mysql--使用shardingsphere实现分表
一. 简介
为什么要分表,无非就两个原因,要么是并发太高,要么就是数据量太大。
所谓分表就是把传统的单表扩展为多个数据结构一样的表,通过分表策略确定操作哪一张表。
我使用的分表规则是通过主键id进行取模运算。
例如user表,假设分三个表:user_0 user_1 user_2
插入操作:
假设添加一个用户主键id为1 1%3 = 1
该用户将会插入到user_1表中
查询操作:
查询操作时shardingsphere会将个个表中的id进行排序后返回
手把手在springboot中通过shardingsphere实现mysql的分表操作。
它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成,shardingSphere定位为关系型数据库中间件。
二. 编码阶段
1. 依赖引入(主要依赖)
1 <dependency>
2 <groupId>org.mybatis.spring.boot</groupId>
3 <artifactId>mybatis-spring-boot-starter</artifactId>
4 <version>2.2.0</version>
5 </dependency>
6 <!--druid数据源-->
7 <dependency>
8 <groupId>com.alibaba</groupId>
9 <artifactId>druid-spring-boot-starter</artifactId>
10 <version>1.2.1</version>
11 </dependency>
12 <!--shardingsphere-->
13 <dependency>
14 <groupId>org.apache.shardingsphere</groupId>
15 <artifactId>sharding-jdbc-spring-boot-starter</artifactId>
16 <version>4.0.0-RC1</version>
17 </dependency>
18 <dependency>
19 <groupId>org.apache.shardingsphere</groupId>
20 <artifactId>sharding-jdbc-spring-namespace</artifactId>
21 <version>4.0.0-RC1</version>
22 </dependency>
23 <!--jdbc-->
24 <dependency>
25 <groupId>mysql</groupId>
26 <artifactId>mysql-connector-java</artifactId>
27 <version>8.0.22</version>
28 </dependency>
2. 修改配置文件
1 #mybatis信息
2 mybatis:
3 mapper-locations: classpath:mapping/*Mapper.xml
4 type-aliases-package: com.example.demo.entity
5
6 Spring:
7 shardingsphere:
8 datasource:
9 names: master #配置数据源
10 master:
11 type: com.alibaba.druid.pool.DruidDataSource
12 driver-class-name: com.mysql.cj.jdbc.Driver
13 url: jdbc:mysql://127.0.0.1:3306/test_1?serverTimezone=Asia/Shanghai&useSSL=false&allowMultiQueries=true
14 username: lv1
15 password: 123456
16 #配置分表规则
17 sharding:
18 #指定所需分的表
19 tables:
20 #表user_
21 user_:
22 actual-data-nodes: master.user_$->{0..2} #需要分表的表 user_0 user_1 user_2
23 table-strategy:
24 inline:
25 sharding-column: id #主键
26 algorithm-expression: user_$->{id % 3} #分表规则
27 #表order_
28 order_:
29 actual-data-nodes: master.order_$->{0..2} #需要分表的表
30 table-strategy:
31 inline:
32 sharding-column: id #主键
33 algorithm-expression: order_$->{id % 3} #分表规则
34 props:
35 sql:
36 show: true
3. 测试
@RestController
@RequestMapping("/user")
@Api(tags = "用户相关")
public class UserController { @Autowired
private UserService userService; @PostMapping(value = "/create")
@ApiOperation(value = "创建用户")
public Object create(){
List<User> users = new ArrayList<>();
User user1 = new User(1, "Echo", 1, 18, "贵阳");
User user2 = new User(2, "Echo", 1, 18, "贵阳");
User user3 = new User(3, "Echo", 1, 18, "贵阳");
User user4 = new User(4, "Echo", 1, 18, "贵阳");
User user5 = new User(5, "Echo", 1, 18, "贵阳");
User user6 = new User(6, "Echo", 1, 18, "贵阳");
users.add(user1);
users.add(user2);
users.add(user3);
users.add(user4);
users.add(user5);
users.add(user6);
return userService.insertForeach(users);
} @GetMapping(value = "get")
@ApiOperation(value = "获取用户信息")
private Object list(){
return userService.list();
}
}
4. 测试结果
插入效果:
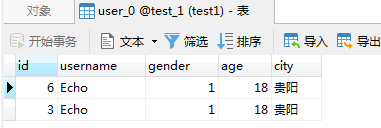
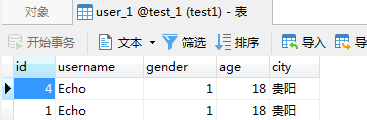
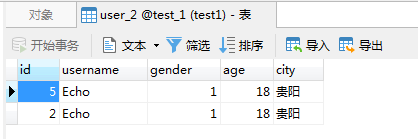
查询效果:
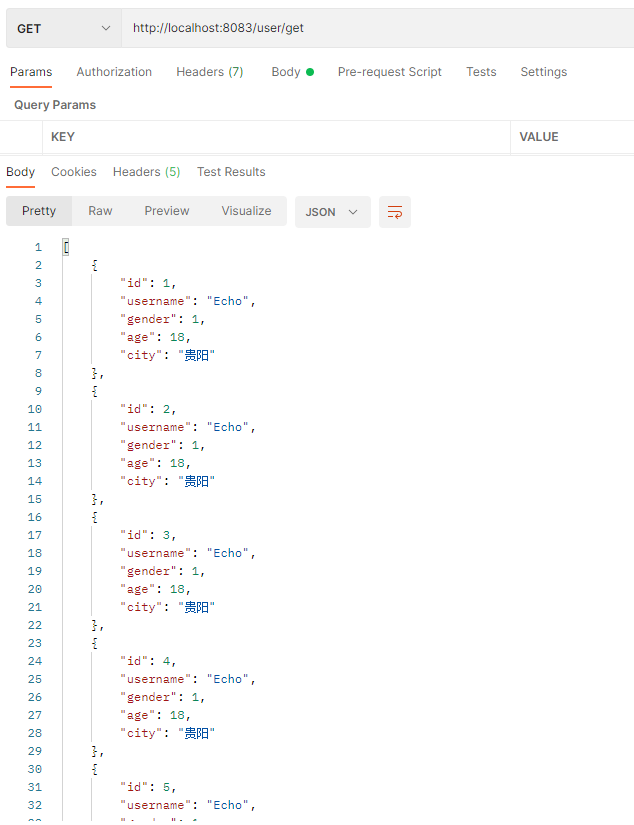
mysql--使用shardingsphere实现分表的更多相关文章
- 分库分表(4) ---SpringBoot + ShardingSphere 实现分表
分库分表(4)--- ShardingSphere实现分表 有关分库分表前面写了三篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论) 3.分库 ...
- 分库分表(6)--- SpringBoot+ShardingSphere实现分表+ 读写分离
分库分表(6)--- ShardingSphere实现分表+ 读写分离 有关分库分表前面写了五篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论 ...
- 支持MySql的数据库自动分表工具DBShardTools发布
支持MySql的数据库自动分表工具DBShardTools发布 前段时间参与了公司的一个项目,这个项目的特点是数据量.访问量都比较大,考虑使用数据库水平分表策略,Google了大半天,竟然没有找到分表 ...
- MySQL纯透明的分库分表技术还没有
MySQL纯透明的分库分表技术还没有 种树人./oneproxy --proxy-address=:3307 --admin-username=admin --admin-password=D033 ...
- MySQL分库备份与分表备份
MySQL分库备份与分表备份 1.分库备份 要求:将mysql数据库中的用户数据库备份,备份的数据库文件以时间命名 脚本内容如下: [root@db01 scripts]# vim backup_da ...
- mysql数据库为什么要分表和分区?
一般下载的源码都带了MySQL数据库的,做个真正意义上的网站没数据库肯定不行. 数据库主要存放用户信息(注册用户名密码,分组,等级等),配置信息(管理权限配置,模板配置等),内容链接(html ,图片 ...
- Mysql中的分库分表
mysql中的分库分表分库:减少并发问题分表:降低了分布式事务分表 1.垂直分表 把其中的不常用的基础信息提取出来,放到一个表中通过id进行关联.降低表的大小来控制性能,但是这种方式没有解决高数据量带 ...
- Mycat安装并实现mysql读写分离,分库分表
Mycat安装并实现mysql读写分离,分库分表 一.安装Mycat 1.1 创建文件夹 1.2 下载 二.mycat具体配置 2.1 server.xml 2.2 schema.xml 2.3 se ...
- Docker安装Mycat并实现mysql读写分离,分库分表
Docker安装Mycat并实现mysql读写分离,分库分表 一.拉取mycat镜像 二.准备挂载的配置文件 2.1 创建文件夹并添加配置文件 2.1.1 server.xml 2.1.2 serve ...
- mysql、oracle分库分表方案之sharding-jdbc使用(非demo示例)
选择开源核心组件的一个非常重要的考虑通常是社区活跃性,一旦项目团队无法进行自己后续维护和扩展的情况下更是如此. 至于为什么选择sharding-jdbc而不是Mycat,可以参考知乎讨论帖子https ...
随机推荐
- Linux文件目录结构详解 (转)
整理自<鸟哥的私房菜> 对于每一个Linux学习者来说,了解Linux文件系统的目录结构,是学好Linux的至关重要的一步.,深入了解linux文件目录结构的标准和每个目录的详细功能, ...
- 42. Trapping Rain Water [dp][stack]
description: Given n non-negative integers representing an elevation map where the width of each bar ...
- 简单学习java内存马
看了雷石的内存马深入浅出,就心血来潮看了看,由于本人java贼菜就不介绍原理了,本文有关知识都贴链接吧 前置知识 本次主要看的是tomcat的内存马,所以前置知识有下列 1.tomcat结构,tomc ...
- ARTS第十一周
受辞职考研和新冠肺炎疫情影响,一直没更.遗憾,数学和专业课再高点就有戏了.继续. 1.Algorithm:每周至少做一个 leetcode 的算法题2.Review:阅读并点评至少一篇英文技术文章3. ...
- 前端-Vue基础2
1.过滤器 前台通过后台传值,要对后台传过来的变量进行特殊处理,比如根据id转成中文等: 1.1 局部过滤器 局部过滤器只针对一个Vue实例 默认将|左侧count传递给右侧方法 {{count|fi ...
- Github Copilot 结合python的使用
之前提交的github copilot技术预览版申请,今天收到准入邮件,于是安上试一试这个准备把我送去电子厂上班的copy a lot ? 官网及申请地址:https://copilot.github ...
- CTF-OldDriver-writeup
题目信息: 有个年轻人得到了一份密文,身为老司机的你能帮他看看么? 附件:enc.txt [{"c": 73660675747411714617220651332429160804 ...
- matlab——插值与拟合
@ 目录 前言 一.拟合 1.定义 2.三种判别准则 3.最小二乘法 (1)一般形式 (2)常用函数 (3)matlab实现 二.插值 1.定义 2.方法 (1)分段线性插值 (2)拉格朗日插值多项式 ...
- Java基础00-Lamda表达式30
1. Lambda表达式 Java8新特征之Lambda表达式 1.1 函数式编程思想概述 1.2 体验Lambda表达式 代码示例: 方式一就不演示了,可以去看Java基础24 方式2:匿名内部类的 ...
- Docker安装和常用配置【Linux】
Linux下安装配置docker 安装指南:https://developer.aliyun.com/article/110806 一.配置国内镜像源 1.1 设置国内阿里巴巴下载源 [root@lo ...