模糊C均值算法
Fuzzy C-Means读书笔记
一、算法简介
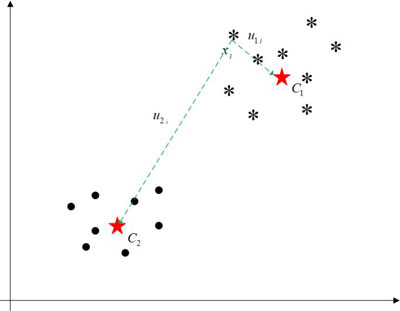
很显然,图中的数据集可分为两个簇。借鉴K-Means算法的思想,利用单个特殊的点(质心)表示一个簇。因此,我们用\(C_1\)和\(C_2\)分别表示簇1和簇2。现在我们将隶属度引入到K-Means中,这就是我们研究的模糊C-Means算法。
二、算法的目标函数
K-Means算法的评价指标:簇内样本之间的距离尽可能的小,簇间样本之间的距离尽可能的大。Fuzzy C-Means继承并发展了它的评价指标。在K-Means算法中,每个数据只能归属一个簇。而在Fuzzy C-Means算法中,每个数据归属C个类。例如,在上图中,第\(j\)个数据\(x_j\)与\(C_1\)和\(C_2\)的距离分别为\(||x_j - C_1||^2\)、\(||x_j - C_2||^2\)。由上图可知,\(x_j\)属于\(C_1\)。所以我们希望\(||x_j - C_1||^2\)比\(||x_j - C_2||^2\)更有用点。最简单的想法是引入权重,希望\(u_{1j}\)越大越好,\(u_{2j}\)越小越好。因此,我用使用\(u_{1j}+u_{2j}=1\)对目标函数\((u_{1j})^m||x_j - C_1||^2+(u_{2j})^m||x_j - C_2||^2\)进行约束。模糊指数\(m(m>1)\)控制距离重要性的大小。
假设我们有\(N\)个数据,那么这\(N\)个数据到第一类的距离为:
\]
\(N\)个数据到第二类的距离为:
\]
则Fuzzy C-Means的目标函数:
s.t.
\left\{
\begin{matrix}
\sum_{i=1}^{2}{u_{i1}}=u_{11}+u_{21}=1\\
\sum_{i=1}^{2}{u_{i2}}=u_{11}+u_{22}=1\\
...\\
\sum_{i=1}^{2}{u_{iN}}=u_{1N}+u_{2N}=1
\end{matrix}
\right.
\]
三、算法迭代公式推导
这里,我们对上述的目标函数中的类别数2扩展到任意数\(L\),即
s.t.\ \ \ \ \sum_{i=1}^{L}{u_{ij}=1},\ \ \text{j=1,2,...,N}
\]
很显然,拉格朗日乘子法(Lagrange multipliers)是我们求解多元函数在一组约束下的极值的方法。
=\sum_{i=1}^{L}\sum_{j=1}^{N}{(u_{ij})^m||x_j - C_i||^2}+\sum_{j=1}^{N}\lambda_{j}(\sum_{i=1}^{L}{u_{ij}}-1)\\
=\sum_{i=1}^{L}\sum_{j=1}^{N}{(u_{ij})^m||x_j - C_i||^2}+\sum_{j=1}^{N}(\sum_{i=1}^{L}{\lambda{j}u_{ij}}-\lambda_{j})
\]
\(J\)对\(u_{ij}\)求偏导:
mu_{ij}^{m-1}||x_j - C_i||^2=-\lambda_{j}\\
u_{ij}^{m-1}=\frac{-\lambda_{j}}{m||x_j - C_i||^2}\\
u_{ij}=(\frac{-\lambda_{j}}{m||x_j - C_i||^2})^{\frac{1}{m-1}}\\
u_{ij}=(-\frac{\lambda_{j}}{m})^{\frac{1}{m-1}}{\frac{1}{||x_j - C_i||^{\frac{2}{m-1}}}}
\]
将上式求出来的\(u_{ij}\)带入约束条件中:
1=(-\frac{\lambda_{j}}{m})^{\frac{1}{m-1}}\sum_{i=1}^{L}{\frac{1}{||x_j - C_i||^{\frac{2}{m-1}}}}\\
(-\frac{\lambda_{j}}{m})^{\frac{1}{m-1}}=\frac{1}{\sum_{i=1}^{L}{\frac{1}{||x_j - C_i||^{\frac{2}{m-1}}}}}
\]
将上式求出来的结果带入\(u_{ij}\)中,可得
u_{ij}=\frac{1}{\sum_{k=1}^{L}{(\frac{||x_j - C_i||}{||x_j - C_k||})^{\frac{2}{m-1}}}}
\]
\(J\)对\(c_{i}\)求偏导:
\sum_{j=1}^{N}{u_{ij}^{m}(x_j-C_i)}=0\\
\sum_{j=1}^{N}{u_{ij}^{m}}x_j - C_i\sum_{s=1}^{N}{u_{is}^{m}}=0\\
C_i=\frac{\sum_{j=1}^{N}{u_{ij}^{m}}x_j}{\sum_{s=1}^{N}{u_{is}^{m}}}\\
C_i=\sum_{j=1}^{N}{\frac{u_{ij}^{m}}{\sum_{s=1}^{N}{u_{is}^{m}}}x_j}
\]
四、Matlab实现
%% ------------------------ 编码信息 -------------------------% Author: Lee Wen-Tsao% Time: 2021-09-01% Content: Fuzzy C-Means% Parameter:% n: 数据长度% k: 分类数目% m: 模糊指数,取值范围(1.5, 2.5)%% ----------------------- 清理运行环境 -----------------------clc;clear;close all;%% 输入数据Iris = uiimport('iris.data');Iris = cellfun(@(x) regexp(x,',','split'), Iris.iris,'UniformOutput',false);data = cellfun(@(x) x(:,1:4),Iris,'UniformOutput',false);data = str2double(reshape([data{:}],4,150)');%% 定义参数[n, d] = size(data);maxIter = 1000;k = 3;m = 2;display = true;epsilon = 0.01;%% 初始化隶属度矩阵random_mat = rand(k,n);sum_mat = sum(random_mat);MembershipMat = random_mat ./ sum_mat;%% 拟合数据obj_fcn = zeros(1,maxIter);for it=1:maxIter% 更新簇心centers = updateCenter(MembershipMat, data, m, k);% 更新隶属矩阵[MembershipMat, dists] = updateMembershipMat(centers, data, k, n, m);% 计算目标函数值obj_fcn(it) = sum(sum((MembershipMat.^m).*(dists.^2)));if displayfprintf('Iteration count=%d, obj_fcn=%f\n',it, obj_fcn(it))endif it > 1if abs(obj_fcn(it)-obj_fcn(it-1))<epsilon, break;endendendtatgets = getLabel(MembershipMat);%% 根据隶属度矩阵更新聚类中心function Centroids = updateCenter(MembershipMat, data, m, k)fm = MembershipMat.^m;summation = sum(fm, 2).*ones(k, size(data,2));Centroids = (fm*data)./summation;end%% 更新隶属度矩阵function [Membership, dist] = updateMembershipMat(Centroids, data, k, n, m)dist = ones(k, n);for i=1:kdist(i,:) = vecnorm(data - Centroids(i,:), 2, 2)';endMebership = dist.^(-2/(m-1));summation = sum(Mebership);Membership = (Mebership./summation);end%% 获取标签function labels = getLabel(MembershipMat)[~, labels] = max(MembershipMat);end
注意:鸢尾花(Iris)数据集来自UCI数据库。
模糊C均值算法的更多相关文章
- 模糊C均值聚类-FCM算法
FCM(fuzzy c-means) 模糊c均值聚类融合了模糊理论的精髓.相较于k-means的硬聚类,模糊c提供了更加灵活的聚类结果.因为大部分情况下,数据集中的对象不能划分成为明显分离的簇,指派一 ...
- paper 104: 彩色图像高速模糊的懒惰算法
工程及源代码:快速模糊.rar 图像模糊算法有很多种,我们最常见的就是均值模糊,即取一定半径内的像素值之平均值作为当前点的新的像素值,在一般的工业 ...
- 多核模糊C均值聚类
摘要: 针对于单一核在处理多数据源和异构数据源方面的不足,多核方法应运而生.本文是将多核方法应用于FCM算法,并对算法做以详细介绍,进而采用MATLAB实现. 在这之前,我们已成功将核方法应用于FCM ...
- 基于核方法的模糊C均值聚类
摘要: 本文主要针对于FCM算法在很大程度上局限于处理球星星团数据的不足,引入了核方法对算法进行优化. 与许多聚类算法一样,FCM选择欧氏距离作为样本点与相应聚类中心之间的非相似性指标,致使算法趋向 ...
- 模糊C均值聚类的公式推导
j=1...n,N个样本 i=1...c,C聚类 一.优化函数 FCM算法的数学模型其实是一个条件极值问题: 把上面的条件极值问题转化为无条件的极值问题,这个在数学分析上经常用到的一种方法就是拉格朗日 ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- R语言 模糊c均值(FCM)算法程序(转)
FCM <- function(x, K, mybeta = 2, nstart = 1, iter_max = 100, eps = 1e-06) { ## FCM ## INPUTS ## ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
随机推荐
- 浅讲.Net 6之ConfigurationManager
介绍 本节为大家带来.NET 6新增的ConfigurationManager,很多人好奇为啥要讲这个,读取加载配置信息都随手就来了,我们往下看一下. 翻译:这添加了 ASP.NET Core 的新 ...
- 【Tool】MySQL安装
MySQL安装 2019-11-07 14:30:32 by冲冲 本机 Windows7 64bit,MySQL是 mysql-8.0.18-winx64.zip. 1.官网下载 https:// ...
- 8.2 k8s 基于StatefulSet运行mysql 一主多从 ,数据通过pv/pvc结合NFS服务器持久化
1.准备mysql和xtrabackup镜像 下载mysql官方镜像并上传到本地harbor docker pull mysql:5.7 docker tag m ysql:5.7 192.168.1 ...
- 实战!spring Boot security+JWT 前后端分离架构认证登录!
大家好,我是不才陈某~ 认证.授权是实战项目中必不可少的部分,而Spring Security则将作为首选安全组件,因此陈某新开了 <Spring Security 进阶> 这个专栏,写一 ...
- CF713C Sonya and Problem Wihtout a Legend
考虑我们直接选择一个暴力\(dp\). \(f_{i,j} = min_{k<=j}\ (f_{i - 1,k}) + |a_i - j|\) 我们考虑到我们直接维护在整个数域上\(min(f_ ...
- Codeforces 700D - Huffman Coding on Segment(莫队+根分)
Codeforces 题目传送门 & 洛谷题目传送门 好家伙,刚拿到此题时我连啥是 huffman 编码都不知道 一种对 \(k\) 个字符进行的 huffman 编码的方案可以看作一个由 \ ...
- mount 挂载详解
挂接命令(mount) 首先,介绍一下挂接(mount)命令的使用方法,mount命令参数非常多,这里主要讲一下今天我们要用到的. 命令格式:mount [-t vfstype] [-o option ...
- 充分利用nginx的reload功能平滑的上架和更新业务
以前更新我们都要停服务更新,不管什么时候更新,都可能有客户在访问,体验不好,二是如果有数据传输,可能会造成数据丢失. nginx reload可以不间断更新配置文件,原理就是当我们修改配置文件发起re ...
- WebRTC网页打开摄像头并录制视频
前面我们能打开本地摄像头,并且在网页上看到摄像头的预览图像. 本文我们使用MediaRecorder来录制视频.在网页上播放录制好的视频,并能提供下载功能. html 首先创建一个html界面,放上一 ...
- 5 — springboot中的yml多环境配置
1.改文件后缀 2.一张截图搞定多环境编写和切换