使用python scrapy爬取知乎提问信息
前文介绍了python的scrapy爬虫框架和登录知乎的方法.
这里介绍如何爬取知乎的问题信息,并保存到mysql数据库中.
首先,看一下我要爬取哪些内容:
如下图所示,我要爬取一个问题的6个信息:
- 问题的id(question_id)
- 标题(title)
- 问题描述(intro)
- 回答个数(answer_num)
- 关注人数(attention_uv)
- 浏览次数(read_pv)
 

爬取结果我保存到mysql数据库中,表名为:zhihu_question
如下图中,红框里的就是上图是有人为我的穿着很轻浮,我该如何回应?问题的信息.
(回答个数,关注着和浏览次数数据不一致是因为我是在爬取文章信息之后的一段时间才抽出来时间写的文章,在这期间回答个数,关注着和浏览次数都会增长.)
 

爬取方法介绍
我用的是scrapy框架中自带的选择器selectors.
selectors通过特定的 XPath 或者 CSS 表达式来“选择” HTML文件中的某个部分。
XPath 是一门用来在XML文件中选择节点的语言,也可以用在HTML上。 CSS 是一门将HTML文档样式化的语言。
XPath最最直观的介绍:
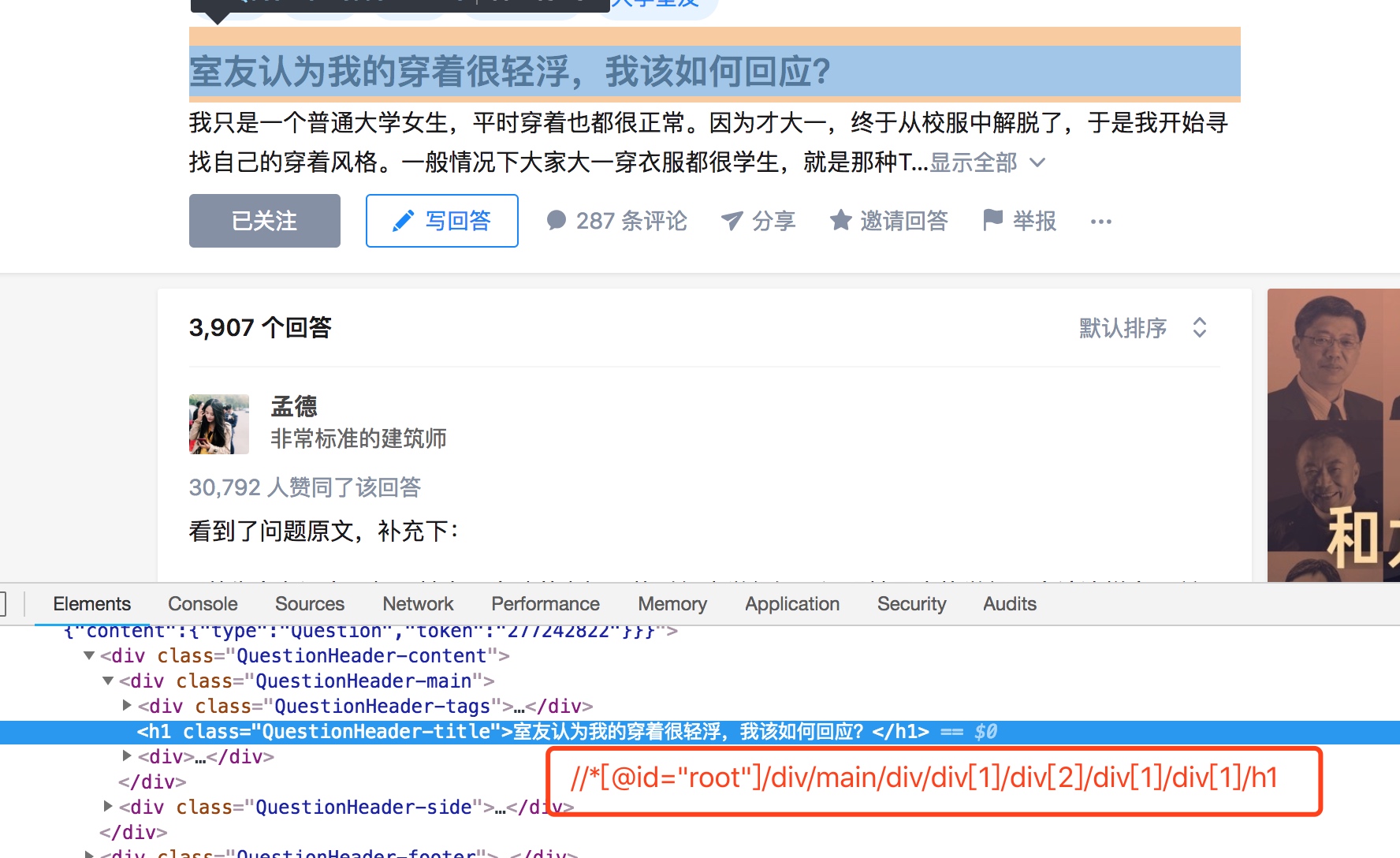
例如:知乎问题页面上的标题的XPath如下:
图中红框里就是标题的XPath.(这只是一个直观的介绍,还有一些细节可以在代码中看到)

爬取代码:
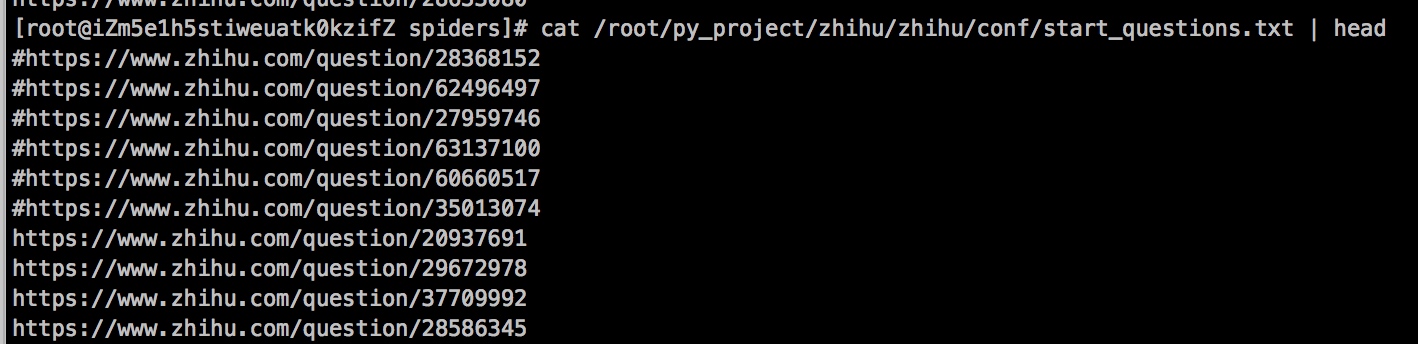
爬取问题的相关信息只需要问题url即可,我这里把收集的问题url写到文件中,爬虫程序去遍历文件,然后依次爬取.
我是在登录成功知乎后的check_login这个方法里面构造的起始url,所以读文件的方法也在这里,代码如下:
def check_login(self, response):
# 验证登录成功之后构造初始问题url
file = open("/root/py_project/zhihu/zhihu/conf/start_questions.txt")
while 1:
line = file.readline()
line = line.strip('\n') #去掉最后的换行
if not line:
break
if(line[0:1] == "#"):
#如果是#开头的url, 跳过
print line
pass
else:
print("current url : " + line)
yield scrapy.Request(line,callback=self.parse_question, headers=self.headers)
file.close()
其中最重要的一行是:
yield scrapy.Request(line,callback=self.parse_question, headers=self.headers)
yield scrapy.Request 代表开始爬取一条url,如果有多个url就yield多次. 这里的次数等同于start_question.txt中非#开头的url
如下:

callback=self.parse_question 是请求url地址后,返回的response的回调处理函数,也是整个爬取过程中最核心的代码.
如下:
def parse_question(self,response):
item = QuestionItem()
url = response.url
questionid=url[url.rindex("/")+1:]
item['questionid']=questionid
item['title']=response.selector.xpath('//*[@class="QuestionHeader-title"]/text()')[0].extract()
descarr=response.selector.xpath('//span[@itemprop="text"]/text()')
if len(descarr) > 0:
item['desc']=descarr[0].extract()
else:
item['desc']="-"
item['answer_num']=response.selector.xpath('//*[@id="QuestionAnswers-answers"]/div/div/div[1]/h4/span/text()[1]')[0].extract().replace(',','')
item['attention_uv']=response.selector.xpath('//strong[@class="NumberBoard-itemValue"]/text()')[0].extract().replace(',','')
item['read_pv']=response.selector.xpath('//strong[@class="NumberBoard-itemValue"]/text()')[1].extract().replace(',','')
yield item
其中主要代码是用selectors.xpath选取我们需要的问题信息(注意:这里的路径并不一定与 chrome的debug模式中复制的xpath一致,直接复制的xpath一般不太能用,自己看html代码结构写的),
获取到问题的信息之后放到item.py中定义好的QuestionItem对象中,然后yield 对象 , 会把对象传递到配置的pipelines中.
pipelines一般是在配置文件中配置,
因为这里爬取问题只保存到mysql数据库,并不下载图片,(而爬取答案需要下载图片)所以各自在在爬虫程序中定义的pipelines,如下:
custom_settings = {
'ITEM_PIPELINES' : {
'zhihu.mysqlpipelines.MysqlPipeline': 5
#'scrapy.pipelines.images.ImagesPipeline': 1,#这个是scrapy自带的图片下载pipelines
}
}
以上是爬取知乎问题的整个大致过程.
后文介绍爬取收藏夹下的回答 和 问题下的回答(包括内容和图片).
使用python scrapy爬取知乎提问信息的更多相关文章
- python scrapy爬取知乎问题和收藏夹下所有答案的内容和图片
上文介绍了爬取知乎问题信息的整个过程,这里介绍下爬取问题下所有答案的内容和图片,大致过程相同,部分核心代码不同. 爬取一个问题的所有内容流程大致如下: 一个问题url 请求url,获取问题下的答案个数 ...
- 利用 Scrapy 爬取知乎用户信息
思路:通过获取知乎某个大V的关注列表和被关注列表,查看该大V和其关注用户和被关注用户的详细信息,然后通过层层递归调用,实现获取关注用户和被关注用户的关注列表和被关注列表,最终实现获取大量用户信息. 一 ...
- 爬虫(十六):scrapy爬取知乎用户信息
一:爬取思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账 ...
- 爬虫实战--利用Scrapy爬取知乎用户信息
思路: 主要逻辑图:
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- scrapy 爬取知乎问题、答案 ,并异步写入数据库(mysql)
python版本 python2.7 爬取知乎流程: 一 .分析 在访问知乎首页的时候(https://www.zhihu.com),在没有登录的情况下,会进行重定向到(https://www. ...
- scrapy爬取知乎某个问题下的所有图片
前言: 1.仅仅是想下载图片,别人上传的图片也是没有版权的,下载来可以自己欣赏做手机背景但不商用 2.由于爬虫周期的问题,这个代码写于2019.02.13 1.关于知乎爬虫 网上能访问到的理论上都能爬 ...
- python scrapy爬取HBS 汉堡南美航运公司柜号信息
下面分享个scrapy的例子 利用scrapy爬取HBS 船公司柜号信息 1.前期准备 查询提单号下的柜号有哪些,主要是在下面的网站上,输入提单号,然后点击查询 https://www.hamburg ...
- Python——Scrapy爬取链家网站所有房源信息
用scrapy爬取链家全国以上房源分类的信息: 路径: items.py # -*- coding: utf-8 -*- # Define here the models for your scrap ...
随机推荐
- leetcode — regular-expression-matching
/** * Source : https://oj.leetcode.com/problems/regular-expression-matching/ * * Created by lverpeng ...
- 一张图读懂PBN飞越转弯衔接TF/CF航段计算
在PBN旁切转弯的基础上,再来看飞越转弯接TF(或CF)航段,保护区结构上有些相似,只是转弯拐角处的保护区边界有“简化”,其余部分是相近的. FlyOver接TF段的标称航迹有一个飞越之后转弯切入航迹 ...
- 接触Java的15天,初步了解面向对象
面向对象的三打特征:封装 ,继承 ,多态 . 图老师给的,叫我们好好看一看 对象(object):一个杯子,一台电脑,一个人,一件衣服 等,都可以称为对象. 类:类是对象的抽象的分类:比如,人类进行 ...
- github-SSH模式如何配置秘钥clone远程仓库以及分支切换
一.ssh模式clone 恕我无知,之前使用git命令都是https模式,该模式每次push都需要输入账号和密码,而且速度会根据的网速的快慢而定. 近日电脑重装了系统,在用SSH模式clone远程仓库 ...
- hadoop的企业优化
前言: Mapreduce程序的效率的瓶颈在于两点: 计算机性能: CPU.内存.磁盘健康.网络 I/O操作: 数据倾斜 map和reduce数量设置不合理 map的运行时间太长,导致reduc的等待 ...
- Ps—导出:sql作业配合ps导出csv文件
$dateText=Get-Date #获取当前日期时间 $dateText = $dateText.ToShortDateString() #转为短日期格式(去掉时间部分) $checkDate=( ...
- 【读书笔记】iOS-对iOS应用进行模糊测试
一,模糊测试,是指通过反复向待测应用发送畸形的数据,对应用进行动态测试的过程. 二,模糊测试,也称动态分析,是一种构造非法输入并将其提供给应用,以期让应用暴露出某些安全问题的艺术和科学. 参考资料:& ...
- vue.js及项目实战[笔记]— 01 vue.js
一. vue基础 1. 历史介绍 angular 09年,年份较早,一开始大家是拒绝的 react 2013年,用户体验较好,直接拉到一堆粉丝 vue 2014年,用户体验较好 前端框架与库的区别 j ...
- .NET代码设计简单规范
以下转载于:http://www.it28.cn/ASPNET/825095.html 下面这个规范是我为朋友写的几点建议,写的很范,作为BLOG,愿与大家一起分享.只给出部分设计规范样例,关于.NE ...
- Linux 下修改网卡接口名
Linux下修改网卡接口名 by:授客 QQ:1033553122 (测试环境:CentOS-6.0-x86_64-bin-DVD1.iso+Vmware) 作用 可以用于解决类似如下Device n ...