linux内核学习之四:进程切换简述【转】
转自:http://www.cnblogs.com/xiongyuanxiong/p/3531884.html
在讲述专业知识前,先讲讲我学习linux内核使用的入门书籍:《深入理解linux内核》第三版(英文原版叫《Understanding the Linux Kernel》),不过这本书不一定对每个人都适合,大家可以根据自己的情况选择适合的入门书籍。看了前面几章,感觉这本书的语言极其精练,没有一句多余的,必须慢慢读。可能我以前习惯了粗略浏览的阅读方式,读这本书时经常看着看着就迷糊了,不得不回到前面重新读起,如此反反复复。关于进程的一章更是深奥难懂,前前后后翻了十几遍才明白个大概。另外说明下,我用来验证代码的内核版本为官方的linux-3.2.54内核,而系统是用debian7.3_i386光盘安装的。
进程是现代操作系统的核心概念之一,用于分配系统(CPU,内存)资源的使用。了解linux进程及进程切换的知识,首先要理解进程与程序的区别,进程是执行流,是动态概念;程序是数据与指令序列的集合,是静态概念。进程作为动态的执行流,可以用execv系统调用自由选择一个程序(只要有权限)来执行的,理解这一点很重要。在阅读本书的第三章《进程》中,有两个地方比较难于理解的。
1 switch_to宏的last参数
书中讨论switch_to宏(第110页)时,提到,该宏有3个参数:prev,next和last。前两个分别是当前进程描述符地址和待切换的进程描述符的地址,相信大家对这两个参数都不会有疑问,prev就是从current得到的,而next则是schedule()函数在根据调度算法从进程等待队列中挑选的。关键是第三个last参数,为什么需要这么一个参数呢?书中的描述比较难理解。它的意思是说,A切换到B时,prev=A,next=B, 经过一定时间后,A被重新调度到CPU上执行时,A需要知道从哪个进程切换过来的,需要从last参数得到。实际上我们只需要关注A->B这一个过程就可以理解last参数的使用了。下面我们用图片记录每个步骤:
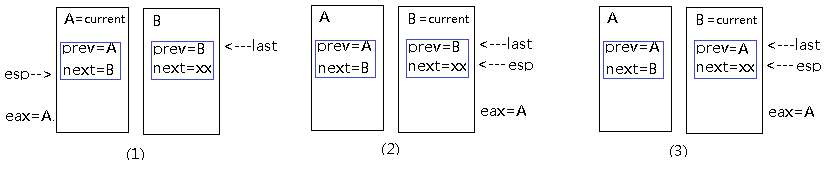
(1) 在进程切换之前,A是当前进程,esp寄存器指向A的内核栈,prev,next这两个局部变量保存在栈中,也就是在A的内核栈中。那么B的内核栈有没有这两个参数呢?当然也有,因为B既然是在等待队列中,很可能B也经历过被其他进程切换出去这一个过程,在那个过程中,B的内核栈同样保存了这两个变量(如果B是新创建的进程,可以在创建时,或在schedule函数中将两个值压入内核栈),但是这两个值肯定跟A中的prev=A,next=B不同,因为那个过程中,B是被切换的,因此,这时,B的内核栈中应该是prev=B.
为了在切换到B进程执行时,prev参数是正确的,就需要借助于第三个参数last 。在schedule函数中(它挑选的B,当然也知道B进程描述符的地址),它从B的进程描述符中得到B的内核栈的地址(书中是thread_info参数,3.2.54版本代码中改成了stack参数,原理是一样的),从而得到B的prev参数的地址,作为第三个参数传给switch_to宏。switch_to宏还将A的进程描述符地址加载到EAX寄存器中,而在进程切换过程中,EAX寄存器内容是不会改变的。
(2) 执行进程切换,主要是内核栈的切换,因为内核实现中,将thread_info结构与内核栈放在一起,esp改变了,current参数得到的当前进程描述符地址也跟着改变。这时,当前进程变成了B进程,并在B的内核栈上工作。注意,这时B内核栈的prev参数还是不正确的,它指向的依然是B。
(3) 将EAX寄存器内容复制到last指向的内存,即B内核栈的prev参数所在的地址。这样,B内核栈上的prev参数就指向了正确的A进程描述符的地址。
2 进程切换过程中进程栈
书中对进程切换的描述中,对进程的栈的描述是零散的,很容易让人犯糊途。栈是进程中的重要数据结构,在函数调用中起到核心作用,关于栈的详细描述可以参阅《深入理解计算机系统》。下面描述进程切换过程中,进程的栈的变迁。
linux的进程有两种栈,用户栈和内核栈,它们在不同的内存区域,用户栈在用户态中使用,在用户地址空间分配(0~3G),内核栈在内核态中使用,在内核地址空间分配(3G~4G)。用户栈主要用于函数调用和存储局部变量,内核栈除此之外还要保存进程切换额外的信息,如通用寄存器等。不管是用户栈还是内核栈,CPU都是用ESP寄存器保存栈顶地址,因此早在进程切换前,进程进入内核态后,用户栈就需要被切换出去,整个切换过程,都是在内核栈上工作,因而用户栈与进程切换无关。另一方面,内核的实现中,将thread_info结构与内核栈放在一起,内核栈改变了,current参数得到的当前进程描述符地址也跟着改变,因此进程切换,就是由内核栈切换来完成的。整个完整的进程切换可以分为三个部分,以下假设从进程A切换到进程B:
(1) A的用户态-->A的内核态
这一过程是由中断,异常或系统调用实现的,书中的后面章节会有介绍,以后再详谈。这里只讨论几个要点,每次从用户态切换到内核态,内核栈都会被清空,ESP直接指向内核栈的栈底,而用户栈的信息则会保存到内核栈中。清空内核栈的设计估计是考虑到经过了用户态的操作后,以前内核栈的调用信息没有用处了,没有必要再保存,毕竟内核栈只分配了8K或4K的空间。那么,切换到内核态之前,内核怎么知道进程的内核栈地址呢,进程描述符虽然保存有内核栈的地址(stack变量),但是进程描述符位于动态内态中,从内存读取的效率太低了。实现上,它是从TSS中获取的。
书中“任务状态段”一节(第108页)对TSS进行比较详细的描述,每个CPU都有一个TSS,CPU可以快速访问它。TSS的一个最重要的功能就是在用户态转为内核态时供CPU读取内核栈地址,即是init_tss[cpu]->sp0字段(3.2.54版本的代码),实际上,它存储的是栈底地址,因此一加载到ESP中,就同时清空了内核栈。
(2) A的内核态->B的内核态
这一阶段实现的是进程间的内核栈切换,同时也实现进程切换。与此过程关系最密切的是task_struct的thread变量,thread变量的类型是thread_struct,可称为线程描述符,用于保存进程切换的硬件上下文(书中第109页)。书中的switch_to和__switch_to函数详细描述了进程切换过程中的每一个步骤,与内核栈相关的有:
- 保存A的内核栈栈顶地址,即ESP寄存器的内容到A_task->thread->sp。(switch_to的第3步,变量名根据3.2.54版本中的代码)
- 将B_task->thread->sp内容加载到ESP。(switch_to的第4步,这步完成了内核栈的切换)
- 将B_task->thread->sp0加载到init_tss[cpu]->sp0字段(__switch_to的第3步),这一步与(1)的描述对应,以后B在运行期间,用户态切换到内核态时,ESP寄存器总是从init_tss[cpu]->sp0字段获取内核栈的地址,这一操作同时清空了内核栈内容。(thread_struct结构有sp0,sp1变量,sp0保存内核栈栈底地址,sp保存栈顶地址)。
(3)B的内核态->B用户态
执行与(1)相反的过程,从内核栈中取出(1)中保存的用户栈信息,装载相应寄存器,切换到用户栈,内核栈信息不必保存,因为(2)中已保存了栈底地址,下次进入内核栈时直接将其加载到ESP寄存器中即可(将栈底地址作为栈顶使用)。这一过程书中后面的章节同样会有详细描述。
有关进程的内容远不止这些,例如,进程的创建与清除,进程队列,进程调度等,总之要理解linux内核的进程管理,必须将《深入理解linux内核》一书相关章节逐句逐句细细品读。
linux内核学习之四:进程切换简述【转】的更多相关文章
- linux内核学习之四:进程切换简述
在讲述专业知识前,先讲讲我学习linux内核使用的入门书籍:<深入理解linux内核>第三版(英文原版叫<Understanding the Linux Kernel>),不过 ...
- linux内核学习之六 进程创建过程学习
一 关于linux进程概念的补充 关于进程的基本概念这里不多说,把自己的学习所得作一些补充: 1. 在linux内核中,系统最多可以有64个进程同时存在. 2.linux进程包含的关键要素:一段可执行 ...
- linux内核学习之四 系统调用
一 概念区分 提到linux系统调用,不得不区分几个比较容易混淆的概念: 系统调用:系统调用就是一种特殊的接口.通过这个接口,用户可以访问内核空间.系统调用规定了用户进程进入内核的具体位置. 应用程 ...
- linux内核学习之进程管理------task_struct结构体
struct task_struct { volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ struct t ...
- Linux内核学习笔记二——进程
Linux内核学习笔记二——进程 一 进程与线程 进程就是处于执行期的程序,包含了独立地址空间,多个执行线程等资源. 线程是进程中活动的对象,每个线程都拥有独立的程序计数器.进程栈和一组进程寄存器 ...
- Linux内核学习笔记-2.进程管理
原创文章,转载请注明:Linux内核学习笔记-2.进程管理) By Lucio.Yang 部分内容来自:Linux Kernel Development(Third Edition),Robert L ...
- Linux内核学习笔记(1)-- 进程管理概述
一.进程与线程 进程是处于执行期的程序,但是并不仅仅局限于一段可执行程序代码.通常,进程还要包含其他资源,像打开的文件,挂起的信号,内核内部数据,处理器状态,一个或多个具有内存映射的内存地址空间及一个 ...
- Linux内核分析——Linux内核学习总结
马悦+原创作品转载请注明出处+<Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 Linux内核学习总结 一 ...
- Linux内核学习总结(final)
Linux内核学习总结 符钰婧 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 ...
随机推荐
- mysql 备份 常用脚本
全备: innobackupex --defaults-file=/data/mysql3316/my3316.cnf --user=root --password=mysqlpass /data/b ...
- Linux - 链接概念详解
1> Linux链接概念Linux链接分两种,一种被称为硬链接(Hard Link),另一种被称为符号链接(Symbolic Link).默认情况下,ln命令产生硬链接. [硬连接]硬连接指通过 ...
- 04Windows中的字符类型
1. Windows 中常用的数据类型定义 //WinNt.h中定义 typedef unsigned short wchar_t; //A 16-bit character typedef char ...
- destoon修改手机端分页
1. global.func.php pages函数和listpages函数 函数开头增加 $DT_TOUCH,$newsamplepages变量 global $DT_URL, $DT, $L,$D ...
- destoon模块自定义字段的添加并让其支持搜索的方法
今天看了看模块设置里的自定义字段功能的用法,试着加了个新字段glry,设置了值,然后去数据库moduleid的article表看,字段成功加上了. 于是去template下article文件夹的lis ...
- paper:synthesizable finit state machine design techniques using the new systemverilog 3.0 enhancements之onehot coding styles(index-parameter style with registered outputs)
case语句中,对于state/next 矢量仅仅做了1-bit比较. parameter 值不是表示FSM的状态编码,而是表示state/next变量的索引.
- ZOJ 2314 (sgu 194) Reactor Cooling (无源汇有上下界最大流)
题意: 给定n个点和m条边, 每条边有流量上下限[b,c], 求是否存在一种流动方法使得每条边流量在范围内, 而且每个点的流入 = 流出 分析: 无源汇有上下界最大流模板, 记录每个点流的 in 和 ...
- emacs设置字体
* C-h f set-default-font set-default-font is an alias for `set-frame-font' in `frame.el'. (set-defau ...
- [POJ 1005] I Think I Need a Houseboat C++解题
I Think I Need a Houseboat Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 81874 ...
- python-高级编程-07-端口
TCP和UDP协议中都有端口这个概念,但是端口却不是IP协议的一部分 端口的出现主要是为了给协议栈和应用对应 .协议栈端口号将数据分配给不同的应用程序 .应用层程序用端口号去区分不同的链接 TCP 和 ...