mysql使用自增Id为什么存储比较快
转自:https://blog.csdn.net/bigtree_3721/article/details/73151028
InnoDB引擎表的特点
1、InnoDB引擎表是基于B+树的索引组织表(IOT)
关于B+树
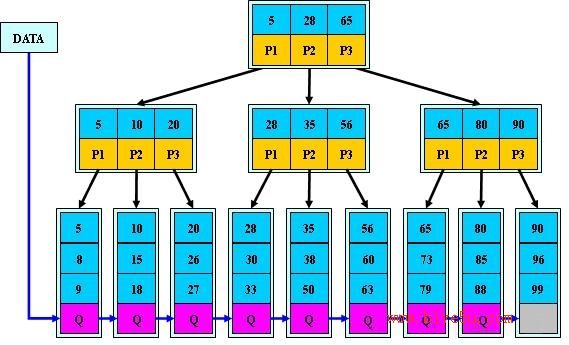
(图片来源于网上)
B+ 树的特点:
(1)所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
(2)不可能在非叶子结点命中;
(3)非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
2、如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择主键作为聚集索引、如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引、如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
3、数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
4、如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页
5、如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
综上总结,如果InnoDB表的数据写入顺序能和B+树索引的叶子节点顺序一致的话,这时候存取效率是最高的,也就是下面这几种情况的存取效率最高:
1、使用自增列(INT/BIGINT类型)做主键,这时候写入顺序是自增的,和B+数叶子节点分裂顺序一致;
2、该表不指定自增列做主键,同时也没有可以被选为主键的唯一索引(上面的条件),这时候InnoDB会选择内置的ROWID作为主键,写入顺序和ROWID增长顺序一致;
除此以外,如果一个InnoDB表又没有显示主键,又有可以被选择为主键的唯一索引,但该唯一索引可能不是递增关系时(例如字符串、UUID、多字段联合唯一索引的情况),该表的存取效率就会比较差。
《高性能MySQL》中的原话

欢迎关注
mysql使用自增Id为什么存储比较快的更多相关文章
- mysql 数据库自增id 的总结
有一个表StuInfo,里面只有两列 StuID,StuName其中StuID是int型,主键,自增列.现在我要插入数据,让他自动的向上增长,insert into StuInfo(StuID,Stu ...
- MySQL 使用自增ID主键和UUID 作为主键的优劣比较详细过程(从百万到千万表记录测试)
测试缘由 一个开发同事做了一个框架,里面主键是uuid,我跟他建议说mysql不要用uuid用自增主键,自增主键效率高,他说不一定高,我说innodb的索引特性导致了自增id做主键是效率最好的,为了拿 ...
- MYSQL获取自增ID的四种方法
MYSQL获取自增ID的四种方法 1. select max(id) from tablename 2.SELECT LAST_INSERT_ID() 函数 LAST_INSERT_ID 是与tabl ...
- mysql数据库自增id重新从1排序的两种方法
mysql默认自增ID是从1开始了,但当我们如果有插入表或使用delete删除id之后ID就会不会从1开始了哦. 使用mysql时,通常表中会有一个自增的id字段,但当我们想将表中的数据清空重新添 ...
- DBS-MySQL:MYSQL获取自增ID的四种方法
ylbtech-DBS-MySQL:MYSQL获取自增ID的四种方法 1.返回顶部 1. 1. select max(id) from tablename 2.SELECT LAST_INSERT_I ...
- mysql数据库表自增ID批量清零 AUTO_INCREMENT = 0
mysql数据库表自增ID批量清零 AUTO_INCREMENT = 0 #将数据库表自增ID批量清零 SELECT CONCAT( 'ALTER TABLE ', TABLE_NAME, ' AUT ...
- mysql 返回自增id
String dateNow= DateTime.Now.ToString("yyyyMMddhhmmss"+ new Random().Next(1, 99)); //随机数 ...
- MySQL 使用自增ID主键和UUID 作为主键的优劣比較具体过程(从百万到千万表记录測试)
主键类型 SQL语句 运行时间 (秒) (1)模糊范围查询1000条数据,自增ID性能要好于UUID 自增ID SELECT SQL_NO_CACHE t.* FROM test.`UC_US ...
- MySQL中自增ID起始值修改方法
在实际测试工作过程中,有时因为生产环境已有历史数据原因,需要测试环境数据id从某个值开始递增,此时,我们需要修改数据库中自增ID起始值,下面以MySQL为例: 表名:users; 建表时添加: ); ...
随机推荐
- PostgreSQL数组使用
原文:https://my.oschina.net/Kenyon/blog/133974 1.数组的定义 不一样的维度元素长度定义在数据库中的实际存储都是一样的,数组元素的长度和类型必须要保持一致, ...
- IntelliJ IDEA无法更新maven索引
maven索引的作用时在添加dependency的时候能有自动提示,不影响dependency的下载: 解决办法: 1.http://ju.outofmemory.cn/entry/359450 2. ...
- PHP 入门学习教程及进阶(源于知乎网友的智慧)
思过崖历程: 自学的动机.自学的技巧.自学的目标三个方面描述学习PHP的经历 一.自学的动机: 一定要有浓厚的兴趣,兴趣是最后的老师,可以在你迷茫的时候不断地支撑着你走下去. 自学不是为了工作,不是为 ...
- [模板][P4238]多项式求逆
NTT多项式求逆模板,详见代码 #include <map> #include <set> #include <stack> #include <cmath& ...
- BZOJ1515 : [POI2006]Lis-The Postman
首先,如果这个图本身就不存在欧拉回路,那么显然无解. 对于每个子串: 1.如果里面有不存在的边,那么显然无解. 2.如果里面有一条边重复出现,那么显然也无解. 3.对于每条边,维护其前驱与后继,若前驱 ...
- [P1082][NOIP2012] 同余方程 (扩展欧几里得/乘法逆元)
最近想学数论 刚好今天(初赛上午)智推了一个数论题 我屁颠屁颠地去学了乘法逆元 然后水掉了P3811 和 P2613 (zcy吊打集训队!)(逃 然后才开始做这题. 乘法逆元 乘法逆元的思路大致就是a ...
- 2017.08.06【NOIP提高组】模拟赛B组
Summary 今天的比赛60+100+100=260分,没有想到第一题正解是搜索,我与AK差一段距离,这段距离,叫倒着搜.总的来说不是很难. Problem T1 天平 题目大意 给你N个排序好的砝 ...
- 2017.07.07【NOIP提高组】模拟赛B组
Summary 因为某种无法抗拒的原因,今天没有打比赛,所以也就没有那种心态.今天的题目有状压DP和二分,这套题不难也不简单,适中,适合我这种渣渣来做.在改题时,发现了许多问题.我连欧拉函数的计算都记 ...
- Egret引擎的常用倒计时
直接上代码, private timeControl() { let timer: egret.Timer = segret.Timer(); timer.addEventListener(egret ...
- RS485 VS 20mA 电流环
RS485采用差分信号负逻辑,+2V-+6V表示“0”,- 6V-- 2V表示“1”.RS485有两线制和四线制两种接线,四线制只能实现点对点的通信方式,现很少采用,现在多采用的是两线制接线方式,这种 ...