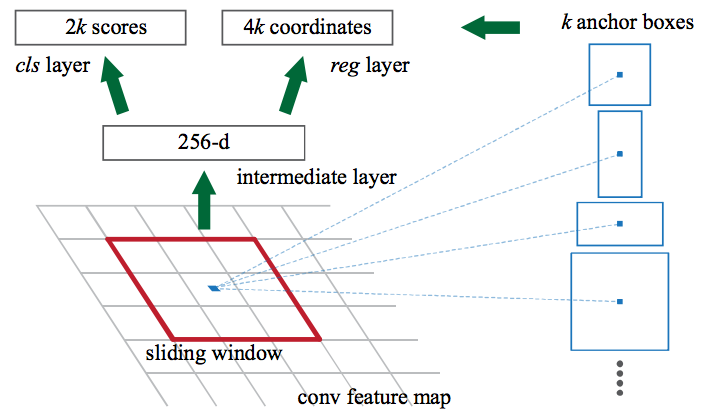
图11 Region Proposal Network在CNN的特征图上进行滑动窗口操作,对于每个窗口的位置,网络会对每个anchor(候选区域)输出分数和bounding box(共4*k个box坐标,k是anchor的个数)。(源于:Towards Real-Time Object Detection with Region Proposal Networks)
Region Proposal Network在CNN特征图上进行滑动窗口操作,然后每个窗口,输出k个潜在的bounding box和分数,k个boxes如何选择和表达呢?

图12 一般行人的bouding box趋向于竖直长方形,据此我们可以构建这样维度的anchor,从而Region Proposal Network的先验知识。(源于:[CSE 6367 - Assignments - Assignment 1])
直觉上,我们会认为图像中的物体应该符合一定的大小和长宽比,比如行人的形状更可能是长方形的box。类似地,我们一般也不会关注那些非常窄的boxes。据此,我们构建了k个这样的common aspect ratios,并称作anchor boxes。每个anchor box输出bounding box和对应的位置图像的分数。
考虑这些anchor boxes,Region Proposal Network的输入和输出如下:
- 输入:CNN特征图
- 输出:每个anchor对应的bounding box以及分数(表示bounding box中对应图像部分是物体的可能性)
然后,将Region Proposal Network中输出的目标可能bounding box输入到Fast R-CNN,并生成类别和tightened bounding box。
2017: Mask R-CNN - Extending Faster R-CNN for Pixel Level Segmentation

图13 图像实例分割的目标是识别场景中像素级的物体。(源于:[1703.06870] Mask R-CNN])
到这里我们已经可以利用CNN特征快速定位图像中不同目标的bounding boxes了,那么接下来是否可以继续延伸一下,提取像素级的目标实例而不是仅仅给出bounding boxes呢?这就是经典的图像分割问题,Kaiming He和他的团队(包括Girshick)在Facebook AI实验室中采用的架构,Mask R-CNN。
类似于Fast R-CNN和Faster R-CNN,Mask R-CNN的潜在创意来源也是很直接的,鉴于Faster R-CNN在目标检测中的效果,我们是否可以将其扩展到像素级的图像分割中呢?
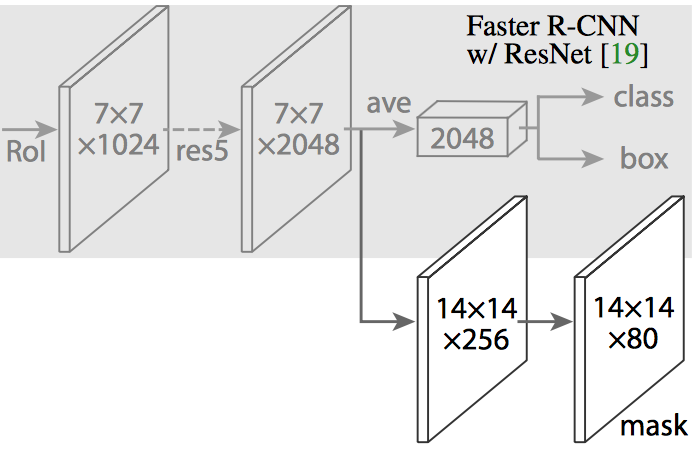
图14 Mask R-CNN在Faster R-CNN的CNN特征提取层的上层增加一个全卷积网络(Fully Convolutional Network,FCN)用于生成mask(分割输出结果)。(源于:[1703.06870] Mask R-CNN)
Maks R-CNN在Faster R-CNN的基础上增加一个分支,用于输出一个二值掩膜(Binary Mask),判断给定像素是否属于物体。上述分支(图14中的白色部分)就是一个置于CNN特征图上层的全卷积神经网络。模型的输入和输出如下:
- 输入:CNN特征图
- 输出:指示像素是否属于物体的二值矩阵
但是Mask R-CNN的作者做了少量调整使得整个网络输出期望的结果。
RoiAlign - Realigning RoIPool to be More Accurate
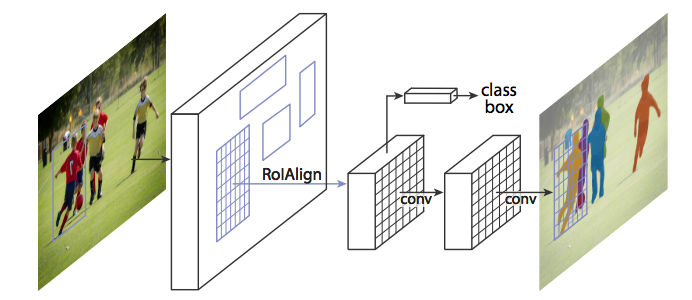
图15 采用RoIAlign取代RoIPool对图像进行遍历,从而使得RoIPool选择区域的特征图与原始图像对应更加精确,主要原因是像素级的分割比bounding box需要更加精确的对齐。(源于:[1703.06870] Mask R-CNN)
直接采用Faster R-CNN的架构执行Mask R-CNN可能导致RoIPool选择区域的特征图与原始图像区域存在少量的偏离。由于图像分割需要像素级的标记,因此这样自然会导致精度下降。
Mask R-CNN采用RoIAlign的方法对RoIPool进行调整使其更精确对齐。
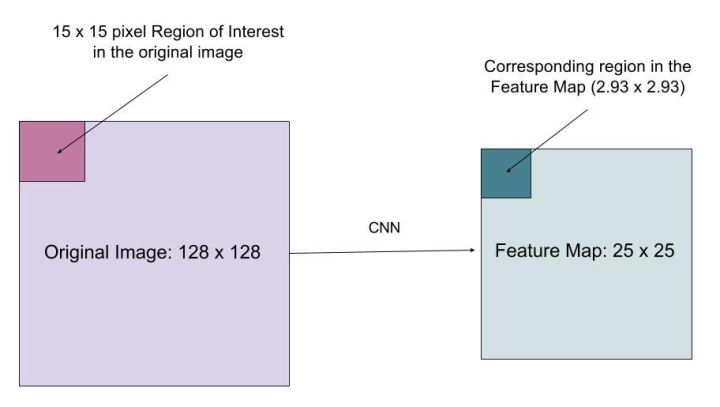
图16 如何将region of interest的原始图像和特征图精确对齐?
假设有一幅128*128大小的图像,对应的特征图大小为25*25,如果要将原始图像左上角15*15大小的像素映射到特征图中(如图16所示),如何从特征图中选择像素呢?显然原始图像中每个像素对应特征图中的25*128个像素,要选择原始图像中的15个像素,需要选择15*25/128=2.93个像素。
在RoIPool中,我们会四舍五入选择3个像素,从而会导致微小的偏移。在RoIAlign中,我们要避免这样的近似。取而代之的是采用bilinear interpolation获取精确的对应值,即选择像素2.93,从而能够避免RoIPool导致的偏移。
生成这些mask之后,Mask R-CNN结合Faster R-CNN中生成的分类和bounding box,生成精确的分割结果。

图17 Mask R-CNN能够分割图像并对图像中的物体进行分类。(源于:[1703.06870] Mask R-CNN)
源码
如果你想自己试验一下这些算法,这里是相关的源码库:
Faster R-CNN
- Caffe: rbgirshick/py-faster-rcnn
- PyTorch: longcw/faster_rcnn_pytorch
- MatLab: ShaoqingRen/faster_rcnn
Mask R-CNN
- PyTorch: felixgwu/mask_rcnn_pytorch
- TensorFlow: CharlesShang/FastMaskRCNN
物体检测丨从R-CNN到Mask R-CNN的更多相关文章
- 物体检测丨Faster R-CNN详解
这篇文章把Faster R-CNN的原理和实现阐述得非常清楚,于是我在读的时候顺便把他翻译成了中文,如果有错误的地方请大家指出. 原文:http://www.telesens.co/2018/03/1 ...
- 物体检测丨浅析One stage detector「YOLOv1、v2、v3、SSD」
引言 之前做object detection用到的都是two stage,one stage如YOLO.SSD很少接触,这里开一篇blog简单回顾该系列的发展.很抱歉,我本人只能是蜻蜓点水,很多细节也 ...
- 物体检测之FPN及Mask R-CNN
对比目前科研届普遍喜欢把问题搞复杂,通过复杂的算法尽量把审稿人搞蒙从而提高论文的接受率的思想,无论是著名的残差网络还是这篇Mask R-CNN,大神的论文尽量遵循著名的奥卡姆剃刀原理:即在所有能解决问 ...
- cs231n---语义分割 物体定位 物体检测 物体分割
1 语义分割 语义分割是对图像中每个像素作分类,不区分物体,只关心像素.如下: (1)完全的卷积网络架构 处理语义分割问题可以使用下面的模型: 其中我们经过多个卷积层处理,最终输出体的维度是C*H*W ...
- 利用modelarts和物体检测方式识别验证码
近来有朋友让老山帮忙识别验证码.在github上查看了下,目前开源社区中主要流行以下几种验证码识别方式: tesseract-ocr模块: 这是HP实验室开发由Google 维护的开源 OCR引擎,内 ...
- 快速上手百度大脑EasyDL专业版·物体检测模型(附代码)
作者:才能我浪费991. 简介:1.1. 什么是EasyDL专业版EasyDL专业版是EasyDL在2019年10月下旬全新推出的针对AI初学者或者AI专业工程师的企业用户及开发者推出的A ...
- 转-------基于R-CNN的物体检测
基于R-CNN的物体检测 原文地址:http://blog.csdn.net/hjimce/article/details/50187029 作者:hjimce 一.相关理论 本篇博文主要讲解2014 ...
- 深度学习笔记之基于R-CNN的物体检测
不多说,直接上干货! 基于R-CNN的物体检测 原文地址:http://blog.csdn.net/hjimce/article/details/50187029 作者:hjimce 一.相关理论 本 ...
- 手把手教你用深度学习做物体检测(五):YOLOv1介绍
"之前写物体检测系列文章的时候说过,关于YOLO算法,会在后续的文章中介绍,然而,由于YOLO历经3个版本,其论文也有3篇,想全面的讲述清楚还是太难了,本周终于能够抽出时间写一些YOLO算法 ...
随机推荐
- 从结果推断过程----->使用System.out和Root Device
刚才解决了一个App中更新的逻辑问题.出问题之后发现,有很多处调用了更新,后来都不知道是哪里改写了SharedPreferences. 然后一直在挨个寻找每一处更新的地方,花了很多时间. 最后直接使用 ...
- BZOJ_1818_[Cqoi2010]内部白点 _扫描线+树状数组
BZOJ_1818_[Cqoi2010]内部白点 _扫描线+树状数组 Description 无限大正方形网格里有n个黑色的顶点,所有其他顶点都是白色的(网格的顶点即坐标为整数的点,又称整点).每秒钟 ...
- ACM学习历程—BestCoder 2015百度之星资格赛1004 放盘子(策略 && 计算几何)
Problem Description 小度熊喜欢恶作剧.今天他向来访者们提出一个恶俗的游戏.他和来访者们轮流往一个正多边形内放盘子.最后放盘子的是获胜者,会赢得失败者的一个吻.玩了两次以后,小度熊发 ...
- bzoj3456城市规划 多项式取模
題目大意 求出有n个点的有标号简单连通无向图的数目. 题解 什么破玩意,直接输出\(2^{C_n^2}\)走人 我们发现这张图要求连通,而上式肯定不能保证连通. 其实上式表示的是不保证连通的有标号简单 ...
- CRC16算法之二:CRC16-CCITT-XMODEM算法的java实现
CRC16算法系列文章: CRC16算法之一:CRC16-CCITT-FALSE算法的java实现 CRC16算法之二:CRC16-CCITT-XMODEM算法的java实现 CRC16算法之三:CR ...
- bootstrap模版兼容IE浏览器代码嵌入
1. bootstrap模板为使IE6.7.8版本(IE9以下版本)浏览器兼容html5新增的标签,引入下面代码文件即可. <script src="https://oss.maxc ...
- 1.改变项目 动态库、静态库属性。 2.使用运行库 /MD、/MT、/LD说明
/MD./MT./LD(使用运行库) 有关 C 运行库以及使用 /clr(公共语言运行时编译) 进行编译时要使用哪些库的更多信息,请参见 CRT 库功能. 传递给链接器的给定调用的所有模块都必须使用相 ...
- shell里的` ` $( ) ${ } expr $(( ))
转自:http://blog.sina.com.cn/s/blog_6151984a0100ekz2.html 所有UNIX命令,要取结果或输出,都要用$( )或反引号` ` tt=` file te ...
- js避免命名冲突
[1]工程师甲编写功能A var a = 1; var b = 2; alert(a+b); [2]工程师乙添加新功能B var a = 2; var b = 1; alert(a-b); [3]上一 ...
- oracle处理重复数据
oracle查找重复记录 SELECT *FROM t_info aWHERE ((SELECT COUNT(*) FROM t_info WHERE Title ...