python爬取北京政府信件信息02
在爬取详细信息页面中,又遇到了问题,就是标签内的信息爬取,用re的正则表达式没有找到解决办法,只能又去网上搜索解决办法
用bs4来解决,用
- soup = BeautifulSoup(text,"html.parser")#解析text中的HTML
来进行分析,虽说这样会有标签信息附着,从网上找到解决办法,
第一种方法
调用find(text=True).strip()
第二种方法
调用stripped_strings
第三种方法
- .get_text().lstrip().rstrip()
个人感觉第三种很好用,在实践之后特意添加
经过测试,不是很理想,对于简单的,只有div标签的很容易,对于第一种,好多p标签的就不好用了,正在寻找更加实用的代码
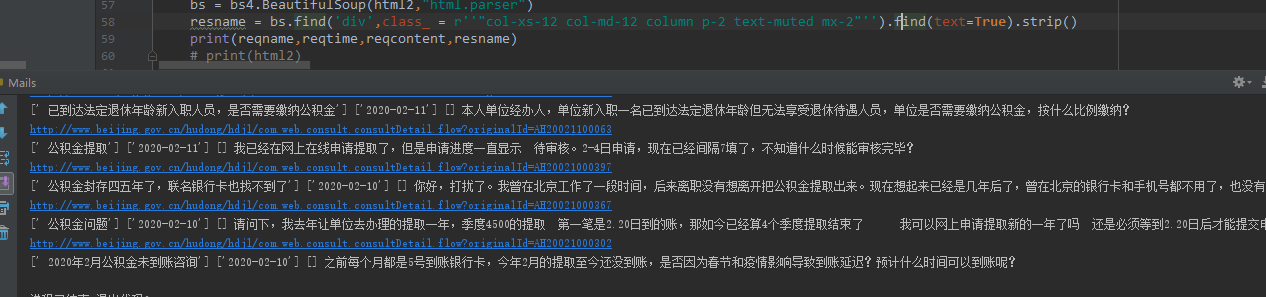
- for add in ad:
- r = add
- address_ = "http://www.beijing.gov.cn/hudong/hdjl/com.web.consult.consultDetail.flow?originalId=%s" % add
- print(address_)
- # 爬取子页面的网页
- html2 = requests.get(address_,headers = head2).text
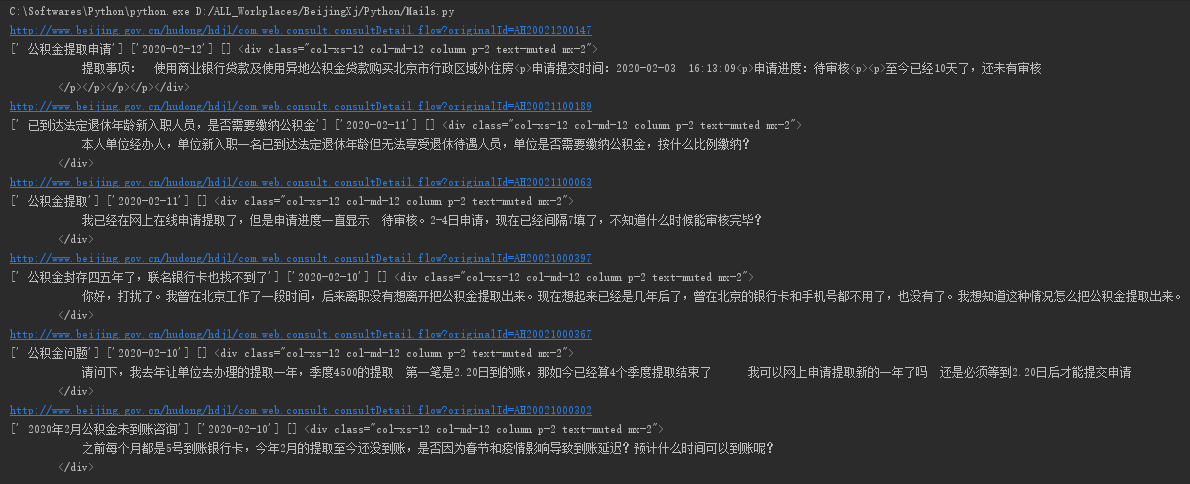
- reqname = re.findall(r'<div class="col-xs-10 col-sm-10 col-md-10 o-font4 my-2"><strong>(.*?)</strong></div>',html2)
- reqtime = re.findall(r'<div class="col-xs-5 col-lg-3 col-sm-3 col-md-3 text-muted ">时间:(.*?)</div>',html2)
- reqcontent = re.findall(r'<div class="col-xs-12 col-md-12 column p-2 text-muted mx-2">(.*?)</div>',html2)
- # resname = re.findall(r'<strong>[官方回答]:</strong>(.*?)</div>',html2)
- bs = bs4.BeautifulSoup(html2,"html.parser")
- resname = bs.find('div',class_ = r''"col-xs-12 col-md-12 column p-2 text-muted mx-2"'')
- print(reqname,reqtime,reqcontent,resname)
- # print(html2)
python爬取北京政府信件信息02的更多相关文章
- python爬取北京政府信件信息01
python爬取,找到目标地址,开始研究网页代码格式,于是就开始根据之前学的知识进行爬取,出师不利啊,一开始爬取就出现了个问题,这是之前是没有遇到过的,明明地址没问题,就是显示网页不存在,于是就在百度 ...
- 用Python爬取智联招聘信息做职业规划
上学期在实验室发表时写了一个爬取智联招牌信息的爬虫. 操作流程大致分为:信息爬取——数据结构化——存入数据库——所需技能等分词统计——数据可视化 1.数据爬取 job = "通信工程师&qu ...
- python爬取 “得到” App 电子书信息
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 静觅 崔庆才 PS:如有需要Python学习资料的小伙伴可以加点击下 ...
- Python爬取房天下二手房信息
一.相关知识 BeautifulSoup4使用 python将信息写入csv import csv with open("11.csv","w") as csv ...
- 这价格看得我偷偷摸了泪——用python爬取北京二手房数据
如果想了解更多关于python的应用,可以私信我,或者加群,里面到资料都是免费的 http://t.cn/A6Zvjdun 近期,有个朋友联系我,想统计一下北京二手房的相关的数据,而自己用Excel统 ...
- 【python】用python爬取中科院院士简介信息
018/07/09 23:43 项目名称:爬取中科院871个院士的简介信息 1.爬取目的:中科院871个院士的简介信息 2.爬取最终结果: 3.具体代码如下: import re # 不用安装(注意! ...
- Python 爬取赶集网租房信息
代码已久,有可能需要调整 #coding:utf-8 from bs4 import BeautifulSoup #有这个bs4不用正则也可以定位要爬取的内容了 from urlparse impor ...
- 利用python爬取贝壳网租房信息
最近准备换房子,在网站上寻找各种房源信息,看得眼花缭乱,于是想着能否将基本信息汇总起来便于查找,便用python将基本信息爬下来放到excel,这样一来就容易搜索了. 1. 利用lxml中的xpath ...
- python爬取实习僧招聘信息字体反爬
参考博客:http://www.cnblogs.com/eastonliu/p/9925652.html 实习僧招聘的网站采用了字体反爬,在页面上显示正常,查看源码关键信息乱码,如下图所示: 查看网页 ...
随机推荐
- .net core 使用阿里云分布式日志
前言 好久没有出来夸白了,今天教大家简单的使用阿里云分布式日志,来存储日志,没有阿里云账号的,可以免费注册一个 开通阿里云分布式日志(有一定的免费额度,个人测试学习完全没问题的,香) 阿里云日志地址: ...
- CUDA刷新器:CUDA编程模型
CUDA刷新器:CUDA编程模型 CUDA Refresher: The CUDA Programming Model CUDA,CUDA刷新器,并行编程 这是CUDA更新系列的第四篇文章,它的目标是 ...
- Contos8 安装 MariaDb 时报错:Could not open mysql.plugin table: table mysql.plugin
导语: 因个人服务器误删了一些文件导致MariaDB崩溃,一直在报错,所以想着重装一下,没想到在重装后启动时再次报错(与之前报错不同),这次的报错原因大致是因为某些插件表找不到. 因此又开启了漫长的寻 ...
- Spring Cloud09: Config 配置中心
一.概述 什么是配置中心呢,在基于微服务的分布式系统中,每个业务模块都可以拆分成独立自主的服务,由多个请求来协助完成某个需求,那么在某一具体的业务场景中,某一个请求需要调用多个服务来完成,那么就存在一 ...
- LeetCode:322. 零钱兑换
链接:https://leetcode-cn.com/problems/coin-change/ 标签:动态规划.完全背包问题.广度优先搜索 题目 给定不同面额的硬币 coins 和一个总金额 amo ...
- tar与NTP时间同步
tar备份与恢复 归档和压缩 : 1.方便对零散文件管理 2.减少空间的占用 常见的压缩格式及命令工具: gzip ----> .gz bzip2 ---->.bz2 xz ---- ...
- 聚类算法K-Means算法和Mean Shift算法介绍及实现
Question:什么是聚类算法 1.聚类算法是一种非监督学习算法 2.聚类是在没有给定划分类别的情况下,根据数据相似度进行样本分组的一种方法 3.理论上,相同的组的数据之间有相同的属性或者是特征,不 ...
- SpringMVC 进阶版
请求限制 一些情况下我们可能需要对请求进行限制,比如仅允许POST,GET等... RequestMapping注解中提供了多个参数用于添加请求的限制条件 value 请求地址 path 请求地址 m ...
- 【题解】Luogu P2889 [USACO07NOV]挤奶的时间Milking Time
Luogu P2889 [USACO07NOV]挤奶的时间Milking Time 题目描述 传送门Bessie is such a hard-working cow. In fact, she is ...
- 办公利器!用Python批量识别发票并录入到Excel表格
辰哥今天来分享一篇办公干货文章:用Python批量识别发票并录入到Excel表格.对于财务专业等学生或者公司财务人员来说,将报账发票等汇总到excel简直就是一个折磨. 尤其是到年底的时候,公司的财务 ...