正则 ?<= 和 ?= 用法
http://www.cnblogs.com/xiashengwang/p/3988573.html
http://www.cnblogs.com/symbol441/articles/957950.html
文本:
方法1: 匹配,捕获(存储)
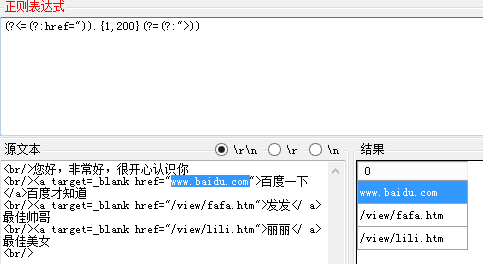
正则表达式:(?<=(href=")).{1,200}(?=(">))
解释:(?<=(href=")) 表示 匹配以(href=")开头的字符串,并且捕获(存储)到分组中
(?=(">)) 表示 匹配以(">)结尾的字符串,并且捕获(存储)到分组中
匹配结果:

方法2: 匹配,不捕获(不存储)
正则表达式:(?<=(?:href=")).{1,200}(?=(?:">))
解释:(?<=(?:href=")) 表示 匹配以(href=")开头的字符串,并且不捕获(不存储)到分组中
(?=(?:">)) 表示 匹配以(">)结尾的字符串,并且不捕获(不存储)到分组中
匹配结果:
|
(?:pattern)
|
非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分是很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。
|
|
(?=pattern)
|
非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
|
|
(?!pattern)
|
非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。
|
|
(?<=pattern)
|
非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。
|
|
(?<!pattern)
|
非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。这个地方不正确,有问题
|
一.概念
【分组】
我们已经提到了怎么重复单个字符(直接在字符后面加上限定符就行了);但如果想要重复一个字符串又该怎么办?你可以用小括号来指定子表达式(也叫做分组),然后你就可以指定这个子表达式的重复次数了,你也可以对子表达式进行其它一些操作(后面会有介绍)。(\d{1,3}\.){3}\d{1,3}是一个简单的IP地址匹配表达式。要理解这个表达式,请按下列顺序分析它:
\d{1,3}匹配1到3位的数字,(\d{1,3}\.}{3}匹配三位数字加上一个英文句号(这个整体也就是这个分组)重复3次,最后再加上一个一到三位的数字(\d{1,3})。
不幸的是,它也将匹配256.300.888.999这种不可能存在的IP地址(IP地址中每个数字都不能大于255)。如果能使用算术比较的话,或许能简单地解决这个问题,但是正则表达式中并不提供关于数学的任何功能,所以只能使用冗长的分组,选择,字符类来描述一个正确的IP地址:((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)。
理解这个表达式的关键是理解2[0-4]\d|25[0-5]|[01]?\d\d?,这里我就不细说了,你自己应该能分析得出来它的意义。
【后向引用】
使用小括号指定一个子表达式后,匹配这个子表达式的文本可以在表达式或其它程序中作进一步的处理。默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
后向引用用于重复搜索前面某个分组匹配的文本。例如,\1代表分组1匹配的文本。难以理解?请看示例:
\b(\w+)\b\s+\1\b可以用来匹配重复的单词,像go go, kitty kitty。首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(\b(\w+)\b),然后是1个或几个空白符(\s+),最后是前面匹配的那个单词(\1)。
你也可以自己指定子表达式的组名。要指定一个子表达式的组名,请使用这样的语法:(?<Word>\w+)(或者把尖括号换成'也行:(?'Word'\w+)),这样就把\w+的组名指定为Word了。要反向引用这个分组捕获的内容,你可以使用\k<Word>,所以上一个例子也可以写成这样:\b(?<Word>\w+)\b\s+\k<Word>\b。
使用小括号的时候,还有很多特定用途的语法。下面列出了最常用的一些:
分组语法 捕获
(exp) 匹配exp,并捕获文本到自动命名的组里
(?<name>exp) 匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name'exp)
(?:exp) 匹配exp,不捕获匹配的文本
位置指定
(?=exp) 匹配exp前面的位置
(?<=exp) 匹配exp后面的位置
(?!exp) 匹配后面跟的不是exp的位置
(?<!exp) 匹配前面不是exp的位置
注释
(?#comment) 这种类型的组不对正则表达式的处理产生任何影响,只是为了提供让人阅读注释
我们已经讨论了前两种语法。第三个(?:exp)不会改变正则表达式的处理方式,只是这样的组匹配的内容不会像前两种那样被捕获到某个组里面。
位置指定
接下来的四个用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们用于指定一个位置,就像\b,^,$那样,因此它们也被称为零宽断言。最好还是拿例子来说明吧:
(?=exp)也叫零宽先行断言,它匹配文本中的某些位置,这些位置的后面能匹配给定的后缀exp。比如\b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如果在查找I'm singing while you're dancing.时,它会匹配sing和danc。
(?<=exp)也叫零宽后行断言,它匹配文本中的某些位置,这些位置的前面能给定的前缀匹配exp。比如(?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找reading a book时,它匹配ading。
假如你想要给一个很长的数字中每三位间加一个逗号(当然是从右边加起了),你可以这样查找需要在前面和里面添加逗号的部分:((?<=\d)\d{3})*\b。请仔细分析这个表达式,它可能不像你第一眼看出来的那么简单。
下面这个例子同时使用了前缀和后缀:(?<=\s)\d+(?=\s)匹配以空白符间隔的数字(再次强调,不包括这些空白符)。
负向位置指定
前面我们提到过怎么查找不是某个字符或不在某个字符类里的字符的方法(反义)。但是如果我们只是想要确保某个字符没有出现,但并不想去匹配它时怎么办?例如,如果我们想查找这样的单词--它里面出现了字母q,但是q后面跟的不是字母u,我们可以尝试这样:
\b\w*q[^u]\w*\b匹配包含后面不是字母u的字母q的单词。但是如果多做测试(或者你思维足够敏锐,直接就观察出来了),你会发现,如果q出现在单词的结尾的话,像Iraq,Benq,这个表达式就会出错。这是因为[^u]总是匹配一个字符,所以如果q是单词的最后一个字符的话,后面的[^u]将会匹配q后面的单词分隔符(可能是空格,或者是句号或其它的什么),后面的\w*\b将会匹配下一个单词,于是\b\w*q[^u]\w*\b就能匹配整个Iraq fighting。负向位置指定能解决这样的问题,因为它只匹配一个位置,并不消费任何字符。现在,我们可以这样来解决这个问题:\b\w*q(?!u)\w*\b。
零宽负向先行断言(?!exp),只会匹配后缀exp不存在的位置。\d{3}(?!\d)匹配三位数字,而且这三位数字的后面不能是数字。
同理,我们可以用(?<!exp),零宽负向后行断言来查找前缀exp不存在的位置:(?<![a-z])\d{7}匹配前面不是小写字母的七位数字(实验时发现错误?注意你的“区分大小写”先项是否选中)。
一个更复杂的例子:(?<=<(\w+)>).*(?=<\/\1>)匹配不包含属性的简单HTML标签内里的内容。(<?(\w+)>)指定了这样的前缀:被尖括号括起来的单词(比如可能是<b>),然后是.*(任意的字符串),最后是一个后缀(?=<\/\1>)。注意后缀里的\/,它用到了前面提过的字符转义;\1则是一个反向引用,引用的正是捕获的第一组,前面的(\w+)匹配的内容,这样如果前缀实际上是<b>的话,后缀就是</b>了。整个表达式匹配的是<b>和</b>之间的内容(再次提醒,不包括前缀和后缀本身)。
二.实际运用
现在网络上现在很流行的爬虫程序,其实就是根据正则表达式来对网页进行解析匹配获取有用信息分组并存储下来的.
像网页上最多的就是像<table>,<tr>,<td>之类的标签,而相对于我们用户而言,这些都是没有任意意义的,有意义的是其中所包含的值.如<a href="http://www.163.com">网易</a>我所所关心的就是其href属性当中的值,还有就是其文字结点的值.其它的对于我们来说没有任何意义.这就要运用到我们所说的正确表达式匹配了.
不过如果我们只是针对取某一个标签的结点值,我们可以通过javascript+DOM方法把他们取出来,不过要是不是一类而是要求全部内空当中去取,那样用DOM动态解析的方式就显着有时不好用了.
下同说一个我运用的实例吧
我有一个页面:
 <p> 11-13 <a href=/bj/11/109/4969873.html target=_blank> 中介 - 3400元/3居 - 紫竹桥兵器大厦附近大三居 (紫竹院) </a>
<p> 11-13 <a href=/bj/11/109/4969873.html target=_blank> 中介 - 3400元/3居 - 紫竹桥兵器大厦附近大三居 (紫竹院) </a> <p> 11-13 <a href=/bj/11/104/4969872.html target=_blank> 1200元/3居 - 出租上地三居室合住(免中介费) (上地) </a>
<p> 11-13 <a href=/bj/11/104/4969872.html target=_blank> 1200元/3居 - 出租上地三居室合住(免中介费) (上地) </a> <p> 11-13 <a href=/bj/11/114/4969866.html target=_blank> 中介 - 2600元/2居 - 北太平庄43号院二居出租 (北太平庄) </a>
<p> 11-13 <a href=/bj/11/114/4969866.html target=_blank> 中介 - 2600元/2居 - 北太平庄43号院二居出租 (北太平庄) </a> <p> 11-13 <a href=/bj/11/914/4969865.html target=_blank> 400元/1居 - 单间独立卫浴免供暖费 (北七家) </a>
<p> 11-13 <a href=/bj/11/914/4969865.html target=_blank> 400元/1居 - 单间独立卫浴免供暖费 (北七家) </a> <p> 11-13 <a href=/bj/11/301/4969864.html target=_blank> 中介 - 2400元/2居 - 东直门春秀路太平庄南里二居室出租 (东直门外三里屯工人体育馆) </a>
<p> 11-13 <a href=/bj/11/301/4969864.html target=_blank> 中介 - 2400元/2居 - 东直门春秀路太平庄南里二居室出租 (东直门外三里屯工人体育馆) </a> <p> 11-13 <a href=/bj/11/208/4969863.html target=_blank> 中介 - 2400元/4居 - 出租定福家园新房四居室 (团结湖) </a>
<p> 11-13 <a href=/bj/11/208/4969863.html target=_blank> 中介 - 2400元/4居 - 出租定福家园新房四居室 (团结湖) </a> <p> 11-13 <a href=/bj/11/214/4969862.html target=_blank> 中介 - 2600元/3居 - 花家地北里三室一厅出租 (酒仙桥 将台路) </a>
<p> 11-13 <a href=/bj/11/214/4969862.html target=_blank> 中介 - 2600元/3居 - 花家地北里三室一厅出租 (酒仙桥 将台路) </a> <p> 11-13 <a href=/bj/11/209/4969859.html target=_blank> 1300元/1居 - 十里堡华堂附近新公寓合租 (京广桥 红庙 八里庄) </a>
<p> 11-13 <a href=/bj/11/209/4969859.html target=_blank> 1300元/1居 - 十里堡华堂附近新公寓合租 (京广桥 红庙 八里庄) </a> <p> 11-13 <a href=/bj/11/70/4969846.html target=_blank> 中介 - 600元/3居 - 出租丰益桥西盛鑫家园4室2厅2卫精装修的房子(免收中介费 (丰益桥西盛鑫家园) </a>
<p> 11-13 <a href=/bj/11/70/4969846.html target=_blank> 中介 - 600元/3居 - 出租丰益桥西盛鑫家园4室2厅2卫精装修的房子(免收中介费 (丰益桥西盛鑫家园) </a> <p> 11-13 <a href=/bj/11/901/4969844.html target=_blank> 750元/3居 - 田园风光雅园3居中的一居室出租 (回龙观) </a>
<p> 11-13 <a href=/bj/11/901/4969844.html target=_blank> 750元/3居 - 田园风光雅园3居中的一居室出租 (回龙观) </a> <p> 11-13 <a href=/bj/11/1101/4969840.html target=_blank> 350元/1居 - 找一女孩跟我合租 (亦庄) </a>
<p> 11-13 <a href=/bj/11/1101/4969840.html target=_blank> 350元/1居 - 找一女孩跟我合租 (亦庄) </a> <p> 11-13 <a href=/bj/11/102/4969839.html target=_blank> 中介 - 3400元/3居 - 出租知春里小区三居室 (北京大学) </a>
<p> 11-13 <a href=/bj/11/102/4969839.html target=_blank> 中介 - 3400元/3居 - 出租知春里小区三居室 (北京大学) </a> <p> 11-13 <a href=/bj/11/217/4969838.html target=_blank> 1100元/3居 - 双井桥 三居 出租 (新装修的)合租 (双井) </a>
<p> 11-13 <a href=/bj/11/217/4969838.html target=_blank> 1100元/3居 - 双井桥 三居 出租 (新装修的)合租 (双井) </a> <p> 11-13 <a href=/bj/11/70/4969837.html target=_blank> 中介 - 3500元/3居 - 丰台区兆丰园精装修房子一套低价出租 (玉泉路 吴家村) </a>
<p> 11-13 <a href=/bj/11/70/4969837.html target=_blank> 中介 - 3500元/3居 - 丰台区兆丰园精装修房子一套低价出租 (玉泉路 吴家村) </a> <p> 11-13 <a href=/bj/11/70/4969835.html target=_blank> 中介 - 2900元/3居 - 我有一套长安新城精装修的三居室要出租 (青塔 大成路 长安新城) </a>
<p> 11-13 <a href=/bj/11/70/4969835.html target=_blank> 中介 - 2900元/3居 - 我有一套长安新城精装修的三居室要出租 (青塔 大成路 长安新城) </a> <p> 11-13 <a href=/bj/11/201/4969834.html target=_blank> 中介 - 2200元/1居 - 房屋出租,北辰附近 (亚运村) </a>
<p> 11-13 <a href=/bj/11/201/4969834.html target=_blank> 中介 - 2200元/1居 - 房屋出租,北辰附近 (亚运村) </a>
我现在要取出其中的链接和相应的关键描述字符,即从类似
<p> 11-13 <a href=/bj/11/70/4969837.html target=_blank> 中介 - 3500元/3居 - 丰台区兆丰园精装修房子一套低价出租 (玉泉路 吴家村) </a>
中取出我们想要的信息,第一就是链接地址:/bj/11/70/496837.html;第二就是其描述信息:中介 - 3500元/3居 - 丰台区兆丰园精装修房子一套低价出租 (玉泉路 吴家村)
现在我们来分析下我们所取字符的共同特征,简单总结一下分为以下几个部分
1.他们都是以<a href=打头,以</a>结尾.
2.在href属性之后有可能还有其他的属性标签,如class,等其它相关的属性.
方向确定我们就可以确定着手写正则式了
首先满足第一条件头就为<a\s+href=;就是这样,很简单吧,同样,末尾为</a>也可以直接写
应该说现在已经可以正常匹配了,不过他匹配了一个整个的<a>标签,不是我们所想要的,我们只是想要其中的部分
所以还需要继续修改,因为我们要在一个标签中去取两个部分,一个链接和描述文字,其最好的方法就是把他们放在一个分组当中,待我们使用时可以直接使用,关于建立分组,前面的资料说的很清楚.为了直观,我们采用自定义分组,即(?<分组名>)格式
一起组织起来就成了我们想要的.
即
 (?<=<a\s+href=(?<link>.*?(?=\starget=)).*?>(?<content>.*?)(?=</a>)
(?<=<a\s+href=(?<link>.*?(?=\starget=)).*?>(?<content>.*?)(?=</a>)
因为时间的关系,其中分析过程略的较多,不过具体大体思路就像如上所说.只不过具体的问题具体分析.
正则 ?<= 和 ?= 用法的更多相关文章
- 正则 ?<= 和 ?= 用法 以及零宽断言等概念
正则 ?<= 和 ?= 用法 参考网址:http://baike.baidu.com/link?url=2zORJF9GOjU8AkmuHDLz9cyl9yiL68PdW3frayzLwW ...
- 正则 ?<= 和 ?= 用法,范例
(exp) 匹配exp,并捕获文本到自动命名的组里(?<name>exp) 匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name'exp)(?:exp) 匹配exp,不捕 ...
- Python爬虫利器之Beautiful Soup,Requests,正则的用法(转)
https://cuiqingcai.com/1319.html https://cuiqingcai.com/2556.html https://cuiqingcai.com/977.html
- String replaceAll 正则注意事项及特殊用法(xjl456852原创)
我们知道String replaceAll(参数a, 参数b) 参数a是需要些正则表达式的. 但是今天试了试,发现参数b也有一些其它特性. 查看源码后,发现有些特性是平时不怎么用的.下面我来介绍一下这 ...
- ASP.NET中EVAL用法大全
<%# Bind("Subject") %> //绑定字段<%# Container.DataItemIndex + 1%> //实现自动编号<%# ...
- Eval()和DataBinder Eval(Container DataItem,)的区别及用法
ASP.NET 2.0改善了模板中的数据绑定操作把v1.x中的数据绑定语法DataBinder.Eval(Container.DataItem, fieldname)简化为Eval(fiel ...
- Python re模块, xpath 用法
1.re正则的用法总结 (1). ^ 表示以哪个字符为开头 eg: '^g' 表示以g开头的字符串 . 表示任意字符 '^g.d' 表示以g开头第二个为任意字符,第三个为b的字 ...
- 终于明白vim 和 grep 中 的正则表达式的用法, vim 正则表达式 和grep基本正则表达式 几乎一样
要搞清楚 vim中的正则和普通的Perl正则表达式的区别: 因为在perl中所有的元字符 都可以直接使用, 不需要在 元字符的前面加 反斜杠. 但是在vim, 包括grep中就有所区别, 同样是元字符 ...
- ToString()格式和用法大全,C#实现保留两位小数的方法
C,货币,2.5.ToString("C"),¥2.50.D,十进制数,25.ToString("D5"),00025.E,科学型,25000.ToString ...
随机推荐
- 华为机试_字符串识别_Vector的使用;
第一题:拼音转数字输入是一个只包含拼音的字符串,请输出对应的数字序列.转换关系如下:描述: 拼音 yi er san si wu liu qi ba jiu ...
- ajax.abort 终止AJAX请求
$(document).ready(function () { var ajax; $('#choice').change(function() ...
- Spread 之自定义对角线cellType源码: DiagonalCellType
最新的SpreadWinform提供了多达24种CellType类型,下面的这2篇博文对新增了GcTextBoxCellType和GcDateTimeCellType单元格格式做了比较详细的说明. & ...
- ugui自制摇杆。
珍爱生命,远离插件. 以上8个字,好好理解. 反正我是这么觉得. 我说的是unity,不是魔兽世界. 总有一天,我会一句一句写出属于自己的东西. 可以开始主题了. 如图所示,建立一个画 ...
- [Guava官方文档翻译] 7. Guava的Immutable Collection(不可变集合)工具 (Immutable Collections Explained)
我的技术博客经常被流氓网站恶意爬取转载.请移步原文:http://www.cnblogs.com/hamhog/p/3538666.html ,享受整齐的排版.有效的链接.正确的代码缩进.更好的阅读体 ...
- HDOJ 1042 N! -- 大数运算
题目地址:http://acm.hdu.edu.cn/showproblem.php?pid=1042 Problem Description Given an integer N(0 ≤ N ≤ 1 ...
- OpenJudge 2803 碎纸机 / Poj 1416 Shredding Company
1.链接地址: http://poj.org/problem?id=1416 http://bailian.openjudge.cn/practice/2803 2.题目: 总时间限制: 1000ms ...
- jQuery—一些常见方法(3)【width(),innerWidth(),outerWidth()】
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- JQuery上传控件 jUploader 使用
jUploader 1.0 Demo Download: jquery.jUploader-1.01.js 9.75kb Download: jquery.jUploader-1.01.min.js ...
- opensuse安装mysql-workbench
首先安装好mysqlserver,做本地测试其实不用安装mysqlclient. 到http://software.opensuse.org/package/mysql-workbench 下载相应版 ...