大数据学习day15----第三阶段----scala03--------1.函数(“_”的使用, 函数和方法的区别)2. 数组和集合常用的方法(迭代器,并行集合) 3. 深度理解函数 4 练习(用java实现类似Scala函数式编程的功能(不能使用Lambda表达式))
1. 函数
函数就是一个非常灵活的运算逻辑,可以灵活的将函数传入方法中,前提是方法中接收的是类型一致的函数类型
函数式编程的好处:想要做什么就调用相应的方法(fliter、map、groupBy、sortBy),想要具体怎么做,就传入相应的函数
函数式编程的特点之一就是支持链式编程(不停的函数调用函数)
1.1 一种更加简洁的定义函数的方式(_)
以前的形式

简洁的形式

"_" 相当于一个占位符,将遍历出来的值赋给这个占位符
该占位符号出现两次,其会认为出现两个参数,由于此处就是一个参数,若用如下表达式求平方会报错

此时想求平方的话可以使用math包来达到目的
1.2 函数和方法区别
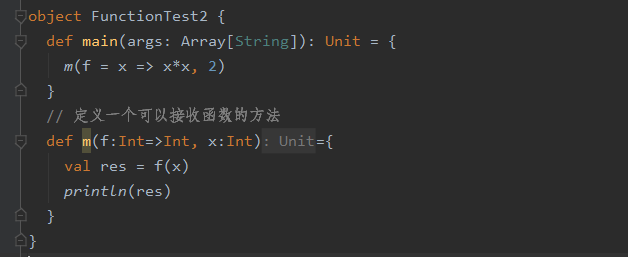
函数可以作为参数传入到方法中【函数本质是一个引用类型】,但是方法不能作为参数传入方法中
函数中也可以调用方法
下面的例子似乎能得到方法可以作为参数传入方法

m相当于m _的语法糖,m _会生成一个函数
问题1:为什么在方法中传入方法m可以执行相应的运算呢?
因为当传入一个方法名时,scala内部会将其转换成函数,实际传入的还是一个函数
问题2:m _这种语法到底是生成了一个跟m方法运算逻辑一样的函数,还是生成的函数调用了m方法呢
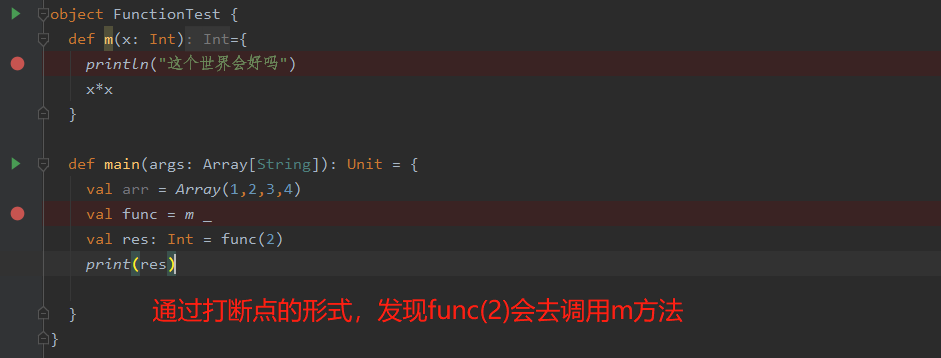
所以m _这种语法是生成了一个函数,这个生成的函数再调用了m方法
案例
2. 数组和集合常用的方法
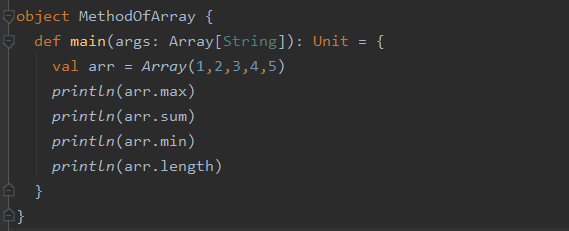
2.1 max(最大值),min(最小值),sum(求和),length(长度)
2.2 reduce、fold
- reduce
在Scala中,可以使用reduce这种二元操作对集合中的元素进行归约,reduce包含reduceLeft和reduceRight两种操作,前者从集合的头部开始操作,后者从集合的尾部开始操作
object MethodOfArray {
def main(args: Array[String]): Unit = {
val arr = Array(1,2,3)
println(arr.reduce(_+_)) // 6
println(arr.reduce(_-_)) // -4 此处说明reduce默认使用reduceLeft
println(arr.reduceLeft(_-_)) // -4
println(arr.reduceRight(_-_)) // 2
println(arr.reduce(_*_)) //6
}
}
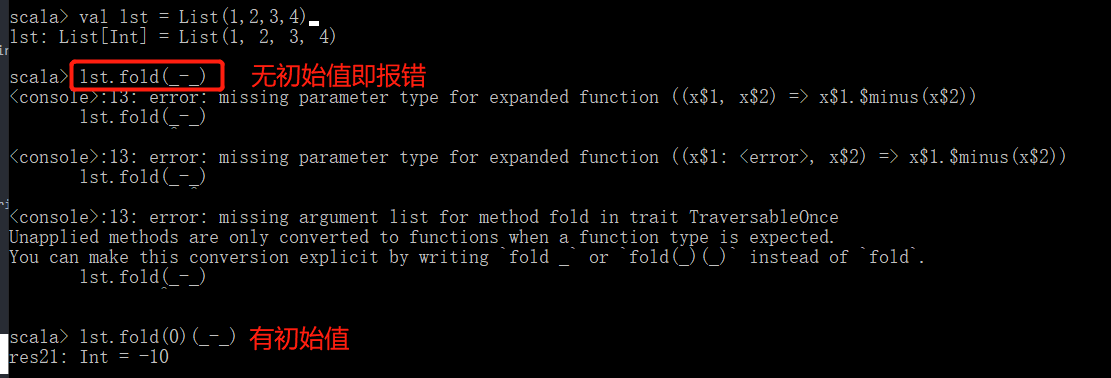
- fold
fold类似reduce,但其一定要从一个初始值开始,并以该值作为上下文,处理集合中的每个元素
2.3 sortBy:排序,默认是升序

以下只是改变比较的规则(将数据以字符串的形式比较),并不是改变数据,所以结果还是Int

若想实现降序,可如下
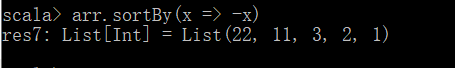
补充:迭代器
迭代器不存储数据,其只是一个帮助拿数据的工具
2.4 求并集

此处因为是List,所以可以有重复,若是改变成Set,这求并集后将不会有重复的元素
2.5 聚合:Aggregate
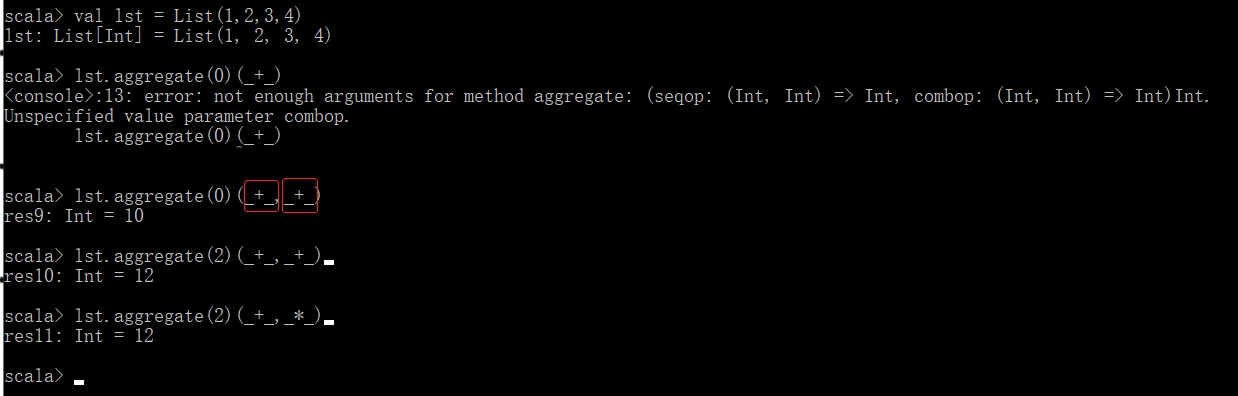
右边的参数用不到,不写会报错,源码如下

2.6 交集和差集
- 交集
val r2 = l1.intersect(l2)
- 差集:去掉相同的元素
val r3 = l1.diff(l2)
2.7 并行化集合(arr.par)


即9个线程运行此任务(得到的值具有随机性)
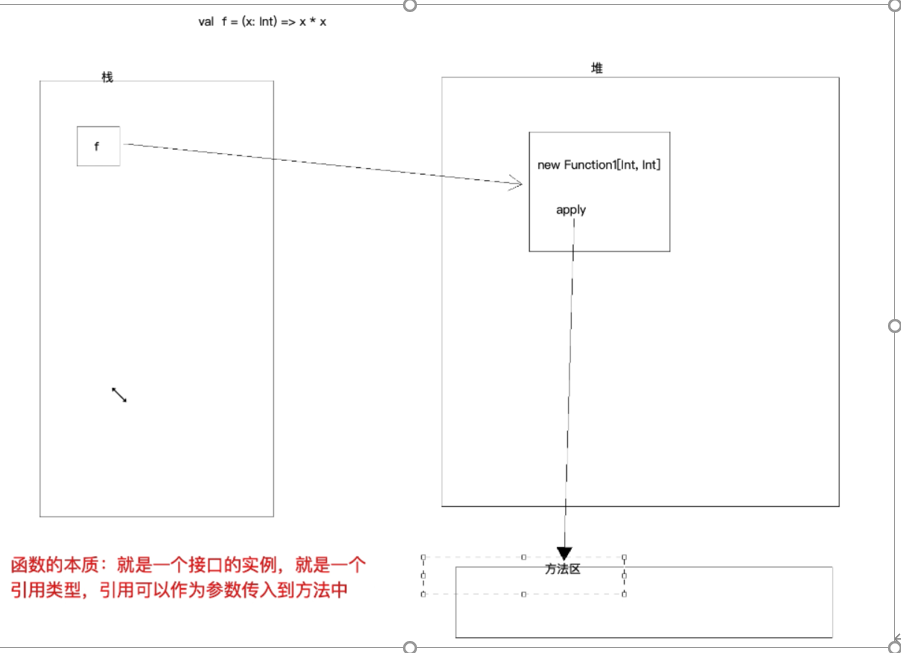
3. 深度理解函数
函数本质是一个接口的实例,是一个引用类型,引用可以作为参数传入到方法中
(1) 以前定义函数的完整形式
val f1:(Int,Double) => Double = (x: Int, y: Double) => (x + y)
(2)但其对应的真正写法应该如下
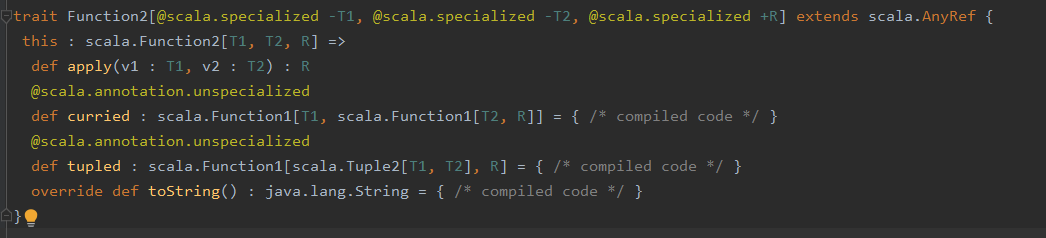
val f2:Function2[Int, Double, Double] = (x: Int, y: Double) => (x + y) //function2表示函数的输入参数的个数为2
补充: 在scala语言中,函数也是对象,每一个对象都是scala.FunctionN(1-22)1的实例,其中N是函数参数的数量

当点击蓝色字时,发现波浪线处会变成(1)中相应位置处的形式,所以说,(1)中的写法较2中用了语法糖
(3)更加准确的函数定义应该如下(波浪线处提示用语法糖)

点进Function2,可知其为一个特质(接口),此处相当于定义了一个接口的实例,源码部分如下
图解定义一个函数内部的过程
4 练习

方法一:装饰的方式:
思路:将原始的List用一个新的List(MyList)包装起来,获得一个包装类,然后在这个包装类中定义map方法,从而实现想要的功能
MyList类
public class MyList {
private List<String> words;
public MyList(List<String> words) { // 定义有参构造方法
this.words = words;
}
public List<String> map(MapFunction func) {
//定义一个新的集合,装转换后的数据
List<String> nList = new ArrayList<>();
//循环老的List
for(String word: words) {
//应用外部传入的逻辑
String nWord = func.apply(word);
//将新的单词添加到新的List中
nList.add(nWord);
}
//返回新的List
return nList;
}
}
MyFunction类
public interface MapFunction {
//定义一个规范,输入一个String,返回一个String
public String apply(String word);
}
因为MyList对象调用的map方法中传入的是一个运算逻辑,不能写死,所以此处就创建一个接口,不同的逻辑就相当于不同的实现类(即重写的apply方法不一样)
class MyListTest {
public static void main(String[] args) {
List<String> words = Arrays.asList("Hadoop", "Spark", "Hbase", "Flink", "Hive");
MyList myList = new MyList(words);
// 实现后面拼接字符串
List<String> res1 = myList.map(new MapFunction() {
@Override
public String apply(String word) {
return word + 2.0;
}
});
// 实现List中的元素都变大写
List<String> res2 = myList.map(new MapFunction(){
@Override
public String apply(String word) {
return word.toUpperCase();
}
});
System.out.println(res1);
}
}
若是在java8中,可以使用Lambda写逻辑运算,如转换大写部分可以直接使用如下替换
List<String> nList = myList.map(w -> w.toUpperCase());
此时可以去看下scala中的map是怎么实现的,类比发现逻辑跟自己上面的写法是一样的
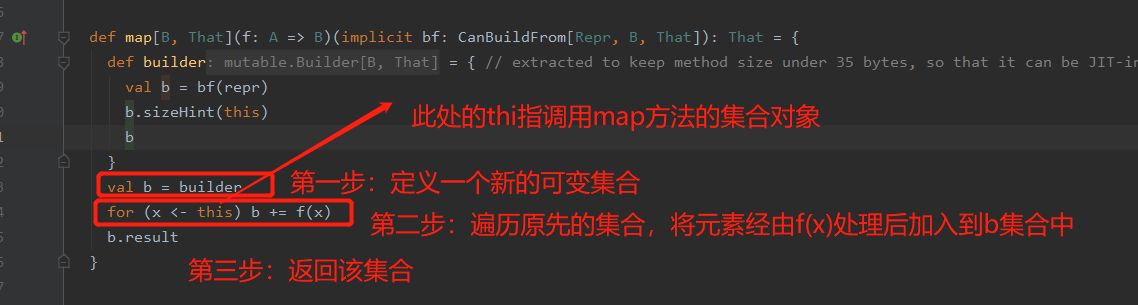
方法二:继承的方式
方法一的缺点:不能使用被包装集合中的方法(如add等),泛型写死,不支持链式编程(自己扩展的方法,)
此方法的优点:
- 具备ArrayList所有的功能
- 扩展了map、filter、reduce等方法
- 支持链式编程 (自己定义的map、fliter等方法返回值类型变为自己定义的集合)
- 支持传入多种数据类型:泛型
MyAdvList
说明:此集合为自己定义的集合,继承了ArrayList(这样就具备了ArrayList的所有功能),并实现了MyTraversableLike接口(scala中的集合,Set等也是实现了这个接口(TraversableLike)的),这样当别的集合想用该方法时,直接实现这个接口就行
public class MyAdvList<T> extends ArrayList<T> implements MyTraversableLike<T>{
@Override
public <R> MyAdvList<R> map(MyFunction1<T, R> func) {
// 创建一个新的集合,注意此处的返回值为自己定义的MyAdvList,这样才能支持自己写的方法的链式编程
MyAdvList<R> nList = new MyAdvList<>();
// 遍历老的集合(即调用该map方法的集合)
for(T t: this){
// 应用外部传入的逻辑
R res = func.apply(t);
// 将新的数据放入的刚创建的新的集合中去
nList.add(res);
}
return nList;
}
@Override
public MyAdvList<T> filter(MyFunction1<T, Boolean> func) {
MyAdvList<T> nList = new MyAdvList<>();
for(T t: this){
if(func.apply(t)){
nList.add(t);
}
}
return nList;
}
}
MyTraversableLike接口
import java.util.List; //MyTraversableLike<T>泛型类,以后T类型就可以在方法中使用了
public interface MyTraversableLike<T> { //泛型方法,在返回值的前面、void的前面<R> /**
* 做映射,传入一个运算逻辑,将数据进行处理,返回一个新的List
* @param func
* @param <R>
* @return
*/
<R> List<R> map(MyFunction1<T, R> func); /**
* 对原来集合的数据进行过滤,满足func的条的留下
* @param func
* @return
*/
List<T> filter(MyFunction1<T, Boolean> func); }
MyFunction1(传进map方法中的运算逻辑,相当于一个规范,此处接口可以达到这个目的)
public interface MyFunction1<T, R> {
/**
* 定义一个规范,属于一个T类型的参数,返回一个R
* T 和 R 可以是同一个类型
* @param r
* @return
*/
R apply(T r);
}
测试类
public class MyAdvListTest {
public static void main(String[] args) {
// MyAdvList<String> words = new MyAdvList<>();
// words.add("Hadoop");
// words.add("Spark");
// words.add("Flink");
// words.add("Hive");
// List<String> nList = words.map(new MyFunction1<String, String>() {
// @Override
// public String apply(String r) {
// return r.toUpperCase();
// }
// });
MyAdvList<Integer> num = new MyAdvList<>();
num.add(1);
num.add(2);
num.add(3);
num.add(4);
// List<Double> nList = num.map(new MyFunction1<Integer, Double>() {
// @Override
// public Double apply(Integer r) {
// return r * 10.0;
// }
// });
// 链式编程
List<Double> nList = num.map(r -> r * 3.0).filter(x -> x%2==0);
System.out.println(nList);
}
}
这样既可达到需求
补充:java8中Stream【流水线】的使用
public class StreamDemo {
public static void main(String[] args) {
List<Integer> num = Arrays.asList(1,2,4,5,6,7);
// 使用Java8的Stream【流水线】,集合中是没有filter等方法的
Optional<Integer> reduce = num.stream().filter(i -> i % 2 == 0).map(i -> i * i).reduce((a, b) -> a + b);
Integer integer = reduce.get();
System.out.println(integer);
}
}
public class StreamDemo {
public static void main(String[] args) {
Stream<Integer> integerStream = nums.stream().filter(i -> i % 2 == 0).map(i -> i * i);
// 以下是通过迭代器获取数据
// Iterator<Integer> iterator = integerStream.iterator();
//
// while (iterator.hasNext()) {
// Integer r = iterator.next();
// System.out.println(r);
// }
// java8新特性直接获取
//integerStream.forEach(i -> System.out.println(i));
integerStream.forEach(System.out::println);
}
}
大数据学习day15----第三阶段----scala03--------1.函数(“_”的使用, 函数和方法的区别)2. 数组和集合常用的方法(迭代器,并行集合) 3. 深度理解函数 4 练习(用java实现类似Scala函数式编程的功能(不能使用Lambda表达式))的更多相关文章
- 大数据学习day31------spark11-------1. Redis的安装和启动,2 redis客户端 3.Redis的数据类型 4. kafka(安装和常用命令)5.kafka java客户端
1. Redis Redis是目前一个非常优秀的key-value存储系统(内存的NoSQL数据库).和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list ...
- 大数据学习--day15(常用类:Date--DateFormat--SimpleDateFormat--File--包装类)
常用类:Date--DateFormat--SimpleDateFormat--File--包装类 这些常用类就不像字符串挖那么深了,只列列用法. 时间处理: /** * 时间处理类 * DateFo ...
- 大数据学习笔记——Java篇之集合框架(ArrayList)
Java集合框架学习笔记 1. Java集合框架中各接口或子类的继承以及实现关系图: 2. 数组和集合类的区别整理: 数组: 1. 长度是固定的 2. 既可以存放基本数据类型又可以存放引用数据类型 3 ...
- 大数据笔记(二十五)——Scala函数式编程
===================== Scala函数式编程 ======================== 一.Scala中的函数 (*) 函数是Scala中的头等公民,就和数字一样,可以在变 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 大数据学习路线,来qun里分享干货,
一.Linux lucene: 全文检索引擎的架构 solr: 基于lucene的全文搜索服务器,实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面. 推荐一个大数据学习群 ...
随机推荐
- buff/cache 占用过高解决方法
cache 读磁盘时,数据从磁盘读出后,暂留在缓冲区(cache),为后续程序的使用做准备 buffer 写磁盘时,先保存到磁盘缓冲区(buffer),然后再写入到磁盘 三条命令: #echo 1 & ...
- 使用jax加速Hamming Distance的计算
技术背景 一般认为Jax是谷歌为了取代TensorFlow而推出的一款全新的端到端可微的框架,但是Jax同时也集成了绝大部分的numpy函数,这就使得我们可以更加简便的从numpy的计算习惯中切换到G ...
- 攻防世界 WEB 高手进阶区 easytornado Writeup
攻防世界 WEB 高手进阶区 easytornado Writeup 题目介绍 题目考点 Python模板 tornado 模板注入 Writeup 进入题目, 目录遍历得到 /flag.txt /w ...
- docker容器命令(一)
容器命令 创建容器:docker run 参数: -it 交互 -d 后台 –name 容器名 -p 主机端口:容器端口 (主机端口映射到docker端口) docker run --name cen ...
- 你以为我在玩游戏?其实我在学 Java
大家好,我是程序员cxuan!今天和大家一起Look一下这个有趣的国外编程网站! 寓教于乐 "今天我们来学习 Java " . "Java 是一门面向对象的编程语言&qu ...
- 001.AD域控简介及使用
一 AD概述 1.1 AD简介 域(Domain)是Windows网络中独立运行的单位,域之间相互访问则需要建立信任关系. 当一个域与其他域建立了信任关系后,2个域之间不但可以按需要相互进行管理,还可 ...
- MySQL基础语句(修改)
①INSERT INSERT INTO students (class_id, name, gender, score) VALUES (2, '大牛', 'M', 80); 向students表插入 ...
- myeclipse自带tomcat
安装myeclipse自带的tomcat没有在myeclipse的安装目录下,是再myeclipse指定的工作空间下 的.metadata\.plugins\com.genuitec.eclipse. ...
- GoLang设计模式16 - 模板方法模式
模板方法设计模式是一种行为型设计模式.这种模式通过常用于为某种特定的操作定义一个模板或者算法模型. 以一次性密码(OTP:One Time Password)为例.我们常见的一次性密码有两种:短信密码 ...
- [hdu6991]Increasing Subsequence
令$f_{i}$表示以$i$为结尾的极长上升子序列个数,则有$f_{i}=\sum_{j<i,a_{j}<a_{i},\forall j<k<i,a_{k}\not\i ...