simhash文章排重
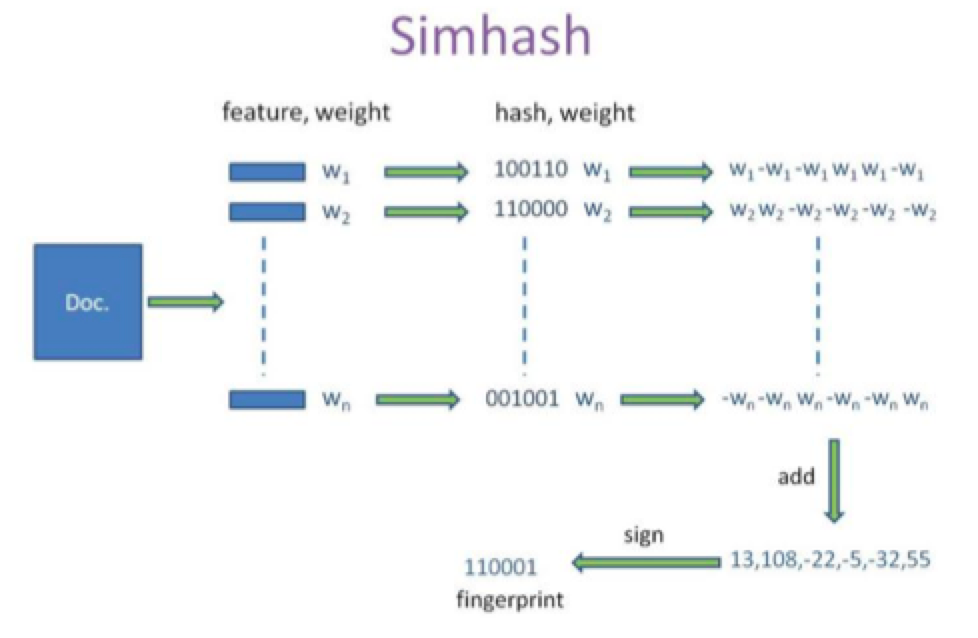
第一种是方案是查找待查询文本的64位simhash code的所有3位以内变化的组合,大约需要四万多次的查询,参考下图:
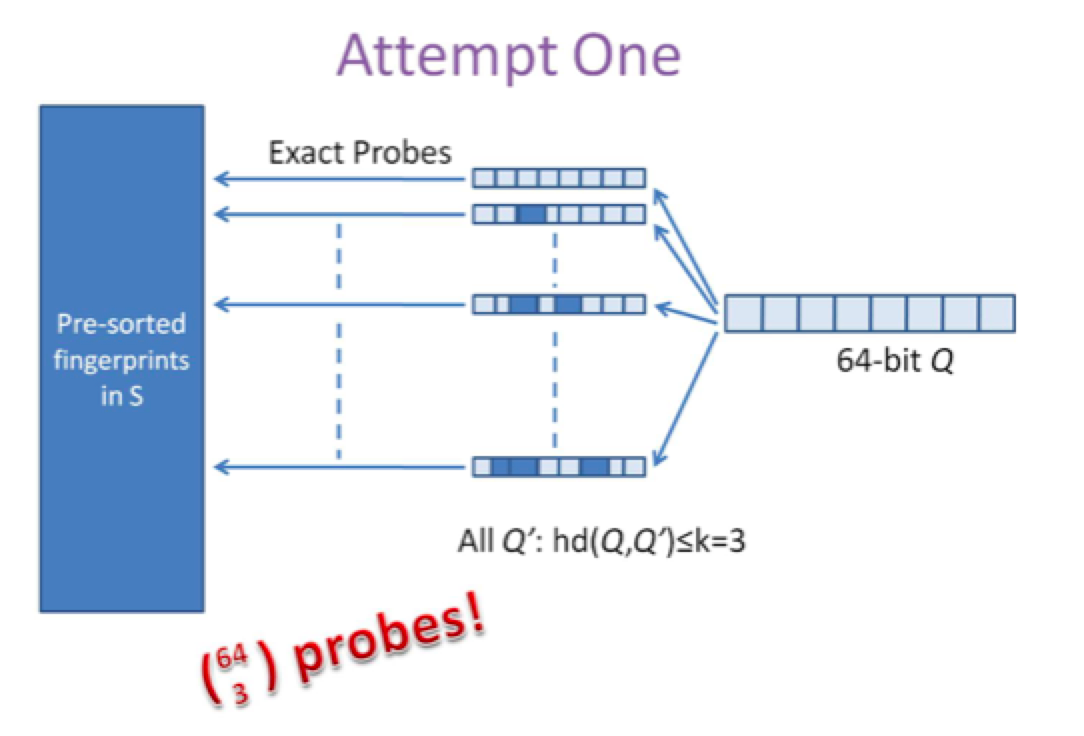
第二种方案是预生成库中所有样本simhash code的3位变化以内的组合,大约需要占据4万多倍的原始空间,参考下图
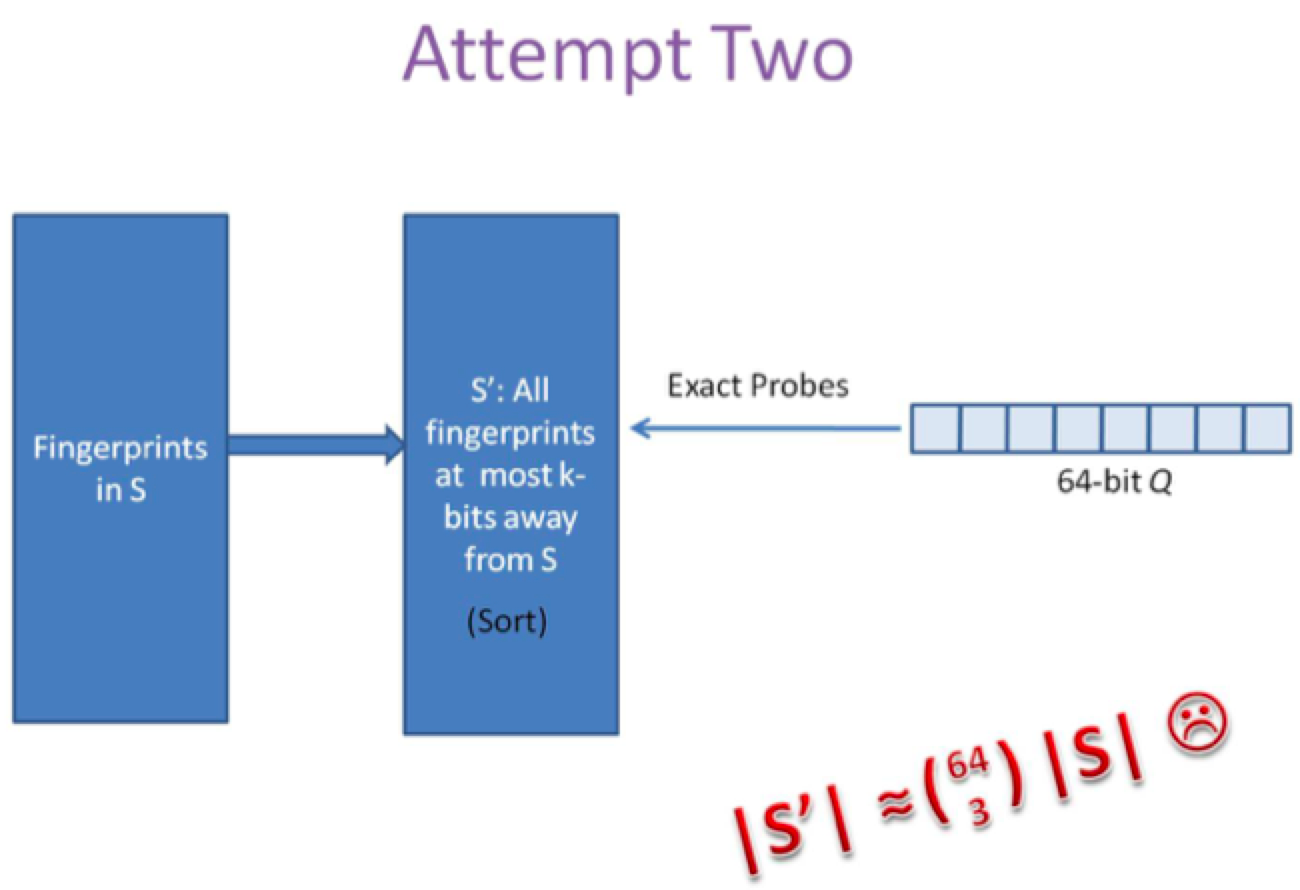
上述两种方法,或者时间复杂度,或者空间复杂度,其一无法满足实际的需求。我们需要一种方法,其时间复杂度优于前者,空间复杂度优于后者。 假设我们要寻找海明距离3以内的数值,根据抽屉原理,只要我们将整个64位的二进制串划分为4块,无论如何,匹配的两个simhash code之间至少有一块区域是完全相同的,如图所示
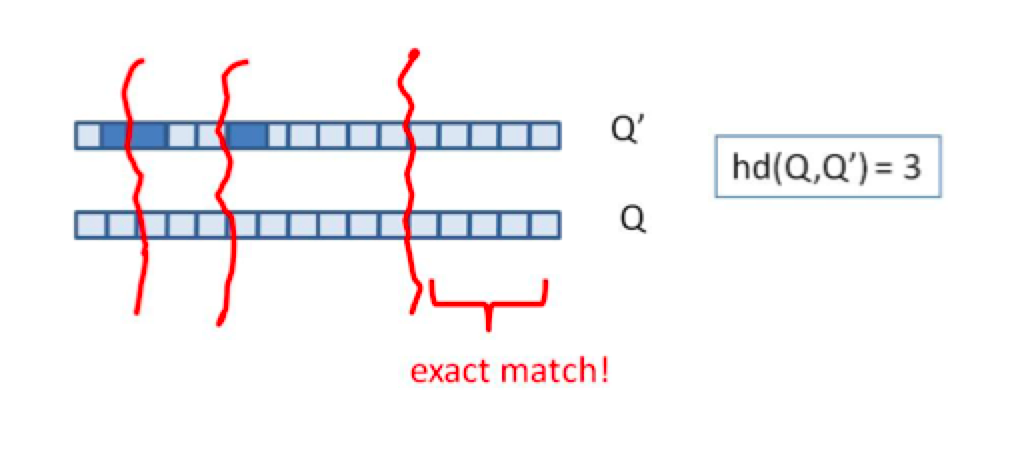
由于我们无法事先得知完全相同的是哪一块区域,因此我们必须采用存储多份table的方式。在本例的情况下,我们需要存储4份table,并将64位的simhash code等分成4份;对于每一个输入的code,我们通过精确匹配的方式,查找前16位相同的记录作为候选记录,如图所示:
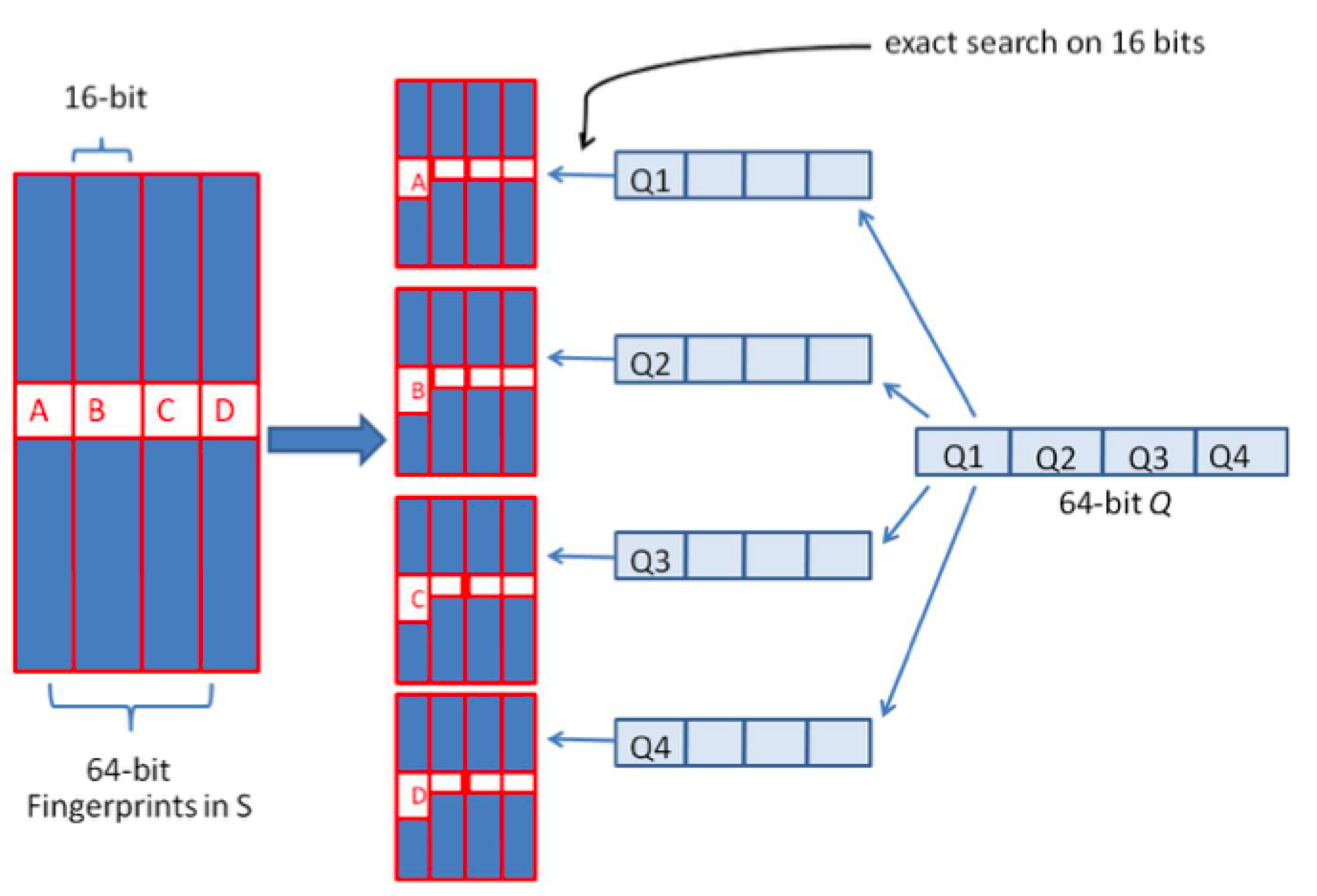
让我们来总结一下上述算法的实质:
1、将64位的二进制串等分成四块
2、调整上述64位二进制,将任意一块作为前16位,总共有四种组合,生成四份table
3、采用精确匹配的方式查找前16位
4、如果样本库中存有2^34(差不多10亿)的哈希指纹,则每个table返回2^(34-16)=262144个候选结果,大大减少了海明距离的计算成本
我们可以将这种方法拓展成多种配置,不过,请记住,table的数量与每个table返回的结果呈此消彼长的关系,也就是说,时间效率与空间效率不可兼得! 这就是Google每天所做的,用来识别获取的网页是否与它庞大的、数以十亿计的网页库是否重复。另外,simhash还可以用于信息聚类、文件压缩等。

SimHash 算法原理
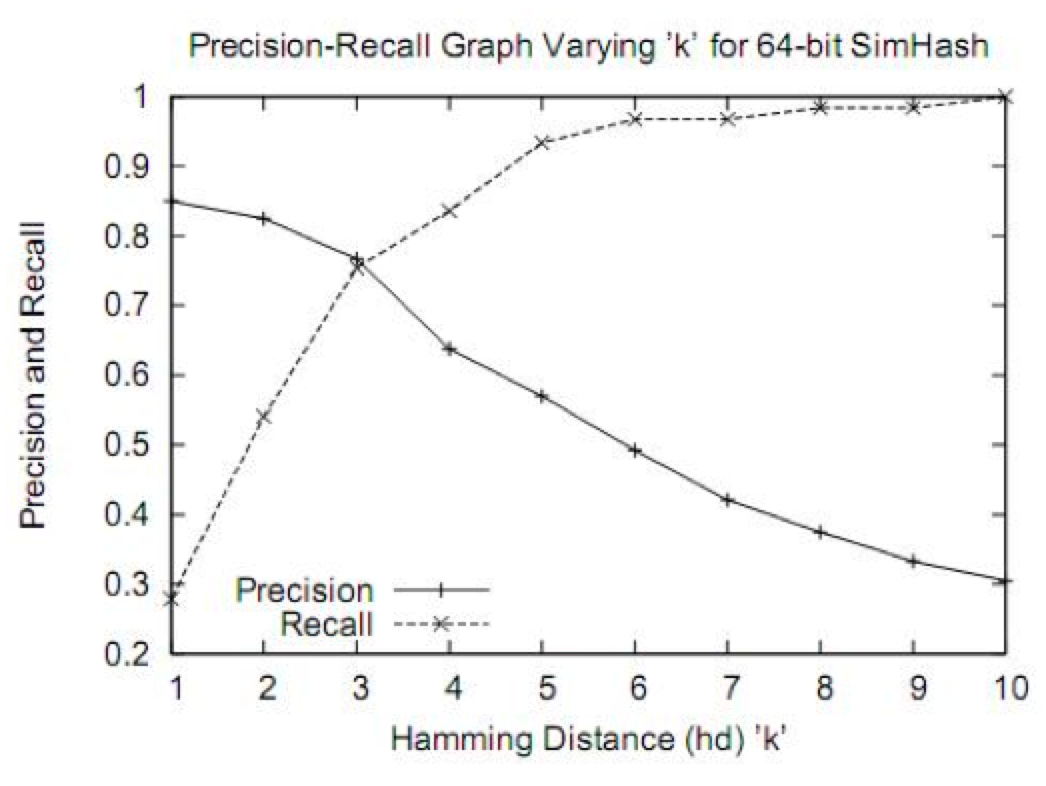
simhash用于比较大文本,比如500字以上效果都还蛮好,距离小于3的基本都是相似,误判率也比较低。但是如果我们处理的是微博信息,最多也就140个字,使用simhash的效果并不那么理想。看如下图,在距离为3时是一个比较折中的点,在距离为10时效果已经很差了,不过我们测试短文本很多看起来相似的距离确实为10。如果使用距离为3,短文本大量重复信息不会被过滤,如果使用距离为10,长文本的错误率也非常高,如何解决?——采用分段函数!
SimHash 算法原理——评估结果
1、dump 一天的新闻数据:
数据项要求:标题、内容、新闻原始地址。
2、评估指标
排重准确率(97%): 数据集:排重新闻集
方式:人工(研发先评估、产品评估)
召回率(75%):
数据集:训练数据集-排重新闻集
方式:扩大海明距离,再进行人工评估
SimHash 算法原理——代码片段
高效计算二进制序列中1的个数:这个函数来计算的话,时间复杂度是 O(n); 这里的n默认取值为3。由此可见还是蛮高效的。


simhash文章排重的更多相关文章
- Sicily 1051: 魔板(BFS+排重)
相对1150题来说,这道题的N可能超过10,所以需要进行排重,即相同状态的魔板不要重复压倒队列里,这里我用map储存操作过的状态,也可以用康托编码来储存状态,这样时间缩短为0.03秒.关于康托展开可以 ...
- C#微信公众号开发系列教程五(接收事件推送与消息排重)
微信公众号开发系列教程一(调试环境部署) 微信公众号开发系列教程一(调试环境部署续:vs远程调试) C#微信公众号开发系列教程二(新手接入指南) C#微信公众号开发系列教程三(消息体签名及加解密) C ...
- linux取某个字段排重
排重统计 cat a.txt | awk -F ';' '{print $2}' | sort -u | wc -l
- 《MYSQL》----字符串的复杂函数,检索的七-天-排-重
接到了一个新的需求,拿到需求的时候瞬间有点头大,因为实在是有些棘手. 我们这个系统本身是个接口系统,总接口数大概在200个左右.外部会有很多用户在 不同的时间拿着不同参数去调我们的这些接口,用户的调集 ...
- python之路day07-集合set的增删查、列表如何排重(效率最高的方法)、深浅copy
集合set 集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的.以下是集合最重要的两点: 去重,把一个列表变成集合,就自动去重了. ...
- uid列表来讲讲我是如何利用php数组进行排重的
经常接到要对网站的会员进行站内信.手机短信.email进行群发信息的通知,用户列表一般由别的同事提供,当中难免会有重复,为了避免重复发送,所以我在进行发送信息前要对他们提供的用户列表进行排重. 假如得 ...
- SQL 数据排重,去掉重复数据 有用
.最大的错误: 在对数据排重的时候,首先想到的就是Distinct,虽然这很管用,但多数场合下不适用,因为通常排重后还要做进一步处理,比如对编号排重后要按日期统计等. 无法排重的Group by ...
- 转:C#微信公众号开发之接收事件推送与消息排重的方法
本文实例讲述了C#微信公众号开发之接收事件推送与消息排重的方法.分享给大家供大家参考.具体分析如下: 微信服务器在5秒内收不到响应会断掉连接,并且重新发起请求,总共重试三次.这样的话,问题就来了.有这 ...
- python 手把手教你基于搜索引擎实现文章查重
前言 文章抄袭在互联网中普遍存在,很多博主都收受其烦.近几年随着互联网的发展,抄袭等不道德行为在互联网上愈演愈烈,甚至复制.黏贴后发布标原创屡见不鲜,部分抄袭后的文章甚至标记了一些联系方式从而使读者获 ...
随机推荐
- Mac Eclipse 配置 SDK Manager Proxy (代理)
默认的下载地址非常慢,可以换成东软的代理. 顶部任务栏中选择SDK Manager -> 偏好设置 : 可以看到下载速度快了很多,出现类很多安装选项: 安装好后,在偏好设置窗口中,选择Clear ...
- Django的rest_framework认证组件之全局设置源码解析
前言: 在我的上一篇博客我介绍了一下单独为某条url设置认证,但是如果我们想对所有的url设置认证,该怎么做呢?我们这篇博客就是给大家介绍一下在Rest_framework中如何实现全局的设置认证组件 ...
- Idea创建简单Java Web项目并部署Servlet
1.打开Idea,创建JAVA Web项目 在WEB-INF目录下创建classes和lib文件夹 配置编译输出路径为刚才新建的classes文件夹 配置依赖jar包加载路径 添加tomcat ser ...
- Boost::bind使用详解
1.Boost::bind 在STL中,我们经常需要使用bind1st,bind2st函数绑定器和fun_ptr,mem_fun等函数适配器,这些函数绑定器和函数适配器使用起来比较麻烦,需要根据是全局 ...
- Android通过手机搭建服务器,WIFI建立热点实现C/S聊天室通信功能
应用效果图: 客户端 ...
- ulogd(一)
参考资料: https://blog.csdn.net/eydwyz/article/details/52456335 https://blog.csdn.net/chinalinuxzend/art ...
- linux学习第七天 (Linux就该这么学)
今天讲了chmod (权限 设置)和 chown(属性 设置),特殊权限:SUID u+s 数字法是4 x=s - = S,SGID g+s 数字法是2 x=s -=S,SBIT o+t x=t ...
- 实现一个jsp同时提交两个form到两个Servlet
<%@ page contentType="text/html;charset=GBK" language="java"%> <html> ...
- C#中读写INI文件
C#中读写INI文件 c#的类没有直接提供对ini文件的操作支持,可以自己包装win api的WritePrivateProfileString和GetPrivateProfileString函数实现 ...
- merge and saveorupdate
首先 saveOrUpdate返回void 也就是什么都不返回 而merge会返回一个对象 merge 在执行session.merge(a)代码后,a对象仍然不是持久化状态,a对象仍然不会被关联到S ...