ubuntu 16.0安装 hadoop2.8.3
环境:ubuntu 16.0
需要软件:jdk ssh
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
2.8.3
安装 jdk并配置环境变量
安装ssh和rshync,主要设置免密登录
sudo apt-get install ssh
sudo apt-get install rshync
sh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
ssh
安装hadoop
root@hett-virtual-machine:/usr/local/hadoop# tar -xzvf /home/hett/Downloads/hadoop-2.8.3.tar.gz
root@hett-virtual-machine:/usr/local/hadoop# mv hadoop-2.8.3 hadoop
root@hett-virtual-machine:/usr/local# cd hadoop/
root@hett-virtual-machine:/usr/local/hadoop# mkdir tmp
root@hett-virtual-machine:/usr/local/hadoop# mkdir hdfs
root@hett-virtual-machine:/usr/local/hadoop# mkdir hdfs/data
root@hett-virtual-machine:/usr/local/hadoop# mkdir hdfs/name
root@hett-virtual-machine:/usr/local/hadoop# nano /etc/profile
配置
export HADOOP_HOME=/usr/local/hadoop
export JAVA_HOME=/usr/local/jdk1.8.0_151
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH:$HADOOP_HOME/bin
root@hett-virtual-machine:/usr/local/hadoop# source /etc/profile
root@hett-virtual-machine:/usr/local/hadoop# cd etc/hadoop/
root@hett-virtual-machine:/usr/local/hadoop/etc/hadoop# ls
capacity-scheduler.xml httpfs-env.sh mapred-env.sh
configuration.xsl httpfs-log4j.properties mapred-queues.xml.template
container-executor.cfg httpfs-signature.secret mapred-site.xml.template
core-site.xml httpfs-site.xml slaves
hadoop-env.cmd kms-acls.xml ssl-client.xml.example
hadoop-env.sh kms-env.sh ssl-server.xml.example
hadoop-metrics2.properties kms-log4j.properties yarn-env.cmd
hadoop-metrics.properties kms-site.xml yarn-env.sh
hadoop-policy.xml log4j.properties yarn-site.xml
hdfs-site.xml mapred-env.cmd
root@hett-virtual-machine:/usr/local/hadoop/etc/hadoop#
root@hett-virtual-machine:/usr/local/hadoop/etc/hadoop# nano hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_151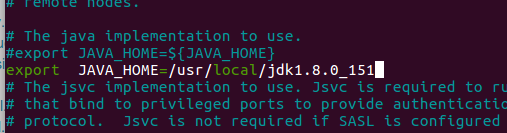
配置yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_151
3)配置core-site.xml
添加如下配置:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>4),配置hdfs-site.xml
添加如下配置
<configuration>
<!—hdfs-site.xml-->
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
</configuration>5),配置mapred-site.xml
添加如下配置:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>6),配置yarn-site.xml
添加如下配置:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.241.128:8099</value>
</property>
</configuration>4,Hadoop启动
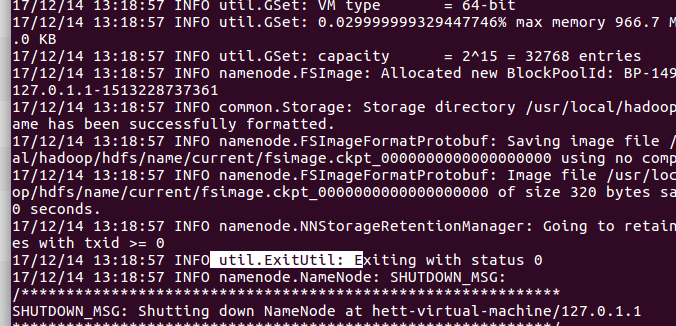
1)格式化namenode
$ bin/hdfs namenode –format
2)启动NameNode 和 DataNode 守护进程
$ sbin/start-dfs.sh3)启动ResourceManager 和 NodeManager 守护进程
$ sbin/start-yarn.sh

- $ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
- $ ssh-keygen -t rsa # 会有提示,都按回车就可以
- $ cat id_rsa.pub >> authorized_keys # 加入授权

root@hett-virtual-machine:~# cd /usr/local/hadoop/
root@hett-virtual-machine:/usr/local/hadoop# sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-hett-virtual-machine.out
localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-hett-virtual-machine.out
........
5,启动验证
1)执行jps命令,有如下进程,说明Hadoop正常启动
# jps
6097 NodeManager
11044 Jps
7497 -- process information unavailable
8256 Worker
5999 ResourceManager
5122 SecondaryNameNode
8106 Master
4836 NameNode
4957 DataNode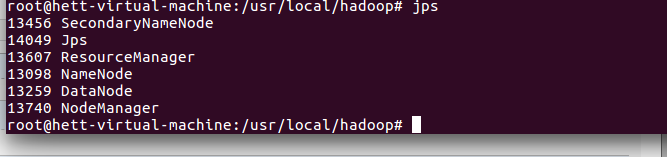
ubuntu 16.0安装 hadoop2.8.3的更多相关文章
- Ubuntu 16.04安装Vim8.0
Ubuntu 16.04安装Vim8.0 https://www.aliyun.com/jiaocheng/131859.html sudo add-apt-repository ppa:jonath ...
- Ubuntu 16.04 安装Mysql 5.7 踩坑小记
title:Ubuntu 16.04 安装Mysql 5.7 踩坑小记 date: 2018.02.03 安装mysql sudo apt-get install mysql-server mysql ...
- ubuntu 16.04 安装 tensorflow-gpu 包括 CUDA ,CUDNN,CONDA
ubuntu 16.04 安装 tensorflow-gpu 包括 CUDA ,CUDNN,CONDA 显卡驱动装好了,如图: 英文原文链接: https://github.com/williamFa ...
- Ubuntu 16.04 安装 VMware Tools(解决windows和Ubuntu之间不能互相复制粘贴文件的问题)
Ubuntu 16.04安装虚拟工具VMware Tools,指的是在虚拟机VMWare安装Ubuntu 16.04后再安装VMware Tools的过程.很多人接触Linux都是从虚拟机开始,而安装 ...
- Ubuntu 16.04 安装Mysql数据库
系统环境 Ubuntu 16.04; 安装步骤 1.通过以下环境安装mysql服务端与客户端软件 sudo apt-get install mysql-server apt-get isntall m ...
- Ubuntu 16.04安装sogou 拼音输入法
一.更换为国内的软件源 安装搜狗输入法之前请先更换为国内的软件源,否则无法解决依赖问题.首先,用以下命令打开源列表: sudo gedit /etc/apt/sources.list #用文本编辑器打 ...
- ubuntu 16.04 安装Tensorflow
ubuntu 16.04 安装Tensorflow(CPU) 安装python ubuntu 16.04自带python2.7,因此可以略过这一步 安装pip sudo apt-get install ...
- Ubuntu 16.04安装tensorflow_gpu的方法
参考资料: Ubuntu 16.04安装tensorflow_gpu 1.9.0的方法 装Tensorflow,运行项目报错: module compiled against API version ...
- ubuntu 16.04 安装pycharm
Ubuntu16.04下安装Cuda8.0+Caffe+TensorFlow-gpu+Pycharm过程(Simple) ubuntu 16.04 安装pycharm 1.安装java jdk 直接 ...
随机推荐
- Android开发---开发文档翻译
2014.11.24 1:ClipData类:用于表示剪切的数据,此剪切的数据可以是复杂类型,包括一个或多个条目实例 (1)基础知识 >公共类:public class >嵌套类:Clip ...
- intellj idea 使用
1. 导入包快捷 Alt + Enter 2. 查看方法注释,点击进入源码即可,若想和eclipse一样鼠标停留即可出现注释提示,开启方法为: Preferences->Editor->G ...
- Mybatis:resultMap的使用总结(转自https://www.cnblogs.com/kenhome/p/7764398.html)
resultMap是Mybatis最强大的元素,它可以将查询到的复杂数据(比如查询到几个表中数据)映射到一个结果集当中. resultMap包含的元素: <!--column不做限制,可以为任意 ...
- Untiy PoolManager随手记
用法,1是获取,2是清除, 问题是这个池到底能做什么用 首先用这个池生成的对象是在池节点下使用,而不是取出来用(可以取出来用,直接transform.parent赋值就可以) 疑问,池里面的节点时什么 ...
- 聪明的质监员(codevs 1138)
题目描述 Description 小 T 是一名质量监督员,最近负责检验一批矿产的质量.这批矿产共有n 个矿石,从1到n 逐一编号,每个矿石都有自己的重量wi 以及价值vi.检验矿产的流程是:见图 ...
- [Xcode 实际操作]三、视图控制器-(2)UITabBarController选项卡(标签)视图控制器
目录:[Swift]Xcode实际操作 本文将为你演示,选项卡视图控制器的创建和使用. 在项目文件夹[DemoApp]上点击鼠标右键,弹出右键菜单. [New File]->[Cocoa Tou ...
- Java内存模型(Java Memory Model,JMM)
今天简单聊聊什么叫做 Java 内存模型,不是 JVM 内存结构哦. JMM 是一个语言级别的内存模型,处理器的硬件模型是硬件级别,Java中的内存模型是内存可见性的基本保证.从而为我们 volati ...
- angularJs自定义指令(directive)实现滑块滑动
最近老大让我一个效果实现在页面某一部分内滑块随着滚动条上下滑动,说明一下我们项目使用技术angularJs.大家都知道,使用jquery很好实现. 那么angular如何实现呢,我用的是自定义指令(d ...
- [題解]TYVJ_2032(搜索/最短路)
搜索:https://www.cnblogs.com/SiriusRen/p/6532506.html?tdsourcetag=s_pctim_aiomsg 來自 SiriusRen 數據範圍小,考慮 ...
- [未读]深入浅出node.js
还没看过,据说很多内容来自国外译文.