[大数据之Spark]——Transformations转换入门经典实例
Spark相比于Mapreduce的一大优势就是提供了很多的方法,可以直接使用;另一个优势就是执行速度快,这要得益于DAG的调度,想要理解这个调度规则,还要理解函数之间的依赖关系。
本篇就着重描述下Spark提供的Transformations方法.
依赖关系
宽依赖和窄依赖

窄依赖(narrow dependencies)
窄依赖是指父RDD仅仅被一个子RDD所使用,子RDD的每个分区依赖于常数个父分区(O(1),与数据规模无关)。
- 输入输出一对一的算子,且结果RDD的分区结构不变。主要是map/flatmap
- 输入输出一对一的算子,但结果RDD的分区结构发生了变化,如union/coalesce
- 从输入中选择部分元素的算子,如filter、distinct、substract、sample
宽依赖(wide dependencies)
宽依赖是指父RDD被多个子分区使用,子RDD的每个分区依赖于所有的父RDD分区(O(n),与数据规模有关)
- 对单个RDD基于key进行重组和reduce,如groupByKey,reduceByKey
- 对两个RDD基于key进行join和重组,如join(父RDD不是hash-partitioned )
- 需要进行分区,如partitionBy
Transformations转换方法实例
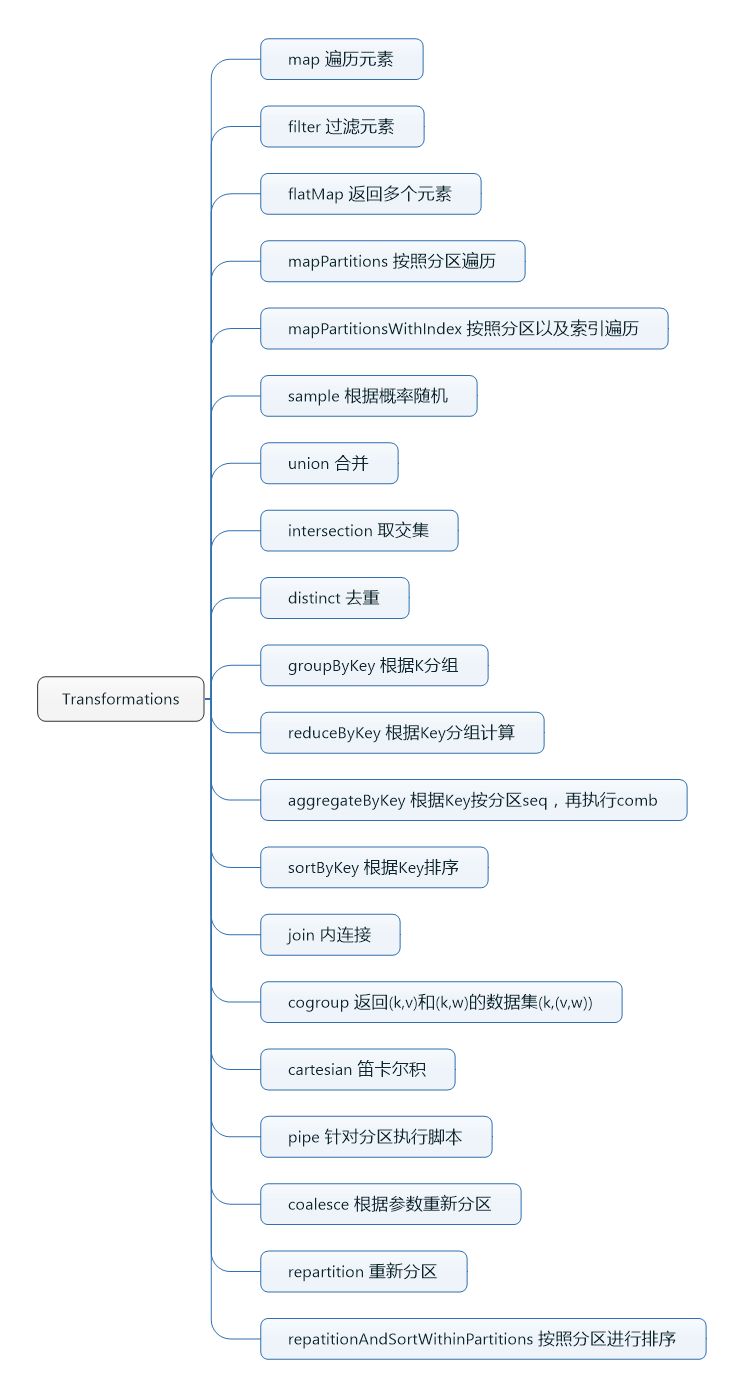
map(func)
map用于遍历rdd中的每个元素,可以针对每个元素做操作处理:
scala> var data = sc.parallelize(1 to 9,3)
//内容为 Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> data.map(x=>x*2).collect()
//输出内容 Array[Int] = Array(2, 4, 6, 8, 10, 12, 14, 16, 18)
filter(func)
filter用于过滤元素信息,仅仅返回满足过滤条件的元素
scala> var data = sc.parallelize(1 to 9,3)
//内容为 Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> data.filter(x=> x%2==0).collect()
//输出内容 Array[Int] = Array(2, 4, 6, 8)
flatMap(func)
flatMap与map相比,不同的是可以输出多个结果,比如
scala> var data = sc.parallelize(1 to 4,1)
//输出内容为 Array[Int] = Array(1, 2, 3, 4)
scala> data.flatMap(x=> 1 to x).collect()
//输出内容为 Array[Int] = Array(1, 1, 2, 1, 2, 3, 1, 2, 3, 4)
mapPartitions(func)
mapPartitions与map类似,只不过每个元素都是一个分区的迭代器,因此内部可以针对分区为单位进行处理。
比如,针对每个分区做和
//首先创建三个分区
scala> var data = sc.parallelize(1 to 9,3)
//输出为 Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
//查看分区的个数
scala> data.partitions.size
//输出为 Int = 3
//使用mapPartitions
scala> var result = data.mapPartitions{ x=> {
| var res = List[Int]()
| var i = 0
| while(x.hasNext){
| i+=x.next()
| }
| res.::(i).iterator
| }}
scala> result.collect
//输出为 Array[Int] = Array(6, 15, 24)
mapPartitionsWithIndex(func)
这个方法与上面的mapPartitions相同,只不过多提供了一个Index参数。
//首先创建三个分区
scala> var data = sc.parallelize(1 to 9,3)
//输出为 Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
//查看分区的个数
scala> data.partitions.size
//输出为 Int = 3
scala> var result = data.mapPartitionsWithIndex{
| (x,iter) => {
| var result = List[String]()
| var i = 0
| while(iter.hasNext){
| i += iter.next()
| }
| result.::( x + "|" +i).iterator
| }}
result.collect
//输出结果为 Array[String] = Array(0|6, 1|15, 2|24)
sample(withReplacement, fraction, seed)
这个方法可以用于对数据进行采样,比如从1000个数据里面随机5个数据。
- 第一个参数withReplacement代表是否进行替换,如果选true,上面的例子中,会出现重复的数据
- 第二个参数fraction 表示随机的比例
- 第三个参数seed 表示随机的种子
//创建数据
var data = sc.parallelize(1 to 1000,1)
//采用固定的种子seed随机
data.sample(false,0.005,0).collect
//输出为 Array[Int] = Array(53, 423, 433, 523, 956, 990)
//采用随机种子
data.sample(false,0.005,scala.util.Random.nextInt(1000)).collect
//输出为 Array[Int] = Array(136, 158)
union(otherDataset)
union方法可以合并两个数据集,但是不会去重,仅仅合并而已。
//创建第一个数据集
scala> var data1 = sc.parallelize(1 to 5,1)
//创建第二个数据集
scala> var data2 = sc.parallelize(3 to 7,1)
//取并集
scala> data1.union(data2).collect
//输出为 Array[Int] = Array(1, 2, 3, 4, 5, 3, 4, 5, 6, 7)
intersection(otherDataset)
这个方法用于取两个数据集的交集
//创建第一个数据集
scala> var data1 = sc.parallelize(1 to 5,1)
//创建第二个数据集
scala> var data2 = sc.parallelize(3 to 7,1)
//取交集
scala> data1.intersection(data2).collect
//输出为 Array[Int] = Array(4, 3, 5)
distinct([numTasks]))
这个方法用于对本身的数据集进行去重处理。
//创建数据集
scala> var data = sc.parallelize(List(1,1,1,2,2,3,4),1)
//执行去重
scala> data.distinct.collect
//输出为 Array[Int] = Array(4, 1, 3, 2)
//如果是键值对的数据,kv都相同,才算是相同的元素
scala> var data = sc.parallelize(List(("A",1),("A",1),("A",2),("B",1)))
//执行去重
scala> data.distinct.collect
//输出为 Array[(String, Int)] = Array((A,1), (B,1), (A,2))
groupByKey([numTasks])
这个方法属于宽依赖的方法,针对所有的kv进行分组,可以把相同的k的聚合起来。如果要想计算sum等操作,最好使用reduceByKey或者combineByKey
//创建数据集
scala> var data = sc.parallelize(List(("A",1),("A",1),("A",2),("B",1)))
//分组输出
scala> data.groupByKey.collect
//输出为 Array[(String, Iterable[Int])] = Array((B,CompactBuffer(1)), (A,CompactBuffer(1, 1, 2)))
reduceByKey(func, [numTasks])
这个方法用于根据key作分组计算,但是它跟reduce不同,它还是属于transfomation的方法。
//创建数据集
scala> var data = sc.parallelize(List(("A",1),("A",1),("A",2),("B",1)))
scala> data.reduceByKey((x,y) => x+y).collect
//输出为 Array[(String, Int)] = Array((B,1), (A,4))
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks])
aggregateByKey比较复杂,我也不是很熟练,不过试验了下,大概的意思是针对分区内部使用seqOp方法,针对最后的结果使用combOp方法。
比如,想要统计分区内的最大值,然后再全部统计加和:
scala> var data = sc.parallelize(List((1,1),(1,2),(1,3),(2,4)),2)
data: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[54] at parallelize at <console>:27
scala> def sum(a:Int,b:Int):Int = { a+b }
sum: (a: Int, b: Int)Int
scala> data.aggregateByKey(0)(sum,sum).collect
res42: Array[(Int, Int)] = Array((2,4), (1,6))
scala> def max(a:Int,b:Int):Int = { math.max(a,b) }
max: (a: Int, b: Int)Int
scala> data.aggregateByKey(0)(max,sum).collect
res44: Array[(Int, Int)] = Array((2,4), (1,5))
sortByKey([ascending], [numTasks])
sortByKey用于针对Key做排序,默认是按照升序排序。
//创建数据集
scala> var data = sc.parallelize(List(("A",2),("B",2),("A",1),("B",1),("C",1)))
data: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[30] at parallelize at <console>:27
//对数据集按照key进行默认排序
scala> data.sortByKey().collect
res23: Array[(String, Int)] = Array((A,2), (A,1), (B,2), (B,1), (C,1))
//升序排序
scala> data.sortByKey(true).collect
res24: Array[(String, Int)] = Array((A,2), (A,1), (B,2), (B,1), (C,1))
//降序排序
scala> data.sortByKey(false).collect
res25: Array[(String, Int)] = Array((C,1), (B,2), (B,1), (A,2), (A,1))
join(otherDataset, [numTasks])
join方法为(K,V)和(K,W)的数据集调用,返回相同的K,所组成的数据集。相当于sql中的按照key做连接。
有点类似于 select a.value,b.value from a inner join b on a.key = b.key;
举个例子
//创建第一个数据集
scala> var data1 = sc.parallelize(List(("A",1),("B",2),("C",3)))
//创建第二个数据集
scala> var data2 = sc.parallelize(List(("A",4)))
//创建第三个数据集
scala> var data3 = sc.parallelize(List(("A",4),("A",5)))
data1.join(data2).collect
//输出为 Array[(String, (Int, Int))] = Array((A,(1,4)))
data1.join(data3).collect
//输出为 Array[(String, (Int, Int))] = Array((A,(1,4)), (A,(1,5)))
cogroup(otherDataset, [numTasks])
在类型为(K,V)和(K,W)的数据集上调用,返回一个 (K, (Seq[V], Seq[W]))元组的数据集。
//创建第一个数据集
scala> var data1 = sc.parallelize(List(("A",1),("B",2),("C",3)))
//创建第二个数据集
scala> var data2 = sc.parallelize(List(("A",4)))
//创建第三个数据集
scala> var data3 = sc.parallelize(List(("A",4),("A",5)))
scala> data1.cogroup(data2).collect
//输出为 Array[(String, (Iterable[Int], Iterable[Int]))] = Array((B,(CompactBuffer(2),CompactBuffer())), (A,(CompactBuffer(1),CompactBuffer(4))), (C,(CompactBuffer(3),CompactBuffer())))
scala> data1.cogroup(data3).collect
//输出为 Array[(String, (Iterable[Int], Iterable[Int]))] = Array((B,(CompactBuffer(2),CompactBuffer())), (A,(CompactBuffer(1),CompactBuffer(4, 5))), (C,(CompactBuffer(3),CompactBuffer())))
cartesian(otherDataset)
这个方法用于计算两个(K,V)数据集之间的笛卡尔积
//创建第一个数据集
scala> var a = sc.parallelize(List(1,2))
//创建第二个数据集
scala> var b = sc.parallelize(List("A","B"))
//计算笛卡尔积
scala> a.cartesian(b).collect
//输出结果 res2: Array[(Int, String)] = Array((1,A), (1,B), (2,A), (2,B))
pipe(command, [envVars])
pipe方法用于针对每个分区的RDD执行一个shell脚本命令,可以使perl或者bash。分区的元素将会被当做输入,脚本的输出则被当做返回的RDD值。
//创建数据集
scala> var data = sc.parallelize(1 to 9,3)
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[34] at parallelize at <console>:27
//测试脚本
scala> data.pipe("head -n 1").collect
res26: Array[String] = Array(1, 4, 7)
scala> data.pipe("tail -n 1").collect
res27: Array[String] = Array(3, 6, 9)
scala> data.pipe("tail -n 2").collect
res28: Array[String] = Array(2, 3, 5, 6, 8, 9)
coalesce(numPartitions)
这个方法用于对RDD进行重新分区,第一个参数是分区的数量,第二个参数是是否进行shuffle
//创建数据集
scala> var data = sc.parallelize(1 to 9,3)
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[6] at parallelize at <console>:27
//查看分区的大小
scala> data.partitions.size
res3: Int = 3
//不使用shuffle重新分区
scala> var result = data.coalesce(2,false)
result: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[19] at coalesce at <console>:29
scala> result.partitions.length
res12: Int = 2
scala> result.toDebugString
res13: String =
(2) CoalescedRDD[19] at coalesce at <console>:29 []
| ParallelCollectionRDD[9] at parallelize at <console>:27 []
//使用shuffle重新分区
scala> var result = data.coalesce(2,true)
result: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[23] at coalesce at <console>:29
scala> result.partitions.length
res14: Int = 2
scala> result.toDebugString
res15: String =
(2) MapPartitionsRDD[23] at coalesce at <console>:29 []
| CoalescedRDD[22] at coalesce at <console>:29 []
| ShuffledRDD[21] at coalesce at <console>:29 []
+-(3) MapPartitionsRDD[20] at coalesce at <console>:29 []
| ParallelCollectionRDD[9] at parallelize at <console>:27 []
repartition(numPartitions)
这个方法作用于coalesce一样,重新对RDD进行分区,相当于shuffle版的calesce
//创建数据集
scala> var data = sc.parallelize(1 to 9,3)
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[6] at parallelize at <console>:27
//查看分区的大小
scala> data.partitions.size
res3: Int = 3
scala> var result = data.repartition(2)
result: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[27] at repartition at <console>:29
scala> result.partitions.length
res16: Int = 2
scala> result.toDebugString
res17: String =
(2) MapPartitionsRDD[27] at repartition at <console>:29 []
| CoalescedRDD[26] at repartition at <console>:29 []
| ShuffledRDD[25] at repartition at <console>:29 []
+-(3) MapPartitionsRDD[24] at repartition at <console>:29 []
| ParallelCollectionRDD[9] at parallelize at <console>:27 []
scala>
repartitionAndSortWithinPartitions(partitioner)
这个方法是在分区中按照key进行排序,这种方式比先分区再sort更高效,因为相当于在shuffle阶段就进行排序。
下面的例子中,由于看不到分区里面的数据。可以通过设置分区个数为1,看到排序的效果。
scala> var data = sc.parallelize(List((1,2),(1,1),(2,3),(2,1),(1,4),(3,5)),2)
data: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[60] at parallelize at <console>:27
scala> data.repartitionAndSortWithinPartitions(new org.apache.spark.HashPartitioner(2)).collect
res52: Array[(Int, Int)] = Array((2,3), (2,1), (1,2), (1,1), (1,4), (3,5))
scala> data.repartitionAndSortWithinPartitions(new org.apache.spark.HashPartitioner(1)).collect
res53: Array[(Int, Int)] = Array((1,2), (1,1), (1,4), (2,3), (2,1), (3,5))
scala> data.repartitionAndSortWithinPartitions(new org.apache.spark.HashPartitioner(3)).collect
res54: Array[(Int, Int)] = Array((3,5), (1,2), (1,1), (1,4), (2,3), (2,1))
参考
[大数据之Spark]——Transformations转换入门经典实例的更多相关文章
- 【互动问答分享】第8期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第8期互动问答分享] Q1:spark线上用什么版本好? 建议从最低使用的Spark 1.0.0版本,Spark在1.0.0开始核心 ...
- 【互动问答分享】第15期决胜云计算大数据时代Spark亚太研究院公益大讲堂
"决胜云计算大数据时代" Spark亚太研究院100期公益大讲堂 [第15期互动问答分享] Q1:AppClient和worker.master之间的关系是什么? AppClien ...
- 【互动问答分享】第13期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第13期互动问答分享] Q1:tachyon+spark框架现在有很多大公司在使用吧? Yahoo!已经在长期大规模使用: 国内也有 ...
- 【互动问答分享】第10期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第10期互动问答分享] Q1:Spark on Yarn的运行方式是什么? Spark on Yarn的运行方式有两种:Client ...
- 【互动问答分享】第7期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第7期互动问答分享] Q1:Spark中的RDD到底是什么? RDD是Spark的核心抽象,可以把RDD看做“分布式函数编程语言”. ...
- 【互动问答分享】第6期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第6期互动问答分享] Q1:spark streaming 可以不同数据流 join吗? Spark Streaming不同的数据流 ...
- 大数据应用日志采集之Scribe演示实例完全解析
大数据应用日志采集之Scribe演示实例完全解析 引子: Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它能够从各种日志源上收集日志,存储到一个中央存储系 ...
- [大数据之Spark]——快速入门
本篇文档是介绍如何快速使用spark,首先将会介绍下spark在shell中的交互api,然后展示下如何使用java,scala,python等语言编写应用.可以查看编程指南了解更多的内容. 为了良好 ...
- 【大数据】Spark性能优化和故障处理
第一章 Spark 性能调优 1.1 常规性能调优 1.1.1 常规性能调优一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分配与性能的提升是成正比的, ...
随机推荐
- 毕业论文中使用的技术—FileReader接口
用来把文件读入内存,并且读取文件中的数据. FileReader接口提供了一个异步API,使用该API可以在浏览器主线程中异步访问文件系统,读取文件中的数据 FileReader接口的方法 方法名 参 ...
- RPC原理及RPC实例分析
在学校期间大家都写过不少程序,比如写个hello world服务类,然后本地调用下,如下所示.这些程序的特点是服务消费方和服务提供方是本地调用关系. 1 2 3 4 5 6 public class ...
- mysql 数据库可以非本地访问
GRANT ALL PRIVILEGES ON 数据库名.* TO root@'%' IDENTIFIED BY '密码' WITH GRANT OPTION;
- java 随机获取国内IP
/* * 随机生成国内IP地址 */ public static String getRandomIp(){ //ip范围 int[][] range = {{607649792,608174079} ...
- sass基础用法
嵌套: 1.选择器嵌套: 2.属性嵌套; .box { border-top: 1px solid red; border-bottom: 1px solid green; } .bo ...
- Leetcode Implement Queue using Stacks
Implement the following operations of a queue using stacks. push(x) -- Push element x to the back of ...
- Curator leader 选举(一)
要想使用Leader选举功能,需要添加recipes包,可以在maven中添加如下依赖: <dependency> <groupId>org.apache.curator< ...
- 整理ViewController的生命周期和加载过程
按照执行顺序排列 - initWithCoder:通过nib文件初始化时触发 - awakeFromNib:nib文件被加载的时候,会发送一个awakeFromNib的消息到nib文件中的每个对象 p ...
- bzoj 2563: 阿狸和桃子的游戏
开始写了一些东西但是后来浏览器挂了就没有存下来简直!!!!!!!!!!!!!QAQ 不想再写一遍了...总之是简单贪心. #include <iostream> #include < ...
- bzoj 3821: 玄学
题目大意 有一个长度为 n 数列,有若干个事件,事件分为操作和询问两种, 一次操作是把数列[l...r] 区间中的每个元素x变成 ax + b mod p. 一次询问是询问 执行了 第l 次到第r次操 ...