csp-s模拟测试41「夜莺与玫瑰·玫瑰花精·影子」
夜莺与玫瑰
题解
联赛$T1$莫比乌斯$\%\%\%$
$dead$ $line$是直线
首先横竖就是$n+m$这比较显然
枚举方向向量
首先我们枚举方向向量时只枚举右下方向,显然贡献$*2$就是所有斜着的直线
$i,j$表示当自己向右$i$个单位长度,向下$j$单位长度
我们相同斜率下只算最短的线贡献,(因为其他长度下方案数都包含在最短里面了)
我们方向向量$i$,$j$的$gcd(i,j)==1$时我们枚举的才是当前斜率最短长度,
然后考虑贡献
考虑容斥,先算出来当前长度下所有线段再减去重合的
$(n-a)*(m-b)$是总方案数,考虑重合部分
假设我们有一个4*4点阵
. . . .
. . . .
. . . .
. . . .
我们算1,1方向向量贡献
\ \ \ .
\ \ \ \
\ \ \ \
. \ \ \
只有
\ \ \ .
\ \ \ \
\ \ \ \
. \ \ \
标蓝才有贡献,别的都是算重的
定义前趋为$x-1$ $y-1$,后继$x+1$ $y+1$
观察这些线发现符合条件就是前趋不在点阵而后继在点阵数量
例如$1$,$1$这个点$+$方向向量得到$-1$ $-1$ 和$2$ $2$
因为$-1$ $-1$不在点阵内所以是合法的
,我们把他们都提到与边界相重
看他们相减后是否在边界中即可
重复的部分就是$max((n-2*a),0)*max((m-2*b),0)$
$\sum\limits_ {a=1}^{a<=n} \sum\limits_{b=1}^{b<=m} [gcd(a,b)==1](n-a)*(m-b)-max((n-2*a),0)*max((m-2*b),0)$
这样我们还是$AC$不了$T=10000$稍巨
所以我们预处理一下,让查询变成$O(n)$的$(其实可以是O(1))然而出题人还卡空间$
把原式子拆成$(n-a)*m-(n-a)*b$每一个$gcd(a,b)==1$都会对第一个式子造成贡献,而后面那个式子就是$(n-a)*{\sum\limits_{b=1}^{b<=m} [gcd(a,b)==1] b}$
维护前缀和$tot(a,m)$表示$b=1--m所有数中$与$a$,$gcd==1$的个数和为$tot(a,m)$,
$sum(a,m)$表示$b=1--m$中所有$gcd(a,b)==1$对应$\sum\limits_{b=1}^{b<=m} [gcd(a,b)==1] b$和为$sum(a,m)$
所以式子$\sum\limits_ {a=1}^{a<=n} \sum\limits_{b=1}^{b<=m} [gcd(a,b)==1](n-a)*(m-b)$可以化为$(n-a)*(tot(a,m)*m-sum(a,m))$
后面这个式子类似
首先如果$(n-2*a)<=0$或$(m-2*b)<=0$就不用减了
所以$m-2*b>0$才可以即$b<\frac{m}{2}$
所以后面式子可以化为$(n-2*a)*(tot(a,\frac{m}{2})*m-2*sum(a,\frac{m}{2}))$
总式子就是$\sum\limits_{a=1}^{a<=n} (n-a)*(tot(a,m)*m-sum(a,m))-(n-2*a)*(tot(a,\frac{m}{2})*m-2*sum(a,\frac{m}{2}))$
单单是这样你还是$AC$不了$4000*4000$枚举$gcd$很慢,你需要递推
代码
- #include<iostream>
- #include<cstdio>
- using namespace std;
- int T,n,m,sum[4100][4100];
- const int mod=1073741824;
- short num[4100][4100],g[4100][4100];
- int gcd(int a,int b){return b?gcd(b,a%b):a;}
- int main(){
- for(register int i=1;i<=4001;i++){
- g[i][i]=g[0][i]=g[i][0]=i;
- for(register int j=1;j<i;j++){
- g[i][j]=g[j][i]=g[j][i%j];
- }
- }
- for(register int i=1;i<=4001;i++){
- for(register int j=1;j<=4001;j++){
- sum[i][j]=sum[i][j-1];
- num[i][j]=num[i][j-1];
- if(g[i][j]==1) sum[i][j]=(sum[i][j]+j)%mod,num[i][j]++;
- }
- }
- scanf("%d",&T);
- while(T--){
- scanf("%d%d",&n,&m);
- long long ans=0;
- for(register int i=1;i<n;i++){
- ans=(ans+(num[i][m]*m%mod-sum[i][m]%mod)*(n-i)%mod)%mod;
- if(2*i<n) ans=ans-(num[i][m/2]*m%mod-2*sum[i][m/2]%mod)*(n-i*2)%mod;
- }
- ans=(ans*2%mod+n+m)%mod;
- printf("%lld\n",(ans+mod)%mod);
- }
- }
夜莺
玫瑰花精
题解
抱歉,题解没时间写了
- 对于 100%的数据
- 可以考虑线段树。首先我们对区间[1..n]建立一棵线段树。对于每一个节点,
- 维护 4 个值。分别是 l,r,mid,p。l 表示在当前结点线段树所在区间最左边的花精所在的位置,r 表示最右边的花精所在的位置。mid 表示在这个小区间[l,r]中的
- 两只花精之间的最长距离除以 2 后的值。p 表示取 mid 值时所在的紧邻的两只
- 花精的中间位置,也就是在[l,r]中的答案值。
- 对于 1 询问:访问线段树的第一个节点,我们比较 l-1,n-r,mid 的值哪
- 个更大,就选哪个,它们的答案依次是 1,n,p。假设我们求得的位置是 fairy[x]。
- 然后访问[fairy[x],fairy[x]]所在的线段树的叶子节点,初始化它的值,然后回溯,
- 进行合并。对于 tr[x].l 与 tr[x].r 可以通过两个儿子的 l,r 信息得出。对于 tr[x].mid
- 值,首先在左右儿子的 mid 值中去一个最大的值。其次考虑一种情况,就是夹在
- 两个线段之间的距离,可以通过(tr[x+x+1].l-tr[x+x].r) / 2 的值得出在于 mid
- 进行比较,然后 p 就随着 mid 的值的更新而更新。
- 对于 2 询问:访问询问花精所在的位置,直接将它的叶子节点
- [fairy[x],fairy[x]]删除,然后回溯时,再做一次合并操作。
代码
- #include<bits/stdc++.h>
- using namespace std;
- #define ll long long
- #define A 1010101
- struct tree{
- ll l,r,mid,ql,qr,p;
- }tr[A];
- ll n,m;
- ll in[A];
- void built(ll x,ll l,ll r){
- tr[x].l=l,tr[x].r=r;
- if(l==r){
- return ;
- }
- ll mid=(l+r)>>1;
- built(x<<1,l,mid);
- built(x<<1|1,mid+1,r);
- }
- void update(ll x){
- // printf("ql=%lld qr=%lld\n",tr[x].ql,tr[x].qr);
- if(tr[x<<1].ql) tr[x].ql=tr[x<<1].ql;
- else tr[x].ql=tr[x<<1|1].ql;
- if(tr[x<<1|1].qr) tr[x].qr=tr[x<<1|1].qr;
- else tr[x].qr=tr[x<<1].qr;
- tr[x].mid=tr[x<<1].mid;
- tr[x].p=tr[x<<1].p;
- if(tr[x<<1].qr&&tr[x<<1|1].ql){
- // ll minn=tr[x].mid;
- if((tr[x<<1|1].ql-tr[x<<1].qr)/2>tr[x].mid){
- tr[x].mid=(tr[x<<1|1].ql-tr[x<<1].qr)>>1;
- tr[x].p=(tr[x<<1].qr+tr[x<<1|1].ql)>>1;
- // minn=tr[x].mid;
- }
- if(tr[x<<1|1].mid>tr[x].mid){
- tr[x].mid=tr[x<<1|1].mid;
- tr[x].p=(tr[x<<1|1].p);
- // minn=tr[x].mid;
- }
- }
- // printf("x=%lld l%lld--r%lld <<1%lld %lld |1%lld %lld区间 leftson mid=%lld mid=%lld x.mid=%lld p=%lld p=%lld p=%lld \n",x,tr[x].ql,tr[x].qr,tr[x<<1].ql,tr[x<<1].qr,tr[x<<1|1].ql,tr[x<<1|1].qr,tr[x<<1].mid,tr[x<<1|1].mid,tr[x].mid,tr[x].p,tr[x<<1].p,tr[x<<1|1].p);
- return ;
- }
- void change(ll x,ll pla,ll val){
- if(tr[x].l==tr[x].r){
- if(val==1){
- tr[x].ql=tr[x].l;
- tr[x].qr=tr[x].r;
- // printf("x=%lld l=%lld r=%lld\n",x,tr[x].l,tr[x].r);
- tr[x].p=0;
- tr[x].mid=0;
- return ;
- }
- else {
- tr[x].ql=0,
- tr[x].qr=0,
- tr[x].p=0,
- tr[x].mid=0;
- // printf("x=%lld ql=%lld qr=%lld\n",x,tr[x].ql,tr[x].qr);
- return ;
- }
- }
- ll mid=(tr[x].l+tr[x].r)>>1;
- if(mid>=pla) change(x<<1,pla,val);
- else change(x<<1|1,pla,val);
- update(x);
- }
- int main(){
- scanf("%lld%lld",&n,&m);
- built(1,1,n);
- for(ll i=1,opt,a,b;i<=m;i++){
- scanf("%lld%lld",&opt,&a);
- if(opt==1){
- if(tr[1].ql==0){
- in[a]=1;
- printf("%lld\n",in[a]);
- change(1,in[a],1);
- continue ;
- }
- ll minn=-0x7ffffff;
- // printf("mid=%lld ql-1=%lld n-qr=%lld\n",tr[1].mid,tr[1].ql-1,n-tr[1].qr);
- if(tr[1].ql-1>minn){
- minn=tr[1].ql-1;
- in[a]=1;
- }
- if(tr[1].mid>minn){
- minn=tr[1].mid;
- in[a]=tr[1].p;
- }
- if(n-tr[1].qr>minn){
- minn=n-tr[1].qr;
- in[a]=n;
- }
- printf("%lld\n",in[a]);
- change(1,in[a],1);
- }
- else change(1,in[a],-1);
- }
- }
影子
题解
以为是神仙$dp$,然后是神仙并查集,
觉得官方题解写的很明白
将所有点按照权值从大到小排序,对于当前点和比当前点权值大的点和并到一个集合内,并查集维护当前集合直径和对应端点,
合并两个并查集时当前直径可以是其中一个集合中直径或两个集合交叉取
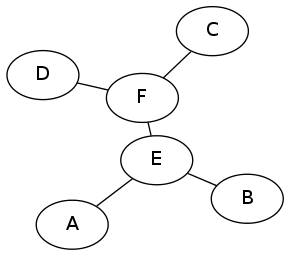
例如集合$AEB$ $CDF$ 合并时直径可以是$A-C$ $A-D$ $B-C$ $B-D$ (交叉取)$A-B$,$C-D$(原本集合)
需要用到两点之间距离$lca$在线回答就行了
合并并查集时$ans=max(ans,直径长度*a[i])$
一个问题是当前点是否在集合内,其实并不会造成影响,你已经将点从大到小排好序了,你当前枚举如果之前出现过那么已经在之前处理过了
代码
- #include<bits/stdc++.h>
- using namespace std;
- #define ll long long
- #define A 500000
- struct moo{
- ll l,r,len,fa;
- }fa[A];
- struct vvv{
- ll v,id;
- friend bool operator < (const vvv & a,const vvv & b){
- return a.v>b.v;
- }
- }v[A];
- ll dis[A],f[A][25],head[A],nxt[A],ver[A],edg[A],deep[A],va[A];
- ll t,n,m,ans=0,tot=0;
- void add(ll x,ll y,ll z){
- nxt[++tot]=head[x],head[x]=tot,ver[tot]=y,edg[tot]=z;
- }
- ll find(ll x){
- // printf("%lld.fa=%lld\n",x,fa[x].fa);
- if(x!=fa[x].fa)
- fa[x].fa=find(fa[x].fa);
- return fa[x].fa;
- }
- inline ll lca(ll x,ll y)
- {
- if(deep[x]>deep[y])swap(x,y);
- for(ll i=t;i>=0;i--)
- {
- if(deep[x]==deep[y]) break;
- if(deep[x]<=deep[f[y][i]]) y=f[y][i];
- }
- if(x==y) return x;
- for(ll i=t;i>=0;i--)
- if(f[x][i]!=f[y][i])
- x=f[x][i],y=f[y][i];
- return f[x][0];
- }
- void merge(ll x,ll y,ll edgval,ll now){
- ll maxx=0;
- x=find(fa[x].fa),y=find(fa[y].fa);
- fa[y].fa=x;
- ll l1=fa[x].l,r1=fa[x].r,l2=fa[y].l,r2=fa[y].r;
- ll dis1=fa[x].len,
- dis2=fa[y].len,
- dis3=dis[l1]+dis[l2]-2*dis[lca(l1,l2)],
- dis4=dis[l1]+dis[r2]-2*dis[lca(l1,r2)],
- dis5=dis[r1]+dis[l2]-2*dis[lca(r1,l2)],
- dis6=dis[r1]+dis[r2]-2*dis[lca(r1,r2)];
- if(dis2>fa[x].len){
- fa[x].l=l2,fa[x].r=r2;
- fa[x].len=dis2;
- }
- if(dis3>fa[x].len){
- fa[x].l=l1,fa[x].r=l2;
- fa[x].len=dis3;
- }
- if(dis4>fa[x].len){
- fa[x].l=l1,fa[x].r=r2;
- fa[x].len=dis4;
- }
- if(dis5>fa[x].len){
- fa[x].l=r1,fa[x].r=l2;
- fa[x].len=dis5;
- }
- if(dis6>fa[x].len){
- fa[x].l=r1,fa[x].r=r2;
- fa[x].len=dis6;
- }
- ans=max(ans,fa[x].len*va[now]);
- // printf("l1=%lld r1=%lld l2=%lld r2=%lld dis1=%lld dis2=%lld dis3=%lld dis4=%lld dis5=%lld dis6=%lld fa[x].len*va[now]=%lld dis[l1]=%lld+dis[l2]=%lld-2*dis[lca(l1,l2)]=%lld %lld lca=%lld ve[%lld]=%lld\n",l1,r1,l2,r2,dis1,dis2,dis3,dis4,dis5,dis6,fa[x].len*va[now],dis[r1],dis[r2],2*dis[lca(r1,r2)],dis[r1]+dis[r2]-2*dis[lca(r1,r2)],lca(r1,r2),now,va[now]);
- }
- void dfs(ll x,ll pre,ll de){
- deep[x]=de;
- for(ll i=head[x];i;i=nxt[i]){
- ll y=ver[i];
- if(y==pre) continue ;
- dis[y]=dis[x]+edg[i];
- f[y][0]=x;
- dfs(y,x,de+1);
- }
- }
- void mem(){
- memset(head,0,sizeof(head));
- memset(fa,0,sizeof(fa));
- tot=0;
- ans=0;
- }
- int main(){
- // freopen("b.in","r",stdin);
- ll T;
- scanf("%lld",&T);
- while(T--){
- scanf("%lld",&n);
- mem();
- t=log(n)/log(2)+1;
- for(ll i=1;i<=n;i++){
- scanf("%lld",&v[i].v);
- v[i].id=i;
- va[i]=v[i].v;
- fa[i].fa=i;
- fa[i].l=fa[i].r=i;
- }
- // printf("n=%lld\n",n);
- for(ll i=1,a,b,c;i<=n-1;++i){
- scanf("%lld%lld%lld",&a,&b,&c);
- add(a,b,c),add(b,a,c);
- }
- dfs(1,0,0);
- f[1][0]=1;
- for(ll j=1;j<=t;j++)
- for(ll i=1;i<=n;i++)
- f[i][j]=f[f[i][j-1]][j-1];
- sort(v+1,v+n+1);
- for(ll i=1;i<=n;i++){
- ll x=v[i].id,val=v[i].v;
- for(ll j=head[x];j;j=nxt[j]){
- ll y=ver[j];
- if(va[y]>=va[x]){
- merge(x,y,edg[j],x);
- }
- }
- }
- printf("%lld\n",ans);
- }
- }
csp-s模拟测试41「夜莺与玫瑰·玫瑰花精·影子」的更多相关文章
- NOIP模拟测试2「排列 (搜索)·APIO划艇」
排序 内存限制:128 MiB 时间限制:1000 ms 标准输入输出 题目描述 输入格式 数据范围与提示 对于30%的数据,1<=N<=4: 对于全部的数据,1<=N< ...
- NOIP模拟测试19「count·dinner·chess」
反思: 我考得最炸的一次 怎么说呢?简单的两个题0分,稍难(我还不敢说难,肯定又有人喷我)42分 前10分钟看T1,不会,觉得不可做,完全不可做,把它跳了 最后10分钟看T1,发现一个有点用的性质,仍 ...
- [考试反思]0909csp-s模拟测试41:反典
说在前面:我是反面典型!!!不要学我!!! 说在前面:向rank1某脸学习,不管是什么题都在考试反思后面稍微写一下题解. 这次是真的真的运气好... 这次知识点上还可以,但是答题策略出了问题... 幸 ...
- [CSP-S模拟测试41]题解
中间咕的几次考试就先咕着吧…… A.夜莺与玫瑰 枚举斜率.只考虑斜率为正且不平行于坐标轴的直线,最后把$ans\times 2$再$+1$即可. 首先肯定需要用$gcd(i,j)==1$确保斜率的唯一 ...
- csp-s模拟测试44「D·E·F」
用心出题,用脚造数据 乱搞场 1 #include<bits/stdc++.h> 2 #define re register 3 #define int long long 4 #defi ...
- NOIP模拟测试30「return·one·magic」
magic 题解 首先原式指数肯定会爆$long$ $long$ 首先根据欧拉定理我们可以将原式换成$N^{\sum\limits_{i=1}^{i<=N} [gcd(i,N)==1] C_{G ...
- NOIP模拟测试21「折纸·不等式」
折纸 题解 考试时无限接近正解,然而最终也只是接近而已了 考虑模拟会爆炸,拿手折纸条试一试,很简单 考你动手能力 代码 #include<bits/stdc++.h> using name ...
- NOIP模拟测试18「引子·可爱宝贝精灵·相互再归的鹅妈妈」
待补 引子 题解 大模拟,注意细节 代码1 #include<bits/stdc++.h> using namespace std; int n,m;char a[1005][1005]; ...
- NOIP模拟测试10「大佬·辣鸡·模板」
大佬 显然假期望 我奇思妙想出了一个式子$f[i]=f[i-1]+\sum\limits_{j=1}^{j<=m} C_{k \times j}^{k}\times w[j]$ 然后一想不对得容 ...
随机推荐
- 多种方法实现实现全排列 + sort调用标准函数库函数的简述
全排列:所有不同顺序的元素组组成的一个集合.这里使用使用递归实现全排列. 使用递归算算法呢,首先我们先找一下结束的条件:我们要对一组元素(这里使用数字举例)实现全排列,临界条件就是递归到只有一个元素的 ...
- JS数组的操作方法汇总
数组的增删 push():添加到最后 pop():取出最后一个 shift():取出第一个 unshift():添加到第一个 splice() : 返回删除的数组,如果没有则为空数组,会改变原数组.可 ...
- 三分钟了解B2B CRM系统的特点
最近很多朋友想了解什么是B2B CRM系统,说到这里小Z先来给大家说说什么是B2B--B2B原本写作B to B,是Business-to-Business的缩写.正常来说就是企业与企业之间的生意往来 ...
- [MySQL数据库之数据库相关概念、MySQL下载安装、MySQL软件基本管理、SQL语句]
[MySQL数据库之数据库相关概念.MySQL下载安装.MySQL软件基本管理.SQL语句] 数据库相关概念 数据库管理软件的由来 数据库管理软件:本质就是个C/S架构的套接字程序. 我们在编写任何程 ...
- 『动善时』JMeter基础 — 20、JMeter配置元件【HTTP Cookie管理器】详细介绍
目录 1.HTTP Cookie管理器介绍 2.HTTP Cookie管理器界面详解 3.JMeter中对Cookie的管理 (1)Cookie的存储 (2)Cookie的管理策略 4.补充:Cook ...
- ES6对象的新增方法的使用
Object.assign Object Object.assign(target, ...sources) 将所有可枚举属性的值从一个或多个源对象复制到目标对象 参数: target 目标对象 so ...
- prometheus nginx-module-vts删除内存区数据
项目地址:https://github.com/vozlt/nginx-module-vts 删除所zone内存中的数据 curl localhost/status/control?cmd=delet ...
- date命令月日时分年
# date +%Y/%m/%d2019/09/29[root@a-3e5 lpts-20190910-keyan-v0.2]# date +%H:%M20:00
- Linux 用 ps 與 top 指令找出最耗費 CPU 與記憶體資源的程式最占cpu的进程
Linux 用 ps 與 top 指令找出最耗費 CPU 與記憶體資源的程式 2016/12/220 Comments ######### ps -eo pid,ppid,%mem,%cpu,cmd ...
- 【转载】 Linux常用命令: zip、unzip 压缩和解压缩命令
Linux常用命令: zip.unzip 压缩和解压缩命令 Linux常用命令: zip.unzip 压缩和解压缩命令 zip的用法 基本用法是: zip [参数] [打包后的文件名] [打包的目 ...