Categorical Reparameterization with Gumbel-Softmax
概
利用梯度反向传播训练网咯几乎是深度学习的不二法门, 但是这往往要求保证梯度的存在, 这在一定程度上限制了一些扩展. 比如在VAE中, 虽然当\(q_{\phi}(z|x)\)是一个正态分布的时候, 我们可以利用reparameterization来保证梯度存在, 即:
\]
但是倘若中间变量是离散变量, 比如我们期望构建一个条件的VAE, 那么我们就没法用这种方式来解决了, 本文就提出了一个对离散分布的近似.
主要内容
Gumbel distribution
由gumbel distribution的性质可以知道, 从离散分布中采样\([\pi_1, \cdots, \pi_k]\)等价于
\]
又\(\arg \max\) 可的一个连续逼近为softmax, 即
\]
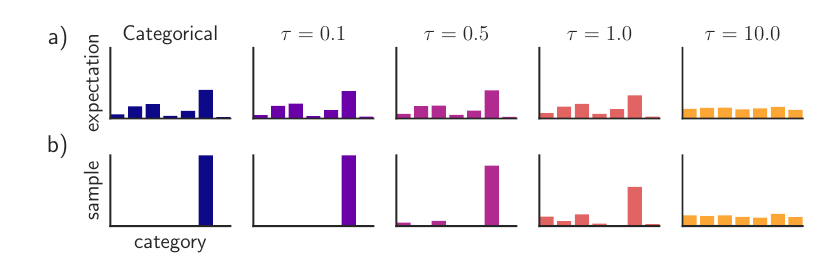
可以发现, 当\(\tau\)比较小的时候, Gumbel-Softmax分布的期望和离散分布的期望是一致的, 采样的情况也是相同的, 我们可以选择一个较小的\(\tau\)使得Gumbel-Softmax分布是离散分布的一个连续近似.
注: 作者偏爱先取一个较大的\(\tau\), 再退火至一个小的\(\tau=0.5\).
注: 作者在概率密度函数的推导过程中, 即公式(15)出有一个小错误, 应当是\(e^{-v}\)而非\(e^{x_k -v}\).
Categorical Reparameterization with Gumbel-Softmax的更多相关文章
- Training spiking neural networks for reinforcement learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 原文链接:https://arxiv.org/pdf/2005.05941.pdf Contents: Abstract Introduc ...
- Texygen文本生成,交大计算机系14级的朱耀明
文本生成哪家强?上交大提出基准测试新平台 Texygen 2018-02-12 13:11测评 新智元报道 来源:arxiv 编译:Marvin [新智元导读]上海交通大学.伦敦大学学院朱耀明, 卢思 ...
- (论文笔记Arxiv2021)Walk in the Cloud: Learning Curves for Point Clouds Shape Analysis
目录 摘要 1.引言 2.相关工作 3.方法 3.1局部特征聚合的再思考 3.2 曲线分组 3.3 曲线聚合和CurveNet 4.实验 4.1 应用细节 4.2 基准 4.3 消融研究 5.总结 W ...
- Transformer模型详解
2013年----word Embedding 2017年----Transformer 2018年----ELMo.Transformer-decoder.GPT-1.BERT 2019年----T ...
- Gumbel-Softmax Trick和Gumbel分布
之前看MADDPG论文的时候,作者提到在离散的信息交流环境中,使用了Gumbel-Softmax estimator.于是去搜了一下,发现该技巧应用甚广,如深度学习中的各种GAN.强化学习中的A2 ...
- 基于Caffe的Large Margin Softmax Loss的实现(中)
小喵的唠叨话:前一篇博客,我们做完了L-Softmax的准备工作.而这一章,我们开始进行前馈的研究. 小喵博客: http://miaoerduo.com 博客原文: http://www.miao ...
- 基于Caffe的Large Margin Softmax Loss的实现(上)
小喵的唠叨话:在写完上一次的博客之后,已经过去了2个月的时间,小喵在此期间,做了大量的实验工作,最终在使用的DeepID2的方法之后,取得了很不错的结果.这次呢,主要讲述一个比较新的论文中的方法,L- ...
- [Machine Learning] logistic函数和softmax函数
简单总结一下机器学习最常见的两个函数,一个是logistic函数,另一个是softmax函数,若有不足之处,希望大家可以帮忙指正.本文首先分别介绍logistic函数和softmax函数的定义和应用, ...
- 前馈网络求导概论(一)·Softmax篇
Softmax是啥? Hopfield网络的能量观点 1982年的Hopfiled网络首次将统计物理学的能量观点引入到神经网络中, 将神经网络的全局最小值求解,近似认为是求解热力学系统的能量最低点(最 ...
随机推荐
- 巩固javaweb第十五天
巩固内容: 单选按钮: 在注册功能中,用户选择学历使用的是单选按钮,并且是多个单选按钮,每个选项对 应一个单选按钮,用户只能选择其中一个,这多个单选按钮的格式相同.如果用户要输入 的信息只有少数几种可 ...
- 关于mysql自动备份的小方法
目前流行几种备份方式:逻辑备份.物理备份.双机热备份.备份脚本的编写等,本文分别从这些方面总结了MySQL自动备份策略的经验和技巧,一起来看看. 目前流行几种备份方式: 一.逻辑备份:使用mysql自 ...
- 4.3 rust func closure
fn add_one_v1 (x: u32) -> u32 { x + 1 } let add_one_v2 = |x: u32| -> u32 { x + 1 }; let add_on ...
- GCD的补充
1-1 关于GCD中的创建和释放 在iOS6.0之前,在GCD中每当使用带creat单词的函数创建对象之后,都应该对其进行一次release操作. 在iOS6.0之后,GC ...
- Leetcode 78题-子集
LeetCode 78 网上已经又很多解这题的博客了,在这只是我自己的解题思路和自己的代码: 先贴上原题: 我的思路: 我做题的喜欢在本子或别处做写几个示例,以此来总结规律:下图就是我从空数组到数组长 ...
- Java如何生成随机数 - Random、ThreadLocalRandom、SecureRandom
Java7 的Random伪随机数和线程安全的ThreadLocalRandom 一.Random伪随机数: Random 类专门用于生成一个伪随机数,它有两个构造器: 一个构造器使用默认的种子(以当 ...
- php-正则邮箱验证及详解
当前的邮箱格式有哪些//1.第1种是QQ邮箱,它的后缀名是,@qq, .com.// 2.第2种是网易邮箱后缀名是,@163.com或者,@126.com// 3.第3种是雅虎邮箱,后缀名是,@yah ...
- Dom 解析XML
xml文件 <?xml version="1.0" encoding="UTF-8"?><data> <book id=&q ...
- greeting-150
拿到程序例行检查,可以看出程序是32位的程序 将程序放入ida中进入主函数查看 但是我们将程序运行一次后发现程序还运行了nao的程序 说明程序在中间还引用了nao函数,通过代码审计我们可以很直接的看到 ...
- [BUUCTF]PWN——[BJDCTF 2nd]r2t4
[BJDCTF 2nd]r2t4 附件 步骤 例行检查,64位,开启了canary和nx 64位ida载入,检索字符串的时候发现了后面函数,shell_addr=0x400626 main函数 可以溢 ...