(数据科学学习手札117)Python+Dash快速web应用开发——交互表格篇(下)
本文示例代码已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
这是我的系列教程Python+Dash快速web应用开发的第十四期,在前两期中,我们针对dash_table的自定义样式、前后端分页、单元格内容编辑等特点展开了介绍。
而在dash_table中还有很多高级特性,可以极大程度上丰富DataTable()所渲染网页表格的交互能力,今天的文章作为交互表格篇的下篇,我们就来一起学习其中比较实用的一些特性。
 图1
图1
2 dash_table的更多实用功能
2.1 更多表格交互特性
上一期文章最后我们学习了通过设置参数editable=True,使得渲染出的表格可以通过鼠标双击进行编辑,而dash_table除此之外,还有更多实用的交互能力:
2.1.1 按列排序
- 普通单列排序
在DataTable()中,我们只需要设置参数sort_action='native',即可开启列排序功能,此时每一列列名单元格内都会出现部件供我们点击切换排序方式:
app1.py
import dash
import dash_table
import dash_bootstrap_components as dbc
import seaborn as sns
df = sns.load_dataset('iris')
app = dash.Dash(__name__)
app.layout = dbc.Container(
[
dash_table.DataTable(
data=df.to_dict('records'),
columns=[
{'name': column, 'id': column}
for column in df.columns
],
style_table={
'height': '500px',
'overflow-y': 'auto'
},
sort_action='native'
)
],
style={
'margin-top': '50px'
}
)
if __name__ == '__main__':
app.run_server(debug=True)
 图2
图2
- 基于后端排序的多列排序
在DataTable()中设置sort_action='native'时,对应的是按列排序的前端模式,也即是数据一次性灌注到浏览器的前提下进行排序,这种方式不仅不适合大型数据集,而且只支持单列排序。
而当数据渲染方式为后端模式时,我们通过设置参数sort_action='custom'以及sort_mode='multi',配合在回调中获取属性sort_by中记录的参与排序的列名及升序降序方式,就可以实现多列排序。
我们在上一期的app2.py的基础上修改得到下面的例子:
app2.py
import dash
import dash_bootstrap_components as dbc
import dash_table
from dash.dependencies import Input, Output
import seaborn as sns
df = sns.load_dataset('iris')
df.insert(0, '#', df.index)
app = dash.Dash(__name__)
app.layout = dbc.Container(
[
dbc.Spinner(
dash_table.DataTable(
id='dash-table',
columns=[
{'name': column, 'id': column}
for column in df.columns
],
page_size=15, # 设置单页显示15行记录行数
page_action='custom',
page_current=0,
style_header={
'font-family': 'Times New Romer',
'font-weight': 'bold',
'text-align': 'center'
},
style_data={
'font-family': 'Times New Romer',
'text-align': 'center'
},
sort_action='custom',
sort_mode='multi'
)
)
],
style={
'margin-top': '50px'
}
)
@app.callback(
[Output('dash-table', 'data'),
Output('dash-table', 'page_count')],
[Input('dash-table', 'page_current'),
Input('dash-table', 'page_size'),
Input('dash-table', 'sort_by')]
)
def refresh_page_data(page_current, page_size, sort_by):
if sort_by:
return (
df
.sort_values(
[col['column_id'] for col in sort_by],
ascending=[
col['direction'] == 'asc'
for col in sort_by
]
)
.iloc[page_current * page_size:(page_current + 1) * page_size]
.to_dict('records'),
1 + df.shape[0] // page_size
)
return (
df.iloc[page_current * page_size:(page_current + 1) * page_size].to_dict('records'),
1 + df.shape[0] // page_size
)
if __name__ == '__main__':
app.run_server(debug=True)
 图3
图3
2.1.2 按列条件筛选
除了基于指定字段进行排序之外,dash_table还支持列的条件筛选,设置filter_action="native",就可以开启基础的按列条件筛选功能,此时每一列表头下都会多出供用户输入筛选条件的单元格:
app3.py
import dash
import dash_table
import dash_bootstrap_components as dbc
import seaborn as sns
df = sns.load_dataset('iris')
app = dash.Dash(__name__)
app.layout = dbc.Container(
[
dash_table.DataTable(
data=df.to_dict('records'),
columns=[
{'name': column, 'id': column}
for column in df.columns
],
# 自定义条件筛选单元格样式
style_filter={
'font-family': 'Times New Romer',
'background-color': '#e3f2fd'
},
style_table={
'height': '500px',
'overflow-y': 'auto'
},
style_header={
'font-family': 'Times New Romer',
'font-weight': 'bold',
'text-align': 'center'
},
style_data={
'font-family': 'Times New Romer',
'text-align': 'center'
},
filter_action="native"
)
],
style={
'margin-top': '50px'
}
)
if __name__ == '__main__':
app.run_server(debug=True)
 图4
图4
而dash_table中自带的条件筛选语法很丰富,有条件的朋友可以前往https://dash.plotly.com/datatable/filtering了解更多。
而dash_table同样可以实现后端筛选,和前面的后端排序类似,主要利用filter_query属性的回调变化在后台基于pandas等框架进行数据筛选,比较简单,这里就不再赘述。
2.2 自带的数据表格下载功能
dash_table还自带了将当前所渲染的表格内容直接下载为csv或xlsx格式文件的简易功能,通过参数export_format设置导出的文件格式,但自带的下载按钮样式比较丑,如果你对此有比较高的要求,还是建议结合之前的上传下载篇自己设计相关功能:
 图5
图5
2.3 冻结首行
通过设置参数fixed_rows={'headers': True},我们可以实现下滑查看表格的过程中,始终保持表头被冻结:
 图6
图6
3 开发一个在线取数工具
在学习完今天的内容之后,我们来结合之前上传下载篇中提到的下载功能,来制作一个简单的对指定数据库中的数据表进行快速条件筛选并下载的工具,其中DataTable的derived_virtual_data属性记录了经过排序、条件筛选等操作后当前显示的表格数据:
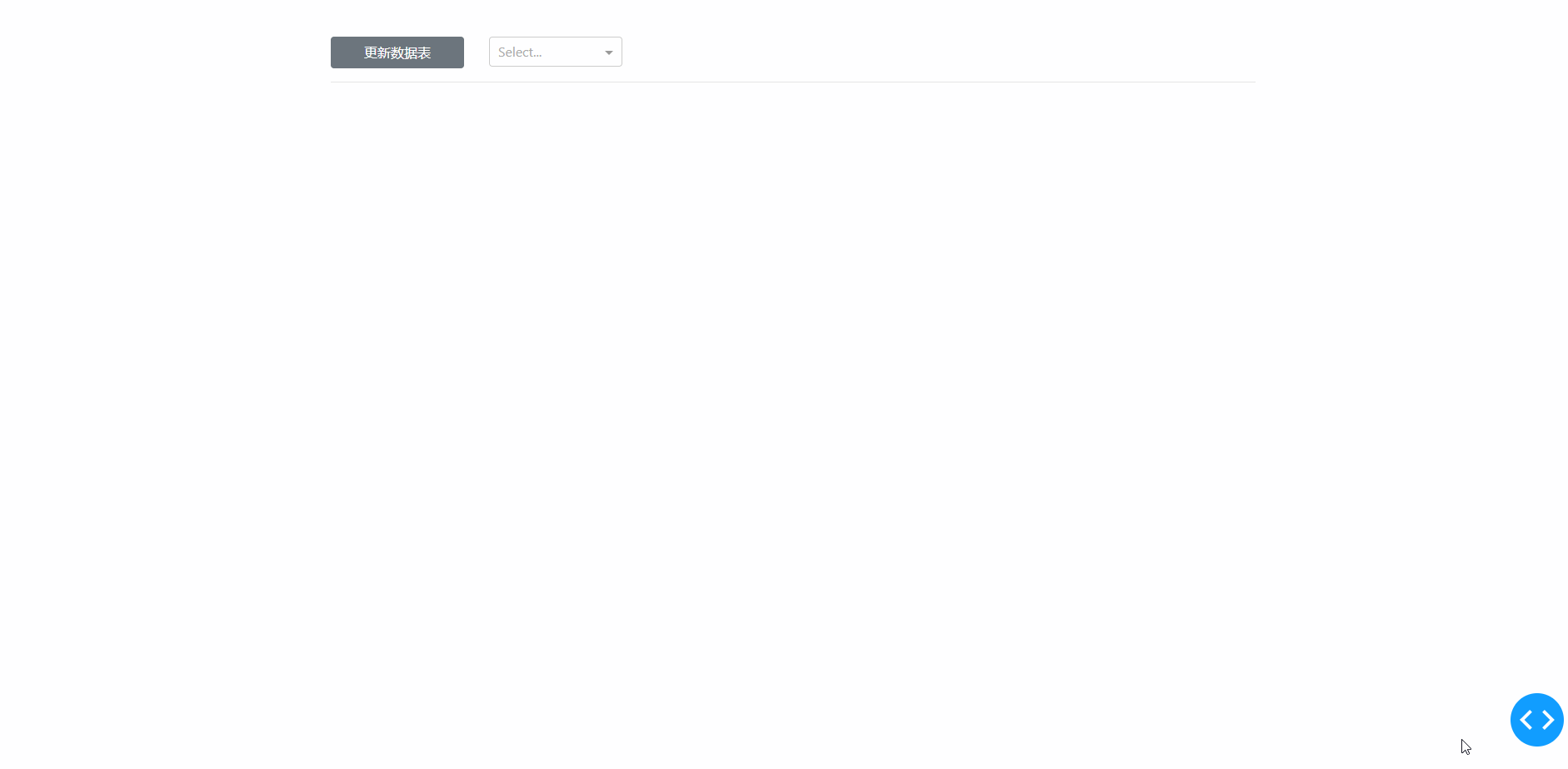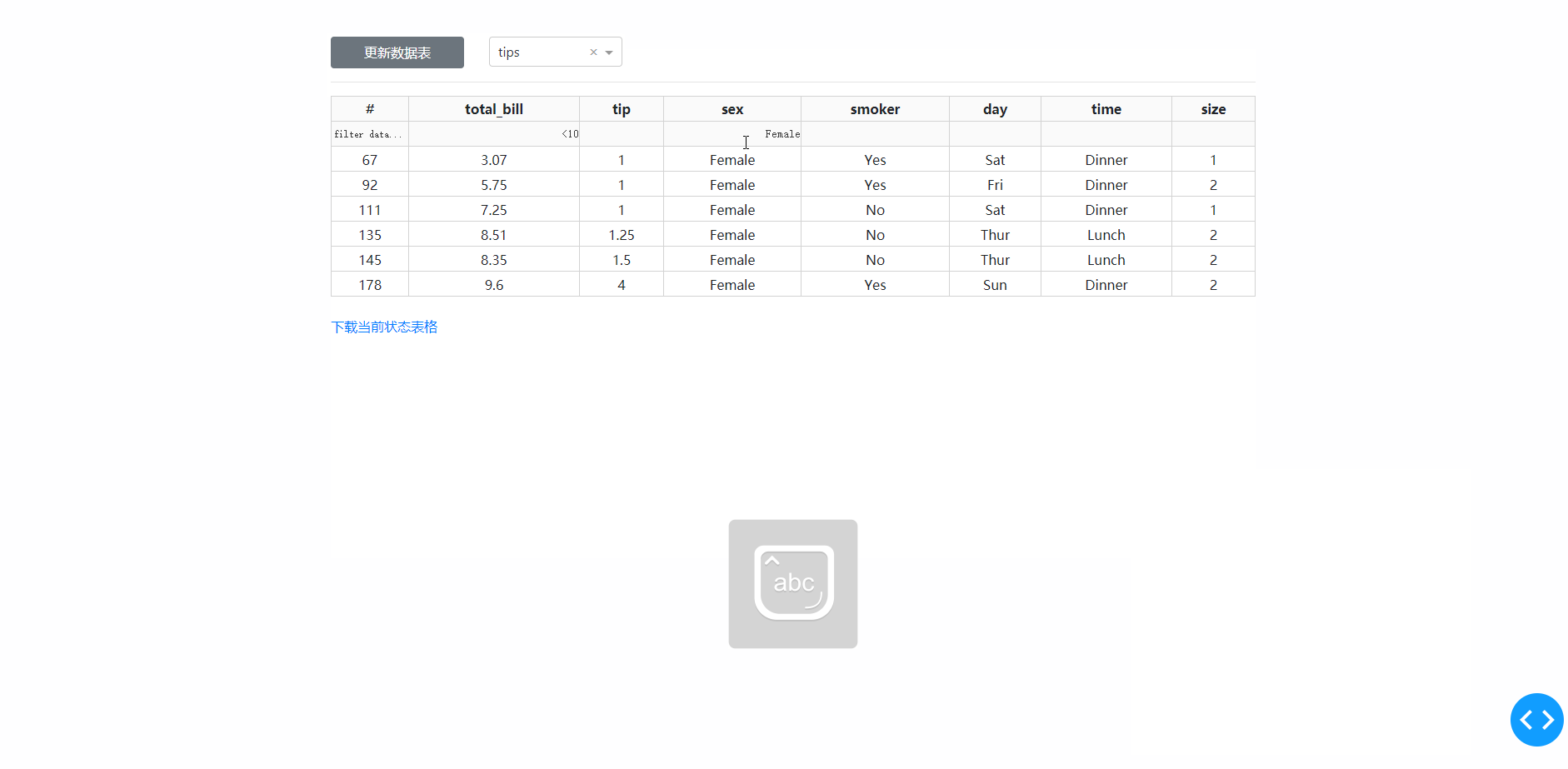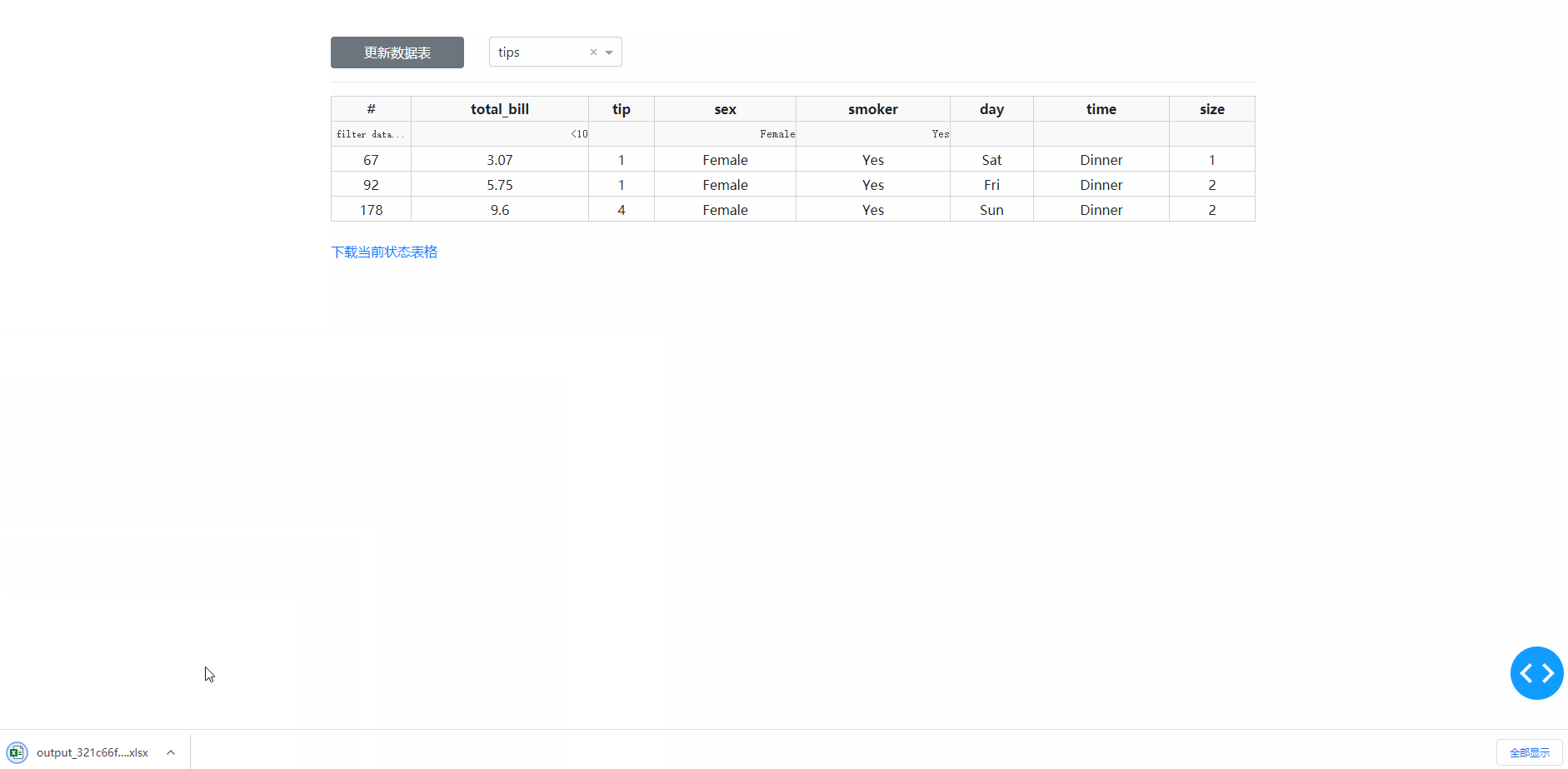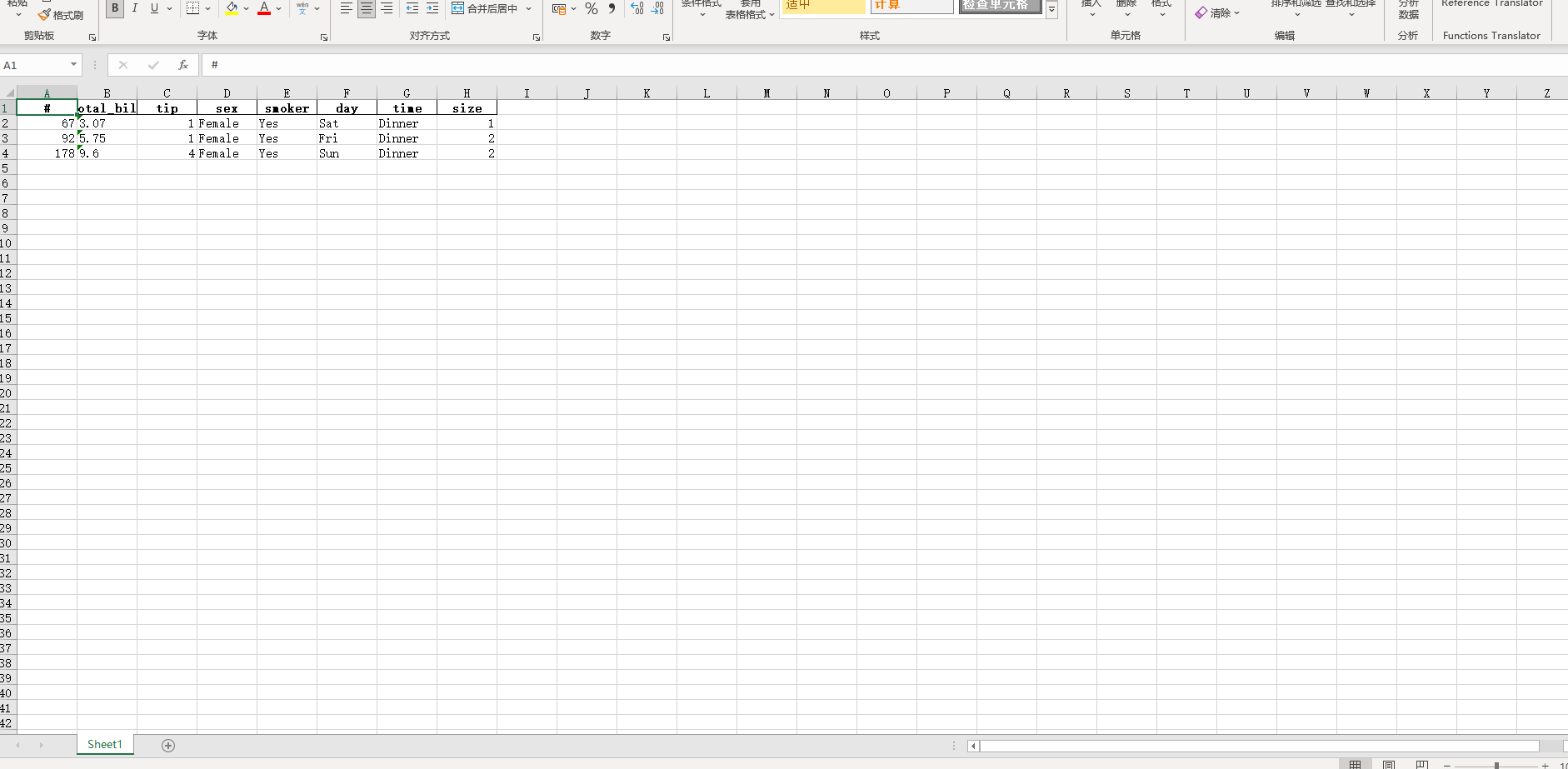 图7
图7
app4.py
import dash
import dash_bootstrap_components as dbc
import dash_core_components as dcc
import dash_html_components as html
import dash_table
from dash.dependencies import Input, Output
from flask import send_from_directory
import os
import uuid
from sqlalchemy import create_engine
import pandas as pd
try:
os.mkdir("downloads")
except FileExistsError:
pass
engine = create_engine('mysql+pymysql://root:mysql@localhost/DASH')
app = dash.Dash(__name__)
@app.server.route('/download/<file>')
def download(file):
return send_from_directory('downloads', file)
app.layout = dbc.Container(
[
dbc.Row(
[
dbc.Col(dbc.Button('更新数据表', id='refresh-tables', style={'width': '100%'}), width=2),
dbc.Col(dcc.Dropdown(id='table-select', style={'width': '100%'}), width=2)
]
),
html.Hr(),
dash_table.DataTable(
id='dash-table',
editable=True,
page_size=15,
style_header={
'font-family': 'Times New Romer',
'font-weight': 'bold',
'text-align': 'center'
},
style_data={
'font-family': 'Times New Romer',
'text-align': 'center'
},
style_data_conditional=[
{
# 对选中状态下的单元格进行自定义样式
"if": {"state": "selected"},
"background-color": "#b3e5fc",
"border": "none"
},
],
filter_action="native"
),
html.Br(),
html.A(id='download-url', target="_blank")
],
style={
'margin-top': '50px'
}
)
@app.callback(
Output('table-select', 'options'),
Input('refresh-tables', 'n_clicks')
)
def refresh_tables(n_clicks):
if n_clicks:
return [
{
'label': table,
'value': table
}
for table in pd.read_sql_query('SHOW TABLES', con=engine)['Tables_in_dash']
]
return dash.no_update
@app.callback(
[Output('dash-table', 'data'),
Output('dash-table', 'columns')],
Input('table-select', 'value')
)
def render_dash_table(value):
if value:
df = pd.read_sql_table(value, con=engine)
return df.to_dict('records'), [
{'name': column, 'id': column}
for column in df.columns
]
else:
return [], []
@app.callback(
[Output("download-url", "href"),
Output("download-url", "children")],
[Input("dash-table", "derived_virtual_data"),
Input("dash-table", "filter_query")],
prevent_initial_call=True
)
def download_table(derived_virtual_data, filter_query):
if derived_virtual_data:
print(derived_virtual_data)
filename = f"output_{uuid.uuid1()}.xlsx"
pd.DataFrame(derived_virtual_data).to_excel("downloads/" + filename, index=False)
return "/download/" + filename, "下载当前状态表格"
return "", ""
if __name__ == '__main__':
app.run_server(debug=True)
以上就是本文的全部内容,欢迎在评论区发表你的意见与观点。
(数据科学学习手札117)Python+Dash快速web应用开发——交互表格篇(下)的更多相关文章
- (数据科学学习手札115)Python+Dash快速web应用开发——交互表格篇(上)
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- (数据科学学习手札116)Python+Dash快速web应用开发——交互表格篇(中)
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- (数据科学学习手札118)Python+Dash快速web应用开发——特殊部件篇
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- (数据科学学习手札102)Python+Dash快速web应用开发——基础概念篇
本文示例代码与数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的新系列教程Python+Dash快 ...
- (数据科学学习手札108)Python+Dash快速web应用开发——静态部件篇(上)
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- (数据科学学习手札109)Python+Dash快速web应用开发——静态部件篇(中)
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- (数据科学学习手札103)Python+Dash快速web应用开发——页面布局篇
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- (数据科学学习手札110)Python+Dash快速web应用开发——静态部件篇(下)
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- (数据科学学习手札123)Python+Dash快速web应用开发——部署发布篇
1 简介 这是我的系列教程Python+Dash快速web应用开发的第二十期,在上一期中我介绍了利用内网穿透的方式,将任何可以联网的电脑作为"服务器"向外临时发布你的Dash应用. ...
随机推荐
- vscode好用插件总结
做个记录:https://blog.csdn.net/xishining/article/details/90819481 1.Auto Rename Tag --自动重命名成对的HTML标记.假如你 ...
- HashMap是如何进行扩容的?
HashMap通过resize()方法进行扩容. 源码解析: resize()函数有两种使用情况: 一.当table数组为null时初始化hash表. 二.当table数组不为null时进行扩容. 1 ...
- java与freemarker遍历map
一.java遍历MAP /** * 1.把key放到一个集合里,遍历key值同时根据key得到值 (推荐) */ Set set =map.keySet(); Iterator it=set.iter ...
- macOS命令行切换Python版本
目录 brew安装anaconda3 anaconda3环境变量设置 安装双版本 命令后切换python环境 pip ide vscode set 参考 brew安装anaconda3 brew ca ...
- sqlyog如何增删改查?
转: sqlyog如何增删改查? 下面是一道完整的 sqlyog 增删改查的练习, 顺着做下去,可以迅速掌握. 1. 创建部门表dept,并插入数据: 2. 创建emp员工表,并插入数据: sql 代 ...
- HDU1067 Gap
题目: Let's play a card game called Gap. You have 28 cards labeled with two-digit numbers. The first d ...
- NodeJs 入门到放弃 — 网络服务器(三)
码文不易啊,转载请带上本文链接呀,感谢感谢 https://www.cnblogs.com/echoyya/p/14484454.html 目录 码文不易啊,转载请带上本文链接呀,感谢感谢 https ...
- ModuleNotFoundError: No module named 'django'
1 .就在前天 我还能用python3 manage.py runserver 0.0.0.0:8000 启动Django 今天就突然报错了(心情极为复杂,你这也能信?) 2.打印python找 ...
- 靶场练习-Sqli-labs通关记录(1-4关)
0x00 实验环境 本地:Win 10 靶场:sqli-labs(共65关,每日一关) 0x02 通关记录 简介:一天一关! (1)第一关: 简单的 ...
- rest framework ViewSet
ViewSets 路由选择确定要用于一个请求哪个控制器之后,控制器负责做出请求的感并产生相应的输出. - Ruby on Rails的文档 Django的REST框架允许你的逻辑一组在一个类中的相关意 ...