基于深度学习的目标检测算法:SSD——常见的目标检测算法
from:https://blog.csdn.net/u013989576/article/details/73439202
问题引入:
目前,常见的目标检测算法,如Faster R-CNN,存在着速度慢的缺点。该论文提出的SSD方法,不仅提高了速度,而且提高了准确度。
SSD:

该论文的主要贡献:
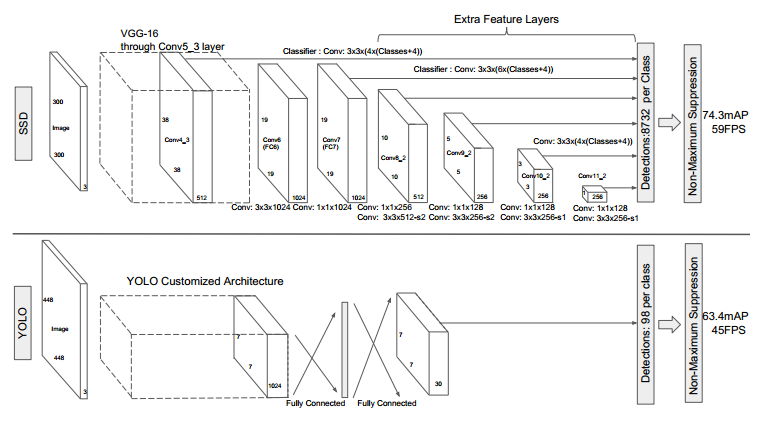
1. 提出了SSD目标检测方法,在速度上,比之前最快的YOLO还要快,在检测精度上,可以和Faster RCNN相媲美
2. SSD的核心是在特征图上采用卷积核来预测一系列default bounding boxes的类别分数、偏移量
3. 为了提高检测准确率,在不同尺度的特征图上进行预测,此外,还得到具有不同aspect ratio的结果
4. 这些改进设计,实现了end-to-end训练,并且,即使图像的分辨率比较低,也能保证检测的精度
5. 在不同的数据集,如:PASCAL VOC、MS COCO、ILSVRC,对该方法的检测速度、检测精度进行了测试,并且与其他的方法进行了对比。
SSD模型结构:
刚开始的层使用图像分类模型中的层,称为base network,在此基础上,添加一些辅助结构:
1. Mult-scale feature map for detection
在base network后,添加一些卷积层,这些层的大小逐渐减小,可以进行多尺度预测
2. Convolutional predictors for detection
每一个新添加的层,可以使用一系列的卷积核进行预测。对于一个大小为m*n、p通道的特征层,使用3*3的卷积核进行预测,在某个位置上预测出一个值,该值可以是某一类别的得分,也可以是相对于default bounding boxes的偏移量,并且在图像的每个位置都将产生一个值,如图2所示。
3. Default boxes and aspect ratio
在特征图的每个位置预测K个box。对于每个box,预测C个类别得分,以及相对于default bounding box的4个偏移值,这样需要(C+4)*k个预测器,在m*n的特征图上将产生(C+4)*k*m*n个预测值。这里,default bounding box类似于FasterRCNN中anchors,如图1所示。
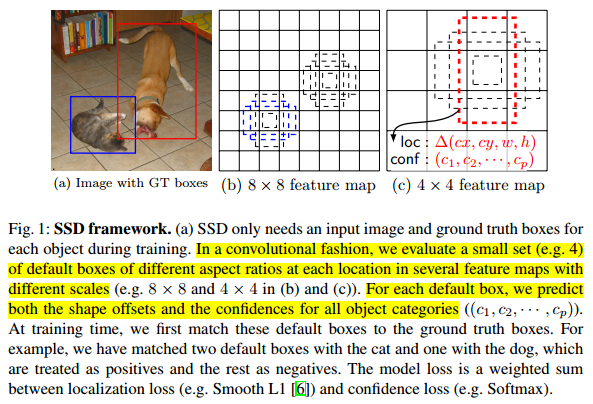

个人感觉SSD模型与Faster RCNN中的RPN很类似。SSD中的dafault bounding box类似于RPN中的anchor,但是,SSD在不同的特征层中考虑不同的尺度,RPN在一个特征层考虑不同的尺度。
SSD模型训练:
1. Matching strategy
将每个groundtruth box与具有最大jaccard overlap的defalult box进行匹配, 这样保证每个groundtruth都有对应的default box;并且,将每个defalut box与任意ground truth配对,只要两者的jaccard overlap大于某一阈值,本文取0.5,这样的话,一个groundtruth box可能对应多个default box。
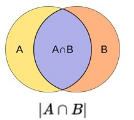
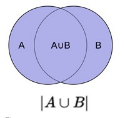
jaccard overlap的计算:
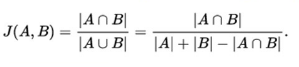
2. Training objective
Let 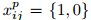
box to the j-th ground truth box of category p 。
损失函数的计算类似于Fast RCNN中的损失函数,总的损失函数是localization loss (loc) 和 confidence loss (conf) 的加权和,如下:
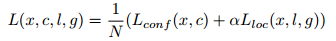
confidence loss:
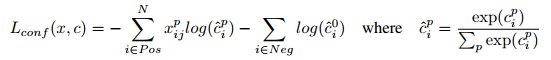
localization loss (loc) :
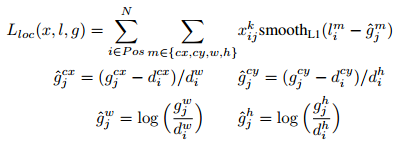
其中,(gcx, gcy, gw, gh)表示groundtruth box,(dcx, dcy, dw, dh)表示default box,(lcx, lcy, lw, lh)表示预测的box相对于default box的偏移量。
3. Choosing scales and aspect ratios for default boxes
为了处理不同尺度的物体,一些文章,如:Overfeat,处理不同大小的图像,然后将结果综合。实际上,采用同一个网络,不同层上的feature
map,也能达到同样的效果。图像分割算法FCN表明,采用低层的特征图可以提高分割效果,因为低层保留的图像细节信息比较多。因此,该论文采用lower
feature map、upper feature map进行预测。
一般来说,CNN的不同层有着不同的感受野。然而,在SSD结构中,default box不需要和每一层的感受野相对应,特定的特征图负责处理图像中特定尺度的物体。在每个特征图上,default box的尺度计算如下:
其中,smin = 0.2,smax = 0.9
default box的aspect ratios 有:{1, 2, 3,1/2,1/3},对于 aspect ratio = 1,额外增加一个default box,该box的尺度为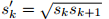
每一个default box,宽度、高度、中心点计算如下:
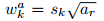
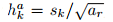
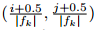
4. Hard negative mining
经过matching后,很多default box是负样本,这将导致正样本、负样本不均衡,训练难以收敛。因此,该论文将负样本根据置信度进行排序,选取最高的那几个,并且保证负样本、正样本的比例为3:1。
5. Data augmentation
为了使得模型对目标的尺度、大小更加鲁棒,该论文对训练图像做了data augmentation。每一张训练图像,由以下方法随机产生:
1)使用原始图像
2)采样一个path,与目标的最小jaccard overlap为0.1、0.3、0.5、0.7、0.9 (这个具体怎么做呢???)
3)随机采样一个path
采样得到的path,其大小为原始图像的[0.1, 1],aspect ratio在1/2与2之间。当groundtruth
box的中心在采样的path中时,保留重叠部分。经过上述采样之后,将每个采样的pathresize到固定大小,并以0.5的概率对其水平翻转。
参考博客:http://blog.csdn.net/smf0504/article/details/52745070
基于深度学习的目标检测算法:SSD——常见的目标检测算法的更多相关文章
- #Deep Learning回顾#之基于深度学习的目标检测(阅读小结)
原文链接:https://www.52ml.net/20287.html 这篇博文主要讲了深度学习在目标检测中的发展. 博文首先介绍了传统的目标检测算法过程: 传统的目标检测一般使用滑动窗口的框架,主 ...
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.object detection要解决的问题就是物体在哪里,是什么这整个流程的问题.然而,这个问题 ...
- (转)基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.object detection要解决的问题就是物体在哪里,是什么这整个流程的问题.然而,这个问题 ...
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN,Faster R-CNN
基于深度学习的目标检测技术演进:R-CNN.Fast R-CNN,Faster R-CNN object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.obj ...
- 基于深度学习的安卓恶意应用检测----------android manfest.xml + run time opcode, use 深度置信网络(DBN)
基于深度学习的安卓恶意应用检测 from:http://www.xml-data.org/JSJYY/2017-6-1650.htm 苏志达, 祝跃飞, 刘龙 摘要: 针对传统安卓恶意程序检测 ...
- 开源项目(9-0)综述--基于深度学习的目标跟踪sort与deep-sort
基于深度学习的目标跟踪sort与deep-sort https://github.com/Ewenwan/MVision/tree/master/3D_Object_Detection/Object_ ...
- 基于深度学习的病毒检测技术无需沙箱环境,直接将样本文件转换为二维图片,进而应用改造后的卷积神经网络 Inception V4 进行训练和检测
话题 3: 基于深度学习的二进制恶意样本检测 分享主题:全球正在经历一场由科技驱动的数字化转型,传统技术已经不能适应病毒数量飞速增长的发展态势.而基于沙箱的检测方案无法满足 APT 攻击的检测需求,也 ...
- 一个基于深度学习回环检测模块的简单双目 SLAM 系统
转载请注明出处,谢谢 原创作者:Mingrui 原创链接:https://www.cnblogs.com/MingruiYu/p/12634631.html 写在前面 最近在搞本科毕设,关于基于深度学 ...
- 基于深度学习的人脸性别识别系统(含UI界面,Python代码)
摘要:人脸性别识别是人脸识别领域的一个热门方向,本文详细介绍基于深度学习的人脸性别识别系统,在介绍算法原理的同时,给出Python的实现代码以及PyQt的UI界面.在界面中可以选择人脸图片.视频进行检 ...
- 深度学习与计算机视觉(12)_tensorflow实现基于深度学习的图像补全
深度学习与计算机视觉(12)_tensorflow实现基于深度学习的图像补全 原文地址:Image Completion with Deep Learning in TensorFlow by Bra ...
随机推荐
- ps快捷键记录
alt+delete 前景色填充 ctrl+delete 背景色填充 alt+shift+鼠标调节 变换选取,做圆环 ctrl+t 自由变换 alt+鼠标拖动 快捷复制某区域 delete ...
- Linux 编译ffmpeg 生成ffplay
本来主要介绍linux环境下如何编译ffmpeg使之生成ffplay.编译总是离不开源码的版本,以及编译环境下:编译环境Ubutun 16.04 ,ffmpeg 版本3.4.2.如何下载ffmpeg ...
- 制作个人开发IDE
1.打开VS2013,新建项目: 2.点击下一步,下一步.到达例如以下界面: 3.下一步 watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdG90b3R ...
- 使用python处理实验数据-yechen_pro_20171231
整体思路 1.观察文档结构: - 工况之一 - 流量一28 - 测点位置=0 -测点纵断面深度-1 -该点数据Speedxxxxxxxx.txt -测点纵断面深度-2 -测点纵断面深度-3 -... ...
- 在eclipse中添加android ADT
对于程序开发的学者来说,eclipse并不陌生,它为我们提供了一个非常广阔的平台来开发程序.同样我们也可以用它来开发android程序. 但是在eclipse中并不能直接开发android程序,需要我 ...
- 可执行Jar包调用动态链接库(DLL/SO)
踩过了很多的坑,查了很多资料,在此记录一下,以SpringBoot项目为基础. Maven加入JNA依赖 <!-- JNA start --> <dependency> < ...
- 允许局域网内其他主机访问本地MySql数据库
mysql的root账户,我在连接时通常用的是localhost或127.0.0.1,公司的测试服务器上的mysql也是localhost所以我想访问无法访问,测试暂停. 解决方法如下: 1,修改表, ...
- PythonCookBook笔记——函数
函数 可接受任意数量参数的函数 接受任意数量的位置参数,使用*参数. 接受任意数量的关键字参数,使用**参数. 只接受关键字参数的函数 强制关键字参数放在某个参数后或直接单个之后. 给函数参数增加元信 ...
- webpack 样式分离之The root route must render a single element
公司项目使用的是webpack1,使用extract-text-webpack-plugin 插件无法将css分离出来,检查原因,发现有如下代码 <Route path="/home& ...
- 深入浅出Stream和parallelStream
https://blog.csdn.net/darrensty/article/details/79283146