潭州课堂25班:Ph201805201 django 项目 第二十九课 docker实例,文件下载前后台实现 (课堂笔记)
docker 实例
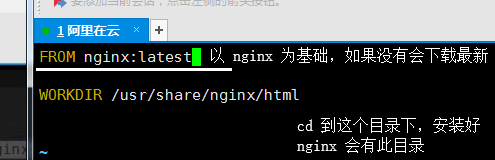
:wq!保存退出
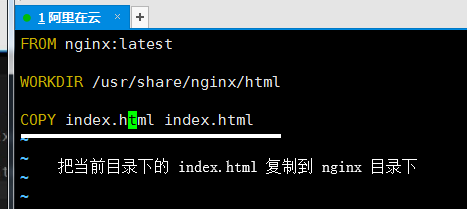
放入一个 html 文件
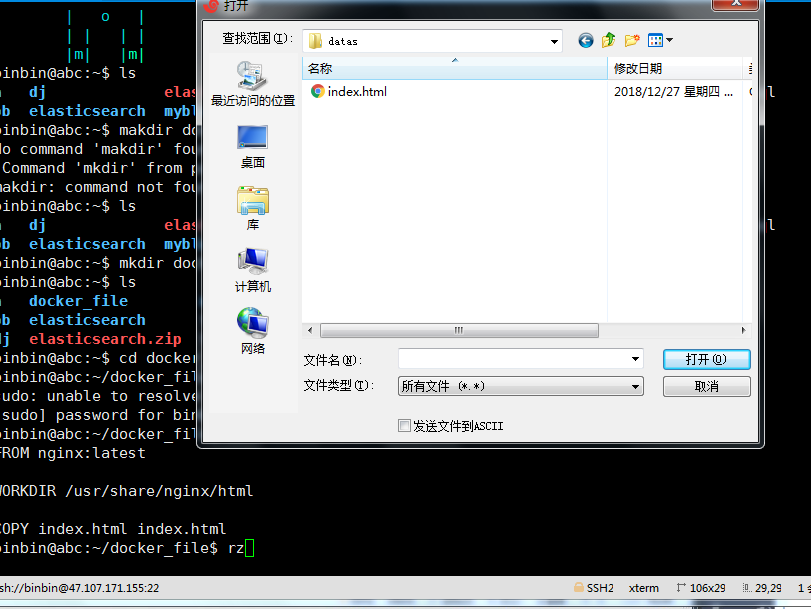
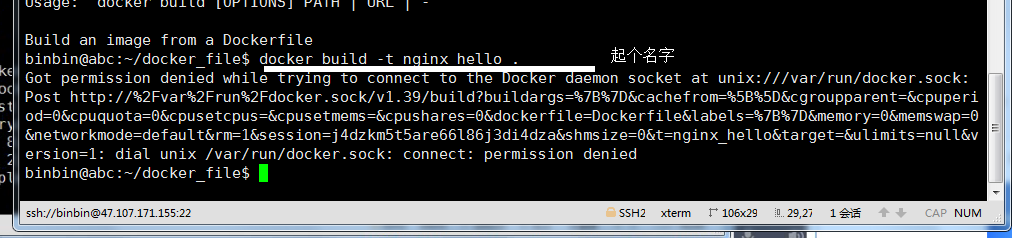
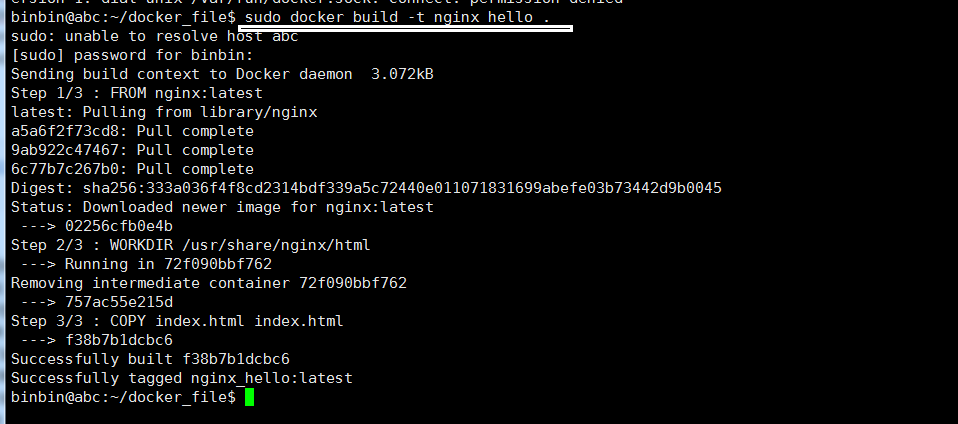
权限不够,加 sudo
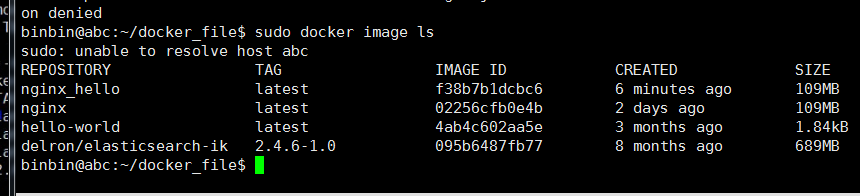
查看本地仓库的 image
运行 docker

-- name,后跟个运行名, -p 物理机端口映射到容器端口, -d 后台运行,后跟创建的 docker 名
访问网址

查看容器
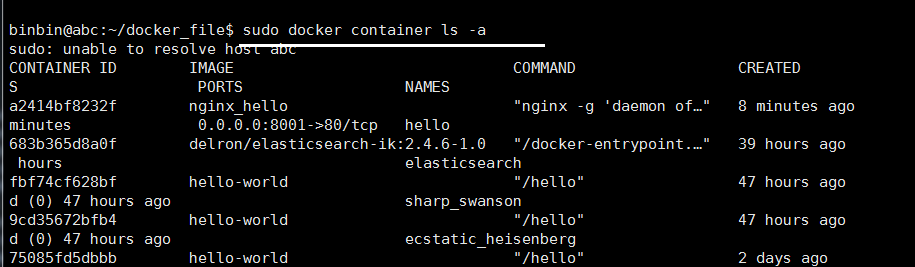
删除 一个容器 rm 跟 id

查看

进入一个正在运行的 docker 中用 exec -it

exit 退出
停止
一、文档下载功能
1.分析
业务处理流程:
判断前端传的文件id是否为空,对应的文件是否存在
请求方法:GET
url定义:/docs/<int:doc_id>/
请求参数:url路径参数
| 参数 | 类型 | 前端是否必须传 | 描述 |
|---|---|---|---|
| doc_id | 整数 | 是 | 文件id |
此功能是通过向前端返回FileResponse来实现的。
2.后端代码实现
导入 自定义模型 utils.models import ModelBase
# 在apps/doc/models.py中定义数据库模型 from django.db import models from utils.models import ModelBase class Doc(ModelBase):
"""create doc view
"""
file_url = models.URLField(verbose_name="文件url", help_text="文件url")
title = models.CharField(max_length=150, verbose_name="文档标题", help_text="文档标题")
desc = models.TextField(verbose_name="文档描述", help_text="文档描述")
image_url = models.URLField(default="", verbose_name="图片url", help_text="图片url")
author = models.ForeignKey('users.Users', on_delete=models.SET_NULL, null=True) class Meta:
db_table = "tb_docs" # 指明数据库表名
verbose_name = "用户" # 在admin站点中显示的名称
verbose_name_plural = verbose_name # 显示的复数名称 def __str__(self):
return self.title
迁移:

下载请求 视图:
import logging
import urllib3 import requests
from django.shortcuts import render
from django.http import FileResponse, Http404
from django.utils.encoding import escape_uri_path
from django.views import View
from django.conf import settings from .models import Doc # 导入日志器
logger = logging.getLogger('django')
#
# def doc(request):
# return render(request, 'doc/docDownload.html',locals())
#
# def doc_index(request):
"""渲染
"""
docs = Doc.objects.defer('author', 'create_time', 'update_time', 'is_delete').filter(is_delete=False)
return render(request, 'doc/docDownload.html', locals()) class DocDownload(View):
"""创建下载视图
docs<int:doc_id>/
"""
def get(self, request, doc_id):
# 把不要的字段列出
doc = Doc.objects.only('file_url').filter(is_delete=False, id=doc_id).first()
if doc:
doc_url = doc.file_url
doc_url = settings.SITE_DOMAIN_PORT + doc_url
doc_name = doc.title
try:
# 流控制(不要等到下载完成再打开)
res = FileResponse(requests.get(doc_url, stream=True))
# 仅测试的话可以这样子设置
# res = FileResponse(open(doc.file_url, 'rb'))
except Exception as e:
logger.info("获取文档内容出现异常:\n{}".format(e))
raise Http404("文档下载异常!") # 拿到文件的后缀名
ex_name = doc_url.split('.')[-1]
# https://stackoverflow.com/questions/23714383/what-are-all-the-possible-values-for-http-content-type-header
# http://www.iana.org/assignments/media-types/media-types.xhtml#image
if not ex_name:
raise Http404("文档url异常!")
else:
ex_name = ex_name.lower() if ex_name == "pdf":
res["Content-type"] = "application/pdf"
elif ex_name == "zip":
res["Content-type"] = "application/zip"
elif ex_name == "doc":
res["Content-type"] = "application/msword"
elif ex_name == "xls":
res["Content-type"] = "application/vnd.ms-excel"
elif ex_name == "docx":
res["Content-type"] = "application/vnd.openxmlformats-officedocument.wordprocessingml.document"
elif ex_name == "ppt":
res["Content-type"] = "application/vnd.ms-powerpoint"
elif ex_name == "pptx":
res["Content-type"] = "application/vnd.openxmlformats-officedocument.presentationml.presentation" else:
raise Http404("文档格式不正确!") doc_filename = escape_uri_path(doc_url.split('/')[-1])
# 设置为inline,会直接打开
res["Content-Disposition"] = "attachment; filename*=UTF-8''{}".format(doc_filename)
return res else:
raise Http404("文档不存在!")
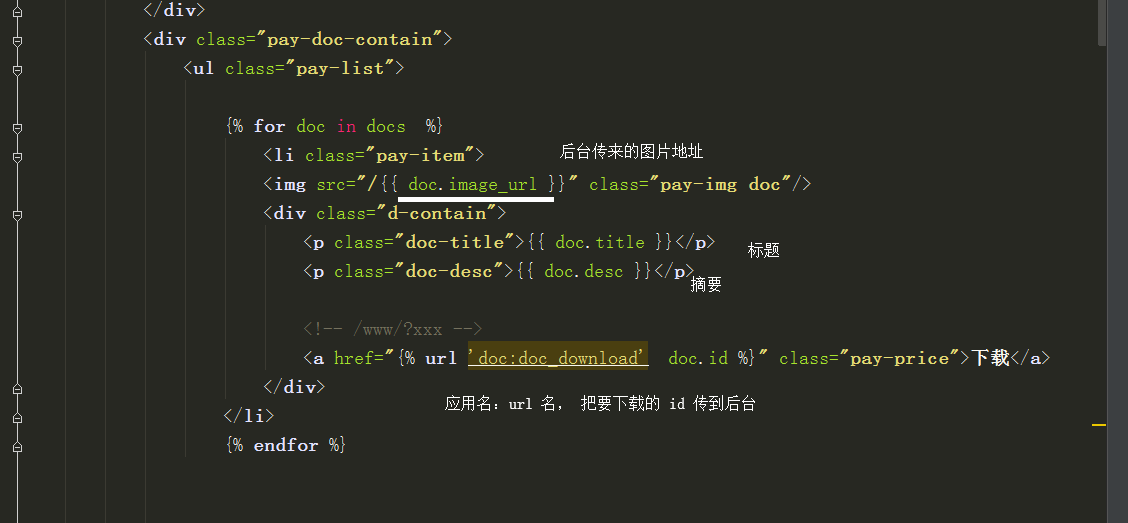
html 文件中
潭州课堂25班:Ph201805201 django 项目 第二十九课 docker实例,文件下载前后台实现 (课堂笔记)的更多相关文章
- 潭州课堂25班:Ph201805201 django 项目 第二十五课 文章多级评论前后台实现 (课堂笔记)
添加新闻评论功能 1.分析 业务处理流程: 判断前端传的新闻id是否为空,是否为整数.是否不存在 判断评论的内容是否为空 判断是否有父评论,父评论的id是否与新闻id匹配 判断用户是否登录 保存新闻评 ...
- 潭州课堂25班:Ph201805201 django 项目 第二十六课 docker简介 (课堂笔记)
官方文档: https://docs.docker.com/install/linux/docker-ce/ubuntu/#set-up-the-repository 1,更新下sudo apt-ge ...
- 潭州课堂25班:Ph201805201 django 项目 第二十八课 新闻elasticsearch搜索前后功台能实现 (课堂笔记)
后端功能实现 文件,类,字段,命名不要改动, 在apps/news/search_indexes.py中创建如下类:(名称固定为search_indexes.py) # -*-# -*- coding ...
- 潭州课堂25班:Ph201805201 django 项目 第二十四课 文章主页 多级评论数据库设计 ,后台代码完成 (课堂笔记)
加载新闻评论功能 1.分析 业务处理流程: 判断前端传的新闻id是否为空,是否为整数.是否不存在 请求方法:GET url定义:'/news/<int:news_id>' 请求参数:url ...
- 潭州课堂25班:Ph201805201 django 项目 第二十二课 文章主页 新闻列表页面滚动加载,轮播图后台实现 (课堂笔记)
新建static/js/news/index.js文件 ,主要用于向后台发送请求, // 新建static/js/news/index.js文件 $(function () { // 新闻列表功能 l ...
- 潭州课堂25班:Ph201805201 django 项目 第十九课 文章主页数据库模型,前后台功能实现 (课堂笔记)
-数据库模型设计 : 文章:新闻表: 字段:图片,标题,摘要,类型,作者,创建时间 标签表 评论表, 轮播图:外键,指向文章的外键表 在 utls 目录下创建 models.py 把其它模型常用的字 ...
- 潭州课堂25班:Ph201805201 django 项目 第十五课 用户注册功能后台实现 (课堂笔记)
前台:判断用户输入 ,确认密码,手机号, 一切通过后向后台发送请求, 请求方式:post 在 suers 应用下的视图中: 1,创建个类, 2,创建 GET 方法,宣言页面 3,创建 POST 方法 ...
- 潭州课堂25班:Ph201805201 django 项目 第二十课 数据库分析设计图 (课堂笔记)
https://www.dbdesigner.net/
- 潭州课堂25班:Ph201805201 django 项目 第十八课 前台 注解 (课堂笔记)
在静态文件 js/user上当下,的 auth.js 文件中 $(function () { let $username = $('#user_name'); // 选择id为user_name的网页 ...
随机推荐
- POJ 1002 487-3279(字典树/map映射)
487-3279 Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 309257 Accepted: 5 ...
- 20165206 预备作业3 Linux安装及学习
Linux的安装与学习 - 在自己笔记本上安装Linux操作系统 在安装虚拟机的过程中遇到了不少问题,但也都进行了尝试并得到了解决.首先是在安装VirtulBox的安装上,按照老师给的链接下载安装,不 ...
- Oracle数据库表索引失效,解决办法:修改Oracle数据库优化器模式
ALTER SYSTEM SET OPTIMIZER_MODE=RULE scope=both; 其他可以选择的模式还有ALL_ROWS/CHOOSE/FIRST_ROWS/ALL_ROWS. 应用系 ...
- Git 分支 - 分支的新建与合并
转载自:https://git-scm.com/book/zh/v1/Git-%E5%88%86%E6%94%AF-%E5%88%86%E6%94%AF%E7%9A%84%E6%96%B0%E5%BB ...
- jquery源码中noConflict(防止$和jQuery的命名冲突)的实现原理
jquery源码中noConflict(防止$和jQuery的命名冲突)的实现原理 最近在看jquery源码分析的视频教学,希望将视频中学到的知识用博客记录下来,更希望对有同样对jquery源码有困惑 ...
- 令人疑惑的 std::remove 算法
摘自<Effective STL>第32条 remove的声明: template<class ForwardIterator, class T> ForwardIterato ...
- pandas处理finance.yahoo股票数据 WTI CL USO OIL
1.参考 用Python做科学计算-基础篇 »matplotlib-绘制精美的图表 »快速绘图 使用pyplot模块绘图 2.数据来源 CL USO OIL 3.代码 #encoding='utf-8 ...
- JMeter中BeanShell Sampler调试分享
BeanShell脚本 String s = "s"; String y = "y"; boolean result = s.equals(y); vars.p ...
- root用户无法通过ssh连接Linux系统
ssh协议为了安全,有些版本默认禁止root用户的登陆 cd /etc/ssh 编辑sshd_config文件 cat sshd_config | grep PermitRootLogin Permi ...
- scrapy 基础使用以及错误方案
原先用的是selenium(后面有时间再写),这是第一次使用scrapy这个爬虫框架,所以记录一下这个心路历程,制作简单的爬虫其实不难,你需要的一般数据都可以爬取到. 下面是我的目录,除了main.p ...