RDD的运行机制
1. RDD 的设计与运行原理
Spark 的核心是建立在统一的抽象 RDD 之上,基于 RDD 的转换和行动操作使得 Spark 的各个组件可以无缝进行集成,从而在同一个应用程序中完成大数据计算任务。
在实际应用中,存在许多迭代式算法和交互式数据挖掘工具,这些应用场景的共同之处在于不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。而 Hadoop 中的 MapReduce 框架都是把中间结果写入到 HDFS 中,带来了大量的数据复制、磁盘 IO 和序列化开销,并且通常只支持一些特定的计算模式。而 RDD 提供了一个抽象的数据架构,从而让开发者不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同 RDD 之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘 IO 和序列化开销。
一个 RDD 就是一个分布式对象集合,提供了一种高度受限的共享内存模型,其本质上是一个只读的分区记录集合,不能直接修改。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段,并且一个 RDD 的不同分区可以保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD 提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定 RDD 之间的相互依赖关系。RDD 提供的转换接口都非常简单,都是类似 map 、filter 、groupBy 、join 等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD 比较适合对于数据集中元素执行相同操作的批处理式应用,而不适合用于需要异步、细粒度状态的应用,比如 Web 应用系统、增量式的网页爬虫等。
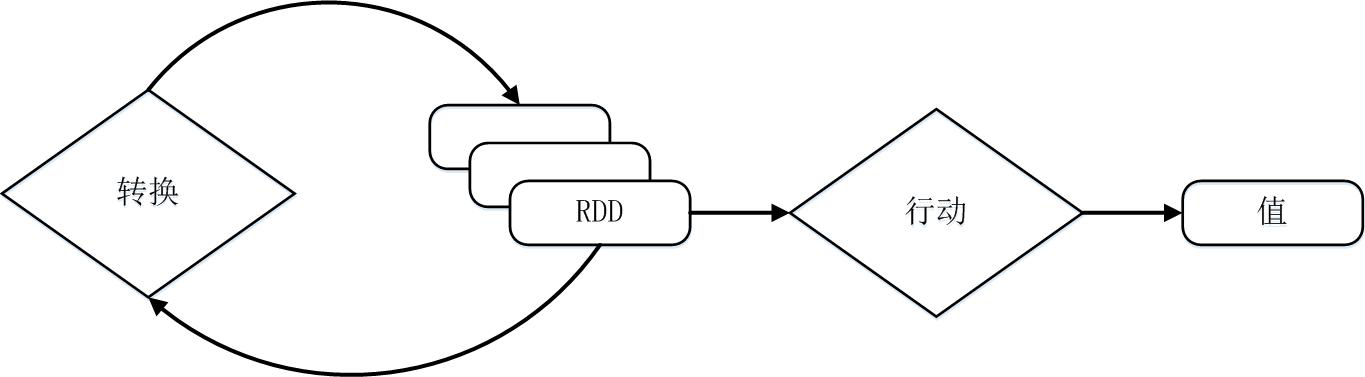
RDD 的典型的执行过程如下:
读入外部的数据源(或者内存中的集合)进行 RDD 创建;
RDD 经过一系列的 “转换” 操作,每一次都会产生不同的 RDD,供给下一个转换使用;
最后一个 RDD 经过 “行动” 操作进行处理,并输出指定的数据类型和值。
RDD 采用了惰性调用,即在 RDD 的执行过程中,所有的转换操作都不会执行真正的操作,只会记录依赖关系,而只有遇到了行动操作,才会触发真正的计算,并根据之前的依赖关系得到最终的结果。
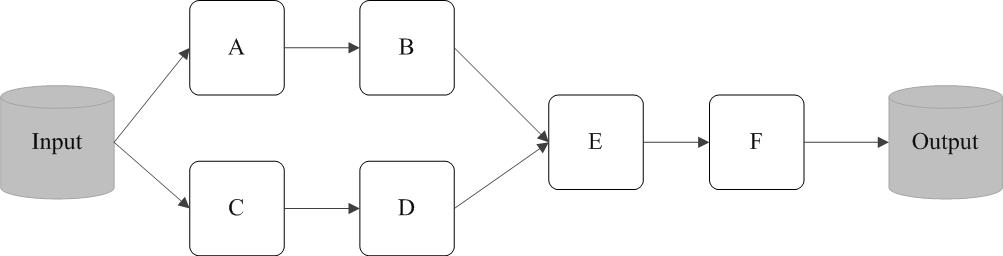
下面以一个实例来描述 RDD 的实际执行过程,如下图所示,开始从输入中创建了两个 RDD,分别是 A 和 C,然后经过一系列的转换操作,最终生成了一个 F,这也是一个 RDD。注意,这些转换操作的执行过程中并没有执行真正的计算,基于创建的过程也没有执行真正的计算,而只是记录的数据流向轨迹。当 F 执行了行为操作并生成输出数据时,Spark 才会根据 RDD 的依赖关系生成有向无环图(DAG),并从起点开始执行真正的计算。正是 RDD 的这种惰性调用机制,使得转换操作得到的中间结果不需要保存,而是直接管道式的流入到下一个操作进行处理。
总体而言,Spark 采用 RDD 以后能够实现高效计算的主要原因如下:
高效的容错性。在 RDD 的设计中,只能通过从父 RDD 转换到子 RDD 的方式来修改数据,这也就是说我们可以直接利用 RDD 之间的依赖关系来重新计算得到丢失的分区,而不需要通过数据冗余的方式。而且也不需要记录具体的数据和各种细粒度操作的日志,这大大降低了数据密集型应用中的容错开销。
中间结果持久化到内存。数据在内存中的多个 RDD 操作之间进行传递,不需要在磁盘上进行存储和读取,避免了不必要的读写磁盘开销;
存放的数据可以是 Java 对象,避免了不必要的对象序列化和反序列化开销。
RDD 中的不同的操作会使得不同 RDD 中的分区会产生不同的依赖关系,主要分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency)。其中,窄依赖表示的是父 RDD 和子 RDD 之间的一对一关系或者多对一关系,主要包括的操作有 map、filter、union 等;而宽依赖则表示父 RDD 与子 RDD 之间的一对多关系,即一个父 RDD 转换成多个子 RDD,主要包括的操作有 groupByKey、sortByKey 等。
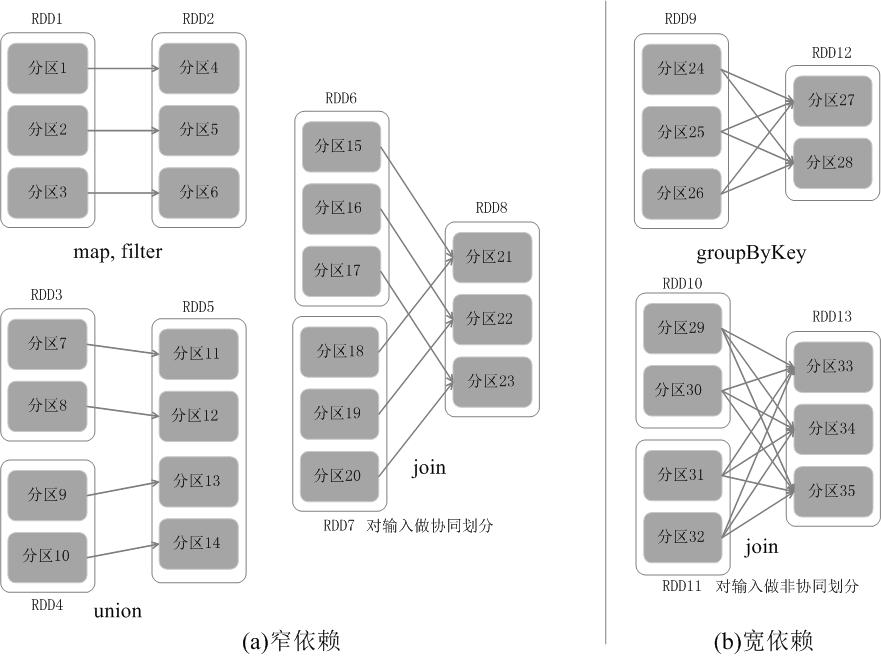
对于窄依赖的 RDD,可以以流水线的方式计算所有父分区,不会造成网络之间的数据混合。对于宽依赖的 RDD,则通常伴随着 Shuffle 操作,即首先需要计算好所有父分区数据,然后在节点之间进行 Shuffle。因此,在进行数据恢复时,窄依赖只需要根据父 RDD 分区重新计算丢失的分区即可,而且可以并行地在不同节点进行重新计算。而对于宽依赖而言,单个节点失效通常意味着重新计算过程会涉及多个父 RDD 分区,开销较大。此外,Spark 还提供了数据检查点和记录日志,用于持久化中间 RDD,从而使得在进行失败恢复时不需要追溯到最开始的阶段。在进行故障恢复时,Spark 会对数据检查点开销和重新计算 RDD 分区的开销进行比较,从而自动选择最优的恢复策略。
Spark 通过分析各个 RDD 的依赖关系生成了 DAG ,再通过分析各个 RDD 中的分区之间的依赖关系来决定如何划分阶段,具体划分方法是:在 DAG 中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的 RDD 加入到当前的阶段中;将窄依赖尽量划分在同一个阶段中,可以实现流水线计算。例如在下图中,首先根据数据的读取、转化和行为等操作生成 DAG。然后在执行行为操作时,反向解析 DAG,由于从 A 到 B 的转换和从 B、F 到 G 的转换都属于宽依赖,则需要从在宽依赖处进行断开,从而划分为三个阶段。把一个 DAG 图划分成多个 “阶段” 以后,每个阶段都代表了一组关联的、相互之间没有 Shuffle 依赖关系的任务组成的任务集合。每个任务集合会被提交给任务调度器(TaskScheduler)进行处理,由任务调度器将任务分发给 Executor 运行。
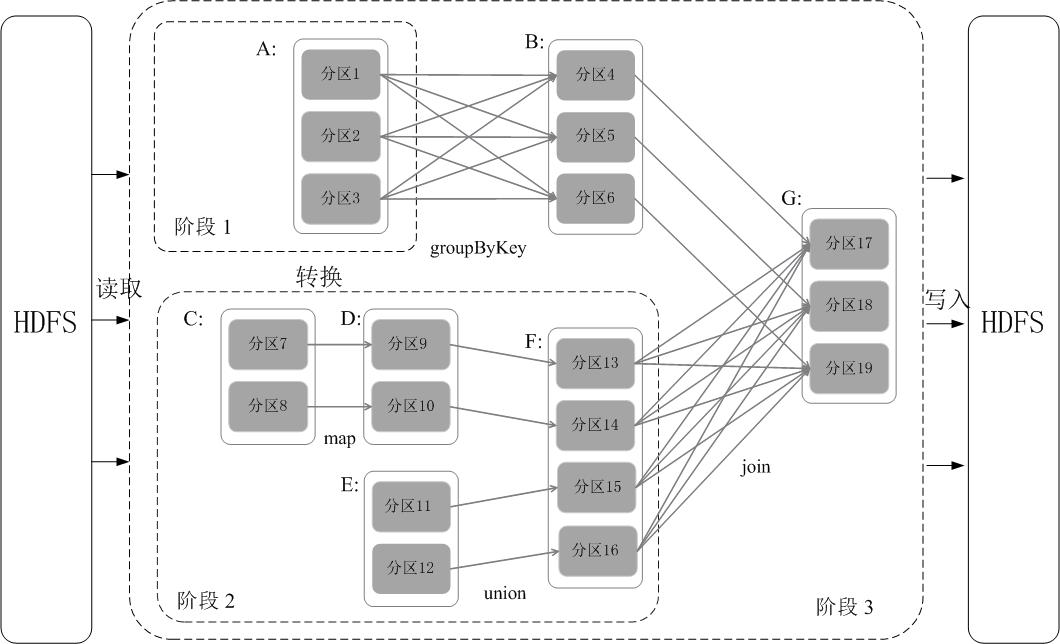
通过上述对 RDD 概念、依赖关系和阶段划分的介绍,结合之前介绍的 Spark 运行基本流程,这里再总结一下 RDD 在 Spark 架构中的运行过程(如下图所示):
创建 RDD 对象;
SparkContext 负责计算 RDD 之间的依赖关系,构建 DAG;
DAGSchedule 负责把 DAG 图反向解析成多个阶段,每个阶段中包含多个任务,每个任务会被任务调度器分发给工作节点上的 Executor 上执行。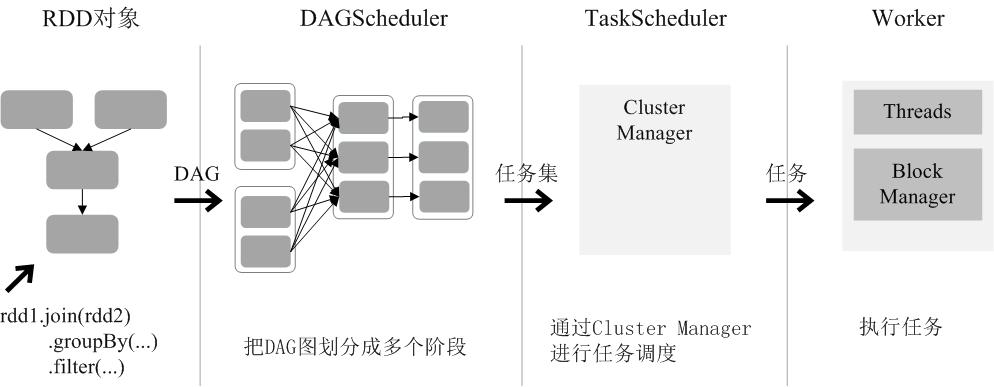
RDD的运行机制的更多相关文章
- Spark 中 RDD的运行机制
1. RDD 的设计与运行原理 Spark 的核心是建立在统一的抽象 RDD 之上,基于 RDD 的转换和行动操作使得 Spark 的各个组件可以无缝进行集成,从而在同一个应用程序中完成大数据计算任务 ...
- Spark Streaming架构设计和运行机制总结
本期内容 : Spark Streaming中的架构设计和运行机制 Spark Streaming深度思考 Spark Streaming的本质就是在RDD基础之上加上Time ,由Time不断的运行 ...
- 通过案例对 spark streaming 透彻理解三板斧之三:spark streaming运行机制与架构
本期内容: 1. Spark Streaming Job架构与运行机制 2. Spark Streaming 容错架构与运行机制 事实上时间是不存在的,是由人的感官系统感觉时间的存在而已,是一种虚幻的 ...
- 通过案例对 spark streaming 透彻理解三板斧之二:spark streaming运行机制
本期内容: 1. Spark Streaming架构 2. Spark Streaming运行机制 Spark大数据分析框架的核心部件: spark Core.spark Streaming流计算. ...
- Spark Streaming揭秘 Day19 架构设计和运行机制
Spark Streaming揭秘 Day19 架构设计和运行机制 今天主要讨论一些SparkStreaming设计的关键点,也算做个小结. DStream设计 首先我们可以进行一个简单的理解:DSt ...
- 【Spark Core】任务运行机制和Task源代码浅析1
引言 上一小节<TaskScheduler源代码与任务提交原理浅析2>介绍了Driver側将Stage进行划分.依据Executor闲置情况分发任务,终于通过DriverActor向exe ...
- 【Spark 深入学习 04】再说Spark底层运行机制
本节内容 · spark底层执行机制 · 细说RDD构建过程 · Job Stage的划分算法 · Task最佳计算位置算法 一.spark底层执行机制 对于Spark底层的运行原理,找到了一副很好的 ...
- 2.Spark Streaming运行机制和架构
1 解密Spark Streaming运行机制 上节课我们谈到了技术界的寻龙点穴.这就像过去的风水一样,每个领域都有自己的龙脉,Spark就是龙脉之所在,它的龙穴或者关键点就是SparkStreami ...
- (十三)Maven插件解析运行机制
这里给大家详细说一下Maven的运行机制,让大家不仅知其然,更知其所以然. 1.插件保存在哪里? 与我们所依赖的构件一样,插件也是基于坐标保存在我们的Maven仓库当中的.在用到插件的时候会先从本地仓 ...
随机推荐
- 【笔记】thanos ruler组件
阅读官网文档后的笔记:https://thanos.io/tip/components/rule.md/ 感受 官网第一个话就强调风险,看来坑很多,能不用尽量不用 recording rule &am ...
- 【解决了一个小问题】golang protocol buffers 3中去掉json标签中的omitempty
参考了这篇帖子:golang protobuf从生成的json标记中删除omitempty标记 由于是在windows上开发,因此写了一个python脚本来解决: remove_tag.py impo ...
- golang中值类型的嵌入式字段和指针类型的嵌入式字段
总结: 1. 值类型的嵌入式字段,该类型拥有值类型的方法集,没有值指针类型的方法集 2. 指针类型的嵌入式字段,该类型拥有值指针类型的方法集,没有值类型的方法集,并且,该类型的指针类型也有值指针类型的 ...
- String类-intern方法
1 package cn.itcast.p1.string.demo; 2 3 class StringObjectDemo { 4 public static void main(String[] ...
- http8种请求方式
根据HTTP标准,HTTP请求可以使用多种请求方法. HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法. HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELE ...
- Android开发----使用 Room 将数据保存到本地数据库
Room介绍以及不使用SQLite的原因 Room 在 SQLite 上提供了一个抽象层,以便在充分利用 SQLite 的强大功能的同时,能够流畅地访问数据库. 处理大量结构化数据的应用可极大地受益于 ...
- CNN-卷积神经网络简单入门(2)
在上篇中,对卷积神经网络的卷积层以及池化层模块进行了简单的介绍,接下来将对卷积神经网络的整个运作流程进行分析,以便对CNN有个总体上的认知和掌握. 如下图,卷积神经网络要完成对图片数字的识别任务.网络 ...
- MariaDB Spider 数据库分库分表实践
分库分表 一般来说,数据库分库分表,有以下做法: 按哈希分片:根据一条数据的标识计算哈希值,将其分配到特定的数据库引擎中: 按范围分片:根据一条数据的标识(一般是值),将其分配到特定的数据库引擎中: ...
- 如何在Visual Studio中添加opencvsharp的可视化工具
这个文件放到这个目录下,就可以看mat对象查看了
- CF1399F Yet Another Segments Subset
首先注意一下题面要求,使得选出的线段两两要么包含要么不相交,也就是说一条线段可能会出现不相交的几条线段,而这些线段上面也可能继续这样包含线段.然后我们可以发现我们要做的实际上是在这条线段上选取几条线段 ...