语音降噪论文“A Hybrid Approach for Speech Enhancement Using MoG Model and Neural Network Phoneme Classifier”的研读
最近认真的研读了这篇关于降噪的论文。它是一种利用混合模型降噪的方法,即既利用了生成模型(MoG高斯模型),也利用了判别模型(神经网络NN模型)。本文根据自己的理解对原理做了梳理。
论文是基于“Speech Enhancement Using a Mixture-Maximum Model”提出的MixMAX模型的。假设噪声是加性噪声,干净语音为x(t),噪声为y(t),则在时域带噪语音z(t)可以表示为z(t) = x(t) + y(t)。对z(t)做短时傅里叶变换(STFT)得到Z(k),再取对数谱(log-spectral)可得到Zk(k表示对数谱的第k维,即对数谱的第k个频段(frequency bin)。若做STFT的样本有L个,则对数谱的维数是 L/2 + 1)。相应的可得到Xk和Yk。MixMAX模型是指加噪后语音的每个频段上的值Zk是对应的Xk和Yk中的大值,即 = MAX(Xk, Yk)。
语音x由音素组成,设定一个音素可用一个高斯表示。假设音素有m个,则干净语音的密度函数f(x)可以表示成下式:

fi(x)表示第i个音素的密度函数。由于x是用多维的对数谱表示的,且各维向量之间相互独立,所以fi(x)可以表示成各维向量的密度函数fi,k(xk)的乘积。各维的密度函数表示如下式:
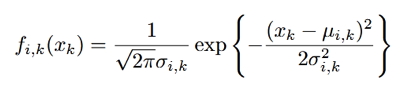
μi,k表示这一维上的均值,δi,k表示这一维上的方差。ci表示这个音素所占的权重,权重的加权和要为1。
噪声y只用一个高斯表示。同语音一样,y也是用多维的对数谱表示的,y的密度函数可以表示如下:
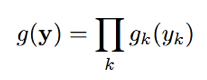
同样gk(yk)表示如下:
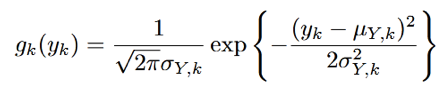
对于y每一维上的密度函数,其概率分布函数Gk(y)为:
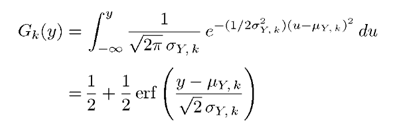
其中erf()为误差函数,表示如下:

同理可求得干净语音中每个音素的每一维上的概率分布函数,如下式:
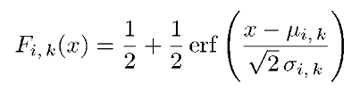
对于带噪语音Z来说,当语音音素给定时(即i给定时)其对数谱的第k维分量Zk的分布函数Hi,k(z)可以通过下式求得:

上式就是求I = i时的条件概率。由于X和Y相互独立,就变成了X和Y的第k维向量上的分布函数的乘积。对Zk的分布函数Hi,k(z)求导,就得到了的密度函数hi,k(z),表示如下:
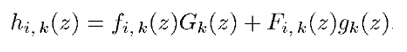
所以z的密度函数h(z)通过下式求得:
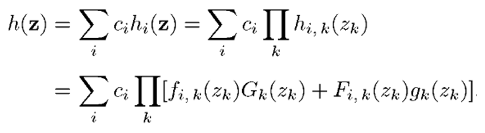
带噪语音Z已知,我们的目标是要根据带噪语音估计出干净语音X,即求出Z已知条件下的X的条件期望。基于MMSE估计,X的条件期望/估计表示如下:
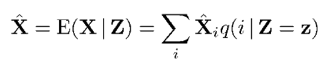
上式中X的条件期望又转换成了每个音素条件期望的加权和。条件概率q(i | Z = z)可根据全概率公式得到,如下:
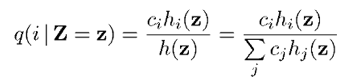
对于每个音素的条件期望,表示如下: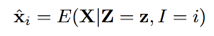 。对于每个音素的对数谱的每一维的条件期望,表示如下:
。对于每个音素的对数谱的每一维的条件期望,表示如下:
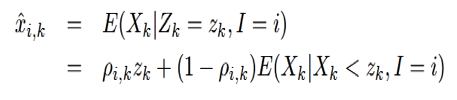
其中:

定义  ,可以推得x的对数谱的每一维上的估计如下式:
,可以推得x的对数谱的每一维上的估计如下式:

可以把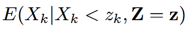 用基于谱减的
用基于谱减的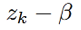 替代,其中β表示消噪程度。ρk可以看成是干净语音的概率。所以
替代,其中β表示消噪程度。ρk可以看成是干净语音的概率。所以
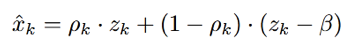
抵消掉正负项,可得:
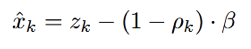
上式就是求消噪后的语音的对数谱的每维向量的数学表达式。zk可根据带噪语音求得,β要tuning,知道ρk后xk的估计就可得到了。对得到的每维向量做反变换,可得到消噪后的时域的值。
上文已给出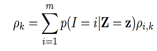 ,其中p(I = i | Z = z)表示在Z已知下是每个音素可能的概率,或者说一帧带噪语音是每个音素的可能的概率,用pi表示。pi可以通过全概率公式求出,即
,其中p(I = i | Z = z)表示在Z已知下是每个音素可能的概率,或者说一帧带噪语音是每个音素的可能的概率,用pi表示。pi可以通过全概率公式求出,即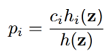 。但对每种语言来说,总的音素的个数是已知的(比如英语中有39个音素),这样求每帧是某个音素的概率是一个典型的分类问题。神经网络(NN)处理分类问题是优于传统方法的,所以可以用NN来训练一个模型,处理时用这个模型来计算每帧属于各个音素的概率,即算出pi,再和ρi,k做乘累加(ρi,k用基于MOG模型的方法求出),就可得到ρk了(
。但对每种语言来说,总的音素的个数是已知的(比如英语中有39个音素),这样求每帧是某个音素的概率是一个典型的分类问题。神经网络(NN)处理分类问题是优于传统方法的,所以可以用NN来训练一个模型,处理时用这个模型来计算每帧属于各个音素的概率,即算出pi,再和ρi,k做乘累加(ρi,k用基于MOG模型的方法求出),就可得到ρk了(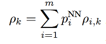 )。有了ρk,xk的估计就可求出了。可以看出NN模型的作用是替换计算pi的传统方法,使计算pi更准确。
)。有了ρk,xk的估计就可求出了。可以看出NN模型的作用是替换计算pi的传统方法,使计算pi更准确。
干净语音的高斯模型并不是用常规的EM算法训练得到的,而是基于一个已做好音素标注的语料库得到的,论文作者用的是TIMIT库。每帧跟一个音素一一对应,把属于一个音素的所有帧归为一类,算对数谱的各个向量的值,最后求均值和方差,得到这个向量的密度函数表达式,均值和方差的计算如下式:
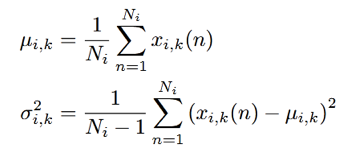
其中Ni表示属于某一音素的帧的个数。一个音素的所有向量的密度表达式相乘,就得到了这个音素的密度函数表达式。再通过属于这个音素的帧数占所有帧数的比例得到权重
(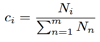 ), 这样干净语音的高斯模型就建立好了。
), 这样干净语音的高斯模型就建立好了。
对于非稳态噪声来说,噪声参数(μY,k和δY,k)最好能自适应。噪声参数的初始值可以通过每句话的前250毫秒求得(基于前250毫秒都是噪声的假设),求法同上面的干净语音的高斯模型,数学表达式如下:

噪声参数的更新基于以下算式:

其中α为平滑系数,0 < α < 1,也需要tuning。噪声参数(μY,k和δY,k)更新了,Gk(y)和gk(yk)就更新了,hi,k(z)也就更新了,从而ρi,k也更新了。
综上, 基于生成-判别混合模型的降噪算法如下:
1) 训练阶段
输入:
根据已标注好音素的语料库,得到对数谱向量z1,…zn(用于算MOG),MFCC向量v1,…,vn(用于NN训练)和每帧相对应的音素标签i1,…,in。
MoG 模型训练:
根据对数谱向量z1,…,zn算干净语音的MOG
NN模型训练:
根据(v1,i1),…(vn,…,in)训练一个基于音素的多分类模型
2) 推理阶段
输入:
带噪语音的对数谱向量以及MFCC向量
输出:
消噪后的语音
计算步骤:

语音降噪论文“A Hybrid Approach for Speech Enhancement Using MoG Model and Neural Network Phoneme Classifier”的研读的更多相关文章
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- 论文笔记:(2019)GAPNet: Graph Attention based Point Neural Network for Exploiting Local Feature of Point Cloud
目录 摘要 一.引言 二.相关工作 基于体素网格的特征学习 直接从非结构化点云中学习特征 从多视图模型中学习特征 几何深度学习的学习特征 三.GAPNet架构 3.1 GAPLayer 局部结构表示 ...
- Speech Enhancement via Deep Spectrum Image Translation Network
文中提出了一种深度网络来解决单通道语音增强问题. 链接:https://arxiv.org/abs/1911.01902 简介 因为背景噪声和混响的存在,录音通常会被扭曲,会对后端的语音识别等技术产生 ...
- VoIP语音处理流程和知识点梳理
做音频软件开发10+年,包括语音通信.语音识别.音乐播放等,大部分时间在做语音通信.做语音通信中又大部分时间在做VoIP语音处理.语音通信是全双工的,既要把自己的语音发送出去让对方听到,又要接收对方的 ...
- 论文翻译:2020_A Recursive Network with Dynamic Attention for Monaural Speech Enhancement
论文地址:基于动态注意的递归网络单耳语音增强 论文代码:https://github.com/Andong-Li-speech/DARCN 引用格式:Li, A., Zheng, C., Fan, C ...
- 论文翻译:2022_PACDNN: A phase-aware composite deep neural network for speech enhancement
论文地址:PACDNN:一种用于语音增强的相位感知复合深度神经网络 引用格式:Hasannezhad M,Yu H,Zhu W P,et al. PACDNN: A phase-aware compo ...
- 论文翻译:Fullsubnet: A Full-Band And Sub-Band Fusion Model For Real-Time Single-Channel Speech Enhancement
论文作者:Xiang Hao, Xiangdong Su, Radu Horaud, and Xiaofei Li 翻译作者:凌逆战 论文地址:Fullsubnet:实时单通道语音增强的全频带和子频带 ...
- 论文翻译:2020_WaveCRN: An efficient convolutional recurrent neural network for end-to-end speech enhancement
论文地址:用于端到端语音增强的卷积递归神经网络 论文代码:https://github.com/aleXiehta/WaveCRN 引用格式:Hsieh T A, Wang H M, Lu X, et ...
- 论文翻译:2019_Deep Neural Network Based Regression Approach for A coustic Echo Cancellation
论文地址:https://dl.acm.org/doi/abs/10.1145/3330393.3330399 基于深度神经网络的回声消除回归方法 摘要 声学回声消除器(AEC)的目的是消除近端传声器 ...
随机推荐
- Prometheus时序数据库-数据的查询
Prometheus时序数据库-数据的查询 前言 在之前的博客里,笔者详细阐述了Prometheus数据的插入过程.但我们最常见的打交道的是数据的查询.Prometheus提供了强大的Promql来满 ...
- linux软件deb打包及开机管理员自启动
环境:Ubuntu 18.04/16.04 Qt:5.12.6 一 deb打包 1.建立目录结构 2.目录内容 1) 子目录DC520: Get以上内容步骤: (1) 创建目录DC520(自己软 ...
- 面向对象进阶时,if语句写错位置
这周blog我也不知道要写什么,因为这章我其实学得有点懵,前面那几天我纠结了好久代码,一直不知道原因错在哪里.后来经过询问老师才知道自己调用错了构造方法,相信也有跟我一样的新手会犯这个错误.我在创建关 ...
- 攻防世界 reverse 进阶 easyre-153
easyre-153 查壳: upx壳 脱壳: 1 int __cdecl main(int argc, const char **argv, const char **envp) 2 { 3 int ...
- Java进阶专题(二十七) 将近2万字的Dubbo原理解析,彻底搞懂dubbo (下)
...接上文 服务发现 服务发现流程 整体duubo的服务消费原理 Dubbo 框架做服务消费也分为两大部分 , 第一步通过持有远程服务实例生成Invoker,这个Invoker 在客户端是核心的远程 ...
- Python数据分析入门(一):搭建环境
Python版本: 本课程用到的Python版本都是3.x.要有一定的Python基础,知道列表.字符串.函数等的用法. Anaconda: Anaconda(水蟒)是一个捆绑了Python.cond ...
- Java例题_38 自定义函数求字符串长度
1 /*38 [程序 38 求字符串长度] 2 题目:写一个函数,求一个字符串的长度,在 main 函数中输入字符串,并输出其长度. 3 */ 4 5 /*分析 6 * 1.从键盘得到一个字符串 7 ...
- 计算机体系结构——CH5 标量处理机
计算机体系结构--CH5 标量处理机 右键点击查看图像,查看清晰图像 X-mind 计算机体系结构--CH5 标量处理机 先行控制技术 指令得重叠执行方式 顺序执行方式 一次重叠执行方式 二次重叠技术 ...
- 没想到吧,Java开发 API接口可以不用写 Controller了
本文案例收录在 https://github.com/chengxy-nds/Springboot-Notebook 大家好,我是小富~ 今天介绍我正在用的一款高效敏捷开发工具magic-api,顺便 ...
- java面试-生产环境服务器变慢,谈谈你的诊断思路
1.uptime:查询linux系统负载 11:16:16 系统当前时间 up 64 days, 19:23 从上次启动开始系统运行的时间3 users 连接数量,同一用户多个连接的时候算多个load ...