linux内存源码分析 - 页表的初始化
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/
本文章中系统我们假设为x86下的32位系统,暂且不分析64位系统的页表结构。
linux分页
linux下采用四级分页,一个线性地址会分为5个偏移量用于寻址,具体看图:
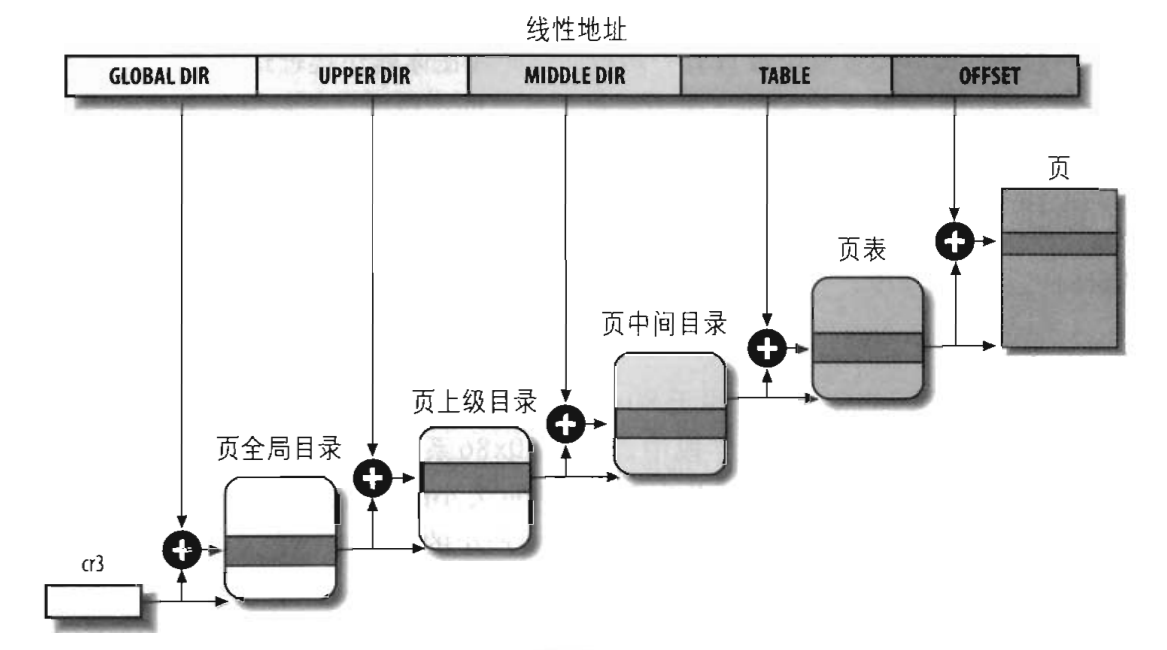
虽然有四级,但并不是每一级都会用到,在linux中,对于硬件体系的不同可能会用到二级页表,三级页表,四级页表中的其中一个,如下:
- 64位系统:使用四级分页或三级分页,跟硬件有关。
- 未开启PAE(物理地址扩展)的32位系统:只使用二级分页,页上级目录和页中间目录里的值全为0。
- 开启PAE的32位系统:使用三级分页,这种情况下被排除在外的是页上级目录,也就是页上级目录中所有值都为0。
图中有个cr3,它是一个寄存器,专门用于保存页全局目录的基地址,内核的主内核页全局目录的基地址保存在swapper_pg_dir全局变量中,但需要使用主内核页表时系统会把这个变量的值放入cr3寄存器,进程们自己的页全局目录基地址保存在自己的进程描述符的pgd中,当进程切换时,进程的页表也是需要切换的,就是把新的进程的进程描述符的pgd存入cr3中。这些目录和页表每一个都是用一个页框进行保存,比如一个进程有一个页全局目录,1024个页中间目录,1024个页表,那系统要为这个进程分配1个页框用于保存页全局目录,1024个页框用于保存页中间目录,1024个页框用于保存页表。当然,进程一般情况下是不会需要这么多页中间目录和页表的。
表项
实际上页全局目录、页上级目录、页中间目录、页表都是保存在一个一个页框中,我们知道常规情况下页框大小为4K(特殊情况有2MB、1GB),也就是页框的布局都是以4K倍数的地址进行排列的,要寻址一个页框,只需要20位地址就足够了。这些目录和页表中保存的都是表项,页全局目录保存的是页全局目录项,页中间目录保存的是页中间目录项,在32位系统中这些项都是32位(20位是所指页框的基地址,12位是标志位)的,在开启PAE后会变成64位,这些项保存着很多标志,我们罗列几个重要的:
- Present标志:为1,所指的页在内存中,为0,不在。
- 所指的页框基地址:占20位。
- Accessed标志:每当分页单元对相应页框进行寻址时设置。
- Dirty标志:只用于页表项,每次对一个页框进行写操作时设置。
- Read/Write标志:读写权限标志。
- User/Supervisor标志:所指的页的特权级(进程能否访问)。
- Page size标志:为1表示指的是2MB或4MB的页框。也就是页表是2MB或者4MB。
在这些里面,最重要的或许就是所指页框基地址了,一个页中间目录项保存的页框基地址就是对应的页表的基地址,而页表项中保存的页框基地址,就是页(用于保存数据)的地址。而Present标志是用于判断是否发生缺页异常处理的标志。由于这些标志加上所指的页框基地址一共32位,一个4K的页框就能够保存1024个表项。
物理地址扩展(PAE)
这个技术是用于X86_32位体系下的,因为32位线性地址最多能表示4GB大小的空间,而PAE技术将物理地址线扩大到36条,也就是CPU能够寻址64GB大小的物理内存。但是物理地址线扩大到36条,但是线性地址还是使用32位,这时候没办法用32位的线性地址去表示64GB大小的物理内存。实际上PAE做的就是让内核有多个“主内核页全局目录”,第一个主内核页全局目录寻址0~4GB的地址,第二个寻址5~8GB的地址,所以当寻址不同区域的地址时,只需要将不同的“主内核页全局目录”基地址存入cr3中。这些多个主内核页全局目录被称为页目录指针表(PDPT)。
开启PAE后,32位系统寻址方式将大大改变:
- 二级分页会变成三级分页
- 表项的大小也由原来的32位变成了64位(原来是12位标志+20位页框基地址,变成12位标志+24位页框基地址,为什么是24位,因为64GB需要24位才能寻址完所有页框)。
- 页框大小将可选择4K或者2MB,通过修改表项中的Page size标志即可指定所指页框大小。
- 线性地址表示也变成如下:



内核启动后内核区域内存布局
一般的,内核启动会被加载到内存的1MB开始处,而普通配置的内核大小一般小于3MB,也就是说,内核镜像被加载内存1MB~4MB的地方,而为什么0MB~1MB的内存内核不使用,因为这段内存一般是由BIOS使用和做一些硬件映射的。如下图:

在里面我们值得注意的就是_end,它在代码里表明了内核镜像在内存中的结束地址,页表的初始化会先初始化未被内核使用的区域,最后再初始化内核使用的区域。
高端内存布局
之前的文章linux内存管理源码分析 - 页框分配器中有简单地描述了高端内存区,在内核的虚拟地址空间的高端内存区中又分为三个区,分别是:非连续内存区、永久内核映射区、固定映射区。
- 非连续内存区是为系统硬件中断处理和内核模块生产空间一次性准备用的。
- 永久映射区是给系统底层空间分区和硬件及驱动准备的。
- 固定映射区是为用户配置和应用软件运行提供可用空间准备的。
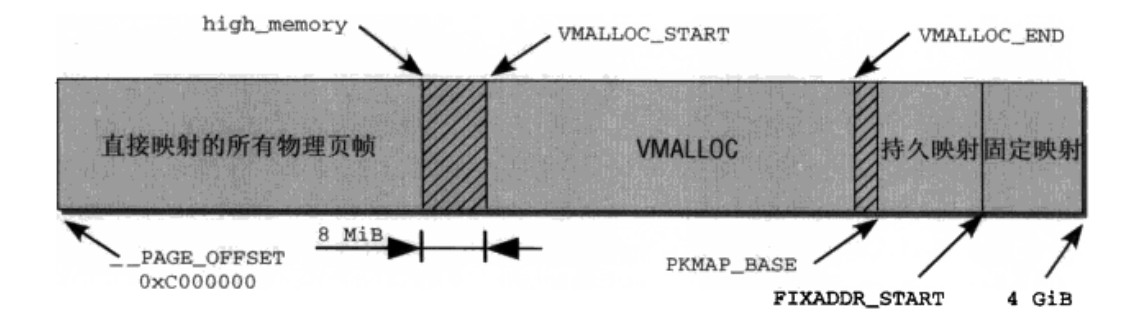
在图中,high_memory是高端内存区(ZONE_HIGHMEM)起始地址,VMALLOC是非连续内存区。
在内核中,永久内核映射区和固定映射区大小一般都为4MB,也就是分别用一个页表可以囊括其所包含地址范围,其他都给非连续内存区使用。不过如果物理内存大小小于896MB的情况下,内核并不会生成高端内存区,只会有ZONE_DMA和ZONE_NORMAL两个区。
我们知道,内核可使用的线性地址就只有1G大小(0xC0000000 ~ 0xFFFFFFFF),而用于ZONE_DMA和ZONE_NORMAL这两个区的映射已经花掉了896MB的线性地址空间,最后只剩下128MB用于映射高端内存,如果内存大于1G,比如2G的情况下,高端内存区大小就为1152MB,这个128MB大小的线性地址空间是完全不够直接映射高端内存的,所以对于高端内存的处理,linux并不会直接映射,而是在需要的时候才进行映射,不需要的时候就释放映射,回收线性地址。
在初始化页表时,会对永久内核映射区和固定映射区分别进行初始化,但是都不会对他们进行映射处理,只有在需要使用时才会分配。

临时内核页表
临时内核页全局目录是在内核编译过程中静态初始化的,临时页表是由startup_32()汇编函数进行初始化的,这个临时页表专门用于系统启动阶段,也就是系统第一个使用的页表,它只能让系统寻址0~8MB这段区间的物理内存,之后会被初始化好的完整页表代替。这个临时页表主要的工作就是让系统能够在实模式(不开启分页)和保护模式(开启分页)下都能够对内存的前8MB进行寻址。也就是将地址0x00000000到0x007fffff这个区间的线性地址和0xC0000000到0xC07fffff这个区间的线性地址映射到物理地址0x00000000到0x007fffff。其实做法也很简单,就是将临时内核页全局目录的0x0、0x1、0x301、0x302项初始化好就行了。为什么是这几项,我们简单说明一下,在实模式下,也就是没有开启分页的情况下,线性地址0x00000000对应的物理地址就是0x00000000,而0x00000000到0x007fffff这个区间的线性地址就包含在页全局目录的0x0和0x1项中。同理,0xC0000000到0xC07fffff通过掩码获得的页全局目录项就是0x301和0x302。
源码
在阅读源码之前,我们必须对一些全局变量进行说明:
- swapper_pg_dir:主内核页全局目录指针,cr3寄存器中保存的内核页全局目录地址就是从这个变量而来。
- max_pfn:物理内存中最后一个页框号。
- max_low_pfn:低端内存中最后一个页框号。
对于页表的初始化,内核有一个优先级顺序,低端内存(物理内存中保留的前1MB) ->低端内存(内核未使用部分) -> 低端内存(内核使用部分) -> 高端内存(固定映射区) -> 高端内存(永久内核映射区)。
首先,对于低端内存区域的页表初始化和高端内存固定映射区页表的初始化都集中在init_mem_mapping(void)函数中,这个函数在start_kernel() -> setup_arch()中:
void __init init_mem_mapping(void)
{
unsigned long end; /* 设置了page_size_mask全局变量,这个变量决定了系统中有多少种页框大小(4K,2M,1G) */
/* 1G大小的页框只存在于64位系统中
* 4K大小的页框是普通的页框
* 2M大小的页框是32位内核开启了PAE后可选择页大小为2M
*/
probe_page_size_mask(); /* max_pfn 和 max_low_pfn 都是由BIOS提供获取 */
#ifdef CONFIG_X86_64 /* 64位没有高端内存区 */
end = max_pfn << PAGE_SHIFT;
#else
end = max_low_pfn << PAGE_SHIFT;
#endif /* end为低端内存(ZONE_MDA和ZONE_NORMAL)的最大页框号 */ /* the ISA range is always mapped regardless of memory holes */
/* 0 ~ 1MB,一般内核启动时被安装在1MB开始处
* 这里先初始化 0 ~ 1MB的物理地址
*/
init_memory_mapping(, ISA_END_ADDRESS); if (memblock_bottom_up()) {
/* 内核启动阶段使用的内存的结束地址,内核启动时一般使用物理内存 1MB ~ 4MB 的区域 */
unsigned long kernel_end = __pa_symbol(_end); /* 先映射 内核结束地址 ~ ZONE_NORMAL结束地址 这块物理地址区域,如果是64位,则直接初始化到最后的内存页框,因为64位没有高端内存区 */
memory_map_bottom_up(kernel_end, end);
/* 再映射 1MB ~ 内核结束地址 这块物理地址区域 */
memory_map_bottom_up(ISA_END_ADDRESS, kernel_end);
} else {
memory_map_top_down(ISA_END_ADDRESS, end);
} #ifdef CONFIG_X86_64
if (max_pfn > max_low_pfn) {
/* can we preseve max_low_pfn ?*/
max_low_pfn = max_pfn;
}
#else
/* 高端内存区的固定映射区的初始化,只初始化好了页中间目录项和页表,页表项并没初始化 */
early_ioremap_page_table_range_init();
#endif
/* 将初始化好的内核页全局目录地址写入cr3寄存器 */
load_cr3(swapper_pg_dir);
/* 刷新tlb,每次修改了页表都需要刷新一下,有兴趣的可以查查为什么 */
__flush_tlb_all(); /* 检查一下是否有问题 */
early_memtest(, max_pfn_mapped << PAGE_SHIFT);
}
在这个函数的注释中写得很清楚了,我们先看init_memory_mapping()。
init_memory_mapping(0, ISA_END_ADDRESS)
/* 内核将start ~ end 这段物理地址映射到线性地址上,这个函数仅会映射低端内存区(ZONE_DMA和ZONE_NORMAL),线性地址0xC0000000 对应的物理地址是 0x00000000 */
unsigned long __init_refok init_memory_mapping(unsigned long start,
unsigned long end)
{
/* 用于保存内存段信息,每个段的页框大小不同,可能有4K,2M,1G三种 */
struct map_range mr[NR_RANGE_MR];
unsigned long ret = ;
int nr_range, i; pr_info("init_memory_mapping: [mem %#010lx-%#010lx]\n",
start, end - ); /* 清空mr */
memset(mr, , sizeof(mr)); /*
* 根据start和end设置mr数组,并返回个数
*/
nr_range = split_mem_range(mr, , start, end); /* 遍历整个mr,将所有内存段的页框进行映射,就是将页框地址写入对应的页表中,返回的是最后映射的地址 */
for (i = ; i < nr_range; i++)
ret = kernel_physical_mapping_init(mr[i].start, mr[i].end,
mr[i].page_size_mask); /* 调整页框映射的设置,和map_range类似,只是map_range是线性地址的映射数据,这里面是页框映射的数据 */
add_pfn_range_mapped(start >> PAGE_SHIFT, ret >> PAGE_SHIFT); /* 返回最后映射的页框号 */
return ret >> PAGE_SHIFT;
}
继续看split_mem_range()函数
/* 这个函数会根据页的大小(4K,2M,1G)建立不同的内存段,1G大小的页框只会在64位系统下使用 */
static int __meminit split_mem_range(struct map_range *mr, int nr_range,
unsigned long start,
unsigned long end)
{
unsigned long start_pfn, end_pfn, limit_pfn;
unsigned long pfn;
int i; /* 获取物理地址end的所在页框号 */
limit_pfn = PFN_DOWN(end); /* head if not big page alignment ? */
/* 物理地址start所在页框,初始化阶段此值为0 */
pfn = start_pfn = PFN_DOWN(start); /* 这一部分建立了一个页框大小为4K的内存段(mr) */
#ifdef CONFIG_X86_32
/*
* PMD_SIZE保存页中间目录可映射区域的大小
* PAE禁用: 4M
* PAE激活: 2M
*/
if (pfn == )
/* 如果pfn为0,也就是开始页框号是0,那结束页框号就是4M或者2M */
end_pfn = PFN_DOWN(PMD_SIZE);
else
/* 如果pfn不为0,以pfn开始(包括pfn),向上找到下一个是PMD_SIZE倍数的页框号 */
end_pfn = round_up(pfn, PFN_DOWN(PMD_SIZE)); /* 以下数值都是二进制表示
* round_up(x,y): x: 11010010 y: 1000 结果; 11011000
* round_up(x,y): x: 11011010 y: 1000 结果: 11100000
*
* round_down(x,y): x: 11010010 y: 1000 结果: 11010000
* round_down(x,1) x: 11011010 y: 1000 结果: 11011000
*
*/
#else /* CONFIG_X86_64 */
/* 以pfn开始(包括pfn),向上找到下一个是PMD_SIZE倍数的页框号 */
end_pfn = round_up(pfn, PFN_DOWN(PMD_SIZE));
#endif
/* 如果结束页框号超过了end所在页框号,那就选取end所在页框号为结束页框 */
if (end_pfn > limit_pfn)
end_pfn = limit_pfn;
/* 第一个内存段的页框大小为一个PMD_SIZE的大小,4M或者2M */
if (start_pfn < end_pfn) {
/*
* mr[nr_range].start = start_pfn<<PAGE_SHIFT;
* mr[nr_range].end = end_pfn<<PAGE_SHIFT;
* mr[nr_range].page_size_mask = 0;
* nr_range++;
*/
nr_range = save_mr(mr, nr_range, start_pfn, end_pfn, );
/* pfn等于结束页框号,下个区创建时就会以这个pfn作为起始页框号*/
pfn = end_pfn;
} /* 第二个区域,创建大小为2M的页框内存段,32位下2M的页框只有在PAE开启的情况下才会有,这个区不是一定会有的(有的条件是 32位系统 && PAE启动 && 开启2M大小页框) */
/* 以pfn开始(包括pfn),向上找到下一个是PMD_SIZE倍数的页框号,这里的情况结果一般都是 start_pfn = pfn */
start_pfn = round_up(pfn, PFN_DOWN(PMD_SIZE)); #ifdef CONFIG_X86_32
/* X86_32位下的处理 */
/* 以limit_pfn开始(包括limit_pfn),向下找到上一个是PMD_SIZE倍数的页框号,这样就有可能有第三个段,有可能没有 */
end_pfn = round_down(limit_pfn, PFN_DOWN(PMD_SIZE)); #else /* CONFIG_X86_64 */
/* X86_64位下的处理 */
/* 以pfn开始(包括pfn),向上找到下一个是PUD_SIZE倍数的页框号 */
end_pfn = round_up(pfn, PFN_DOWN(PUD_SIZE));
if (end_pfn > round_down(limit_pfn, PFN_DOWN(PMD_SIZE)))
end_pfn = round_down(limit_pfn, PFN_DOWN(PMD_SIZE));
#endif if (start_pfn < end_pfn) {
nr_range = save_mr(mr, nr_range, start_pfn, end_pfn,
page_size_mask & (<<PG_LEVEL_2M));
pfn = end_pfn;
} /* X64下会建立一个区域页框大小为1G的,32位下不会有 */
#ifdef CONFIG_X86_64
start_pfn = round_up(pfn, PFN_DOWN(PUD_SIZE));
end_pfn = round_down(limit_pfn, PFN_DOWN(PUD_SIZE));
if (start_pfn < end_pfn) {
/*
* mr[nr_range].start = start_pfn<<PAGE_SHIFT;
* mr[nr_range].end = end_pfn<<PAGE_SHIFT;
* mr[nr_range].page_size_mask = page_size_mask & ((1<<PG_LEVEL_2M)|(1<<PG_LEVEL_1G)));
* nr_range++;
*/
nr_range = save_mr(mr, nr_range, start_pfn, end_pfn,
page_size_mask &
((<<PG_LEVEL_2M)|(<<PG_LEVEL_1G)));
pfn = end_pfn;
} start_pfn = round_up(pfn, PFN_DOWN(PMD_SIZE));
end_pfn = round_down(limit_pfn, PFN_DOWN(PMD_SIZE));
if (start_pfn < end_pfn) {
nr_range = save_mr(mr, nr_range, start_pfn, end_pfn,
page_size_mask & (<<PG_LEVEL_2M));
pfn = end_pfn;
}
#endif /* 将剩余所有的页框作为一个新的4K大小页框的内存段 */
start_pfn = pfn;
end_pfn = limit_pfn;
nr_range = save_mr(mr, nr_range, start_pfn, end_pfn, ); /* 如果使用的是bootmem分配器的情况下会调整一下几个段的起始页框和结束页框 */
if (!after_bootmem)
adjust_range_page_size_mask(mr, nr_range); /* 将相邻两个页框大小相等的区合并 */
for (i = ; nr_range > && i < nr_range - ; i++) {
unsigned long old_start;
if (mr[i].end != mr[i+].start ||
mr[i].page_size_mask != mr[i+].page_size_mask)
continue; /* 前一个区的结束页框等于后一个区的开始页框,并且区中页框大小相等的情况下,合并 */
old_start = mr[i].start;
memmove(&mr[i], &mr[i+],
(nr_range - - i) * sizeof(struct map_range));
mr[i--].start = old_start;
nr_range--;
} /* 打印信息 */
for (i = ; i < nr_range; i++)
printk(KERN_DEBUG " [mem %#010lx-%#010lx] page %s\n",
mr[i].start, mr[i].end - ,
(mr[i].page_size_mask & (<<PG_LEVEL_1G))?"1G":(
(mr[i].page_size_mask & (<<PG_LEVEL_2M))?"2M":"4k")); /* 返回内存段的数量 */
return nr_range;
}
可以看出内存段的数量跟init_mem_mapping()函数中的probe_page_size_mask()函数有很大关系,其实简单说就是将不同大小的页框分成一段一段的。
将页框大小以大小分段后,调用了kernel_physical_mapping_init(),这个函数就是用于做映射了,它会直接修改页表达到映射目的。
/* 将内核的物理地址start到end映射到线性地址上,page_size_mask是页大小,分别有4K,2MB,1G三种大小
* start和end都是物理地址
*/
unsigned long __init
kernel_physical_mapping_init(unsigned long start,
unsigned long end,
unsigned long page_size_mask)
{
int use_pse = page_size_mask == (<<PG_LEVEL_2M);
unsigned long last_map_addr = end;
unsigned long start_pfn, end_pfn;
pgd_t *pgd_base = swapper_pg_dir;
int pgd_idx, pmd_idx, pte_ofs;
unsigned long pfn;
pgd_t *pgd;
pmd_t *pmd;
pte_t *pte;
unsigned pages_2m, pages_4k;
int mapping_iter; /* 根据start获取其对应的页框号,由于页大小为4KB,所以在地址里占用12位,其余的就是页框号了,这里就是start右移12位 */
start_pfn = start >> PAGE_SHIFT;
/* 根据end获取其对应的页框号 */
end_pfn = end >> PAGE_SHIFT; /* 设置为1,表示此时是第一次迭代。在这个函数中需要进行两次迭代,这两次迭代不同的就是设置的表项属性不同 */
mapping_iter = ; if (!cpu_has_pse)
use_pse = ; repeat:
pages_2m = pages_4k = ; /* 等于start地址对应的页框号 */
pfn = start_pfn;
/* 根据页框号pfn获取此页框在页全局目录(pgd)项中的偏移量(pgd_idx),注意后面加了个PAGE_OFFSET(0xC0000000),所以这就会让线性地址0xC0000000与物理地址0x00000000相应 */
pgd_idx = pgd_index((pfn<<PAGE_SHIFT) + PAGE_OFFSET);
/* 指向该页全局目录项,如果pfn为0 */
pgd = pgd_base + pgd_idx; /*
* 这里会从pgd的第pgd_idx项向后遍历所有的页全局目录项,直到页框号pfn大于end_pfn为止
* 这里就会将start到end这段线性地址中所有页框对应的页表项都遍历了一遍
*/
for (; pgd_idx < PTRS_PER_PGD; pgd++, pgd_idx++) { /* 根据页全局目录项获取页中间目录所在页地址 */
pmd = one_md_table_init(pgd); if (pfn >= end_pfn)
continue;
#ifdef CONFIG_X86_PAE
/* 根据页框对应的线性地址获取相应的页中间目录项pmd偏移量 */
pmd_idx = pmd_index((pfn<<PAGE_SHIFT) + PAGE_OFFSET);
pmd += pmd_idx;
#else
/* 在32位未开启PAE的情况下,pmd是空的 */
pmd_idx = ;
#endif
/* PTRS_PER_PMD代表一个页中间目录有多少项,对于没有启动物理地址扩展的32系统下,其项数为1,其他情况下为512项 */
for (; pmd_idx < PTRS_PER_PMD && pfn < end_pfn;
pmd++, pmd_idx++) {
/* 获取页框号pfn对应的物理地址 */
unsigned int addr = pfn * PAGE_SIZE + PAGE_OFFSET; /* 如果使用了PSE,则页框大小会变成4MB,但是这里却是用pages_2m来保存,2MB大小的页框应该是PAE技术使用的,并不是PSE,这里不太明白,可能PAE代替了PSE */
if (use_pse) { unsigned int addr2; /* prot设置为PAGE_KERNEL_LARGE,这个值只有在第二次迭代时才会有效 */
pgprot_t prot = PAGE_KERNEL_LARGE; /* init_prot是第一次迭代时会设置到对应的页表项中 */
pgprot_t init_prot =
__pgprot(PTE_IDENT_ATTR |
_PAGE_PSE); pfn &= PMD_MASK >> PAGE_SHIFT;
addr2 = (pfn + PTRS_PER_PTE-) * PAGE_SIZE +
PAGE_OFFSET + PAGE_SIZE-; /* 检查地址是否处于内核启动所占用的内存区域 */
if (is_kernel_text(addr) ||
is_kernel_text(addr2))
prot = PAGE_KERNEL_LARGE_EXEC; /* 2MB大小的页框计数器 */
pages_2m++; /* 设置页表项为此页框,pfn_pte直接将页框号(pfn)强制转换为物理地址,而我们也知道pfn有start屏蔽页大小占用的位数得来,这里也就实现了直接映射(0xC0000000 映射到 0x00000000) */
/* 注意第一次迭代传入的是init_prot,第二次是prot */
if (mapping_iter == )
set_pmd(pmd, pfn_pmd(pfn, init_prot));
else
set_pmd(pmd, pfn_pmd(pfn, prot)); pfn += PTRS_PER_PTE;
continue;
} /*
* 以下是建立普通大小的页表(4K)
*/ /* 根据页中间目录项获取页表 */
pte = one_page_table_init(pmd); /* 根据页框号获取页表项的偏移量 */
pte_ofs = pte_index((pfn<<PAGE_SHIFT) + PAGE_OFFSET);
/* 根据页表和页表项的偏移量获取到该pfn对应的页框的页表项 */
pte += pte_ofs;
for (; pte_ofs < PTRS_PER_PTE && pfn < end_pfn;
pte++, pfn++, pte_ofs++, addr += PAGE_SIZE) {
/* 遍历此此页表中当前页表项及其之后的所有页表项 */ /* pgprot_t是一个64位(PAE开启)或32位(PAE禁止)的数据类型,表示这个页的保护标志 */
/* 这个值会在第二次迭代时设置到页框号对应的页表项中 */
pgprot_t prot = PAGE_KERNEL; /* 初始化这个页的pgprot_t,这个是第一遍迭代时会设置到页表项中 */
pgprot_t init_prot = __pgprot(PTE_IDENT_ATTR); /* 如果该页框保存着系统的代码,则设置其标志PAGE_KERNEL_EXEC */
if (is_kernel_text(addr))
prot = PAGE_KERNEL_EXEC; /* 4KB大小的页框计数器 */
pages_4k++; if (mapping_iter == ) {
/* 设置页表项为此页框,pfn_pte直接将页框号(pfn)强制转换为物理地址,而我们也知道pfn有start屏蔽页大小占用的位数得来,这里也就实现了直接映射(0xC0000000 映射到 0x00000000) */
set_pte(pte, pfn_pte(pfn, init_prot));
/* last_map_addr保存最近映射的地址,就是我们刚映射完的页框地址 */
last_map_addr = (pfn << PAGE_SHIFT) + PAGE_SIZE;
} else
/* 第二次迭代时调用到,传入prot */
set_pte(pte, pfn_pte(pfn, prot));
}
}
}
if (mapping_iter == ) {
/* direct_pages_count[PG_LEVEL_2M] += pages_2m; 这里是做个统计 */
update_page_count(PG_LEVEL_2M, pages_2m);
/* direct_pages_count[PG_LEVEL_4K] += pages_4k; 这里也是做个统计 */
update_page_count(PG_LEVEL_4K, pages_4k); /* 刷新一下tlb,内核页表改变了都要刷新一次tlb */
__flush_tlb_all(); /* 准备开始第二次迭代,第一次迭代设置到页表项中的pgprot_t为init_prot变量,第二次迭代设置到页表项中的是prot变量,它们的值是不同的 */
mapping_iter = ;
/* 开始第二次迭代 */
goto repeat;
}
/* 最后一次映射的地址(物理地址) */
return last_map_addr;
}
看完这里,应该很清楚低端内存是如何直接映射的了。
回到init_mem_mapping()函数,上面分析的init_memory_mapping(0, ISA_END_ADDRESS)函数只映射了0MB ~ 1MB的物理内存,之后在memory_map_bottom_up()中映射低端内存区中剩余的其他物理内存,首先先映射内核结束地址 ~ ZONE_NORMAL最后一个页框所在地址,然后再映射1MB ~ 内核结束地址。如果没有高端内存的情况下,则直接一次映射1MB ~ 结束地址。这个过程结束后,所有低端内存区就已经直接映射完毕了。
我们主要看看memory_map_bottom_up()的实现。
memory_map_bottom_up(map_start, map_end)
/* 将物理地址map_start ~ map_end 映射到内核区域 */
static void __init memory_map_bottom_up(unsigned long map_start,
unsigned long map_end)
{
unsigned long next, new_mapped_ram_size, start;
unsigned long mapped_ram_size = ;
/* step_size need to be small so pgt_buf from BRK could cover it */
unsigned long step_size = PMD_SIZE; start = map_start;
/* 开始页框号 */
min_pfn_mapped = start >> PAGE_SHIFT; while (start < map_end) {
if (map_end - start > step_size) { /* 向上找到下一个step_size倍数的页框号 */
next = round_up(start + , step_size);
if (next > map_end)
next = map_end;
} else
next = map_end;
/* 内核将 start ~ next 这段物理地址经过修正后映射到线性地址上,最后返回映射的大小 */
new_mapped_ram_size = init_range_memory_mapping(start, next);
/* 下一个setp_size倍数的页框号 */
start = next; /* 映射成功后,new_mapped_ram_size必定会大于mapped_ram_size(这个初始化是0),会将setp_size << 5,也就是下次一次会映射更多的页框 */
if (new_mapped_ram_size > mapped_ram_size)
step_size = get_new_step_size(step_size);
/* 统计已映射内存大小 */
mapped_ram_size += new_mapped_ram_size;
}
}
核心在init_range_memory_mapping()中
/* 内核将start ~ end 这段物理地址映射到线性地址上 */
static unsigned long __init init_range_memory_mapping(
unsigned long r_start,
unsigned long r_end)
{
unsigned long start_pfn, end_pfn;
unsigned long mapped_ram_size = ;
int i; /* 遍历每一个结点的页框段,与memblock_region和NUMA有关,还没研究 */
for_each_mem_pfn_range(i, MAX_NUMNODES, &start_pfn, &end_pfn, NULL) {
/* start_pfn, r_start, r_end中处于中间的那个数 */
u64 start = clamp_val(PFN_PHYS(start_pfn), r_start, r_end);
/* 同上 */
u64 end = clamp_val(PFN_PHYS(end_pfn), r_start, r_end);
if (start >= end)
continue; /*
* if it is overlapping with brk pgt, we need to
* alloc pgt buf from memblock instead.
*/
can_use_brk_pgt = max(start, (u64)pgt_buf_end<<PAGE_SHIFT) >=
min(end, (u64)pgt_buf_top<<PAGE_SHIFT);
/* 又调用到init_memory_mapping,将start ~ end 这段物理地址映射到线性地址上 */
init_memory_mapping(start, end);
mapped_ram_size += end - start;
can_use_brk_pgt = true;
} return mapped_ram_size;
}
最后又是调用到init_memory_mapping函数进行页表的修改,这里就不再次说明了。
整个memory_map_bottom_up()函数也说明完了,其实最后也是调用到init_memory_mapping()进行页表的修改,到这里,整个低端内存的页表初始化相信也没什么大的问题了。
高端内存(ZONE_HIGHMEM)固定映射区页表初始化
固定映射区的页表初始化也是在init_mem_mapping(void)函数中进行,它的初始化是在低端内存区初始化结束之后,调用early_ioremap_page_table_range_init()进行初始化的。具体看看:
/* 固定映射区的初始化,只初始化好了页中间目录项和页表,页表项并没初始化 */
void __init early_ioremap_page_table_range_init(void)
{
pgd_t *pgd_base = swapper_pg_dir;
unsigned long vaddr, end; /* 固定映射区开始地址 */
vaddr = __fix_to_virt(__end_of_fixed_addresses - ) & PMD_MASK;
/* 固定映射区结束地址 */
end = (FIXADDR_TOP + PMD_SIZE - ) & PMD_MASK;
/* 初始化内核的页全局目录中vaddr到end这个范围的线性地址 */
page_table_range_init(vaddr, end, pgd_base);
/* 重新启动一下固定映射区 */
early_ioremap_reset();
}
page_table_range_init(vaddr, end, pgd_base)
核心函数,初始化对应的页表,但是页表项并不会初始化。
/* 初始化pgd_base指向的页全局目录中start到end这个范围的线性地址,整个函数结束后只是初始化好了页中间目录项对应的页表,但是页表中的页表项并没有初始化 */
static void __init
page_table_range_init(unsigned long start, unsigned long end, pgd_t *pgd_base)
{
int pgd_idx, pmd_idx;
unsigned long vaddr;
pgd_t *pgd;
pmd_t *pmd;
pte_t *pte = NULL;
/* 计算start到end这段线性地址区域所使用的页表数,见后面 */
unsigned long count = page_table_range_init_count(start, end);
void *adr = NULL; /* 为这些页表分配连续物理页框 */
if (count)
adr = alloc_low_pages(count); vaddr = start;
/* 找到vaddr线性地址对应的页全局目录中的偏移量 */
pgd_idx = pgd_index(vaddr);
/* 找到vaddr线性地址对应的页中间目录中的偏移量 */
pmd_idx = pmd_index(vaddr);
pgd = pgd_base + pgd_idx; for ( ; (pgd_idx < PTRS_PER_PGD) && (vaddr != end); pgd++, pgd_idx++) {
/* 根据页全局目录项获取页中间目录所在页地址,见后面 */
pmd = one_md_table_init(pgd);
/* 获取页中间目录项 */
pmd = pmd + pmd_index(vaddr);
for (; (pmd_idx < PTRS_PER_PMD) && (vaddr != end);
pmd++, pmd_idx++) {
/* 初始化整个页中间目录项和页表,必要时会为不存在的页表分配页框,不过页表初始化后是空的,具体见后面 */
pte = page_table_kmap_check(one_page_table_init(pmd),
pmd, vaddr, pte, &adr); vaddr += PMD_SIZE;
}
pmd_idx = ;
}
} /* page_table_range_init_count */
/* 计算start到end这段线性地址区域所使用的页表数 */
static unsigned long __init
page_table_range_init_count(unsigned long start, unsigned long end)
{
unsigned long count = ;
#ifdef CONFIG_HIGHMEM
int pmd_idx_kmap_begin = fix_to_virt(FIX_KMAP_END) >> PMD_SHIFT;
int pmd_idx_kmap_end = fix_to_virt(FIX_KMAP_BEGIN) >> PMD_SHIFT;
int pgd_idx, pmd_idx;
unsigned long vaddr; if (pmd_idx_kmap_begin == pmd_idx_kmap_end)
return ; vaddr = start;
/* 根据线性地址vaddr,计算该地址所对应的页全局目录表项的偏移量 */
pgd_idx = pgd_index(vaddr); /* 计算使用的页表数量 */
for ( ; (pgd_idx < PTRS_PER_PGD) && (vaddr != end); pgd_idx++) {
for (; (pmd_idx < PTRS_PER_PMD) && (vaddr != end);
pmd_idx++) {
if ((vaddr >> PMD_SHIFT) >= pmd_idx_kmap_begin &&
(vaddr >> PMD_SHIFT) <= pmd_idx_kmap_end)
count++;
vaddr += PMD_SIZE;
}
pmd_idx = ;
}
#endif
return count;
} /* one_md_table_init */
/* 根据页全局目录项获取第一个页中间目录所在页地址,注意页上级目录(pud)在32位和一些64位下是为空的, */
static pmd_t * __init one_md_table_init(pgd_t *pgd)
{
pud_t *pud;
pmd_t *pmd_table; #ifdef CONFIG_X86_PAE
/* 32位下开启了PAE的情况,页上级目录是空的,但是页中间目录需要存在 */
if (!(pgd_val(*pgd) & _PAGE_PRESENT)) {
/* 如果该页中间目录不存在,这里会分配一个页框用于这个页中间目录 */
pmd_table = (pmd_t *)alloc_low_page();
paravirt_alloc_pmd(&init_mm, __pa(pmd_table) >> PAGE_SHIFT);
/* 设置页全局目录项的值为此新的页中间目录 */
set_pgd(pgd, __pgd(__pa(pmd_table) | _PAGE_PRESENT));
/* 检查是否设置成功,成功的情况下pud中获取的第一个pmd应该等于pmd_table */
pud = pud_offset(pgd, );
BUG_ON(pmd_table != pmd_offset(pud, )); return pmd_table;
}
#endif
/* 获取第一个页上级目录 */
pud = pud_offset(pgd, );
/* 获取页上级目录中第一个页中间目录 */
pmd_table = pmd_offset(pud, ); return pmd_table;
} /* page_table_kmap_check */
/* pte: 页表,页中间目录项pmd对应的页表
* pmd: 页中间目录项
* vaddr: 需要检查的线性地址
* lastpte: 上一个pte
* adr: 连续页框
*/
static pte_t *__init page_table_kmap_check(pte_t *pte, pmd_t *pmd,
unsigned long vaddr, pte_t *lastpte,
void **adr)
{
#ifdef CONFIG_HIGHMEM
/*
* Something (early fixmap) may already have put a pte
* page here, which causes the page table allocation
* to become nonlinear. Attempt to fix it, and if it
* is still nonlinear then we have to bug.
*/
/* 获取固定映射区域开始地址在页中间目录中的偏移量 */
int pmd_idx_kmap_begin = fix_to_virt(FIX_KMAP_END) >> PMD_SHIFT;
/* 获取固定映射区域结束地址在页中间目录中的偏移量 */
int pmd_idx_kmap_end = fix_to_virt(FIX_KMAP_BEGIN) >> PMD_SHIFT; if (pmd_idx_kmap_begin != pmd_idx_kmap_end
&& (vaddr >> PMD_SHIFT) >= pmd_idx_kmap_begin
&& (vaddr >> PMD_SHIFT) <= pmd_idx_kmap_end) { pte_t *newpte;
int i; /* 这个函数需要在释放掉bootmem分配器后使用 */
BUG_ON(after_bootmem);
newpte = *adr;
/* 将页表复制到adr的页框中 */
for (i = ; i < PTRS_PER_PTE; i++)
set_pte(newpte + i, pte[i]);
/* adr指向下一个页框 */
*adr = (void *)(((unsigned long)(*adr)) + PAGE_SIZE); paravirt_alloc_pte(&init_mm, __pa(newpte) >> PAGE_SHIFT);
/* 修改页中间目录项pmd让其对应的页表为newpte */
set_pmd(pmd, __pmd(__pa(newpte)|_PAGE_TABLE));
BUG_ON(newpte != pte_offset_kernel(pmd, ));
/* 刷新tlb */
__flush_tlb_all(); /* 释放掉pte对应的页表 */
paravirt_release_pte(__pa(pte) >> PAGE_SHIFT);
pte = newpte;
}
BUG_ON(vaddr < fix_to_virt(FIX_KMAP_BEGIN - )
&& vaddr > fix_to_virt(FIX_KMAP_END)
&& lastpte && lastpte + PTRS_PER_PTE != pte);
#endif
/* 返回初始化好的页表 */
return pte;
}
到这里整个固定映射区也初始化完成了。
高端内存永久内核映射区
这块区域是最后初始化的,而非连续内存区是在分配过程中进行初始化的。其整个过程与固定映射区初始化类似,最后也调用了page_table_range_init()进行初始化。
永久内核映射区初始化代码在native_pagetable_init() -> paging_init() -> pagetable_init() -> permanent_kmaps_init()中
/* 在pagetable_init中调用,pgd_base的地址是swapper_pg_dir,也就是页全局目录地址
* 这个函数初始化了高端内存区中的永久内核映射区,这个区只需要一个页表就可以概括整个区的线性地址,这个页表地址保存在 pkmap_page_table 变量中方便使用
*/
static void __init permanent_kmaps_init(pgd_t *pgd_base)
{
unsigned long vaddr;
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *pte; /* kmap/unkmap系统调用是用来映射高端物理内存页到内核地址空间的api函数
* 他们分配的内核虚拟地址范围属于 [PKMAP_BASE,FIXADDR_START],大小是2M或4M的虚拟空间
*/
vaddr = PKMAP_BASE;
page_table_range_init(vaddr, vaddr + PAGE_SIZE*LAST_PKMAP, pgd_base); pgd = swapper_pg_dir + pgd_index(vaddr);
pud = pud_offset(pgd, vaddr);
pmd = pmd_offset(pud, vaddr);
pte = pte_offset_kernel(pmd, vaddr);
/* pkmap_page_table保存了页表地址,之后如果用到永久内核映射区就很方便 */
pkmap_page_table = pte;
}
linux内存源码分析 - 页表的初始化的更多相关文章
- linux内存源码分析 - 伙伴系统(初始化和申请页框)
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 之前的文章已经介绍了伙伴系统,这篇我们主要看看源码中是如何初始化伙伴系统.从伙伴系统中分配页框,返回页框于伙伴系 ...
- linux内存源码分析 - 内存回收(整体流程)
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 概述 当linux系统内存压力就大时,就会对系统的每个压力大的zone进程内存回收,内存回收主要是针对匿名页和文 ...
- (转)linux内存源码分析 - 内存回收(整体流程)
http://www.cnblogs.com/tolimit/p/5435068.html------------linux内存源码分析 - 内存回收(整体流程) 概述 当linux系统内存压力就大时 ...
- linux内存源码分析 - 零散知识点
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 直接内存回收中的等待队列 内存回收详解见linux内存源码分析 - 内存回收(整体流程),在直接内存回收过程中, ...
- linux内存源码分析 - 内存压缩(同步关系)
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 概述 最近在看内存回收,内存回收在进行同步的一些情况非常复杂,然后就想,不会内存压缩的页面迁移过程中的同步关系也 ...
- linux内存源码分析 - 内存压缩(实现流程)
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 概述 本文章最好结合linux内存管理源码分析 - 页框分配器与linux内存源码分析 -伙伴系统(初始化和申请 ...
- linux内存源码分析 - SLUB分配器概述
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ SLUB和SLAB的区别 首先为什么要说slub分配器,内核里小内存分配一共有三种,SLAB/SLUB/SLOB ...
- linux内存源码分析 - SLAB分配器概述【转】
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 之前说了管理区页框分配器,这里我们简称为页框分配器,在页框分配器中主要是管理物理内存,将物理内存的页框分配给申请 ...
- linux内存源码分析 - SLAB分配器概述
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 之前说了管理区页框分配器,这里我们简称为页框分配器,在页框分配器中主要是管理物理内存,将物理内存的页框分配给申请 ...
随机推荐
- node 链接mysql(自动链接)
Node.js与MySQL交互操作有很多库 felixge/node-mysql 常用 cnpm i mysql --save dev 1.打开mysql 必须要有,我这里面用的是wamp.可视化用的 ...
- 理解jQuery中$.get、$.post、$.getJSON和$.ajax的用法
ajax的4种方法:$.get.$.post.$getJSON.$ajax. 1.$.get $.get()方法使用GET方式来进行异步请求,它的语法结构为: $.get( url [, data] ...
- 常见编码GBK、GB2312、UTF-8、ISO-8859-1的区别
https://blog.csdn.net/shijing_0214/article/details/50908144 在项目开发中,会经常遇到不同的编码方式.不管什么编码,都是信息在计算机中的一种表 ...
- mybatis学习系列四--mybatis generator逆向工程
采用命令行方式执行逆向工程 1.配置文件generatorConfig.xml 保存在目录:D:\E\workspace\eclipse\mybatis_generator <?xmlversi ...
- 洗礼灵魂,修炼python(21)--自定义函数(2)—函数文档,doctest模块,形参,实参,默认参数,关键字参数,收集参数,位置参数
函数文档 1.什么是函数文档: 就是放在函数体之前的一段说明,其本身是一段字符串,一个完整的函数需要带有函数文档,这样利于他人阅读,方便理解此函数的作用,能做什么运算 2.怎么查看函数文档: func ...
- LCD显示异常分析——开机闪现花屏【转】
转自LCD显示异常分析--开机闪现花屏 最近在工作中,有同事遇到LCD开机瞬间会闪现雪花屏的问题,而这类问题都有个共同点,那就是都发生在带GRAM的屏上,同样的问题,在休眠唤醒时也会出现. 其实这类问 ...
- https证书概念
https://studygolang.com/articles/10776 http://www.360doc.com/content/15/0520/10/21412_471902987.shtm ...
- linux kernel 源码安装
有时我们在安装系统后,发现没有安装当前系统的内核源码在/usr/src/kernels目录下,其实我们是少安装了一个rpm包: 当你配置好yum源后: yum install kernel-devel ...
- shell脚本之数组
变量:存储单个元素的内存空间. 数组:存储多个元素的连续的内存空间. 数组名:整个数组只有一个名字: 数组索引:编号从0开始: 数组名[索引]: 引用数组中的某个元素:${ ARRAY_NAME [ ...
- nginx 了解一下
先决条件 想要流畅的配置 nginx 需要了解一下内容: 1.nginx 调用方式: 启动 (双击 exe.cmd start nginx .cmd nginx) 使用 (powershell 调用需 ...