python爬取+使用网易卡搭作品数量api
第一步,当然是打开浏览器~
然后打开卡搭~
看着熟悉的界面,是不是有点不知所措?
这就对了,咱找点事情干干。

随便找个倒霉蛋,比如这位:“混世大王”,打开他的主页!
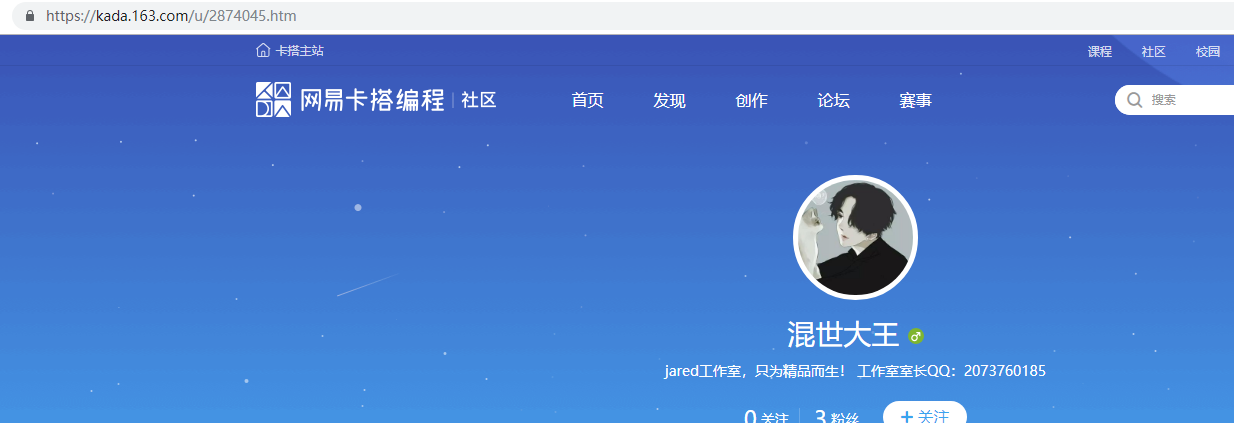
按下f12(我这个是chrome,别的浏览器可能不一样),选进“network",ctrl+r刷新;

在过滤器里选”XHR“,从第一个往下看,如果代码是下图这样的,那就右键在新标签页打开,能看到api返回的数据。
如果不是,就点下一个;
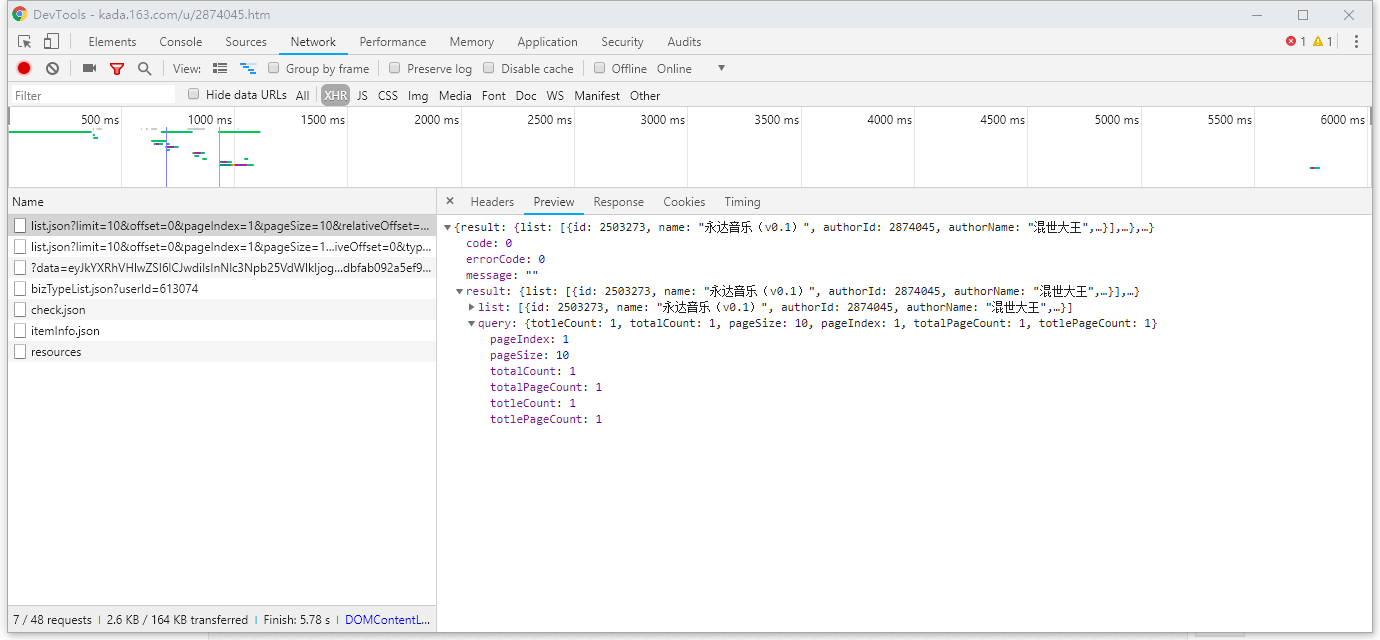
让我们仔细观察一下API返回的数据:
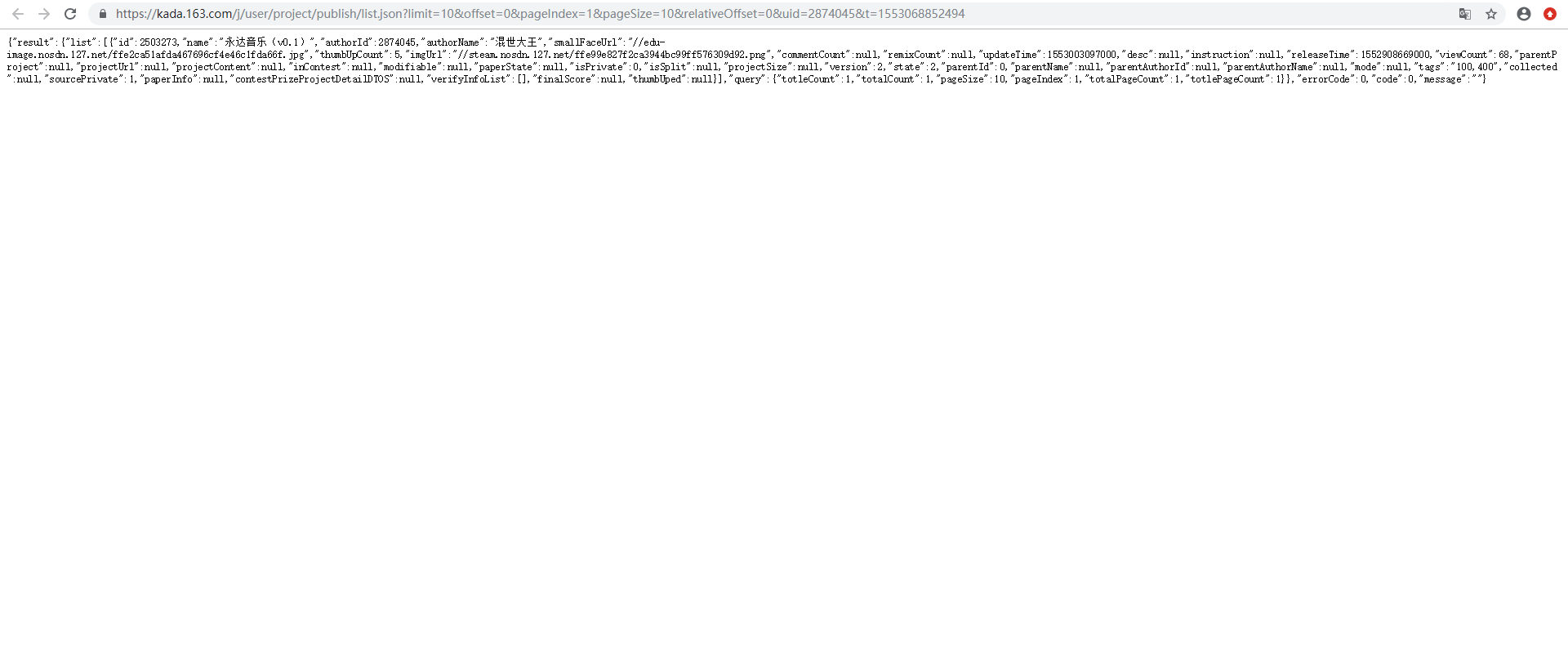
api返回的数据分为很多层,我们要找的就是"totalCount",作品总数。这项数据外面有两层:'result' 'query‘。
api找好了,把地址栏的地址复制下来,根据找到的api写代码吧!
import requests #笨猫出品,必属精品
def get_api():
# 请求头
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Host": "kada.163.com",
"Referer": "https://kada.163.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
}
id = input("请输入id:"); # 输入id
api_url = "https://kada.163.com/j/user/project/publish/list.json?limit=10&offset=0&pageIndex=1&pageSize=10&relativeOffset=0&uid=" + id
# 开始请求
res = requests.get(api_url, headers=headers)
online_dic = res.json()
print(online_dic)
print("作品数:%d" % online_dic['result']['query']['totalCount']) #输出
if __name__ == '__main__':
get_api()
运行效果:输入uid,输出他的作品数量

python爬取+使用网易卡搭作品数量api的更多相关文章
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- python爬取股票最新数据并用excel绘制树状图
大家好,最近大A的白马股们简直 跌妈不认,作为重仓了抱团白马股基金的养鸡少年,每日那是一个以泪洗面啊. 不过从金融界最近一个交易日的大盘云图来看,其实很多中小股还是红色滴,绿的都是白马股们. 以下截图 ...
- Python爬取网易云热歌榜所有音乐及其热评
获取特定歌曲热评: 首先,我们打开网易云网页版,击排行榜,然后点击左侧云音乐热歌榜,如图: 关于如何抓取指定的歌曲的热评,参考这篇文章,很详细,对小白很友好: 手把手教你用Python爬取网易云40万 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- Python:爬取乌云厂商列表,使用BeautifulSoup解析
在SSS论坛看到有人写的Python爬取乌云厂商,想练一下手,就照着重新写了一遍 原帖:http://bbs.sssie.com/thread-965-1-1.html #coding:utf- im ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口 具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地 刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就o ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
随机推荐
- Jquery会死吗?我为什么不用vue写富文本!
一.事件背景: 我最近开源了一个个人耗时半年打造的富文本及一套适用于web后台的ui框架,在gitee上受到网友们的关注,部分网友对我采用jquery的技术栈提出了质疑.总结起来:无非是jquery已 ...
- Enable-Migrations 迁移错误,提示找不到连接字符串
把迁移项目设为启动项目即可,若是MVC Web项目可能就没有这个问题.
- C#/.net基础知识
1 .NET 中类和结构的区别? 答:结构和类具有大体的语法,但是结构受到的限制比类要多.结构不能申明有默认的构造函数,为结构的副本是又编译器创建 和销毁的,所以不需要默认的构造函数和析构函数.结构 ...
- Spring MVC 示例
Srping MVC项目结构如下: 一.首先创建一个Dynamic Web Project 二.WebContent/WEB-INF/文件夹下新增 web.xml,配置servlet 容器对于web. ...
- VirtualBox中出现UUID have already exists ,并且数字键盘numlock效果相反
原文地址:https://www.cnblogs.com/xqzt/p/5053338.html 原因:由于linux密码登录错误,修改也报错误,所以只能重新安装虚拟机并在其中安装镜像文件,但是安装镜 ...
- Android给图片加文字和图片水印
我们在做项目的时候有时候需要给图片添加水印,水寒今天就遇到了这样的问题,所以搞了一个工具类,贴出来大家直接调用就行. /** * 图片工具类 * @author 水寒 * 欢迎访问水寒的个人博客:ht ...
- linux mount命令详解(iso文件挂载)
挂载命令: mount [-t vfstype] [-o options] device dir mount 是挂载命令 -t + 类型 -o + 属性 device iso的文件 dir 挂 ...
- android 跨进程通讯 AIDL
跨进程如何通讯?两个进程无法直接通讯,通过Android系统底层间接通讯.基于service的aidl实现跨进程通讯. 什么叫AIDL? Android interface definition la ...
- git如何强制用远程分支更新本地
git本地即使有修改如何强制更新: 本地有修改和提交,如何强制用远程的库更新本地.我尝试过用git pull -f,总是提示 You have not concluded your merge. (M ...
- 测试的发现遗漏BUG的做法
首先要确认BUG的影响范围: 后续做法如下: 1.从测试角度来说,外部缺陷等同与系统崩溃,测试是必须提的2.可以询问主管或负责人是否在后一个版本中修改3.评估缺陷对于用户使用存在多大的不便4.判定缺陷 ...