大数据学习——sparkSql
官网http://spark.apache.org/docs/1.6.2/sql-programming-guide.html
val sc: SparkContext // An existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val df = sqlContext.read.json("hdfs://mini1:9000/person.json")
1.在本地创建一个文件,有三列,分别是id、name、age,用空格分隔,然后上传到hdfs上
hdfs dfs -put person.json / 2.在spark shell执行下面命令,读取数据,将每一行的数据使用列分隔符分割
val lineRDD = sc.textFile("hdfs://mini1:9000/person.json").map(_.split(" ")) 3.定义case class(相当于表的schema) case class Person(id:Int, name:String, age:Int) 4.将RDD和case class关联 val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt)) 5.将RDD转换成DataFrame val personDF = personRDD.toDF 6.对DataFrame进行处理 personDF.show
DSL风格语法



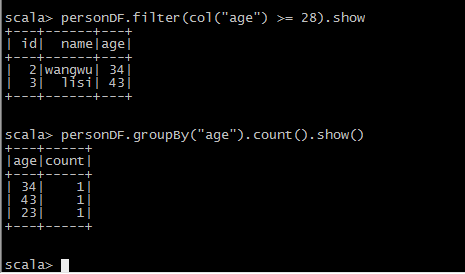
SQL风格语法
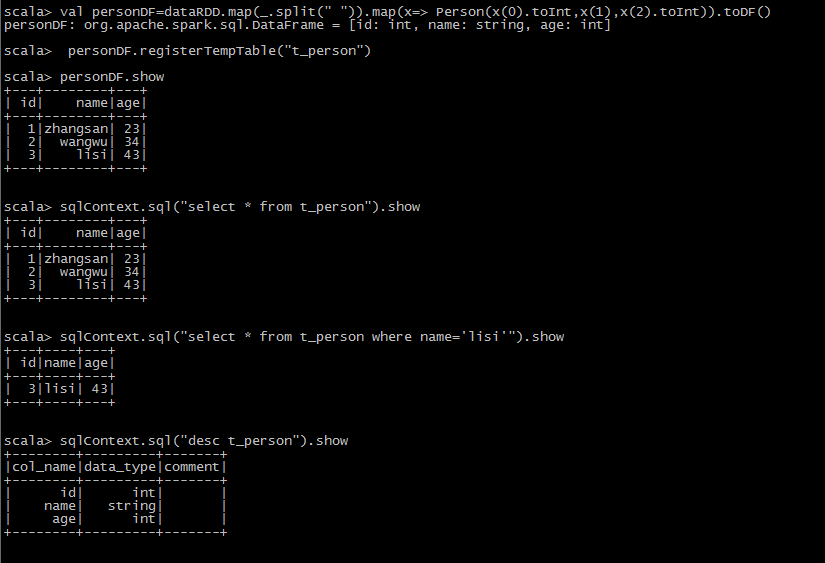
scala> val dataRDD=sc.textFile("hdfs://mini1:9000/person.json")
dataRDD: org.apache.spark.rdd.RDD[String] = hdfs://mini1:9000/person.json MapPartitionsRDD[] at textFile at <console>:27
scala> case class Person(id:Int ,name: String, age: Int)
defined class Person
scala> val personDF=dataRDD.map(_.split(" ")).map(x=> Person(x(0).toInt,x(1),x(2).toInt)).toDF()
scala> personDF.registerTempTable("t_person")

SparkSqlTest
package org.apache.spark import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SQLContext} /**
* Created by Administrator on 2019/6/12.
*/
object SparkSqlTest {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("sparksql").setMaster("local[1]")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val file: RDD[String] = sc.textFile("hdfs://mini1:9000/person.json")
val personRDD = file.map(_.split(" ")).map(x => Person(x(0).toInt, x(1), x(2).toInt))
import sqlContext.implicits._
val personDF: DataFrame = personRDD.toDF()
personDF.registerTempTable("t_person")
sqlContext.sql("select * from t_person").show }
} case class Person(id: Int, name: String, age: Int)
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 23|
| 2| wangwu| 34|
| 3| lisi| 43|
+---+--------+---+
大数据学习——sparkSql的更多相关文章
- 大数据学习——sparkSql对接mysql
1上传jar 2 加载驱动包 [root@mini1 bin]# ./spark-shell --master spark://mini1:7077 --jars mysql-connector-j ...
- 大数据学习——sparkSql对接hive
1. 安装mysql 2. 上传.解压.重命名 2.1. 上传 在随便一台有hadoop环境的机器上上传安装文件 su - hadoop rz –y 2.2. 解压 解压缩:apache- ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习之Linux进阶02
大数据学习之Linux进阶 1-> 配置IP 1)修改配置文件 vi /sysconfig/network-scripts/ifcfg-eno16777736 2)注释掉dhcp #BOOTPR ...
- 大数据学习之Linux基础01
大数据学习之Linux基础 01:Linux简介 linux是一种自由和开放源代码的类UNIX操作系统.该操作系统的内核由林纳斯·托瓦兹 在1991年10月5日首次发布.,在加上用户空间的应用程序之后 ...
随机推荐
- JS将人民币小写金额转换为大写
/** 数字金额大写转换(可以处理整数,小数,负数) */ function smalltoBIG(n) { var fraction = ['角', '分']; var digit = ['零', ...
- [转载]SAP预装服务器全编译
一.说明 SAP系统初始安装后,每当事物码第一次运行时,GUI的左下角会显示编译的状态(如图 1所示),费时很多尤其是对于一些业务内容很丰富的事物码如ME21N.VA01. 图 1 编译状态 产生编译 ...
- String | StringBuffer | StringBuilder 比较
2016的第一天,我决定写一篇博客来纪念这一天,希望一年好运吧. String|StringBuffer|StringBuilder这三者在我们学习JAVASE核心API的时候常常出来,而且大多数入门 ...
- sudo的用法
为了系统安全我们一般不直接使用root用户进行日常维护,sudo是临时提升root权限,有时执行一些命令或者更新没权限的文件时需要使用root,这个时候就需要sudo上场了 普通用户是没有sudo使用 ...
- mongodb安全整理
本文大都网上参考的,我只是整理了一下 一默认配置情况 1.MongoDB安装时不添加任何参数,默认是没有权限验证的,任何用户都可以登录进来,而且登录的用户可以对数据库任意操作而且可以远程访问数据库,需 ...
- 2012-2013 ACM-ICPC, NEERC, Central Subregional Contest J Computer Network1 (缩点+最远点对)
题意:在连通图中,求一条边使得加入这条边以后的消除的桥尽量多. 在同一个边双连通分量内加边肯定不会消除桥的, 求边双连通分量以后缩点,把桥当成边,实际上是要选一条最长的链. 缩点以后会形成一颗树,一定 ...
- 剑指offer18 树的子结构
另一种写法 class Solution { public: bool HasSubtree(TreeNode* pRoot1, TreeNode* pRoot2) { bool result = f ...
- MAC OSXU盘会挂载目录
当U盘接到系统后,你可以在Terminal里输入df -lh.这时,硬盘的使用和分区情况会输出,你在Mounted on 这一列数据中可以找到你的U盘或新添加的硬盘的挂载路径.
- 将一个double类型的小数,按照四舍五入保留两位小数.
package come.one01; public class One02 { public static void main(String[] args) { double numa = 3.14 ...
- MySQL使用INSERT插入多条记录
MySQL使用INSERT插入多条记录,应该如何操作呢?下面就为您详细介绍MySQL使用INSERT插入多条记录的实现方法,供您参考. 看到这个标题也许大家会问,这有什么好说的,调用多次INSERT语 ...