RESTful-rest_framework版本控制、分页器-第六篇
版本控制:
源码位置分析第一步:
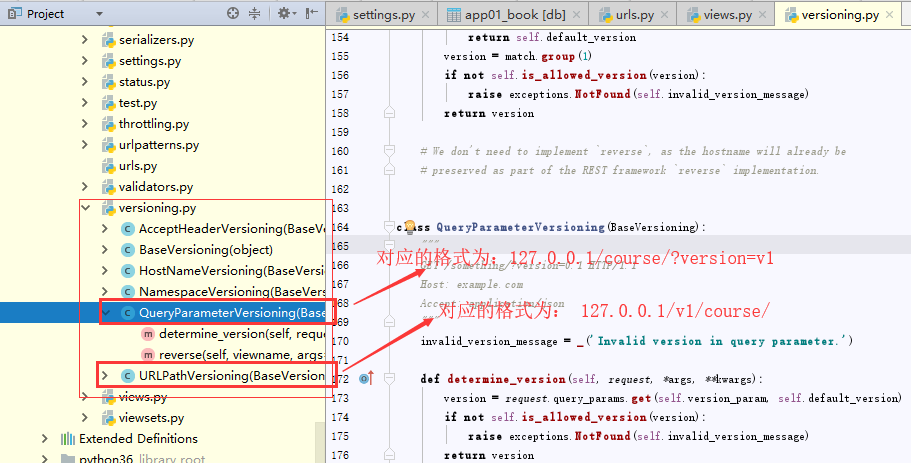
源码位置分析第二步:在APIView-despath方法-initial-determine_version
#执行determine_version,返回两个值,放到request对象里
version, scheme = self.determine_version(request, *args, **kwargs)
request.version, request.versioning_scheme = version, scheme def determine_version(self, request, *args, **kwargs):
#当配置上版本类之后,就会实例化
if self.versioning_class is None:
return (None, None)
scheme = self.versioning_class()
return (scheme.determine_version(request, *args, **kwargs), scheme)
代码实现:
settings配置
REST_FRAMEWORK={
# 'DEFAULT_RENDERER_CLASSES':['rest_framework.renderers.JSONRenderer'],
#url中获取值的key
'VERSION_PARAM':'version',
#默认版本(从request对象里取不到,显示的默认值版本号,例如:默认不写后台打印也是v2 http://127.0.0.1:8006/testversion/)
'DEFAULT_VERSION':'v2',
#允许的版本(只有写在列表里面的,浏览器访问才能输入响应的版本地址,例如:http://127.0.0.1:8006/v2/testversion/)
'ALLOWED_VERSIONS':['v1','v2']
路由设置:
#对应视图方式一:
url(r'^testversion/', views.Test.as_view()),
#对应视图方式二:
url(r'^(?P<version>[v1|v2|v3]+)/testversion/', views.Test2.as_view(),name='ttt'),
视图设置:
from rest_framework.versioning import QueryParameterVersioning,URLPathVersioning
#情况一:
class Test(APIView):
#不再是列表
versioning_class=QueryParameterVersioning
def get(self,request,*args,**kwargs):
print(request.version) #v2 return Response('ok') #情况二:
from django.urls import reverse
class Test2(APIView):
#不再是列表
versioning_class=URLPathVersioning
def get(self,request,*args,**kwargs):
#获取版本
print(request.version) #v1
#获取版本管理的类
print(request.versioning_scheme)
#反向生成url
url=request.versioning_scheme.reverse(viewname='ttt',request=request)
print(url) #http://127.0.0.1:8006/v1/testversion/
url2=reverse(viewname='ttt',kwargs={'version':'v1'})
print(url2) #/v1/testversion/
return Response('ok ttest2')
分页器:
路由:
url(r'^page', views.Page.as_view()),
BookSer序列化所有书籍:
class BookSer(serializers.ModelSerializer):
class Meta:
model=models.Book
fields='__all__'
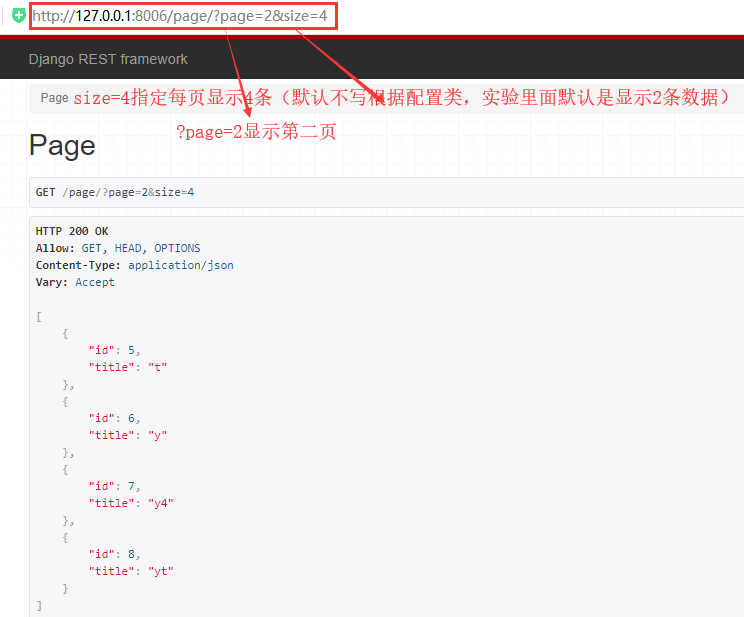
一 简单分页(查看第n页,每页显示n条)
1 简单分页
http://127.0.0.1:8006/page/?page=2&size=4
PageNumberPagination
#每页显示多少条api_settings.PAGE_SIZE
#page_size =
#查询指定页码的参数
#page_query_param = 'page'
#指定每页显示条数
#page_size_query_param = None
#限制每页显示最大条数
#max_page_size = None
#简单分页:PageNumberPagination
from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination
class Page(APIView):
def get(self,request,*args,**kwargs):
#获取所有数据
ret=models.Book.objects.all()
#创建分页对象
my_page=PageNumberPagination()
#默认每页显示条数
my_page.page_size=2
#指定每页显示条数(受下面最大显示条数的限制)
my_page.page_size_query_param='size'
#限制每页最大显示条数
my_page.max_page_size=5
#在数据库中获取分页数据
page_list=my_page.paginate_queryset(ret,request,self)
#对分页进行实例化
ser=BookSer(instance=page_list,many=True)
# 1 再setting里配置每页条数
# 2 写一个类,继承它,属性重写
# 3 再对象里修改
'''
每页显示多少条api_settings.PAGE_SIZE
page_size =
查询指定页码的参数
page_query_param = 'page'
指定每页显示条数
page_size_query_param = None
限制每页显示最大条数
max_page_size = None
'''
return Response(ser.data)
图解:
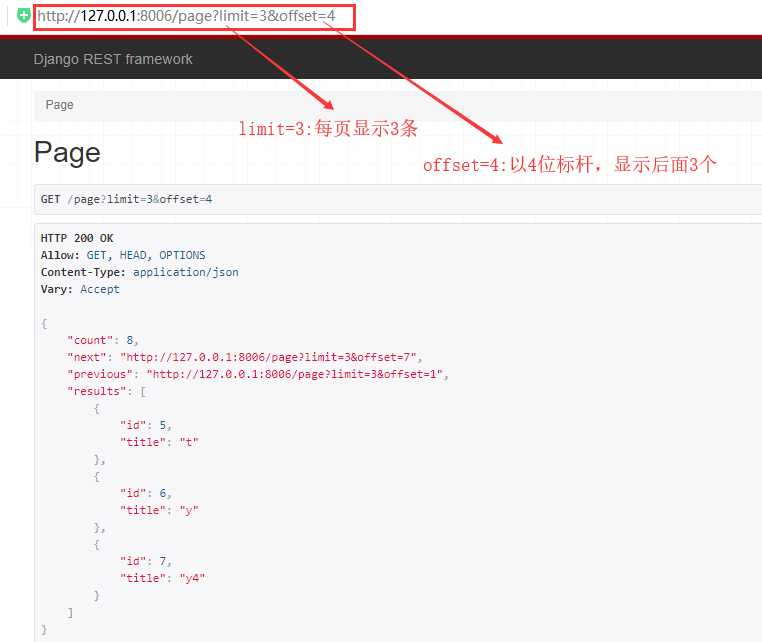
二 偏移分页(在第n个位置,向后查看n条数据)
偏移分页要点:
后台返回的url:http://127.0.0.1:8006/page?limit=3&offset=2
LimitOffsetPagination
default_limit:默认显示多少条
max_limit:最大显示多少条
limit_query_param:重新命名limit(limit=4:表明显示四条,受max_limit的限制)
offset_query_param:指定查询的标杆名(offset=1:表明从第二条开始,往后偏移)
#偏移分页:LimitOffsetPagination
# 也可以自定制,同简单分页
class Page(APIView):
def get(self,request,*args,**kwargs):
#获取所有数据
ret=models.Book.objects.all()
#创建分页而对象
my_page=LimitOffsetPagination()
my_page.default_limit=3
my_page.max_limit=5 #在数据库中获取分页的数据
page_list=my_page.paginate_queryset(ret,request,self)
#对分页进行序列化
ser=BookSer(instance=page_list,many=True)
# 1 再setting里配置每页条数
# 2 写一个类,继承它,属性重写
# 3 再对象里修改
'''
default_limit:默认显示多少条
max_limit:最大显示多少条
limit_query_param:重新命名limit(limit=4:表明显示四条,受max_limit的限制)
offset_query_param:指定查询的标杆名(offset=1:表明从第二条开始,往后偏移)
''' #只是显示指定访问的内容(不包含总条数和上、下页链接)
# return Response(ser.data) # 对Response做了封装,返回内容里有总条数,上一页,下一页的链接
return my_page.get_paginated_response(ser.data)
图解:
三 加密分页:CursorPagination(只能看上一页和下一页,速度快)
加密分页要点:
后台返回的url:例如 http://127.0.0.1:8006/page?cursor=cD0y(随机的字符串)
CursorPagination
cursor_query_param = 'cursor':查询的名字
page_size = api_settings.PAGE_SIZE:每页显示的条数
ordering = '-created' :按谁排序
#加密分页:CursorPagination
#看源码,是通过sql查询,大于id和小于id
class Page(APIView):
def get(self,request,*args,**kwargs):
#获取所有数据
ret=models.Book.objects.all()
#创建分页对象
my_page=CursorPagination()
#安装id就行排序
my_page.ordering='id'
#限制每页显示的条数
my_page.page_size=2 page_list=my_page.paginate_queryset(ret,request,self)
ser=BookSer(instance=page_list,many=True)
# 1 再setting里配置每页条数
# 2 写一个类,继承它,属性重写
# 3 再对象里修改
'''
cursor_query_param = 'cursor':查询的名字(即浏览器后面跟的名字例如:http://127.0.0.1:8006/page?cursor=cD0y)
page_size = api_settings.PAGE_SIZE:每页显示的条数
ordering = '-created' :按谁排序 #浏览器验证:
#1.http://127.0.0.1:8006/page 首先打开显示2条数据
#2.http://127.0.0.1:8006/page?cursor=cj0xJnA9NQ%3D%3D
''' # return Response(ser.data)
# 对Response做了封装,返回内容里有总条数,上一页,下一页的链接(可避免页面被猜到)
return my_page.get_paginated_response(ser.data) #作用就是打印首页会有上一个和下一页的链接,如下备注
# return Response(ser.data) '''可以手动点击上、下翻页(看不到页码)
"next": "http://127.0.0.1:8006/page?cursor=cD00",
"previous": "http://127.0.0.1:8006/page?cursor=cj0xJnA9Mw%3D%3D",
...
'''
访问效果图:

RESTful-rest_framework版本控制、分页器-第六篇的更多相关文章
- 跟我学SpringCloud | 第六篇:Spring Cloud Config Github配置中心
SpringCloud系列教程 | 第六篇:Spring Cloud Config Github配置中心 Springboot: 2.1.6.RELEASE SpringCloud: Greenwic ...
- 解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译)
解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译) http://improve.dk/orcamdf-rawdatabase-a-swiss-a ...
- 解剖SQLSERVER 第六篇 对OrcaMDF的系统测试里避免regressions(译)
解剖SQLSERVER 第六篇 对OrcaMDF的系统测试里避免regressions (译) http://improve.dk/avoiding-regressions-in-orcamdf-b ...
- Python之路【第十六篇】:Django【基础篇】
Python之路[第十六篇]:Django[基础篇] Python的WEB框架有Django.Tornado.Flask 等多种,Django相较与其他WEB框架其优势为:大而全,框架本身集成了O ...
- 第六篇 :微信公众平台开发实战Java版之如何自定义微信公众号菜单
我们来了解一下 自定义菜单创建接口: http请求方式:POST(请使用https协议) https://api.weixin.qq.com/cgi-bin/menu/create?access_to ...
- RabbitMQ学习总结 第六篇:Topic类型的exchange
目录 RabbitMQ学习总结 第一篇:理论篇 RabbitMQ学习总结 第二篇:快速入门HelloWorld RabbitMQ学习总结 第三篇:工作队列Work Queue RabbitMQ学习总结 ...
- 第六篇 Replication:合并复制-发布
本篇文章是SQL Server Replication系列的第六篇,详细内容请参考原文. 合并复制,类似于事务复制,包括一个发布服务器,一个分发服务器和一个或多个订阅服务器.每一个发布服务器上可以定义 ...
- 第六篇 Integration Services:初级工作流管理
本篇文章是Integration Services系列的第六篇,详细内容请参考原文. 简介在前几篇文章中,我们关注使用增量加载方式加载数据.在本篇文章,我们将关注使用优先约束管理SSIS控制流中的工作 ...
- 第六篇 SQL Server安全执行上下文和代码签名
本篇文章是SQL Server安全系列的第六篇,详细内容请参考原文. SQL Server决定主体是否有必要的执行代码权限的根本途径是其执行上下文规则.这一切都可能复杂一个主体有执行代码的权限,但是却 ...
随机推荐
- python:使用OpenSSL
(一)安装pyOpenSSL 1.下载并安装 https://launchpad.net/pyopenssl pyOpenSSL-0.11.winxp32-py2.7.msi ...
- 远程登录事件ID
4672.4624 删除本机记录 HKEY_CURRENT_USER \ Software\Microsoft \ Terminal ServerClientDefault: 删除“此电脑\文档”下 ...
- linux 命令——61 wget(转)
Linux系统中的wget是一个下载文件的工具,它用在命令行下.对于Linux用户是必不可少的工具,我们经常要下载一些软件或从远程服务器恢复备份到本地服务器.wget支持HTTP,HTTPS和FTP协 ...
- 异常:System.InvalidOperationException: This implementation is not part of the Windows Platform FIPS validated cryptographic algorithms 这个实现是不是Windows平台FIPS验证的加密算法。解决方法
遇见这个问题是在使用了MD5加密算法后报错的,可能的原因如下: 1.FIPS不兼容MD5,此时需要修改注册表 HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\C ...
- Tarjan在图论中的应用(二)——用Tarjan来求割点与割边
前言:\(Tarjan\) 求割点和割边建立在 \(Tarjan\)算法的基础之上,因此建议在看这篇博客之前先去学一学\(Tarjan\). 回顾\(Tarjan\)中各个数组的定义 首先,我们来回顾 ...
- 2018.6.5 Oracle plsql编程 游标的使用
--3.查询10部门所有员工的姓名.(ref游标实现) 动态游标 declare --创建一种游标类型 type type_cursor is ref cursor; --声明变量指定游标类型 v_c ...
- 优化通过redis实现的一个抢红包流程【下】
上一篇文章通过redis实现的抢红包通过测试发现有严重的阻塞的问题,抢到红包的用户很快就能得到反馈,不能抢到红包的用户很久(10秒以上)都无法获得抢红包结果,起主要原因是: 1.用了分布式锁,导致所有 ...
- Restful API 的设计规范
RESTful 是目前最流行的 API 设计规范,用于 Web 数据接口的设计.降低开发的复杂性,提高系统的可伸缩性. Restful API接口规范包括以下部分: 一.协议 API与用户的通信协议, ...
- webpack4简单入门
安装webpack需要安装node环境,因此需要在电脑中安装node.node官网https://nodejs.org/,安装LTS版本即可. webpck基本概念 entry:分析依赖模块的入口 o ...
- vue watch深度监听对象,实现数据联动
当对象内的某一个元素发生变化,判断对象另一元素,并进行赋值 <template> <input type="text" v-model="a.a1.a1 ...