SpringBoot数据访问(一) SpringBoot整合Mybatis
前言
SpringData是Spring提供的一个用于简化数据库访问、支持云服务的开源框架。它是一个伞形项目,包含了大量关系型数据库及非关系型数据库的数据访问解决方案,其设计目的是为了使我们可以快速且简单地使用各种数据访问技术。
SpringBoot默认采用整合SpringData的方式统一处理数据访问层,通过添加大量自动配置,引入各种数据访问模板xxxTemplate以及统一的Repository接口,从而达到简化数据访问层的操作。
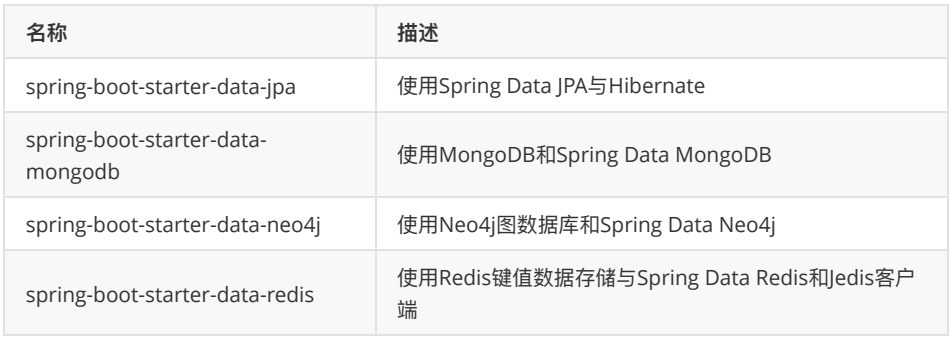
SpringData提供了多种类型数据库支持,对支持的数据库进行了整合,提供了各种依赖启动器,常见数据库依赖启动器如下表所示:
除此之外,还有一些框架技术,SpringData项目并没有进行统一管理,SpringBoot官方也没有提供对应的依赖启动器,但是为了迎合市场开发需求,这些框架技术的开发团队自己适配了对应的依赖启动器,例如,mybatis-spring-boot-starter支持MyBatis的使用。
SpringBoot整合MyBatis
MyBatis是一款优秀的持久层框架,虽然SpringBoot官方并没有对Mybatis进行整合,但是Mybatis技术团队自行适配了对应的启动器,进一步简化了使用Mybatis进行数据的操作。
SpringBoot整合MyBatis的步骤非常简单,只需要引入相关的依赖启动器,再进行数据库相关设置即可。
基础环境搭建
1、数据准备
在MySQL中,执行以下sql脚本:
# 创建数据库
CREATE DATABASE springbootdata;
# 选择使用数据库
USE springbootdata;
# 创建表t_article并插入相关数据
DROP TABLE IF EXISTS t_article;
CREATE TABLE t_article (
id INT(20) NOT NULL AUTO_INCREMENT COMMENT '文章id',
title VARCHAR(200) DEFAULT NULL COMMENT '文章标题',
content LONGTEXT COMMENT '文章内容',
PRIMARY KEY (id)
) ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
INSERT INTO t_article VALUES ('1', 'SpringBoot基础入门', '从入门到放弃...');
INSERT INTO t_article VALUES ('2', 'SpringCloud基础入门', '从入门到转行...'); # 创建表t_comment并插入相关数据
DROP TABLE IF EXISTS t_comment;
CREATE TABLE t_comment (
id INT(20) NOT NULL AUTO_INCREMENT COMMENT '评论id',
content LONGTEXT COMMENT '评论内容',
author VARCHAR(200) DEFAULT NULL COMMENT '评论作者',
a_id INT(20) DEFAULT NULL COMMENT '关联的文章id',
PRIMARY KEY (id)
) ENGINE=INNODB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
INSERT INTO t_comment VALUES ('1', '很好、很详细', 'luccy', '1');
INSERT INTO t_comment VALUES ('2', '赞一个', 'tom', '1');
INSERT INTO t_comment VALUES ('3', '很全面', 'eric', '1');
INSERT INTO t_comment VALUES ('4', '很好、很全面', '张三', '1');
INSERT INTO t_comment VALUES ('5', '很不错', '李四' ,'2');
以上脚本创建了一个名为springbootdata的数据库,然后创建了两张数据表:t_article和t_comment并向这两张表插入相关数据,其中评论表t_comment的a_id与文章表t_article的主键id相关联。
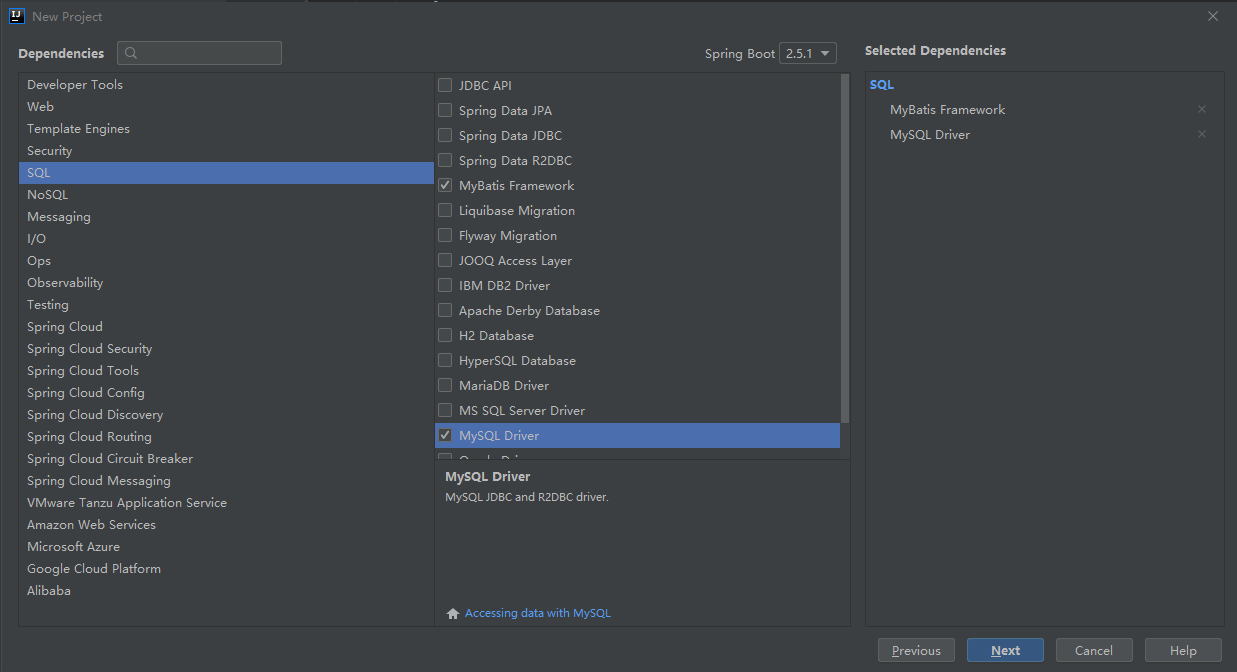
2、创建项目,引入相应的启动器
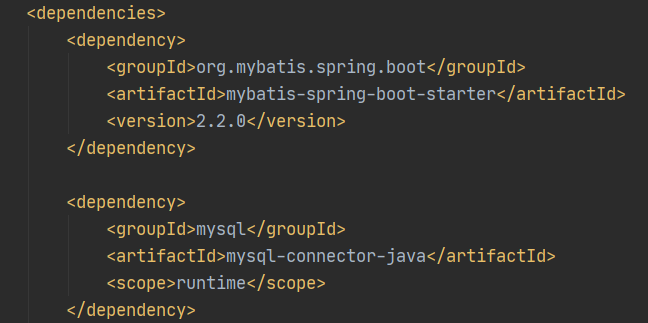
引入这两个依赖器创建项目,在项目pom.xml文件会出现以下依赖:
3、编写与数据库t_article和t_comment和对应的实体类Comment和Article
package com.hardy.springbootdata.entity; /**
* @Author: HardyYao
* @Date: 2021/6/12
*/
public class Article { private Integer id; private String title; private String content; public Integer getId() {
return id;
} public void setId(Integer id) {
this.id = id;
} public String getTitle() {
return title;
} public void setTitle(String title) {
this.title = title;
} public String getContent() {
return content;
} public void setContent(String content) {
this.content = content;
} @Override
public String toString() {
return "Article{" +
"id=" + id +
", title='" + title + '\'' +
", content='" + content + '\'' +
'}';
}
}
package com.hardy.springbootdata.entity; /**
* @Author: HardyYao
* @Date: 2021/6/12
*/
public class Comment { private Integer id; private String content; private String author; private Integer aId; public Integer getId() {
return id;
} public void setId(Integer id) {
this.id = id;
} public String getContent() {
return content;
} public void setContent(String content) {
this.content = content;
} public String getAuthor() {
return author;
} public void setAuthor(String author) {
this.author = author;
} public Integer getaId() {
return aId;
} public void setaId(Integer aId) {
this.aId = aId;
} @Override
public String toString() {
return "Comment{" +
"id=" + id +
", content='" + content + '\'' +
", author='" + author + '\'' +
", aId=" + aId +
'}';
}
}
4、编写配置文件
# MySQL数据库连接配置
spring.datasource.url=jdbc:mysql://localhost:3306/springbootdata?serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=root
使用注解的方式整合Mybatis
(1)编写针对t_comment数据表的mapper数据操作接口
package com.hardy.springbootdata.mapper; import com.hardy.springbootdata.entity.Comment;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select; /**
* @Author: HardyYao
* @Date: 2021/6/12
*/
@Mapper
public interface CommentMapper { @Select("SELECT * FROM t_comment WHERE id =#{id}")
Comment findById(Integer id); }
针对该接口类的讲解:@Mapper注解表示该类是一个MyBatis接口文件,并保证能够被SpringBoot自动扫描到Spring容器中。
这里有个问题,如果编写的Mapper接口过多时,那么就需要在很多个接口类上面添加@Mapper注解,这样会比较耗时间。为了解决这个问题,可以直接在SpringBoot项目启动类上添加@MapperScan("xxx")注解(如 @MapperScan("com.hardy.springbootdata.mapper")),这样就不需要再逐个添加@Mapper注解。(@MapperScan注解作用和@Mapper注解相似,但它必须指定需要扫描的具体包名)。
(2)编写测试方法
package com.hardy.springbootdata; import com.hardy.springbootdata.entity.Comment;
import com.hardy.springbootdata.mapper.CommentMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest; @SpringBootTest
class SpringbootdataApplicationTests { @Autowired
private CommentMapper commentMapper; @Test
void contextLoads() {
Comment comment = commentMapper.findById(1);
System.out.println(comment);
} }
控制台打印结果:

由上图可知,查询到的Comment的aId值为null,没有映射成功。这是因为编写的实体类Comment中使用了驼峰命名方式将t_comment表中的a_id字段设计成了aId属性,所以无法正确映射查询结果。
为了解决这个问题,可以在SpringBoot全局配置文件application.properties中添加开启驼峰命名匹配映射配置,示例代码如下:
# 开启驼峰命名匹配映射
mybatis.configuration.map-underscore-to-camel-case=true
再次运行测试方法,控制台打印结果:

可以看到,这次aId映射成功了。
使用配置文件的方式整合MyBatis
(1)编写针对t_article数据表的mapper数据操作接口
package com.hardy.springbootdata.mapper; import com.hardy.springbootdata.entity.Article;
import org.apache.ibatis.annotations.Mapper; /**
* @Author: HardyYao
* @Date: 2021/6/12
*/
@Mapper
public interface ArticleMapper { Article selectArticle(Integer id); }
(2)创建XML映射文件
在resources目录下创建一个统一管理映射文件的mapper包,并在该包下编写与ArticleMapper接口相应的映射文件ArticleMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.hardy.springbootdata.mapper.ArticleMapper"> <select id="selectArticle" resultType="com.hardy.springbootdata.entity.Article">
select * from t_article where id = #{id, jdbcType=BIGINT}
</select> </mapper>
(3)配置XML映射文件路径。前面我们编写的XML文件,SpringBoot是无法自己感知到的,即SpringBoot无法扫描到我们编写的XML配置文件,所以我们还需要在全局配置文件application.properties中添加MyBatis映射文件路径的配置,同时需要添加实体类别名映射路径,示例代码如下:
# 配置Mybatis的XML配置文件路径
mybatis.mapper-locations=classpath:mapper/*.xml
# 配置XML映射文件中指定的实体类别名路径
mybatis.type-aliases-package=com.hardy.springbootdata.entity
(4)编写单元测试进行接口方法测试
@Autowired
private ArticleMapper articleMapper; @Test
public void selectArticle() {
Article article = articleMapper.selectArticle(1);
System.out.println(article);
}
打印结果:

SpringBoot数据访问(一) SpringBoot整合Mybatis的更多相关文章
- SpringBoot数据访问之整合mybatis注解版
SpringBoot数据访问之整合mybatis注解版 mybatis注解版: 贴心链接:Github 在网页下方,找到快速开始文档 上述链接方便读者查找. 通过快速开始文档,搭建环境: 创建数据库: ...
- springboot使用之二:整合mybatis(xml方式)并添加PageHelper插件
整合mybatis实在前面项目的基础上进行的,前面项目具体整合请参照springboot使用之一. 一.整合mybatis 整合mybatis的时候可以从mybatis官网下载mybatis官网整合的 ...
- SpringBoot数据访问之Druid启动器的使用
数据访问之Druid启动器的使用 承接上文:SpringBoot数据访问之Druid数据源的自定义使用 官方文档: Druid Spring Boot Starter 首先在在 Spring Boot ...
- SpringBoot数据访问之整合Mybatis配置文件
环境搭建以及前置知识回顾 SpringBoot中有两种start的形式: 官方:spring-boot-starter-* 第三方:*-spring-boot-starter Mybatis属于第三方 ...
- SpringBoot数据访问(二) SpringBoot整合JPA
JPA简介 Spring Data JPA是Spring Data大家族的一部分,它可以轻松实现基于JPA的存储库.该模块用于增强支持基于JPA的数据访问层,它使我们可以更加容易地构建使用数据访问技术 ...
- Springboot数据访问,棒棒哒!
Springboot对数据访问部分提供了非常强大的集成,支持mysql,oracle等传统数据库的同时,也支持Redis,MongoDB等非关系型数据库,极大的简化了DAO的代码,尤其是Spring ...
- springboot 数据访问【转】【补】
六.SpringBoot与数据访问 1.JDBC pom.xml配置 <dependencies> <dependency> <groupId>org.spring ...
- SpringBoot数据访问之Druid数据源的使用
数据访问之Druid数据源的使用 说明:该数据源Druid,使用自定义方式实现,后面文章使用start启动器实现,学习思路为主. 为什么要使用数据源: 数据源是提高数据库连接性能的常规手段,数据源 ...
- SpringBoot数据访问(三) SpringBoot整合Redis
前言 除了对关系型数据库的整合支持外,SpringBoot对非关系型数据库也提供了非常好的支持,比如,对Redis的支持. Redis(Remote Dictionary Server,即远程字典服务 ...
随机推荐
- Windows核心编程 第七章 线程的调度、优先级和亲缘性(下)
7.6 运用结构环境 现在应该懂得环境结构在线程调度中所起的重要作用了.环境结构使得系统能够记住线程的状态,这样,当下次线程拥有可以运行的C P U时,它就能够找到它上次中断运行的地方. 知道这样低层 ...
- 【Git】3. Git重要特性-分支操作,合并冲突详解
一.分支介绍 在版本控制过程当中,有时候需要同时推进多个任务,这样的话,就可以给每个任务创建单独的分支. 有了分支之后,对应的开发人员就可以把自己的工作从主线上分离出来,在做自己分支开发的时候,不会影 ...
- 【python】Leetcode每日一题-笨阶乘
[python]Leetcode每日一题-笨阶乘 [题目描述] 通常,正整数 n 的阶乘是所有小于或等于 n 的正整数的乘积.例如,factorial(10) = 10 * 9 * 8 * 7 * 6 ...
- python-文件操作练习-配置文件读取、修改、删除
文件操作练习:http://www.cnblogs.com/wupeiqi/articles/4950799.html global log 127.0.0.1 local2 daemon maxco ...
- 游戏中的2D OBB碰撞模型的碰撞算法介绍和实践
前言 上一篇博文说道,射线与场景中模型上的所有三角形求交时,会大幅度影响效率且花费比较多的时间,因此会采取使用包围盒的形式,进行一个加速求交.在此文中介绍OBB碰撞模型的碰撞算法 OBB的碰撞模型 有 ...
- MySQL慢日志全解析
前言: 慢日志在日常数据库运维中经常会用到,我们可以通过查看慢日志来获得效率较差的 SQL ,然后可以进行 SQL 优化.本篇文章我们一起来学习下慢日志相关知识. 1.慢日志简介 慢日志全称为慢查询日 ...
- 如何安装Eigen库和Sophus库
* { font-family: "Tibetan Machine Uni", "sans-serif", STFangSong; outline: none ...
- apache common pool2原理与实战
完整源码,请帮我点个star哦! 原文地址为https://www.cnblogs.com/haixiang/p/14783955.html,转载请注明出处! 简介 对象池顾名思义就是存放对象的池,与 ...
- Exception in thread "main" java.lang.NoClassDefFoundError: com/google/common/collect/ImmutableMap
selenium + java + mac + idea 报错分析: 网上搜的教程,配置selenium 自动化测试环境,都是只让导入 client-combined-3.141.59-sources ...
- mysql枚举和集合
create table consumer( id int, name char(16), sex enum('male','female','other'), level enum('vip1',' ...