老Python带你从浅入深探究Tuple
元组
Python中的元组容器序列(tuple)与列表容器序列(list)具有极大的相似之处,因此也常被称为不可变的列表。
但是两者之间也有很多的差距,元组侧重于数据的展示,而列表侧重于数据的存储与操作。
它们非常相似,虽然都可以存储任意类型的数据,但是一个元组定义好之后就不能够再进行修改。
元组特性
元组的特点:
- 元组属于容器序列
- 元组属于不可变类型
- 元组底层由顺序存储组成,而顺序存储是线性结构的一种
基本声明
以下是使用类实例化的形式进行对象声明:
tup = tuple((1, 2, 3, 4, 5))
print("值:%r,类型:%r" % (tup, type(tup)))
# 值:(1, 2, 3, 4, 5),类型:<class 'tuple'>
也可以选择使用更方便的字面量形式进行对象声明,使用逗号对数据项之间进行分割:
tup = 1, 2, 3, 4, 5
print("值:%r,类型:%r" % (tup, type(tup)))
# 值:(1, 2, 3, 4, 5),类型:<class 'tuple'>
为了美观,我们一般会在两侧加上(),但是要确定一点,元组定义是逗号分隔的数据项,而并非是()包裹的数据项:
tup = (1, 2, 3, 4, 5)
print("值:%r,类型:%r" % (tup, type(tup)))
# 值:(1, 2, 3, 4, 5),类型:<class 'tuple'>
多维元组
当一个元组中嵌套另一个元组,该元组就可以称为多维元组。
如下,定义一个2维元组:
tup = (1, 2, ("三", "四"))
print("值:%r,类型:%r" % (tup, type(tup)))
# 值:(1, 2, ('三', '四')),类型:<class 'tuple'>
续行操作
在Python中,元组中的数据项如果过多,可能会导致整个元组太长,太长的元组是不符合PEP8规范的。
- 每行最大的字符数不可超过79,文档字符或者注释每行不可超过72
Python虽然提供了续行符\,但是在元组中可以忽略续行符,如下所示:
tup = (
1,
2,
3,
4,
5
)
print("值:%r,类型:%r" % (tup, type(tup)))
# 值:(1, 2, 3, 4, 5),类型:<class 'tuple'>
类型转换
元组支持与布尔型、字符串、列表、以及集合类型进行类型转换:
tup = (1, 2, 3)
bTup = bool(tup) # 布尔类型
strTup = str(tup) # 字符串类型
liTup = list(tup) # 列表类型
setTup = set(tup) # 集合类型
print("值:%r,类型:%r" % (bTup, type(bTup)))
print("值:%r,类型:%r" % (strTup, type(strTup)))
print("值:%r,类型:%r" % (liTup, type(liTup)))
print("值:%r,类型:%r" % (setTup, type(setTup)))
# 值:True,类型:<class 'bool'>
# 值:'(1, 2, 3)',类型:<class 'str'>
# 值:[1, 2, 3],类型:<class 'list'>
# 值:{1, 2, 3},类型:<class 'set'>
如果一个2维元组遵循一定的规律,那么也可以将其转换为字典类型:
tup = (("k1", "v1"), ("k2", "v2"), ("k3", "v3"))
dictTuple = dict(tup)
print("值:%r,类型:%r" % (dictTuple, type(dictTuple)))
# 值:{'k1': 'v1', 'k2': 'v2', 'k3': 'v3'},类型:<class 'dict'>
索引操作
元组的索引操作仅支持获取数据项。
其他的任意索引操作均不被支持。
使用方法参照列表的索引切片一节。
绝对引用
元组拥有绝对引用的特性,无论是深拷贝还是浅拷贝,都不会获得其副本,而是直接对源对象进行引用。
但是列表没有绝对引用的特性,代码验证如下:
>>> import copy
>>> # 列表的深浅拷贝均创建新列表...
>>> oldLi = [1, 2, 3]
>>> id(oldLi)
4542649096
>>> li1 = copy.copy(oldLi)
>>> id(li1)
4542648840
>>> li2 = copy.deepcopy(oldLi)
>>> id(li2)
4542651208
>>> # 元组的深浅拷贝始终引用老元组
>>> oldTup = (1, 2, 3)
>>> id(oldTup)
4542652920
>>> tup1 = copy.copy(oldTup)
>>> id(tup1)
4542652920
>>> tup2 = copy.deepcopy(oldTup)
>>> id(tup2)
4542652920
Python为何要这样设计?其实仔细想想不难发现,元组不能对其进行操作,仅能获取数据项。
那么也就没有生成多个副本提供给开发人员操作的必要了,因为你修改不了元组,索性直接使用绝对引用策略。
值得注意的一点:[:]也是浅拷贝,故对元组来说属于绝对引用范畴。
元组的陷阱
Leonardo Rochael在2013年的Python巴西会议提出了一个非常具有思考意义的问题。
我们先来看一下:
>>> t = (1, 2, [30, 40])
>>> t[-1] += [50, 60]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
现在,t到底会发生下面4种情况中的哪一种?
- t 变成 (1, 2, [30, 40, 50, 60])。
- 因为 tuple 不支持对它的数据项赋值,所以会抛出 TypeError 异常。
- 以上两个都不是。
- a 和 b 都是对的。
正确答案是4,t确实会变成 (1, 2, [30, 40, 50, 60]),但同时元组是不可变类型故会引发TypeError异常的出现。
>>> t
(1, 2, [30, 40, 50, 60])
如果是使用extend()对t[-1]的列表进行数据项的增加,则答案会变成1。
我当初在看了这个问题后,暗自告诉自己了2件事情:
list的数据项增加尽量不要使用+=,而应该使用append()或者extend()
Ps:我也不知道自己为什么会产生这样的想法,但这个想法确实伴随我很长时间,直至现在
tuple中不要存放可变类型的数据,如list、set、dict等..
元组更多的作用是展示数据,而不是操作数据。
举个例子,当用户根据某个操作获取到了众多数据项之后,你可以将这些数据项做出元组并返回。
用户对被返回的原对象只能看,不能修改,若想修改则必须创建新其他类型对象。
解构方法
元组的解构方法与列表使用相同。
使用方法参照列表的解构方法一节。
常用方法
方法一览
常用的list方法一览表:
| 方法名 | 返回值 | 描述 |
|---|---|---|
| count() | integer | 返回数据项在T中出现的次数 |
| index() | integer | 返回第一个数据项在T中出现位置的索引,若值不存在,则抛出ValueError |
基础公用函数:
| 函数名 | 返回值 | 描述 |
|---|---|---|
| len() | integer | 返回容器中的项目数 |
| enumerate() | iterator for index, value of iterable | 返回一个可迭代对象,其中以小元组的形式包裹数据项与正向索引的对应关系 |
| reversed() | ... | 详情参见函数章节 |
| sorted() | ... | 详情参见函数章节 |
获取长度
使用len()方法来获取元组的长度。
返回int类型的值。
tup = ("A", "B", "C", "D", "E", "F", "G")
print(len(tup))
# 7
Python在对内置的数据类型使用len()方法时,实际上是会直接的从PyVarObject结构体中获取ob_size属性,这是一种非常高效的策略。
PyVarObject是表示内存中长度可变的内置对象的C语言结构体。
直接读取这个值比调用一个方法要快很多。
统计次数
使用count()方法统计数据项在该元组中出现的次数。
返回int:
tup = ("A", "B", "C", "D", "E", "F", "G", "A")
aInTupCount = tup.count("A")
print(aInTupCount)
# 2
查找位置
使用index()方法找到数据项在当前元组中首次出现的位置索引值,如数据项不存在则抛出异常。
返回int。
tup = ("A", "B", "C", "D", "E", "F", "G", "A")
aInTupIndex = tup.index("A")
print(aInTupIndex)
# 0
底层探究
内存开辟
Python内部实现中,列表和元组还是有一定的差别的。
元组在创建对象申请内存的时候,内存空间大小便进行了固定,后续不可更改(如果是传入了一个可迭代对象,例如tupe(range(100)),这种情况会进行扩容与缩容,下面的章节将进行探讨研究)。
而列表在创建对象申请内存的时候,内存空间大小不是固定的,如果后续对其新增或删除数据项,列表会进行扩容或者缩容机制。
元组创建
空元组
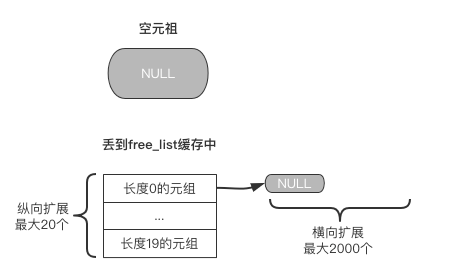
若创建一个空元组,会直接进行创建,然后将这个空元组丢到缓存free_list中。
元组的free_list最多能缓存 20 * 2000 个元组,这个在下面会进行讲解。
如图所示:
元组转元组
这样的代码会进行元组转元组:
tup = tuple((1, 2, 3))
首先内部本身就是一个元组(1, 2, 3),所以会直接将内部的这个元组拿出来并返回引用,并不会再次创建。
代码验证:
>>> oldTup = (1, 2, 3)
>>> id(oldTup)
4384908128
>>> newTup = tuple(oldTup)
>>> id(newTup)
4384908128
>>>
列表转元组
列表转元组会将列表中的每一个数据项都拿出来,然后放入至元组中:
tup = tuple([1, 2, 3])
所以你会发现,列表和元组中的数据项引用都是相同的:
>>> li1 = ["A", "B", "C"]
>>> tup = tuple(li1)
>>> print(id(li1[0]))
4383760656
>>> print(id(tup[0]))
4383760656
>>>
可迭代对象转元组
可迭代对象是没有长度这一概念的,如果是可迭代对象转换为元组,会先对可迭代对象的长度做一个猜想。
并且根据这个猜想,为元组开辟一片内存空间,用于存放可迭代对象的数据项。
然后内部会获取可迭代对象的迭代器,对其进行遍历操作,拿出数据项后放至元组中。
如果猜想的长度太小,会导致元组内部的内存不够存放下所有的迭代器数据项,此时该元组会进行内部的扩容机制,直至可迭代对象中的数据项全部被添加至元组中。
rangeObject = range(1, 101)
tup = tuple(rangeObject)
// 假如猜想的是9
// 第一步:+ 10
// 第二步:+ (原长度+10) * 0.25
// 其实,就是增加【原长度*0.25 + 2.5】
如果猜想的长度太大,而实际上迭代器中的数据量偏少,则需要对该元组进行缩容。
切片取值
对元组进行切片取值的时候,会开辟一个新元组用于存放切片后得到的数据项。
tup = (1, 2, 3)
newSliceTup = tup[0:2]
当然,如果是[:]的操作,则参照绝对引用,直接返回被切片的元组引用。
代码验证:
>>> id(tup)
4384908416
>>> newSliceTup = tup[0:2]
>>> id(newSliceTup)
4384904392
缓存机制
free_list缓存
元组的缓存机制和列表的缓存机制不同。
元组的free_list会缓存0 - 19长度的共20种元组,其中每一种长度的元组通过单向链表横向扩展缓存至2000个,如下图所示:
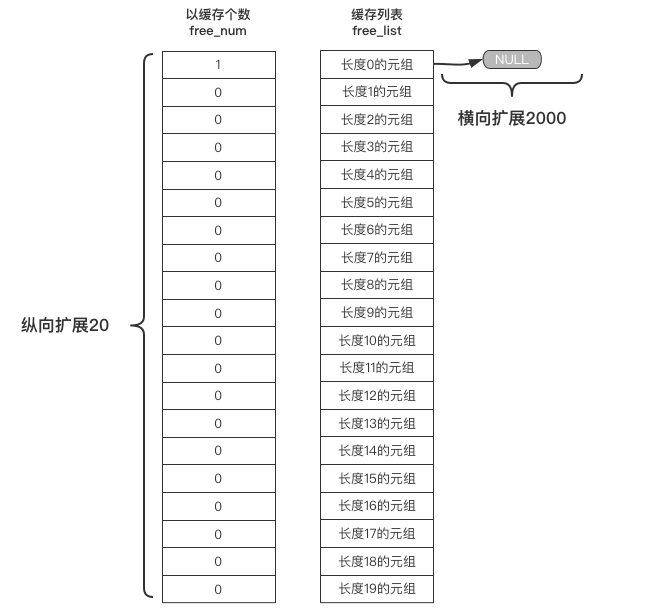
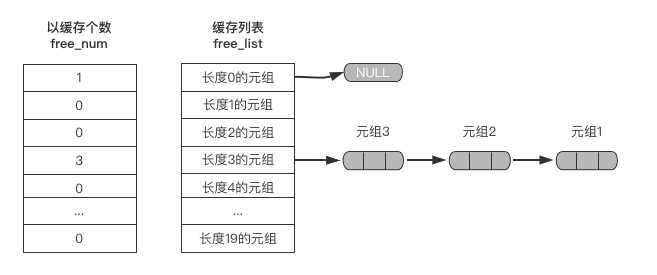
当每一次的del操作有数据项的元组时,都会将该元组数据项清空并挂载至free_list单向链表的头部的位置。
del 元组1
del 元组2
del 元组3
如下图所示:
当要创建一个元组时,会通过创建元组的长度,从free_list单向链表的头部取出一个元组,然后将数据项存放进去。
前提是free_list单向链表中缓存的有该长度的元组。
tup = (1, 2, 3)
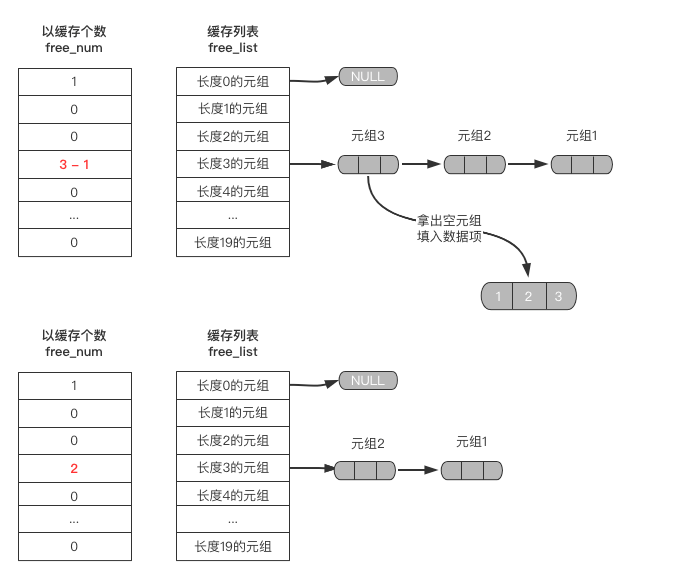
空元组与非空元组的缓存
空元组的缓存是一经创建就缓存到free_list单向链表中。
而非空元组的缓存必须是del操作后才缓存到free_list单向链表中。
空元组的创建
第一次创建空元组后,空元组会缓存至free_list单向链表中。
以后的每一次空元组创建,返回的其实都是同一个引用,也就是说空元组在free_list单向链表中即使被引用了也不会被销毁。
>>> t1 = ()
>>> id(t1)
4511088712
>>> t2 = ()
>>> id(t2)
4511088712
非空元组的创建
当free_list单向链表中有相同长度的元组时,会进行引用并删除。
这个在上图中已经示例过了,就是这个:
代码示例:
$ python3
Python 3.6.8 (v3.6.8:3c6b436a57, Dec 24 2018, 02:04:31)
[GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> v1 = (None, None, None)
>>> id(v1)
4384907696
>>> v2 = (None, None, None)
>>> id(v2)
4384908056
>>> del v1
>>> del v2 # ①
>>> v3 = (None, None, None)
>>> id(v3) # ②
4384908056
>>> v4 = (None, None, None)
>>> id(v4) # ③
4384907696
>>>
①:free_list num_free=3 单向链表结构:v2 —> v1
②:创建了v3,拿出v2的空元组,填入v3数据项,故v2和v3的id值相等,证明引用同一个元组,此时free_list num_free=3 单向链表结构为:—> v1
③:创建了v4,拿出v1的空元组,填入v4数据项,故v1和v4的id值相等,证明引用同一个元组
tupleobject.c源码
官网参考:点我跳转
源码一览:点我跳转
以下是截取了一些关键性源代码,并且做上了中文注释,方便查阅。
每一个元组都有几个关键性的属性:
Py_ssize_t ob_refcnt; // 引用计数器
Py_ssize_t ob_size; // 数据项个数,即元组大小
PyObject *ob_item[1]; // 存储元组中的数据项 [指针, ]
关于缓存free_list的属性:
PyTuple_MAXSAVESIZE // 相当于图中的 free_num ,最大20,即纵向扩展的缓存元组长度
PyTuple_MAXFREELIST // 图中 free_list 的横向扩展缓存列表个数,最大2000
创建元组
空元组
PyObject *
PyTuple_New(Py_ssize_t size)
{
PyTupleObject *op;
// 缓存相关
Py_ssize_t i;
// 元组的大小不能小于0
if (size < 0) {
PyErr_BadInternalCall();
return NULL;
}
#if PyTuple_MAXSAVESIZE > 0
// 创建空元组,优先从缓存中获取
// size = 0 表示这是一个空元组,从free_list[0]中获取空元组
if (size == 0 && free_list[0]) {
// op就是空元组
op = free_list[0];
// 新增空元组引用计数器 + 1
Py_INCREF(op);
#ifdef COUNT_ALLOCS
tuple_zero_allocs++;
#endif
// 返回空元组的指针
return (PyObject *) op;
}
// 如果创建的不是空元组,且这个创建的元组数据项个数小于20,并且free_list[size]不等于空,表示有缓存
// 则从缓存中去获取,不再重新开辟内存
if (size < PyTuple_MAXSAVESIZE && (op = free_list[size]) != NULL) {
// 拿出元组
free_list[size] = (PyTupleObject *) op->ob_item[0];
// num_free减1
numfree[size]--;
#ifdef COUNT_ALLOCS
fast_tuple_allocs++;
#endif
/* Inline PyObject_InitVar */
// 初始化,定义这个元组的长度为数据项个数
#ifdef Py_TRACE_REFS
Py_SIZE(op) = size;
// 定义类型为 tuple
Py_TYPE(op) = &PyTuple_Type;
#endif
// 增加一次新的引用
_Py_NewReference((PyObject *)op);
}
// 如果是空元组
else
#endif
{
// 检查内存情况,是否充足
/* Check for overflow */
if ((size_t)size > ((size_t)PY_SSIZE_T_MAX - sizeof(PyTupleObject) -
sizeof(PyObject *)) / sizeof(PyObject *)) {
return PyErr_NoMemory();
}
// 开辟内存,并获得一个元组:op
op = PyObject_GC_NewVar(PyTupleObject, &PyTuple_Type, size);
if (op == NULL)
return NULL;
}
// 空元组的每一个槽位都是NULL
for (i=0; i < size; i++)
op->ob_item[i] = NULL;
#if PyTuple_MAXSAVESIZE > 0
// 缓存空元组
if (size == 0) {
free_list[0] = op;
++numfree[0];
Py_INCREF(op); /* extra INCREF so that this is never freed */
}
#endif
#ifdef SHOW_TRACK_COUNT
count_tracked++;
#endif
// 将元组加入到GC机制中,用于内存管理
_PyObject_GC_TRACK(op);
return (PyObject *) op;
}
可迭代对象转元组
这个不在tupleobject.c源码中,而是在abstract.c源码中。
官网参考:点我跳转
源码一览:点我跳转
PyObject *
PySequence_Tuple(PyObject *v)
{
PyObject *it; /* iter(v) */
Py_ssize_t n; /* guess for result tuple size */
PyObject *result = NULL;
Py_ssize_t j;
if (v == NULL) {
return null_error();
}
/* Special-case the common tuple and list cases, for efficiency. */
// 如果是元组转换元组,如 tup = (1, 2, 3) 或者 tup = ((1, 2, 3))直接返回内存地址
if (PyTuple_CheckExact(v)) {
Py_INCREF(v);
return v;
}
// 如果是列表转换元组,则执行PyList_AsTuple(),将列表转换为元组
// 如 tup = ([1, 2, 3])
if (PyList_CheckExact(v))
return PyList_AsTuple(v);
/* Get iterator. */
// 获取迭代器, tup = (range(1, 4).__iter__())
it = PyObject_GetIter(v);
if (it == NULL)
return NULL;
/* Guess result size and allocate space. */
// 猜想迭代器长度,也就是猜一下有多少个数据项
n = PyObject_LengthHint(v, 10);
if (n == -1)
goto Fail;
// 根据猜想的迭代器长度,进行元组的内存开辟
result = PyTuple_New(n);
if (result == NULL)
goto Fail;
/* Fill the tuple. */
// 将迭代器中每个数据项添加至元组中
for (j = 0; ; ++j) {
PyObject *item = PyIter_Next(it);
if (item == NULL) {
if (PyErr_Occurred())
goto Fail;
break;
}
//如果迭代器中数据项比猜想的多,则证明开辟内存不足需要需要进行扩容
if (j >= n) {
size_t newn = (size_t)n;
/* The over-allocation strategy can grow a bit faster
than for lists because unlike lists the
over-allocation isn't permanent -- we reclaim
the excess before the end of this routine.
So, grow by ten and then add 25%.
*/
// 假如猜想的是9
// 第一步:+ 10
// 第二步:+ (原长度+10) * 0.25
// 其实,就是增加【原长度*0.25 + 2.5】
newn += 10u;
newn += newn >> 2;
// 判断是否超过了元组的数据项个数限制(sys.maxsize)
if (newn > PY_SSIZE_T_MAX) {
/* Check for overflow */
PyErr_NoMemory();
Py_DECREF(item);
goto Fail;
}
n = (Py_ssize_t)newn;
// 扩容机制
if (_PyTuple_Resize(&result, n) != 0) {
Py_DECREF(item);
goto Fail;
}
}
// 将数据项放入元组之中
PyTuple_SET_ITEM(result, j, item);
}
/* Cut tuple back if guess was too large. */
// 如果猜想的数据项太多,而实际上迭代器中的数据量偏少
// 则需要对该元组进行缩容
if (j < n &&
_PyTuple_Resize(&result, j) != 0)
goto Fail;
Py_DECREF(it);
return result;
Fail:
Py_XDECREF(result);
Py_DECREF(it);
return NULL;
}
列表转元组
这个不在tupleobject.c源码中,而是在listobject.c源码中。
官网参考:点我跳转
源码一览:点我跳转
PyObject *
PyList_AsTuple(PyObject *v)
{
PyObject *w;
PyObject **p, **q;
Py_ssize_t n;
// 例如:tup = ([1, 2, 3])
// 进行列表的验证
if (v == NULL || !PyList_Check(v)) {
PyErr_BadInternalCall();
return NULL;
}
// 获取大小,即数据项个数
n = Py_SIZE(v);
// 开辟内存
w = PyTuple_New(n);
// 如果是空元组
if (w == NULL)
return NULL;
// 执行迁徙操作
p = ((PyTupleObject *)w)->ob_item;
q = ((PyListObject *)v)->ob_item;
// 将列表中数据项的引用,也给元组进行引用
// 这样列表中数据项和元组中的数据项都引用同1个对象
while (--n >= 0) {
// 数据项引用计数 + 1
Py_INCREF(*q);
*p = *q;
p++;
q++;
}
// 返回元组
return w;
}
切片取值
PyObject *
PyTuple_GetSlice(PyObject *op, Py_ssize_t i, Py_ssize_t j)
// 切片会触发该方法
{
// 如果对空元组进行切片,则会抛出异常
if (op == NULL || !PyTuple_Check(op)) {
PyErr_BadInternalCall();
return NULL;
}
// 内部的具体实现方法
return tupleslice((PyTupleObject *)op, i, j);
}
static PyObject *
tupleslice(PyTupleObject *a, Py_ssize_t ilow,
Py_ssize_t ihigh)
{
PyTupleObject *np;
PyObject **src, **dest;
Py_ssize_t i;
Py_ssize_t len;
// 计算索引位置
if (ilow < 0)
ilow = 0;
if (ihigh > Py_SIZE(a))
ihigh = Py_SIZE(a);
if (ihigh < ilow)
ihigh = ilow;
// 如果是[:]的操作,则直接返回源元组对象a的指针,即绝对引用
if (ilow == 0 && ihigh == Py_SIZE(a) && PyTuple_CheckExact(a)) {
Py_INCREF(a);
return (PyObject *)a;
}
// 初始化新的切片对象元组长度
len = ihigh - ilow;
// 开始切片,创建了一个新元组np
np = (PyTupleObject *)PyTuple_New(len);
if (np == NULL)
return NULL;
src = a->ob_item + ilow;
dest = np->ob_item;
// 对源元组中的数据项的引用计数+1
for (i = 0; i < len; i++) {
PyObject *v = src[i];
Py_INCREF(v);
dest[i] = v;
}
// 返回切片对象新元组np的引用
return (PyObject *)np;
}
缓存相关
static void
tupledealloc(PyTupleObject *op)
{
Py_ssize_t i;
Py_ssize_t len = Py_SIZE(op);
PyObject_GC_UnTrack(op);
Py_TRASHCAN_SAFE_BEGIN(op)
// 如果元组的长度大于0,则不是一个非空元组
if (len > 0) {
i = len;
// 将内部的数据项引用计数都 - 1
while (--i >= 0)
Py_XDECREF(op->ob_item[i]);
#if PyTuple_MAXSAVESIZE > 0
// 准备缓存,判断num_free是否小于20,并且单向链表中的已缓存元组个数小于2000
if (len < PyTuple_MAXSAVESIZE &&
numfree[len] < PyTuple_MAXFREELIST &&
Py_TYPE(op) == &PyTuple_Type)
{
// 添加至链表头部
op->ob_item[0] = (PyObject *) free_list[len];
// 将num_free + 1
numfree[len]++;
free_list[len] = op;
goto done; /* return */
}
#endif
}
// 内存中进行销毁
Py_TYPE(op)->tp_free((PyObject *)op);
done:
Py_TRASHCAN_SAFE_END(op)
}
老Python带你从浅入深探究Tuple的更多相关文章
- 老Python带你从浅入深探究List
列表 Python中的列表(list)是最常用的数据类型之一. Python中的列表可以存储任意类型的数据,这与其他语言中的数组(array)不同. 被存入列表中的内容可称之为元素(element)或 ...
- 浅入深出Vue:第一个页面
今天正式开始入门篇,也就是实战了~ 首先我们是要做一个博客网站,UI 框架采用江湖传闻中的 ElementUI,今天我们就来利用它确定我们博客网站的基本布局吧. 准备工作 新建一个vue项目(可以参考 ...
- Mybatis源码解析,一步一步从浅入深(二):按步骤解析源码
在文章:Mybatis源码解析,一步一步从浅入深(一):创建准备工程,中我们为了解析mybatis源码创建了一个mybatis的简单工程(源码已上传github,链接在文章末尾),并实现了一个查询功能 ...
- Mybatis源码解析,一步一步从浅入深(六):映射代理类的获取
在文章:Mybatis源码解析,一步一步从浅入深(二):按步骤解析源码中我们提到了两个问题: 1,为什么在以前的代码流程中从来没有addMapper,而这里却有getMapper? 2,UserDao ...
- 浅入深出之Java集合框架(上)
Java中的集合框架(上) 由于Java中的集合框架的内容比较多,在这里分为三个部分介绍Java的集合框架,内容是从浅到深,如果已经有java基础的小伙伴可以直接跳到<浅入深出之Java集合框架 ...
- 浅入深出之Java集合框架(中)
Java中的集合框架(中) 由于Java中的集合框架的内容比较多,在这里分为三个部分介绍Java的集合框架,内容是从浅到深,如果已经有java基础的小伙伴可以直接跳到<浅入深出之Java集合框架 ...
- 浅入深出之Java集合框架(下)
Java中的集合框架(下) 由于Java中的集合框架的内容比较多,在这里分为三个部分介绍Java的集合框架,内容是从浅到深,哈哈这篇其实也还是基础,惊不惊喜意不意外 ̄▽ ̄ 写文真的好累,懒得写了.. ...
- 浅入深出Vue:环境搭建
浅入深出Vue:环境搭建 工欲善其事必先利其器,该搭建我们的环境了. 安装NPM 所有工具的下载地址都可以在导航篇中找到,这里我们下载的是最新版本的NodeJS Windows安装程序 下载下来后,直 ...
- 浅入深出Vue:工具准备之PostMan安装配置及Mock服务配置
浅入深出Vue之工具准备(二):PostMan安装配置 由于家中有事,文章没顾得上.在此说声抱歉,这是工具准备的最后一章. 接下来就是开始环境搭建了~尽情期待 工欲善其事必先利其器,让我们先做好准备工 ...
随机推荐
- idea自制模板代码快捷键
一:/** 方法描述 /*** 功能描述: * @param: $param$ * @return: $return$ * @auther: $user$ * @date: */二./c** 类描述 ...
- Maven安装本地依赖包
前提已安装maven并且配置了环境变量1.进入jar包所在的目录,打开cmd2.了解包的groupId.artifactId.version2.输入命令(依赖sdk为例)---maven命令mvn i ...
- 8、MyBatis之使用注解开发
9.使用注解开发 mybatis最初配置信息是基于 XML ,映射语句(SQL)也是定义在 XML 中的.而到MyBatis 3提供了新的基于注解的配置.不幸的是,Java 注解的的表达力和灵活性十分 ...
- Activity类组成分析(一)Instrumentation
目录 前言 解剖 继承关系 重要成员 Instrumentation 总结 前言 要了解清楚StartActivity的过程,Activity对象实例的构造过程是重要组成部分:而要弄清楚Activit ...
- C# 8 - Nullable Reference Types 可空引用类型
在写C#代码的时候,你可能经常会遇到这个错误: 但如果想避免NullReferenceException的发生,确实需要做很多麻烦的工作. 可空引用类型 Null Reference Type 所以, ...
- 比Django官方实现更好的分页组件+Bootstrap整合
前言 Django全家桶自带的分页组件只能说能满足分页这个功能,但是没那么好用就是了 Django的分页效果 django-pure-pagination分页效果 使用方法 首先安装: pip ins ...
- Python数据分析入门(六):Pandas的函数应用
apply和applymap 1. 可直接使用NumPy的函数 示例代码: # Numpy ufunc 函数 df = pd.DataFrame(np.random.randn(5,4) - 1) p ...
- 【笔记】《Redis设计与实现》chapter19 事务
chapter19 事务 Redis通过MULTI.EXEC.WATCH等命令来实现事务功能 19.1 事务的实现 事务开始 redis> MULTI ok 通过切换客户端状态的flag属性的R ...
- 使用Leaflet创建地图模块
背景 最近需要为某单位开发地图展示系统,因此开始涉略和使用Leaflet这个轻量级地图库. 创建基础地图需要以下几步 引入相关js和css文件,创建基础地图 <div id="map& ...
- 本地+分布式Hadoop完整搭建过程
1 概述 Hadoop在大数据技术体系中极为重要,被誉为是改变世界的7个Java项目之一(剩下6个是Junit.Eclipse.Spring.Solr.HudsonAndJenkins.Android ...