ORB-SLAM3论文阅读:ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial and Multi-Map SLAM
简介
ORB-SLAM3是第一个能在单目、双目、RGBD鱼眼相机和针孔相机模型下运行视觉、视觉-惯导以及多地图SLAM的系统。其贡献主要包括两方面:提出了完全依赖于最大后验估计的紧耦合视觉-惯导SLAM系统,IMU初始化阶段也采用最大后验估计。可以在室内室外大小各种环境下运行,比其他算法快2-5倍。其次提出了多地图系统,DBoW2用于回环检测需要保证时间一致性,在验证几何一致性前需要匹配三个连续的关键帧到同一区域,虽然精度高,但是召回率低,因而回环检测过程太慢,之前的地图很难重复利用到。ORB-SLAM3采用了新的位置识别方法,先检测候补帧的几何一致性,再要求连续三帧局部一致性,虽然提高了一点计算代价,但是改进了召回率。可以长期在比较恶劣的环境下运行。丢失时会重新开启一个子地图,当重新回到原来的位置会与之前的地图合并,系统允许不连接的子图存在,这些子图可以用于位置识别、相机重定位、回环检测、地图合并。与视觉里程计只使用最新的几帧数据相比,ORB-SLAM3利用了所有之前的信息,这能够在BA关键帧时提供高的视察观测,提高精度。
最终双目在EuRoC上的精度为3.6cm,,在TUM-VI上达到了9mm的精度。
系统概述
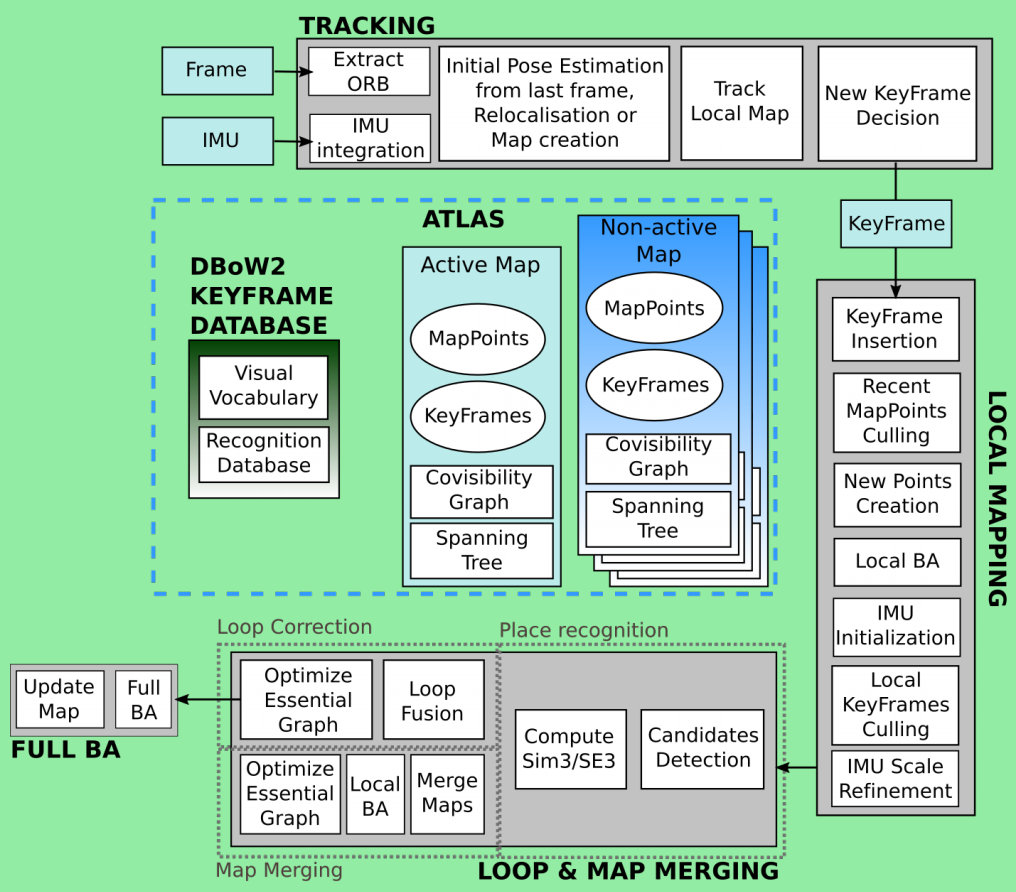
与之前的版本相比,多了IMU,回环检测里面多了子图融合,MAP变为了地图集ATLAS,主要包括动态地图和活动地图,前者指新的关键帧所在的图,系统为关键帧建立DBoW2数据库用于重定位、回环检测和地图合并。
追踪线程和之前的没有区别,主要是特征点估计位姿,多了IMU预积分,速度和bias估计,追踪丢失时,尝试在ATLAS图中重新定位当前帧。
局部地图线程向动态地图中增加关键帧和路标点,移除冗余信息,使用视觉或者视觉-惯导BA对地图中当前关键帧的局部窗口进行优化,IMU参数使用最大后验估计进行优化。
回环和地图合并线程检测动态地图和所有地图之间的重合区域,如果公共区域都在动态地图中,则执行回环纠正,否则将合并为一个地图,并且该地图设为动态地图。在回环纠正后执行一次全局BA优化。
关键技术
重定位
ORB-SLAM中使用ePnP算法,这里因为使用的算法要和相机模型无关,因此采用MLPnP算法,仅适用投影射线作为输入,相机仅需要提供一个重投影函数,将像素映射为投影射线即可。
非校正双目SLAM
许多双目SLAM系统假设双目图像都是已校正的,即两张图像都是使用针孔模型采用相同的焦距进行建模,使得图像平面是共面的,并与水平极线对齐,这样一幅图像中的特征可以很容易地通过查看另一幅图像中的同一行进行匹配。而双目图像已校正的假设是很严格的,如对于鱼眼相机则需要严重的图像裁剪,失去了大视野的优势。论文假设了左右相机之间存在一个常数SE(3)变换,并且两边能够观测到一个重合的区域。这使得估计地图的尺度很方便,因此SLAM系统估计一个六自由度的刚体姿态。只要左右目能看到重叠区域,则第一次看到时就能估计出准确的尺度,并对这些点进行三角化,剩余的信息可以作为单目信息。
视觉-惯导SLAM:相比较于ORB-SLAM-VI,前者只能用针孔相机,而且初始化太慢,本文采用基于IMU的初始化,更加迅速且准确。
理论基础
估计的状态量
位姿、世界坐标系的速度,重力和加速度偏差(公式1)。IMU在图像帧之间进行预积分,得到旋转、速度、位置变化,进而与估计量一起得到惯导测量的残差项(公式2)。除了惯导残差,还使用了第i帧和3D点之间的重投影误差(公式3)。已知惯导测量项和残差项,根据关键帧的状态和3D点可以得到优化问题的表达式(公式4)。使用了鲁棒huber核降低误匹配的影响,而对于惯导项的残差则不需要(不存在误匹配问题)。该优化问题需要有一个好的初始化,才能使得最终收敛的解较准确。
IMU初始化
为了获得较好的初始值:速度、重力方向、IMU偏差。基于以下事实:1.纯单目SLAM能提供准确的初始地图,但是尺度未知。2. 相比较于在BA中使用隐式表示,尺度如果准确表示为优化变量将会收敛得更快。3.忽视IMU初始化中传感器的不确定性会产生较大的不可预知误差。根据以上三点,将IMU初始化问题表示为最大后验估计,主要分为三步:
仅视觉的最大后验估计:初始化单目SLAM,跑2s,以4Hz插入关键帧,可以得到有10个位姿、上百个点的统一尺度的地图,优化也使用仅视觉BA。最终得到一些统一尺度的位姿。
仅惯导的最大后验估计:使用上一步得到的轨迹(位姿)和关键帧之间惯导测量估计状态量(公式5),包括:上一步中的尺度因子、重力方向、加速度计和陀螺仪偏差(初始化中假设为常量)、统一尺度下的速度,以上一步的位姿作为初始化(位姿固定)。优化函数见公式6-8。公式9和公式10分别为重力方向和尺度因子的更新方式。一旦仅惯导优完成后,位姿、速度、地图点都要用尺度因子更新,且与重力方向的z轴对齐。
视觉-惯导最大后验估计:当视觉和惯导参数都估计之后,使用联合估计继续优化解,对于所有的关键帧有同样的bias和先验信息。
以上的初始化方法比其他方法更准确,对于双目,则固定尺度因子为1,且不作为优化变量,相对来说简单一点。
追踪和地图
追踪采用视觉-惯导优化最新的两帧,固定地图点。对于建图,采用滑动窗口,维护关键帧和点( 固定共视关键帧)。当运动太小,惯导优化无法准确估计参数时,仅仅估计重力方向和尺度。此时bias为常数的假设不再成立,从每一帧估计出来的bias都校正后使用。使用以上方法直到地图中超过100个关键帧或者初始化过去了75秒。
追踪丢失
当少于15个点被追踪到时,认为丢失了:如果是短期丢失,则当前位姿通过IMU读取,地图通过在估计的相机位姿投影,在一个较大的窗口内进行匹配。如果超过了五秒,认为进入了长期丢失,此时一个新的视觉-惯导地图以第一步的方法建立,并成为动态地图。
地图合并以及回环检测
对于短期和中期运行的地图,数据处理是将地图点通过估计位姿投影。DBoW2的问题是准确率高但是召回率太低了。时间一致性要求连续三帧相似,带来的系统延时太频繁。本文提出了新算法:只要出现了新的关键帧,就和ATLAS中的任一帧进行匹配,如果匹配的关键帧也在动态地图中,则进行回环检测;如果匹配帧不在动态地图中,则进行合并成新的动态地图。本文的另一个创新点:当前关键帧和匹配地图估计之后,在匹配到的关键帧和其周围关键帧(共视图)中建立局部窗口,在该窗口中查找中距离的数据关联。改进了回环检测和地图合并的准确率。
位置识别
- 找与动态关键帧\(K_a\)最相似的三个关键帧\(K_m\)(三个关键帧不在\(K_a\)的共视图中)。
- 对于每个\(K_m\)定义一个局部窗口,包括\(K_m\)和他共视度最高的一些关键帧,对应观测的地图点。该窗口的关键帧理论上和\(K_a\)之间存在匹配关系,包括对应的2D特征和3D点。
- 使用RANSAC计算\(K_m\)中地图点和\(K_a\)中地图点的位姿变换\(T_{am}\), 地图未成熟(其实就是尺度不知道)使用Sim3,否则使用SE3。计算出位姿变换后进行重投影,如果每个3D点重投影误差在一定范围内则投一票,找到候选票数最多的\(T_{am}\)。
- \(T_{am}\)也要进一步优化,使用双向投影。Huber函数降低无匹配影响。如果优化后内点较多,则选择则一个更小的窗口,进行非线性优化。
- 找到与\(K_a\)共视点超过阈值的两个关键帧,找不到则等待新的关键帧,不需要使用词袋,直到三个关键帧能确定\(T_{am}\)或者连续两个新的关键帧都失败了。
- 在匹配的过程中还考虑了当前帧和候选帧的pitch和raw角 是否在阈值之内。
视觉地图合并
当前帧和非动态子地图帧匹配到后需要地图合并,合并后信息不能冗余,且保证合并速度较快:
- 联合窗口:包括\(K_a\)和其共视帧,\(K_m\)和其共视帧,以及对应的地图点。\(K_a\)对应的动态地图设为\(M_a\),\(K_m\)对应的地图为\(M_m\)。在构建联合窗口前,\(M_a\)中的帧和点都通过\(T_{ma}\)与\(M_m\)中进行对齐。
- 合并地图时,要移除冗余的点,在\(M_m\)关键帧中搜索\(M_a\)的点,\(M_a\)中的冗余点将会被移除,同时共视图和本征图都会被更新,即在\(M_a\)和\(M_m\)中的关键帧中加边。
- 联合窗口BA:BA对象为\(Ma\)和\(M_m\)中的帧。为了固定gauge freedom,与\(M_m\)公视的关键帧被固定,一旦优化完成,所有联合窗口内的关键帧可以立即用于追踪,地图可以快速准确利用。
- 位姿图优化:在本征图上对合并后的地图进行位姿优化,这里让联合窗口的关键帧固定住(上一步已经优化了),误差校正从联合窗口传递到该地图的剩余部分。
视觉-惯导地图合并
和视觉地图合并类似:
如果是动态地图,则估计\(T_{ma}\in Sim(3)\),否则估计\(T_{ma}\in SE(3)\)
BA:在\(K_a\)和\(K_m\)的最近的五个关键帧上进行优化。位姿、速度、bias。对于\(M_m\),当前关键帧窗口前的帧被固定,而\(M_a\)中可以被优化。
闭环检测
和地图合并类似,只有在同一动态地图的两帧匹配后,才会建立联合窗口,冗余的点会被检测,并且在共视图和本征图中加上新的边。然后进行位姿图优化,将误差传递到动态图的其他部分。最终是一个全局BA,找到最大后验估计。在视觉-惯导中,为了减少计算量,全局BA只在关键帧太少时采用。
图例
论文中除了系统图还有两张对优化状态量描述很详细的图:
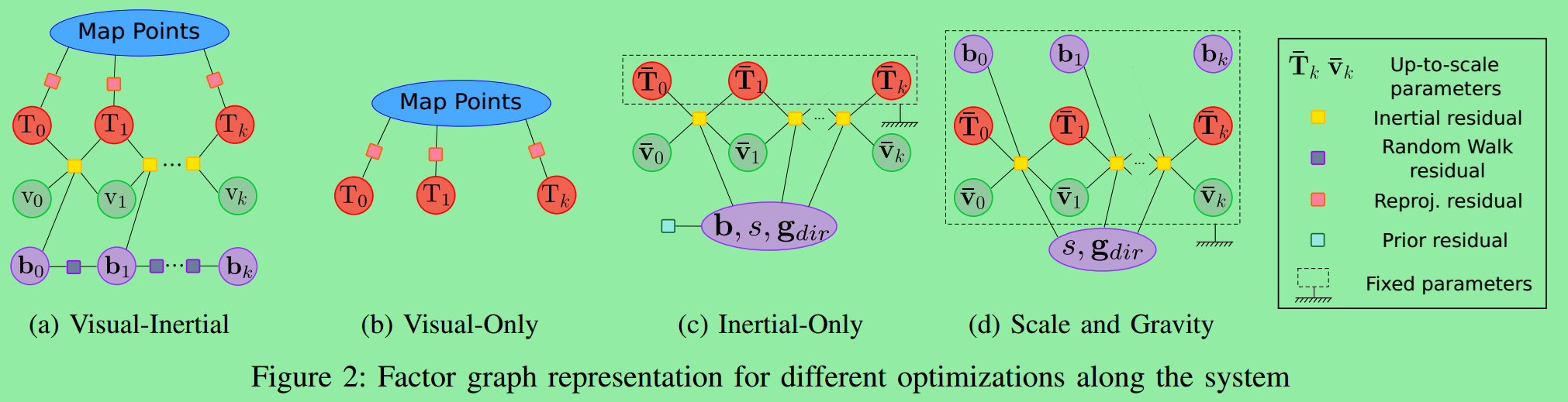
图2是不同模式下的因子图,正方形为残差量,圆形(包括椭圆)为优化变量,虚框中为固定的量,不需要优化。(a)为视觉惯导因子图,包括重投影残差、随机游走残差、惯性测量残差,优化地图点、位姿、速度和bias。图(b)为仅视觉因子图只有重投影残差,优化地图点和位姿。图(c)是仅惯导因子图,位姿已经通过仅视觉部分提供,这里直接固定,位姿固定,速度、bias、尺度、重力方向需要被估计,注意根据公式(6)-(8),这里有一个先验残差。图(d)是追踪时如果运动量太小,惯导估计不准确,则只估计尺度和重力方向。
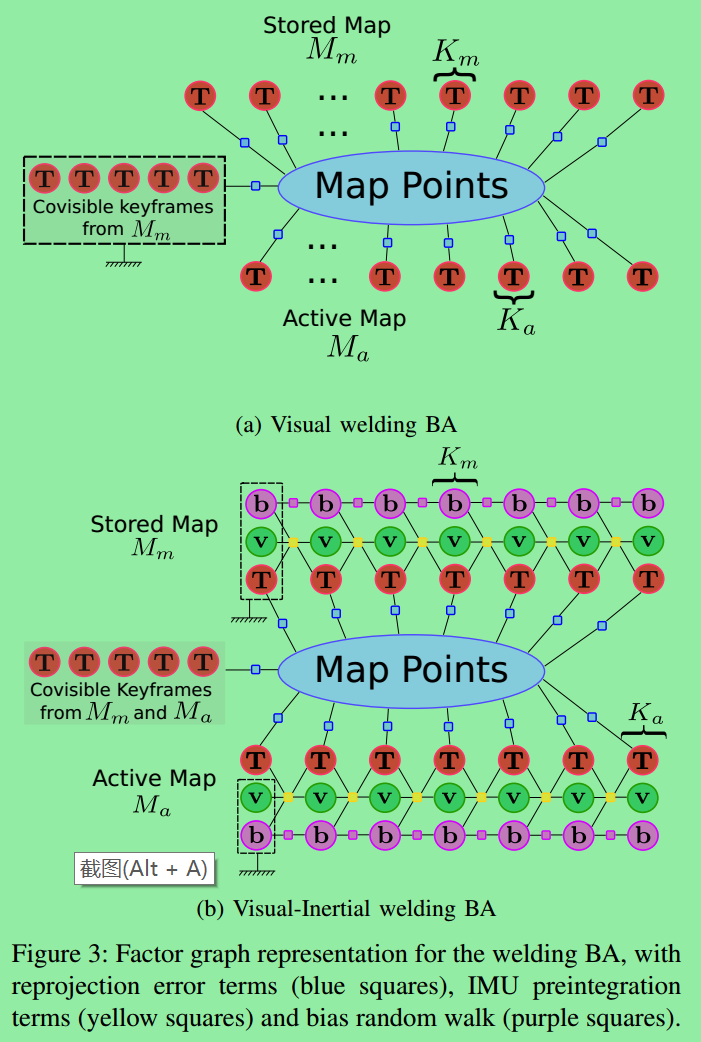
该图为联合窗口中做BA时优化的量。
实验
包括在EuRoC上跑的单地图实验、TUM-VI 上的视觉惯导SLAM,EuRoC上的多地图SLAM,效果惊人,具体见论文,数据很详细。
一些问题
- 哪些帧会出现在动态地图?
新的关键帧肯定会,长期丢失后重新初始化建立的关键帧,合并地图后产生动态地图
- 运动量太小,为什么只估计尺度和重力方向?图2(d)。
ORB-SLAM3论文阅读:ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial and Multi-Map SLAM的更多相关文章
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- 论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline
论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline 如上图所示,本文旨在解决一个问题:给定一张图像, ...
随机推荐
- GPU上如何优化卷积
GPU上如何优化卷积 本文将演示如何在TVM中编写高性能卷积实现.我们以平方大小的输入张量和滤波器为例,假设卷积的输入是大批量的.在本例中,使用不同的布局来存储数据,以实现更好的数据局部性.缓冲区布局 ...
- Java静态方法和实例方法的区别以及this的用法
Java静态方法和实例方法 相同之处:都能接收传过来的参数,都能返回参数. 不同之处:有static就是静态方法,静态方法在另外一个类里面,不用new这个静态方法所在的类,也能直接访问这个方法,比较方 ...
- 对话Apache Hudi VP, 洞悉数据湖的过去现在和未来
Apache Hudi是一个开源数据湖管理平台,用于简化增量数据处理和数据管道开发,该平台可以有效地管理业务需求,例如数据生命周期,并提高数据质量.Hudi的一些常见用例是记录级的插入.更新和删除.简 ...
- 【NX二次开发】Block UI 整数表
属性说明 常规 类型 描述 BlockID String 控件ID Enable Logical 是否可操作 Group Logical ...
- 【NX二次开发】切换模块的方法,切换到制图模块
源码(NX12.0): Session theSession = NXOpen::Session::GetSession(); theSession->ApplicationSwitchImme ...
- 【C++】Vector求最大值最小值
最大值: int max = *max_element(v.begin(),v.end()); 最小值: int min = *min_element(v.begin(),v.end());
- [Linux]经典面试题 - 系统管理 - 备份策略
[Linux]经典面试题 - 系统管理 - 备份策略 目录 [Linux]经典面试题 - 系统管理 - 备份策略 一.备份目录 1.1 系统目录 1.2 服务目录 二.备份策略 2.1 完整备份 2. ...
- 555定时器(1)单稳态触发器电路及Multisim实例仿真
555定时器(Timer)因内部有3个5K欧姆分压电阻而得名,是一种多用途的模数混合集成电路,它能方便地组成施密特触发器.单稳态触发器与多谐振荡器,而且成本低,性能可靠,在各种领域获得了广泛的应用. ...
- css初级代码
<!DOCTYPE html> <html lang="zh-cn"> <head> <meta charset="utf-8& ...
- 简易版JDBC连接池
JDBC连接池mini版的实现 首先是工具类 DbUtil 主要参数就是Driver.User.PWD等啦,主要用于建立连接 URL需要注意的是SSL和serverTimezone参数,和mysql驱 ...