(二)scrapy 中如何自定义 pipeline 下载图片
这里以一个很简单的小爬虫为例,爬取 壹心理 网站的阅读页面第一页的所有文章及其对应的图片,文章页面如下:
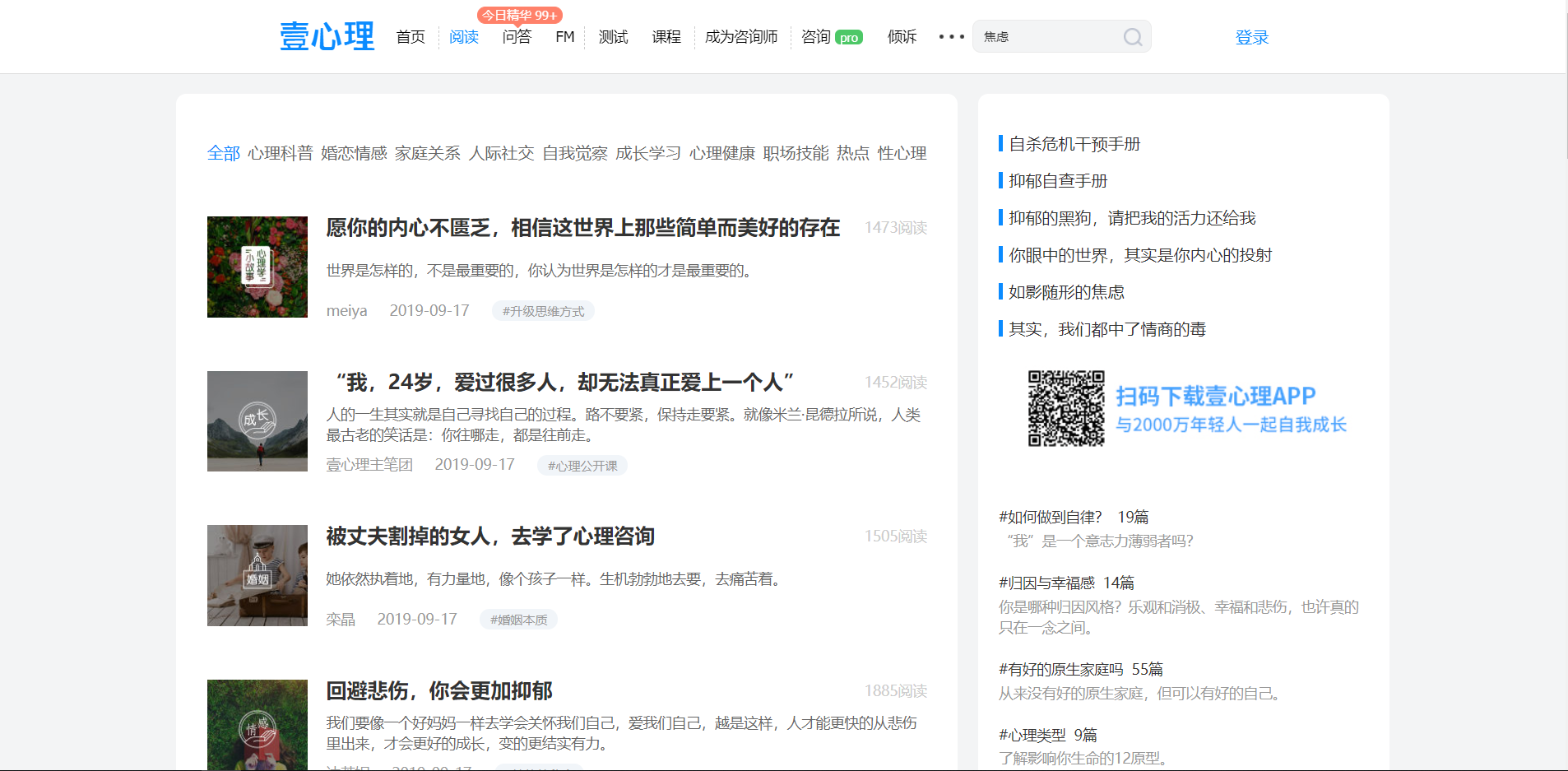
创建项目
首先新建一个 scrapy 项目,安装好相关依赖(步骤可参考:scrapy 安装及新建爬虫项目并运行)。
新建一个爬虫:
scrapy genspider xinli001 'www.xinli001.com/info'
此时项目工程目录与新建的爬虫如下:
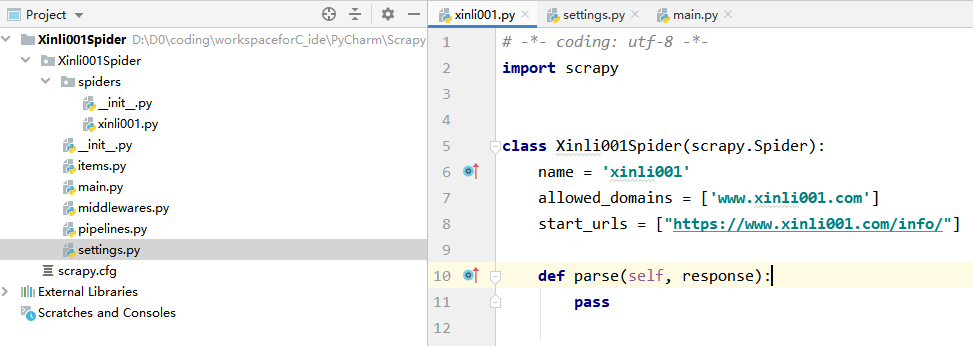
爬取信息并编写图片自动下载逻辑
本次主要是记录自定义 pipeline 来爬取图片,所以只是简单的选取一些信息来爬取,包括文章标题、图片、发布时间和作者。
1.通过 xpath 提取出文章模块,就是下图中方框中的:
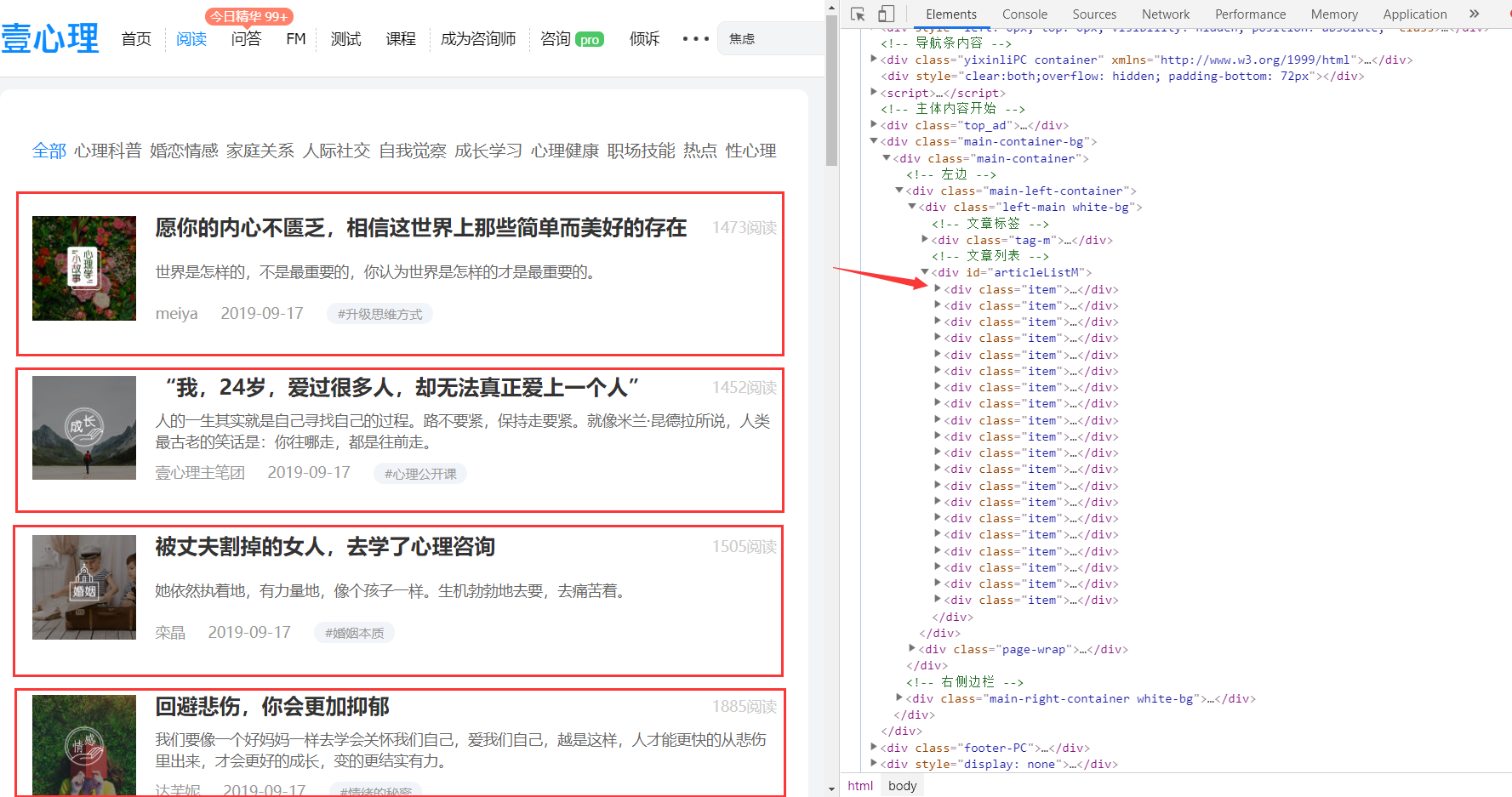
上图右边便是对应的代码位置,下面将先使用 xpath 提取所有 item 模组,之后在对所有 item 组块遍历分别提取其对应的相关信息。
提取 item:
post_nodes = response.xpath('//*[@id="articleListM"]//div[@class="item"]')
2.遍历 post_nodes 并从中提取出相关信息:
下面给出第一个 item 中的网页结构:
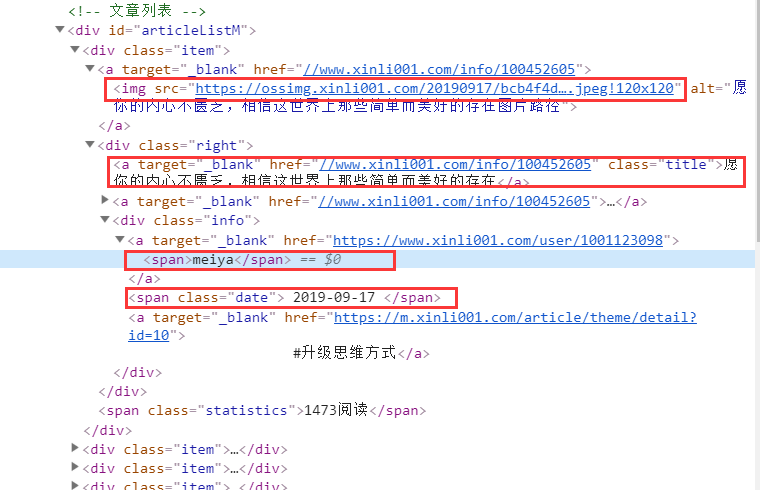
对照上面结构提取相关信息:
# 图片
image_url= post_node.xpath('a/img/@src').extract_first()
# 标题
title = post_node.xpath('div[@class="right"]/a/text()').extract_first()
# 发布时间
create_date = post_node.xpath('div[@class="right"]/div[@class="info"]/span/text()').extract_first()
# 作者
writer = post_node.xpath('div[@class="right"]/div[@class="info"]/a[1]/span/text()').extract_first()
3.定义 Xinli001Item
在 item.py 文件中添加 xinli001 爬虫对应的 item:
class Xinli001SpiderItem(scrapy.Item):
title = scrapy.Field()
image_url = scrapy.Field()
writer = scrapy.Field()
create_date = scrapy.Field()
4.提交 item 实例
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
from urllib import parse
from Xinli001Spider.items import Xinli001SpiderItem
class Xinli001Spider(scrapy.Spider):
name = 'xinli001'
allowed_domains = ['www.xinli001.com']
start_urls = ["https://www.xinli001.com/info/"]
def parse(self, response):
# 提取文章 model
post_nodes = response.xpath('//*[@id="articleListM"]//div[@class="item"]')
for post_node in post_nodes:
# 创建 item 实例
article_item = Xinli001SpiderItem()
# 图片
image_url= post_node.xpath('a/img/@src').extract_first()
# 标题
title = post_node.xpath('div[@class="right"]/a/text()').extract_first()
# 发布时间
create_date = post_node.xpath('div[@class="right"]/div[@class="info"]/span/text()').extract_first()
# 作者
writer = post_node.xpath('div[@class="right"]/div[@class="info"]/a[1]/span/text()').extract_first()
article_item['image_url'] = [image_url]
article_item['title'] = title
article_item['create_date'] = create_date
article_item['writer'] = writer
# 提交 item 实例给 pipeline 处理
yield article_item
5.配置图片下载相关参数:
# 实现自动的图片下载的相关配置
IMAGES_URLS_FIELD = "image_url" # 图片
project_dir = os.path.abspath(os.path.dirname(__file__)) # 获取当前路径
IMAGES_STORE = os.path.join(project_dir, 'images') # 将图片保存到当前项目路径下的 images 文件夹下
将上面的代码加入到 settings.py 中 Configure item pipelines 相关代码的下方。
6.启用 scrapy 的图片下载
在第5步之后,需要在 settings.py 中开启图片下载的服务:
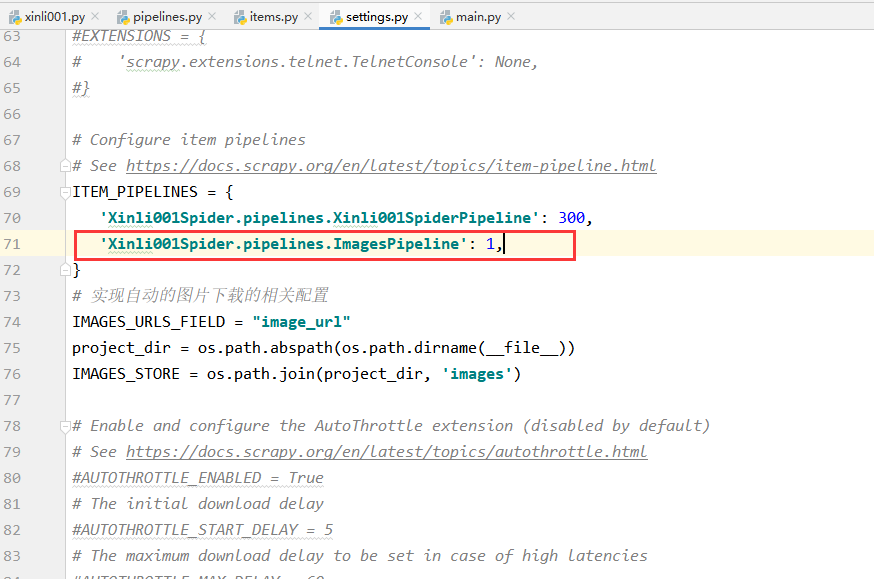
7.再次运行爬虫,便可实现图片的自动下载
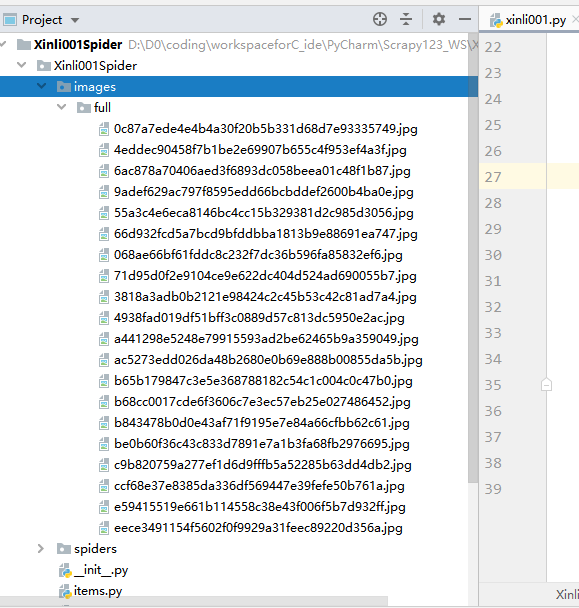
获取图片存放路径
图片下载之后,若要想访问图片,则需要获得图片的存放路径,此时我们便可对上面的 ImagePipeline 实现自定义来将获取图片存放路径的逻辑填充进代码中。
1-首先,添加 ArticleImagePipeline 类:
# 自定义 ImagePipeline ,继承自 ImagesPipeline,并添加相关自定义操作
class ArticleImagePipeline(ImagesPipeline):
# 重写 item_completed 方法
def item_completed(self, results, item, info):
# 默认传过来的 result 是一个list
# ok 表示返回是否成功,value是一个dict,存放了图片保存的路径
for ok, value in results:
image_file_path = value["path"]
# 将获得的文件存放路径填充到 item 中
item["front_image_path"] = image_file_path
# 返回item
return item
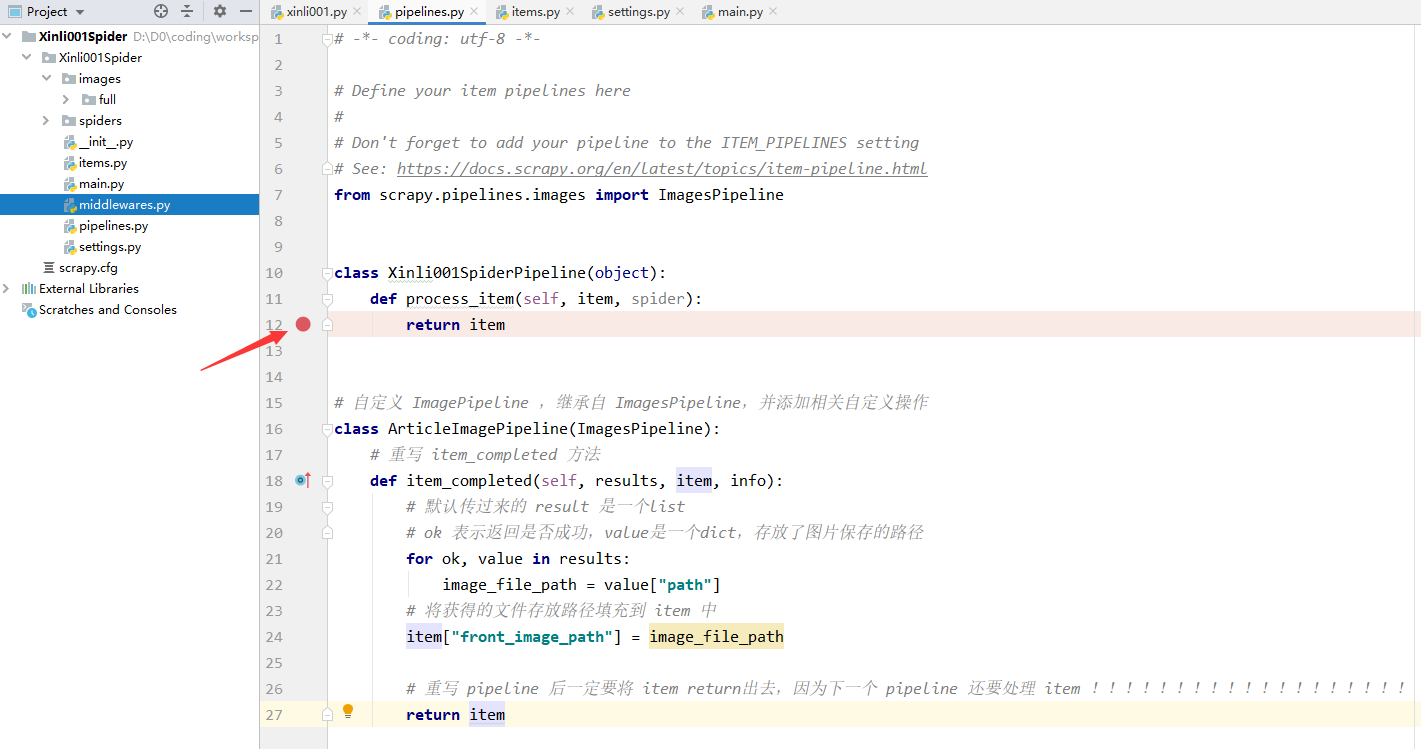
2-将 ArticleImagePipeline 配置到 settings.py 文件中:
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'Xinli001Spider.pipelines.Xinli001SpiderPipeline': 300,
# 'Xinli001Spider.pipelines.ImagesPipeline': 1,
'Xinli001Spider.pipelines.ArticleImagePipeline': 1,
}
注意上面之前使用的 ImagesPipeline 不需要了,要注释掉。
3-添加相关 item 属性
在 Xinli001SpiderItem 中添加一个 front_image_path 属性来存储图片存放路径:

4-查看返回的图片路径
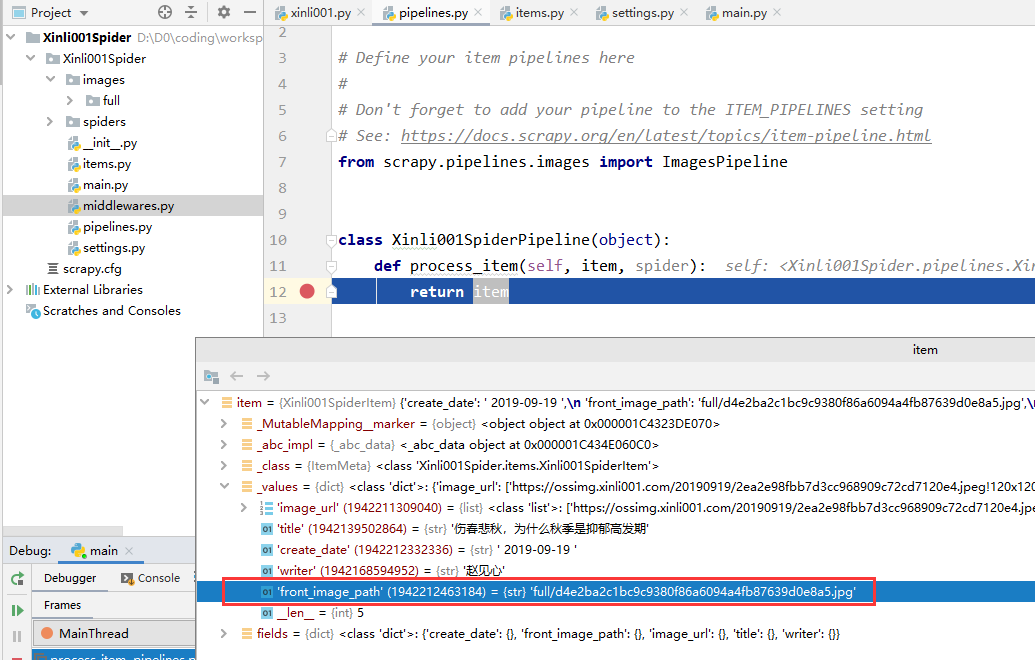
第二步中我们配置了两个 Pipeline ,一个顺序在前(ArticleImagePipeline:1),一个在后(Xinli001SpiderPipeline:300),我们可以在后面的 Pipeline 处理函数处打个断点,然后启动调试功能来运行。
打断点:
debug 一下:
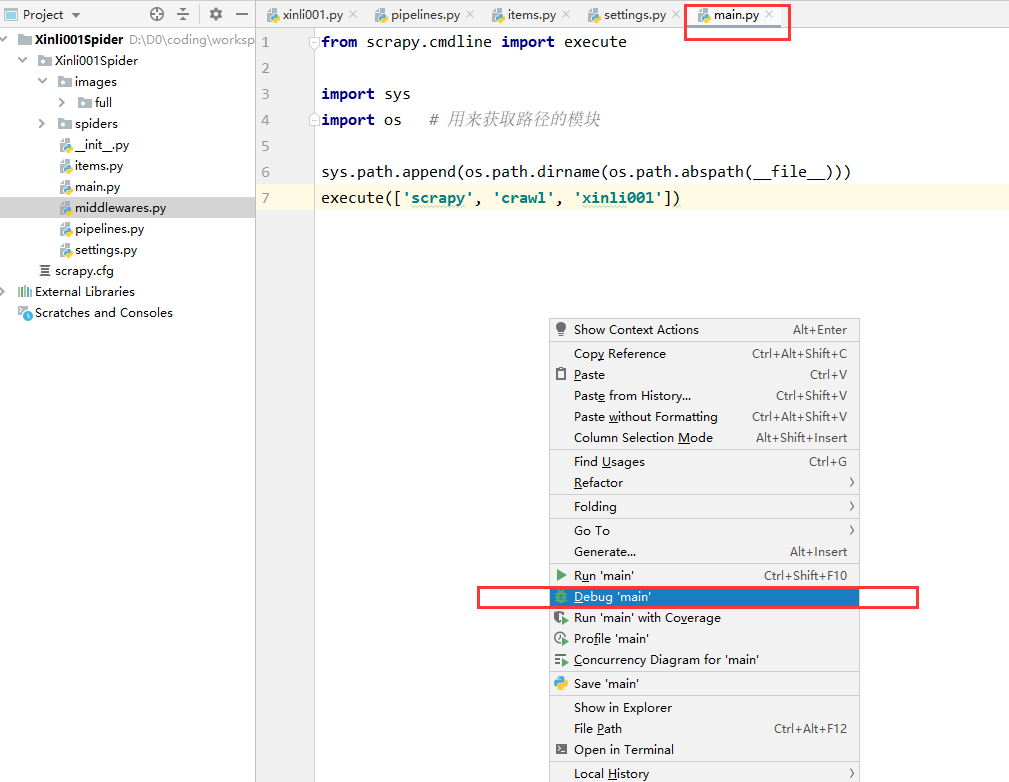
可以看到执行到断点处时,已经提取到了图片存放路径:
(二)scrapy 中如何自定义 pipeline 下载图片的更多相关文章
- 通过scrapy内置的ImagePipeline下载图片到本地、并提取本地保存地址
1.通过scrapy内置的ImagePipeline下载图片到本地 2.获取图片保存本地的地址 1.通过scrapy内置的ImagePipeline下载图片到本地 1)在settings.py中打开 ...
- 使用Scrapy自带的ImagesPipeline下载图片,并对其进行分类。
ImagesPipeline是scrapy自带的类,用来处理图片(爬取时将图片下载到本地)用的. 优势: 将下载图片转换成通用的JPG和RGB格式 避免重复下载 缩略图生成 图片大小过滤 异步下载 . ...
- Expo大作战(十二)--expo中的自定义样式Custom font,以及expo中的路由Route&Navigation
简要:本系列文章讲会对expo进行全面的介绍,本人从2017年6月份接触expo以来,对expo的研究断断续续,一路走来将近10个月,废话不多说,接下来你看到内容,讲全部来与官网 我猜去全部机翻+个人 ...
- 自定义NSOperation下载图片
自定义NSOperation的话,只是需要将要下载图片的操作下载它的main方法里面,考虑到,图片下载完毕,需要回传到控制器里,这里可以采用block,也可以采用代理的方式实现,我采用的是代理的方式实 ...
- cropper.js 二次开发:截图并下载图片
cropper.js 是一个基于jquery的图片截取库. 参考:https://blog.csdn.net/weixin_38023551/article/details/78792400 我的代码 ...
- scrapy中的ImagePipeline下载图片到本地、并提取本地的保存地址
通过scrapy内置到ImagePipeline下载图片到本地 在settings中打开 ITEM_PIPELINES的注释,并在这里面加入 'scrapy.pipelines.images.Imag ...
- iOS下载图片失败
一.具体问题 开发的过程中,发现某个界面部分图片的显示出现了问题只显示占位图片,取出图片的url在浏览器却是能打开的,各种尝试甚至找同行的朋友帮忙在他们项目里展示都会存在问题,最终发现通过第三方框架S ...
- WinCE开机Logo的实现(USB下载图片到nandflash)
WinCE开机启动Logo使用Eboot读取NandFlash中的图片数据,然后显示的方式.对于开机logo的方式网友http://jazka.blog.51cto.com/809003/664131 ...
- Scrapy框架——介绍、安装、命令行创建,启动、项目目录结构介绍、Spiders文件夹详解(包括去重规则)、Selectors解析页面、Items、pipelines(自定义pipeline)、下载中间件(Downloader Middleware)、爬虫中间件、信号
一 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的用途十分广泛,可 ...
随机推荐
- C#winform控件序列化,反序列化
using System; using System.Collections.Generic; using System.Drawing; using System.IO; using System. ...
- 学习AJAX必知必会(3)~自动重启工具nodemon、缓存问题、请求超时和网络异常、取消重复请求
1.nodemon 自动重启工具(自动重启基于nodejs开发的服务端应用) ■ nodemon 是一个工具,通过在检测到目录中的文件更改时自动重新启动node应用程序来帮助开发node.js. // ...
- gorm创建记录及设置字段默认值
package main import ( "database/sql" "gorm.io/driver/mysql" "gorm.io/gorm&q ...
- AOP操作-准备工作
AOP操作(准备) 1,Spring 框架中一般基于 AspectJ 实现AOP操作 (1)什么是 AspectJ *AspectJ 不是 Spring 组成部分,独立AOP框架,一般把 Aspect ...
- IoC容器-Bean管理XML方式(p名称空间注入)
5,p名称空间注入(简化xml配置) (1)使用p名称空间注入,可以简化基于xml配置方式 (了解实际用不多) 第一步 添加 p 名称空间在配置文件中 第二步 进行属性注入,在bean标签里面进行 ...
- 集合框架-工具类-Collections-其他方法将非同步集合转成同步集合的方法
集合框架TXT Collections-其他方法将非同步集合转成同步集合的方法
- NGINX的动静分离;什么是负载均衡
目录 一:动静分离 二:负载均衡 一:动静分离 动静分离是指在 web 服务器架构中,将静态页面与动态页面或者静态内容接口和动态内容接口分开不同系统访问的架构设计方法,进而提示整个服务的访问性和可维护 ...
- 第06讲:Flink 集群安装部署和 HA 配置
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 第04讲:Flin ...
- python 小兵(10)内置函数
内置函数(下午讲解) 什么是内置函数?就是python帮我们提供的一个工具,拿过直接用就行,比如我们的print,input,type,id等等.截止到python3.6.2版本 中一共提供了68个内 ...
- 实用的linux 命令
1. 查看当前文件夹下文件或文件夹所占磁盘的大小 du -sh *|sort -rh 2. 查找某个进程号,脚本或程序所在目录的方法 ll /proc/进程id 3. awk 的用法 (1)累加: a ...