模式识别之ocr项目---(模板匹配&BP神经网络训练)
摘 要
在MATLAB环境下利用USB摄像头采集字符图像,读取一帧保存为图像,然后对读取保存的字符图像,灰度化,二值化,在此基础上做倾斜矫正,对矫正的图像进行滤波平滑处理,然后对字符区域进行提取分割出单个字符,识别方法一是采用模板匹配的方法逐个对字符与预先制作好的字符模板比较,如果结果小于某一阈值则结果就是模板上的字符;二是采用BP神经网络训练,通过训练好的net对待识别字符进行识别。最然后将识别结果通过MATLAB下的串口工具输出51单片机上用液晶显示出来。
关键字: 倾斜矫正,字符分割,模板匹配,BP神经网络,液晶显示
Abstract
In the MATLAB environmentusing USB camera capture the character images, saved as an image reading, thenread the saved character images, grayscale, binary, on this basis do tilt correction,the correction image smoothing filter, and then extract the character regionsegmentation of a single character, and then one by one using a templatematching method of character with good character template is a pre-production,if the result is less than a certain threshold, the result is a template of thecharacter. Second, the BP neural network trained by the trained net to identifythe character towards recognition The results will identify the most and thenthe serial port through the MATLAB tool output 51 under microcontroller withLCD display.
Keyword: Tilt correction, character segmentation,template matching, liquid crystal display
一 引言:
光学字符识别(OCR,Optical Character Recognition)是指对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。已有30多年历史,近几年又出现了图像字符识别(image character recognition,ICR)和智能字符识别(intelligent character recognition,ICR),实际上这三种自动识别技术的基本原理大致相同。
关于字符识别的方法有很多种,最简单的就是模板匹配,还有根据采集到的字符用BP神经网络或者SVM来训练得到结果的方式。本文主要针对模板匹配的方式,在MATLAB环境下编程实现。
二 字符图像获取:
在MATLAB下利用image acquisition toolbox获取视频帧,并保存图像在工程文件夹内。摄像头采用普通的USB摄像头,由于这种摄像头拍摄的照片延时比较大,所以先用image acquisition toolbox下的对视频进行预览,调整出最佳的效果来,采集的图像效果越好则识别率越高。 根据测试,实验选择640*480的视频获取窗口,颜色空间选取为RGB空间,获取一帧后保存为jpg的存储格式。

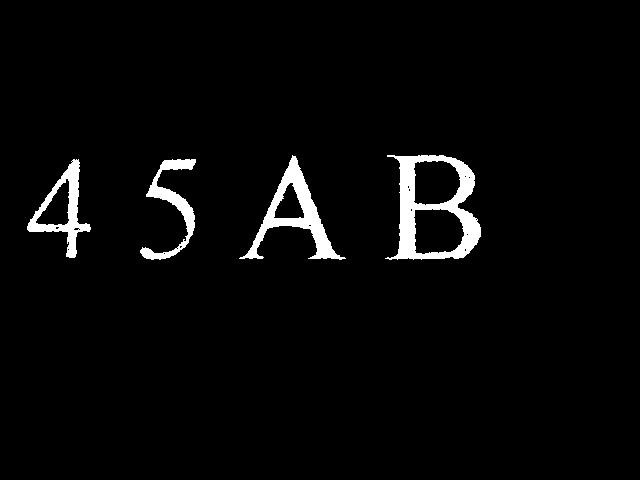
三 字符预处理
3.1字符矫正
由于摄像头拍摄的图像存在一定存在的倾斜度,在分割字符区域时,应先对字符进行矫正。过程如下:
将通过摄像头获取的保存帧图像灰度化,然后对其进行边缘提取,再在1到180度角内对图像进行旋转,记录下边缘提取后的图像在x轴方向上的投影,当x轴方向上的投影最小的时候即表示图像中字符平行于y轴,已经完成矫正,此时记录下旋转的倾斜角。然后利用imrotate函数实现对字符图像的矫正。
3.2 字符区域分割:
在第三步完成对字符图像的倾斜矫正后,将图像分别做x轴和y轴方向上的投影既可以知道字符区域在x轴上的像素分布范围和y轴上的像素分布范围,然后对根据这个范围对图像做分割,在MATLAB中表示为:
goal=I(ix1:iy1,jx1:jy1);
其中goal为分割后的图像,I为分割前的图像,ix1和ix2分别为x轴上投影的像素范围的起始坐标值和终止坐标值,iy1和iy2分别为y轴上投影的像素范围的起始坐标值和终止坐标值。

3.3 单个字体分割:
在分割得到的字符区域图像上,只需要做y轴上的投影就可以知道每个字符在y轴上的分布区间,然后利用这个分布区间就可以分割出单个字符。

3.4 单个字体裁剪
在第五步分割出来的字符基础上进一步对字符的像素区域进行裁剪,原理也是分别做x轴,y轴方向上的投影,求的字符的区间再做剪裁。
四 模板字符识别
4.1字符模板制作:
模板的要求是与要识别的字符的字体格式一致,实验中采用word上的标准字符,通过截图软件截图后按照3-6步的处理过程制作出需要的字符模板,从0到9共10个数字,A到Z共26个字母。
4.2 字符模板归一化
在满足识别率的条件下,尽量采用小模板识别可以提神运算速度,具体的模板大小,可以根据后面的与待识别字符的比较中调节。
4.3识别过程:
将待识别字符与字符模板做同样的归一化处理,然后遍历与字符模板比较,处理方法为先和字符模板做差,然后计算做差后的图像的总像素值,如果小于每一个阈值,则表示该待识别字符和该模板是同一个字符,这样就完成了一次识别。
循环对要识别的字符做同样的处理就可以识别出所有的字符,将结果保存在字符串中。
五 BP神经网络字符识别
BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(outputlayer)。
BP (Back Propagation)神经网络,即误差反传误差反向传播算法的学习过程,由信息的正向传播和误差的反向传播两个过程组成。输入层各神经元负责接收来自外界的输入信息,并传递给中间层各神经元;中间层是内部信息处理层,负责信息变换,根据信息变化能力的需求,中间层可以设计为单隐层或者多隐层结构;最后一个隐层传递到输出层各神经元的信息,经进一步处理后,完成一次学习的正向传播处理过程,由输出层向外界输出信息处理结果。当实际输出与期望输出不符时,进入误差的反向传播阶段。误差通过输出层,按误差梯度下降的方式修正各层权值,向隐层、输入层逐层反传。周而复始的信息正向传播和误差反向传播过程,是各层权值不断调整的过程,也是神经网络学习训练的过程,此过程一直进行到网络输出的误差减少到可以接受的程度,或者预先设定的学习次数为止。
BP神经网络模型BP网络模型包括其输入输出模型、作用函数模型、误差计算模型和自学习模型。
(1)节点输出模型
隐节点输出模型:Oj=f(∑Wij×Xi-qj) (1)
输出节点输出模型:Yk=f(∑Tjk×Oj-qk) (2)
f-非线形作用函数;q -神经单元阈值。
图1 典型BP网络结构模型
(2)作用函数模型
作用函数是反映下层输入对上层节点刺激脉冲强度的函数又称刺激函数,一般取为(0,1)内连续取值Sigmoid函数: f(x)=1/(1+e) (3)
(3)误差计算模型
误差计算模型是反映神经网络期望输出与计算输出之间误差大小的函数:
Ep=1/2×∑(tpi-Opi) (4)
tpi- i节点的期望输出值;Opi-i节点计算输出值。
(4)自学习模型
神经网络的学习过程,即连接下层节点和上层节点之间的权重拒阵Wij的设定和误差修正过程。BP网络有师学习方式-需要设定期望值和无师学习方式-只需输入模式之分。自学习模型为
△Wij(n+1)= h ×Фi×Oj+a×△Wij(n) (5)
h -学习因子;Фi-输出节点i的计算误差;Oj-输出节点j的计算输出;a-动量因子。
5.1 训练样本制作:
在不同分辨率和不同倾斜角度下分别采集几组图片作为训练样本,本实验为了节省计算时间,根据需要只做12345ABCDE这10个字符的识别,因此只各采集了10组数据。不同分辨率下5组,不同倾斜角度下5组。然后按照2-4上的操作过程的对字符进行处理,获得32*32大小的训练样本共100个。
5.2设计BP神经网络
利用MATLAB下的神经网络工具设计一个,以字符图像的x轴y轴像素值为输入特征作为输入层的输入;以logsig函数作为隐含层,隐含层设计节点25个,输出层就是预期的结果,共十种可能,所以有输出层有十种输出。
net=newff(pr,[25 1],{'logsig' 'purelin'},'traingdx', 'learngdm');
net.trainParam.epochs=250;%训练步数
net.trainParam.goal=0.001;%目标误差
net.trainParam.show=10;%系统每10步显示一次训练误差的变化曲线
net.trainParam.lr=0.05; %学习速度
net=train(net,p,t)%训练
并保存训练结果save name net
5.3 BP训练
首先对待识别字符预处理,然后读取读取训练好的网络load name net,通过sim函数对字符进行识别,结果输出,保存在一个字符串内。
六 识别结果发送下位机
利用MTLAB下的串口工具发送识别出的结果给下位机,下位机为51核的单片机,然后在单片机内经过程序处理驱动LM1602液晶显示结果。
5.1 MATLAB下的串口工具:
在Matlab6.0以上版本中新增的设备控制工具条(instrument control toolbox)具备支持计算机与其它具有串口的外部设备之间的通信的功能。其特点如下:
a、支持基于串行接口(RS-232、RS-422、RS-485)的通信;
b、通信数据支持二进制和文本(ASCII)两种方式;
c、支持异步通信和同步通信;
d、支持基于事件驱动的通信(亦称中断方式)。
5.2 下位机处理
5.2.1主控电路
主控芯片采用基于51核的STC12A50S8,51单片机是对目前所有兼容Intel 8031指令系统的单片机的统称。
·8位CPU·4kbytes 程序存储器(ROM)(52为8K)
·256bytes的数据存储器(RAM)(52有384bytes的RAM)
·32条I/O口线·111条指令,大部分为单字节指令
·21个专用寄存器
·2个可编程定时/计数器·5个中断源,2个优先级(52有6个)
·一个全双工串行通信口
·外部数据存储器寻址空间为64kB
·外部程序存储器寻址空间为64kB
·逻辑操作位寻址功能·双列直插40PinDIP封装
·单一+5V电源供电
CPU:由运算和控制逻辑组成,同时还包括中断系统和部分外部特殊功能寄存器;
RAM:用以存放可以读写的数据,如运算的中间结果、最终结果以及欲显示的数据;
ROM:用以存放程序、一些原始数据和表格;
I/O口:四个8位并行I/O口,既可用作输入,也可用作输出;
T/C:两个定时/记数器,既可以工作在定时模式,也可以工作在记数模式;
五个中断源的中断控制系统;
一个全双工UART(通用异步接收发送器)的串行I/O口,用于实现单片机之间或单片机与微机之间的串行通信;
片内振荡器和时钟产生电路,石英晶体和微调电容需要外接。最高振荡频率为12M。
5.2.2 液晶显示电路
实验中显示模板采用1602字符型液晶,它是工业字符型液晶,能够同时显示16x02即32个字符。602液晶模块内部的字符发生存储器(CGROM)已经存储了160个不同的点阵字符图形,这些字符有:阿拉伯数字、英文字母的大小写、常用的符号、和日文假名等,每一个字符都有一个固定的代码,比如大写的英文字母“A”的代码是01000001B(41H),显示时模块把地址41H中的点阵字符图形显示出来,我们就能看到字母“A”。
因为1602识别的是ASCII码,试验可以用ASCII码直接赋值,在单片机编程中还可以用字符型常量或变量赋值,如'A’。
5.2. 3 串口通信图:
由于单片机的串口输出为TTL电平,与PC机通信是需要采用转换为RS232电平,实验中使用美信公司的MAX232芯片。它是美信公司专门为电脑的RS-232标准串口设计的单电源电平转换芯片,使用+5v单电源供电。
七 总结:
本实验完成了usb摄像头的视频帧图像采集,并对采集图像进行了数字图像处理,采用模板匹配和BP神经网络训练的方式对字符进行识别,并利用MATLAB下的串口工具和下位机单片机通信,发送识别结果显示在字符液晶上。
试验中存在的问题:一是,对图像字符进行分割的时候,如果图像采集的分辨率过低的话会出现字符断裂的情况,这时候要做的就是对字符进行连通域检测。二是在做本实验的程序都是针对特定字符进行处理的,没有做自适应的字符个数检测。三是BP训练样本数太少,所以训练后的网络对字符的识别结果并不好。这些都需要后续的改进。
八参考文献:
[ 1] 王鹏.基于神经网络的手写体字符识别 北京工业大学 , 2002
[ 2] 闫雪梅 ,王晓华 ,夏兴高. 基于 PCA和 BP神经网络算法的车牌字符识别 北京理工大学信息科学技术学院 2007
[ 3] 金城 二维图像特征研究 浙江大学博士论文 2006
[ 4] MATLAB2010R image processing tools
附录:
MATLAB程序:
一、模板匹配:
%%%%%%%%%%%%%%%%%模板字符识别1.0%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%朱本福
%利用usb摄像头在MATLAB中通过image acquisition toolbox
%获取一帧图片并保存为ocr.jpg在读取图片进行处理,采用模板匹配的
%方式进行识别,模板为根据操作制作的,最后将结果通过串口发送出去显示在单片机上
%MATLAB2010下开发
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
clc;
clear all;
close all;
vid = videoinput('winvideo', 1, 'YUY2_640x480');%视频获取字符图像
src = getselectedsource(vid);
vid.FramesPerTrigger = 1;
preview(vid);%预览
start(vid) ;
vid.ReturnedColorspace = 'rgb';
vid.FramesPerTrigger =1;
imaqmem(10000000);
frame = getsnapshot(vid) ;%获取一帧
figure(1);
imshow(frame)
imwrite(frame,'ocr.jpg','jpg');%保存该帧图片
stop(vid);
delete(vid);
I=imread('ocr.jpg');%读取测试图片
[m,n,z]=size(I)
figure(1);
imshow(I);title('测试图片')
I1=rgb2gray(I);
imwrite(I1,'I1.jpg');%保存二值化图像
figure(2);
imshow(I1);%显示二值化图像
%figure(3);
%imhist(I1);
Ic = imcomplement(I1);%取反
imwrite(Ic,'Ic.jpg');
figure(33);imshow(Ic);
BW = im2bw(Ic, graythresh(Ic));%二值化
imwrite(BW,'BW.jpg');
figure(5), imshow(BW);
bw=edge(I1,'prewitt');%边缘提取
imwrite(bw,'bw.jpg');
figure(32);imshow(bw);
theta=1:180;
[R,xp]=radon(bw,theta);
[I0,J]=find(R>=max(max(R)));%J记录了倾斜角
qingxiejiao=90-J
goal1=imrotate(BW,qingxiejiao,'bilinear','crop');
imwrite(goal1,'goal1.jpg');
figure,imshow(I1);title('correct image');
%中值滤波
goal3=medfilt2(goal1,[3,3]);
figure(19), imshow(goal3);
goal3=medfilt2(goal3,[3,3]);
imwrite(goal3,'goal3.jpg');
figure(19), imshow(goal3);
%求解X方向的投影像素范围
[ix1,iy1]=xfenge(goal1)
%求解y方向的投影像素范围
[jx1,jy1]=yfenge(goal1)
%字符区域分割:
goal4=goal3(ix1:iy1,jx1:jy1);
imwrite(goal4,'goal4.jpg');
figure(21);imshow(goal4);
[m,n]=size(goal4)
%[L,num] = bwlabel(goal4,8);%区域标记,1,2,3,4
ysum(n-1)=0;
for y=1:n-1
ysum(y)=sum(goal4(:,y));
end
%y=1:n-1;
%figure(12)
%plot(y,ysum)%画出y方向上的像素分布
%找出ysum分布的几个与y轴交点就是单个字符在y轴上分布的区间
i=1;j=1;
for y=1:n-2
if (ysum(y)==0)&(ysum(y+1)~=0)
yy(i)=y
i=i+1;
end
if (ysum(y)~=0)&(ysum(y+1)==0)
yx(j)=y
j=j+1;
end
end
[m_yy,n_yy]=size(yy);%求出字符的分布并分割
if n_yy==3 %根据n_yy和n_yx的个数及分布区间,选择分割区间
%segment
num1=goal4(1:m , 1:yx(1));%分割出字符1
figure(23);imshow(num1);
num2=goal4(1:m ,yy(1):yx(2));%分割出字符2
figure(24);imshow(num2);
num3=goal4(1:m , yy(2):yx(3));%分割出字符3
figure(25);imshow(num3);
num4=goal4(1:m , yy(3):n);%分割出字符4
figure(26);imshow(num4);
%[m1,n1]=size(num1)%求出各个字符的大小
%[m2,n2]=size(num2)
%[m3,n3]=size(num3)
%[m4,n4]=size(num4)
%对单个字符细分,避免字体出现大小不一致的情况,也就是再在x轴上进行分割
[ix1,iy1]=xfenge(num1)
[ix2,iy2]=xfenge(num2)
[ix3,iy3]=xfenge(num3)
[ix4,iy4]=xfenge(num4)
num1=goal4(ix1:iy1 , 1:yx(1));
figure(23);imshow(num1);
num2=goal4(ix2:iy2 ,yy(1):yx(2));
figure(24);imshow(num2);
num3=goal4(ix3:iy3 , yy(2):yx(3));
figure(25);imshow(num3);
num4=goal4(ix4:iy4 , yy(3):n);
figure(26);imshow(num4);
imwrite(num1, 'nnum1.bmp');
imwrite(num2, 'nnum2.bmp');
imwrite(num3, 'nnum3.bmp');
imwrite(num4, 'nnum4.bmp');
end
if n_yy==4 %根据n_yy和n_yx的个数及分布区间,选择分割区间
%segment
num1=goal4(1:m , yy(1):yx(1));
figure(23);imshow(num1);
num2=goal4(1:m ,yy(2):yx(2));
figure(24);imshow(num2);
num3=goal4(1:m , yy(3):yx(3));
figure(25);imshow(num3);
num4=goal4(1:m , yy(4):n);
figure(26);imshow(num4);
%[m1,n1]=size(num1)
%[m2,n2]=size(num2)
%[m3,n3]=size(num3)
%[m4,n4]=size(num4)
%对单个字符细分
[ix1,iy1]=xfenge(num1)
[ix2,iy2]=xfenge(num2)
[ix3,iy3]=xfenge(num3)
[ix4,iy4]=xfenge(num4)
num1=goal4(ix1:iy1 , yy(1):yx(1));
figure(23);imshow(num1);
num2=goal4(ix2:iy2 ,yy(2):yx(2));
figure(24);imshow(num2);
num3=goal4(ix3:iy3 , yy(3):yx(3));
figure(25);imshow(num3);
num4=goal4(ix4:iy4 , yy(4):n);
figure(26);imshow(num4);
imwrite(num1, 'nnum1.bmp');
imwrite(num2, 'nnum2.bmp');
imwrite(num3, 'nnum3.bmp');
imwrite(num4, 'nnum4.bmp');
end
for i=1:36 %将模板归一化
imageName=strcat(num2str(i),'.bmp');
I = imread(imageName);
% figure;imshow(imageName);
M{i}=imresize(I,[16,12],'nearest');
%figure;imshow(M{i});
end
Rchar(4)='0';
for i=1:4
imagenum=strcat('nnum',num2str(i),'.bmp');
J=imread(imagenum);
[m,n]=size(J)
num{i}=imresize(J,[16,12],'nearest'); %待识别字符归一化
[m,n]=size(num{i})
figure;imshow(num{i});
for j=1:36
MM{j}=xor(num{i} , M{j}); %差分比较
% figure;imshow(MM{j});
dist(j)=sum(sum(MM{j}))
if dist(j)<=28 %这个可以根据dist的具体情况选取,这里去18分割效果不错
char(i)=j
end
end
switch char(i)%遍历比较
case 1
Rchar(i)='1' ;
case 2
Rchar(i)='2';
case 3
Rchar(i)='3';
case 4
Rchar(i)='4' ;
case 5
Rchar(i)='5';
case 6
Rchar(i)='6';
case 7
Rchar(i)='7';
case 8
Rchar(i)='8';
case 9
Rchar(i)='9';
case 10
Rchar(i)='0';
case 11
Rchar(i)='A' ;
case 12
Rchar(i)='B';
case 13
Rchar(i)='C';
case 14
Rchar(i)='D' ;
case 15
Rchar(i)='E';
case 16
Rchar(i)='F';
case 17
Rchar(i)='G' ;
case 18
Rchar(i)='H';
case 19
Rchar(i)='I';
case 20
Rchar(i)='J' ;
case 21
Rchar(i)='K';
case 22
Rchar(i)='L';
case 23
Rchar(i)='M' ;
case 24
Rchar(i)='N';
case 25
Rchar(i)='O';
case 26
Rchar(i)='P' ;
case 27
Rchar(i)='Q';
case 28
Rchar(i)='R';
case 29
Rchar(i)='S' ;
case 30
Rchar(i)='T';
case 31
Rchar(i)='U';
case 32
Rchar(i)='V' ;
case 33
Rchar(i)='W';
case 34
Rchar(i)='X';
case 35
Rchar(i)='Y' ;
case 36
Rchar(i)='Z';
otherwise
Rchar(i)='false' ;
end
end
schar=[Rchar(1),Rchar(2),Rchar(3),Rchar(4)]
%schar=['4','5','A','B']
sport1=serial('COM4');%串口输出字符
sport1.BaudRate=9600;
fopen(sport1);
fwrite(sport1,schar);
INSTRFIND
fclose(sport1);
delete(sport1);
clear sport1;
INSTRFIND
子函数:
%对分割出的单个字符进行分割x方向的再分割
function [ix,iy]=xfenge(goal1)
[m,n]=size(goal1);
ix(m)=0;
xx=0;j=1;
for x=1:m
for y=1:n
if goal1(x,y)==1;
xx=1;
end
end
if xx==1
ix(j)=x;
j=j+1;
end
end
ix=ix(1);
iy(m)=0;
xx=0;j=1;
for x=m:-1:1
for y=n:-1:1
if goal1(x,y)==1;
xx=1;
end
end
if xx==1
iy(j)=x;
j=j+1;
end
end
iy=iy(1);
子函数:
%对分割出的单个字符进行分割y方向的再分割
function [jx,jy]=yfenge(goal1)
[m,n]=size(goal1);
jx(m)=0;
xx=0;j=1;
for y=1:n
for x=1:m
if goal1(x,y)==1;
xx=1;
end
end
if xx==1
jx(j)=y;
j=j+1;
end
end
jx=jx(1)
jy(m)=0;
xx=0;j=1;
for y=n:-1:1
for x=m:-1:1
if goal1(x,y)==1;
xx=1;
end
end
if xx==1
jy(j)=y;
j=j+1;
end
end
jy=jy(1)
二、BP神经网络训练后识别:
clc;
clear all;
close all;
for kk = 0:99
p1=ones(16,16);
m=strcat('muban3\',int2str(kk),'.bmp');
x=imread(m,'bmp');
[i,j]=find(x==1);
imin=min(i);
imax=max(i);
jmin=min(j);
jmax=max(j);
bw1=x(imin:imax,jmin:jmax);%words segmentation
bw1=imresize(bw1,[16,16],'nearest');
[i,j]=size(bw1);
i1=round((16-i)/2);
j1=round((16-j)/2);
p1(i1+1:i1+i,j1+1:j1+j)=bw1;
for m=0:15
p(m*16+1:(m+1)*16,kk+1)=p1(1:16,m+1);
end
switch kk
case{0,10,20,30,40,50,60,70,80,90}
t(kk+1)=1;
case{1,11,21,31,41,51,61,71,81,91}
t(kk+1)=2;
case{2,12,22,32,42,52,62,72,82,92}
t(kk+1)=3;
case{3,13,23,33,43,53,63,73,83,93}
t(kk+1)=4;
case{4,14,24,34,44,54,64,74,84,94}
t(kk+1)=5;
case{5,15,25,35,45,55,65,75,85,95}
t(kk+1)=6;
case{6,16,26,36,46,56,66,76,86,96}
t(kk+1)=7;
case{7,17,27,37,47,57,67,77,87,97}
t(kk+1)=8;
case{8,18,28,38,48,58,68,78,88,98}
t(kk+1)=9;
case{9,19,29,39,49,59,69,79,89,99}
t(kk+1)=10;
end
end
% 创建和训练BP网络
pr(1:256,1)=0;
pr(1:256,2)=1;
net=newff(pr,[25 1],{'logsig' 'purelin'}, 'traingdx', 'learngdm');
net.trainParam.epochs=250;
net.trainParam.goal=0.001;
net.trainParam.show=10;
net.trainParam.lr=0.05;
net=train(net,p,t)
save E52net net;
% 识别
I=imread('ocr.jpg');%读取测试图片
[m,n,z]=size(I)
figure(1);
imshow(I);title('测试图片')
I1=rgb2gray(I);
% imwrite(I1,'I1.jpg');%保存二值化图像
figure(2);
imshow(I1);%显示二值化图像
%figure(3);
%imhist(I1);
Ic = imcomplement(I1);%取反
% imwrite(Ic,'Ic.jpg');
figure(33);imshow(Ic);
BW = im2bw(Ic, graythresh(Ic));%二值化
% imwrite(BW,'BW.jpg');
figure(5), imshow(BW);
bw=edge(I1,'prewitt');%边缘提取
% imwrite(bw,'bw.jpg');
figure(32);imshow(bw);
theta=1:180;
[R,xp]=radon(bw,theta);
[I0,J]=find(R>=max(max(R)));%J记录了倾斜角
qingxiejiao=90-J
goal1=imrotate(BW,qingxiejiao,'bilinear','crop');
% imwrite(goal1,'goal1.jpg');
figure,imshow(I1);title('correct image');
%中值滤波
goal3=medfilt2(goal1,[3,3]);
figure(19), imshow(goal3);
goal3=medfilt2(goal3,[3,3]);
% imwrite(goal3,'goal3.jpg');
figure(19), imshow(goal3);
%求解X方向的投影像素范围
[ix1,iy1]=xfenge(goal1)
%求解y方向的投影像素范围
[jx1,jy1]=yfenge(goal1)
%字符区域分割:
goal4=goal3(ix1:iy1,jx1:jy1);
% imwrite(goal4,'goal4.jpg');
figure(21);imshow(goal4);
[m,n]=size(goal4)
%[L,num] = bwlabel(goal4,8);%区域标记,1,2,3,4
ysum(n-1)=0;
for y=1:n-1
ysum(y)=sum(goal4(:,y));
end
%y=1:n-1;
%figure(12)
%plot(y,ysum)%画出y方向上的像素分布
%找出ysum分布的几个与y轴交点就是单个字符在y轴上分布的区间
i=1;j=1;
for y=1:n-2
if (ysum(y)==0)&(ysum(y+1)~=0)
yy(i)=y
i=i+1;
end
if (ysum(y)~=0)&(ysum(y+1)==0)
yx(j)=y
j=j+1;
end
end
[m_yy,n_yy]=size(yy);%求出字符的分布并分割
if n_yy==3 %根据n_yy和n_yx的个数及分布区间,选择分割区间
%segment
num1=goal4(1:m , 1:yx(1));%分割出字符1
figure(41);imshow(num1);
num2=goal4(1:m ,yy(1):yx(2));%分割出字符2
figure(42);imshow(num2);
num3=goal4(1:m , yy(2):yx(3));%分割出字符3
figure(43);imshow(num3);
num4=goal4(1:m , yy(3):n);%分割出字符4
figure(44);imshow(num4);
%[m1,n1]=size(num1)%求出各个字符的大小
%[m2,n2]=size(num2)
%[m3,n3]=size(num3)
%[m4,n4]=size(num4)
%对单个字符细分,避免字体出现大小不一致的情况,也就是再在x轴上进行分割
[ix1,iy1]=xfenge(num1)
[ix2,iy2]=xfenge(num2)
[ix3,iy3]=xfenge(num3)
[ix4,iy4]=xfenge(num4)
num1=goal4(ix1:iy1 , 1:yx(1));
figure(51);imshow(num1);
num2=goal4(ix2:iy2 ,yy(1):yx(2));
figure(52);imshow(num2);
num3=goal4(ix3:iy3 , yy(2):yx(3));
figure(53);imshow(num3);
num4=goal4(ix4:iy4 , yy(3):n);
figure(54);imshow(num4);
imwrite(num1, '1.bmp');
imwrite(num2, '2.bmp');
imwrite(num3, '3.bmp');
imwrite(num4, '4.bmp');
end
if n_yy==4 %根据n_yy和n_yx的个数及分布区间,选择分割区间
%segment
num1=goal4(1:m , yy(1):yx(1));
figure(61);imshow(num1);
num2=goal4(1:m ,yy(2):yx(2));
figure(62);imshow(num2);
num3=goal4(1:m , yy(3):yx(3));
figure(63);imshow(num3);
num4=goal4(1:m , yy(4):n);
figure(64);imshow(num4);
%[m1,n1]=size(num1)
%[m2,n2]=size(num2)
%[m3,n3]=size(num3)
%[m4,n4]=size(num4)
%对单个字符细分
[ix1,iy1]=xfenge(num1)
[ix2,iy2]=xfenge(num2)
[ix3,iy3]=xfenge(num3)
[ix4,iy4]=xfenge(num4)
num1=goal4(ix1:iy1 , yy(1):yx(1));imwrite(num1, '1.bmp');
figure(71);imshow(num1);
num2=goal4(ix2:iy2 ,yy(2):yx(2));imwrite(num2, '2.bmp');
figure(72);imshow(num2);
num3=goal4(ix3:iy3 , yy(3):yx(3));imwrite(num3, '3.bmp');
figure(73);imshow(num3);
num4=goal4(ix4:iy4 , yy(4):n);imwrite(num4, '4.bmp');
figure(74);imshow(num4);
end
for i=1:4
imagenum=strcat(num2str(i),'.bmp');
J=imread(imagenum);
[m,n]=size(J)
num{i}=imresize(J,[32,32],'nearest'); %待识别字符归一化
[m,n]=size(num{i})
figure;imshow(num{i});
imwrite(num{i}, [num2str(i),'.bmp']);
end
clear all;
for i=1:4
p(1:256,1)=1;
p1=ones(16,16);
load E52net net;
% test=input('FileName:', 's');
%x=imread(test,'bmp');
m=strcat(num2str(i),'.bmp');
x=imread(m,'bmp');
[i,j]=find(x==1);
imin=min(i);
imax=max(i);
jmin=min(j);
jmax=max(j);
bw1=x(imin:imax,jmin:jmax);%words segmentation
bw1=imresize(bw1,[16,16],'nearest');
[i,j]=size(bw1);
i1=round((16-i)/2);
j1=round((16-j)/2);
p1(i1+1:i1+i,j1+1:j1+j)=bw1;
for m=0:15
p(m*16+1:(m+1)*16,1)=p1(1:16,m+1);
end
[a,Pf,Af]=sim(net,p);
figure;imshow(p1);
a=round(a)
switch a
case 1
Rchar(i)='1'
case 2
Rchar(i)='2'
case 3
Rchar(i)='3'
case 4
Rchar(i)='4'
case 5
Rchar(i)='5'
case 6
Rchar(i)='A'
case 7
Rchar(i)='B'
case 8
Rchar(i)='C'
case 9
Rchar(i)='D'
case 10
Rchar(i)='E'
otherwise
Rchar(i)='false' ;
end
end
schar=[Rchar(1),Rchar(2),Rchar(3),Rchar(4)]
转载地址:http://blog.csdn.net/u013050589/article/details/24302595
http://blog.csdn.net/sanwandoujiang/article/details/34107993
http://blog.csdn.net/sanwandoujiang/article/details/34103981
http://download.csdn.net/download/dengdong1028/7843431 临近法
模式识别之ocr项目---(模板匹配&BP神经网络训练)的更多相关文章
- 字符识别(模板匹配&BP神经网络训练)
http://blog.csdn.net/zhang11wu4/article/details/7585632
- 字符识别OCR研究一(模板匹配&BP神经网络训练)
摘 要 在MATLAB环境下利用USB摄像头採集字符图像.读取一帧保存为图像.然后对读取保存的字符图像,灰度化.二值化,在此基础上做倾斜矫正.对矫正的图像进行滤波平滑处理,然后对字符区域进行提取切割出 ...
- 练习推导一个最简单的BP神经网络训练过程【个人作业/数学推导】
写在前面 各式资料中关于BP神经网络的讲解已经足够全面详尽,故不在此过多赘述.本文重点在于由一个"最简单"的神经网络练习推导其训练过程,和大家一起在练习中一起更好理解神经网络训 ...
- 使用HOG特征+BP神经网络进行车标识别
先挖个坑,快期末考试了,有空填上w 好了,今晚刚好有点闲,就把坑填上吧. //-------------------------------开篇---------------------------- ...
- MATLAB神经网络(1) BP神经网络的数据分类——语音特征信号分类
1.1 案例背景 1.1.1 BP神经网络概述 BP神经网络是一种多层前馈神经网络,该网络的主要特点是信号前向传递,误差反向传播.在前向传递中,输入信号从输入层经隐含层逐层处理,直至输出层.每一层的神 ...
- JAVA实现BP神经网络算法
工作中需要预测一个过程的时间,就想到了使用BP神经网络来进行预测. 简介 BP神经网络(Back Propagation Neural Network)是一种基于BP算法的人工神经网络,其使用BP算法 ...
- BP神经网络分类器的设计
1.BP神经网络训练过程论述 BP网络结构有3层:输入层.隐含层.输出层,如图1所示. 图1 三层BP网络结构 3层BP神经网络学习训练过程主要由4部分组成:输入模式顺传播(输入模式由输入层经隐含层向 ...
- BP神经网络的手写数字识别
BP神经网络的手写数字识别 ANN 人工神经网络算法在实践中往往给人难以琢磨的印象,有句老话叫“出来混总是要还的”,大概是由于具有很强的非线性模拟和处理能力,因此作为代价上帝让它“黑盒”化了.作为一种 ...
- BP神经网络及其在教学质量评价中 的应用
本文学习笔记是自己的理解,如有错误的地方,请大家指正批评.共同进步.谢谢! 之前的教学质量评价,仅仅是通过对教学指标的简单处理.如求平均值或人为的给出各指标的权值来加权求和,其评价结果带有非常大主观性 ...
随机推荐
- RSA签名
RSA签名: /** * RSA签名 * @param content 待签名数据 * @param privateKey 商户私钥 * @return 签名值 */public static ...
- CountDownLatch和CyclicBarrier 的用法
CountDownLatch是减计数方式,计数==0时释放所有等待的线程:CyclicBarrier是加计数方式,计数达到构造方法中参数指定的值时释放所有等待的线程.CountDownLatch当计数 ...
- bzoj 2330 [SCOI2011]糖果 差分约束模板
题目大意 幼儿园里有N个小朋友,lxhgww老师现在想要给这些小朋友们分配糖果,要求每个小朋友都要分到糖果.但是小朋友们也有嫉妒心,总是会提出一些要求,比如小明不希望小红分到的糖果比他的多,于是在分配 ...
- zoj 3790 Consecutive Blocks 离散化+二分
There are N (1 ≤ N ≤ 105) colored blocks (numbered 1 to N from left to right) which are lined up in ...
- 【HDOJ6229】Wandering Robots(马尔科夫链,set)
题意:给定一个n*n的地图,上面有k个障碍点不能走,有一个机器人从(0,0)出发,每次等概率的不动或者往上下左右没有障碍的地方走动,问走无限步后停在图的右下部的概率 n<=1e4,k<=1 ...
- java内部类的四大作用
一.定义 放在一个类的内部的类我们就叫内部类. 二. 作用 1.内部类可以很好的实现隐藏 一般的非内部类,是不允许有 private 与protected权限的,但内部类可以 2.内部类拥有外围类的所 ...
- LeetCode OJ--Merge Sorted Array *
http://oj.leetcode.com/problems/merge-sorted-array/ 两个有序数组A和B的归并排序,将结果存到A中.因为已知两数组长度且A的数组足够大,所以倒着处理, ...
- 洛谷—— P1342 请柬
https://www.luogu.org/problemnew/show/1342 题目描述 在电视时代,没有多少人观看戏剧表演.Malidinesia古董喜剧演员意识到这一事实,他们想宣传剧院,尤 ...
- 矩阵乘法加速fib数列
考虑矩阵(1,1)(1,0) #include<cstdio> #include<cstring> #include<iostream> using namespa ...
- [LibreOJ β Round #4] 子集
显然是个二分图,直接求最大独立就行了. #include<bits/stdc++.h> #define ll long long #define pb push_back using na ...