Hadoop生态圈-大数据生态体系快速入门篇
Hadoop生态圈-大数据生态体系快速入门篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.大数据概念
1>.什么是大数据
大数据(big data):是指无法在一定时间范围内用常规软件进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发现力和流程优化能力的海量,高增长率和多样化的信息资产。
大数据技术主要解决两个问题,即海量的存储和海量的数据的分析计算。
2>.数据存储单位介绍
按照顺序给出数据存储单位如:Bit,Byte,KB,MB,GB,TB,PB,EB,ZB,YB,BB,NB,DB。换算单位如下:
1Byte = Bit
1K = Byte
1MB = KB
1GB = MB
1TB = GB
1PB = TB
1EB = PB
1ZB = EB
1YB = ZB
1BB = YB
1NB = BB
1DB = NB
3>.大数据特点
大数据最明显的特点简单的来说就是四个V,即:Volume(大量),Velocity(高速),Variety(多样),Value(低价值密度)。
>.Volume(大量)
截止目前,人类生成的所有印刷材料的数据量是200PB,而历史上全人类总共说过的话的数据量大约是5EB,
当前,典型个人计算机硬盘的容量为TB量级,而一些大企业的数据量已经接近EB量级。 >.Velocity(高速)
这是大数据区分与传统数据挖掘的最显著特征。根据IDC的“数字宇宙”的报告,预计到2020年,全球数据
使用量将达到35.2ZB。在如此海量的数据面前,处理数据的效率就是企业的生命。 >.Variety(多样)
这种类型的多样性也让数据被分为结构化数据和非结构化数据。相对于以往便于存储的以数据库/文本为主的
结构化数据,非结构化的数据越来越多,包括网络日志,音频,视频,图片,地理位置信息等等,这些多类型的数
据的处理能力提出了更高的要求。 >.Value(低价值密度)
价值密度的高低与数据总量的大小成反比,如何快速对有价值的数据“提纯”称为目前大数据背景下待解决的
难题。
4>.企业的组织结构
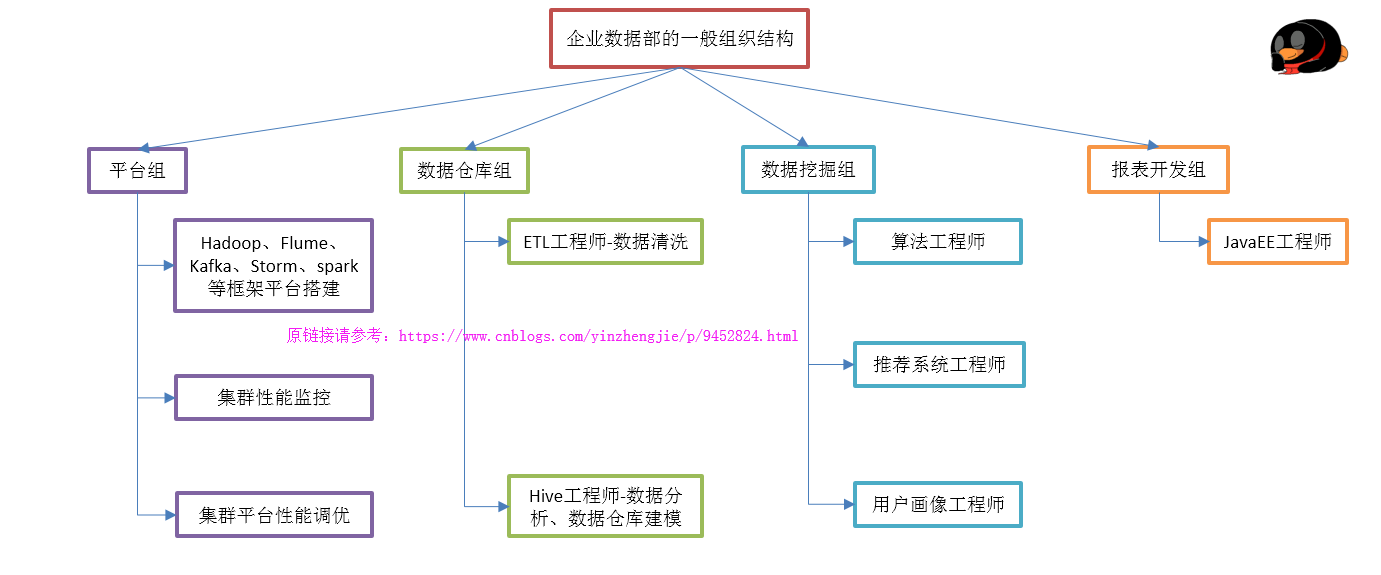
大数据工程师的岗位还是蛮紧缺的,尤其是在数据挖掘方向,其实从事大数据主要分三个方向,即大数据运维,大数据开发,大数据分析,其实大数据报表貌似跟大数据不咋搭边。下图是我在网上描述对企业大数据部门的一般组织结构,那么问题来了?如果你想要从事大数据工作,你会选择哪个方向呢?
二.从Hadoop框架讨论大数据生态圈
1>.Hadoop是什么
Hadoop是什么
>.Hadoop是一个由Apache基金会所开发的分布式洗头膏基础架构;
>.主要解决:海量数据的存储和海量数据的分析计算为题;
>.广义上来说,Hadoop通常是指一个更广泛的概念,它指的不仅仅是Hadoop这款软件,而是指的是Hadoop生态圈;
2>.Hadoop发展历史
Hadoop发展历史
>.Lunce-Doug开创的开源软件,用Java书写代码,实现与Google类似的全文搜索功能,它提供了全文检索引擎的架构,
包括完整的查询引擎和搜索引擎;
>.2001年年底称为Apache基金会的一个子项目;
>.对于大数据的场景,Luence面对与Google同样的困难;
>.学习和模仿Google解决这些问题的办法:微型版Nutch
>.可以说Google是Hadoop的思想之源(Google在大数据方面的三篇论文)
GFS ----催化剂----> HDFS
Map-Reduce ----催化剂----> MR
BigTable ----催化剂----> HBase
>.-2004年,Google公开了部分GFS和MapReduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和MapReduce机制,使Nutch性能飙升;
>.2005年Hadoop作为Lucene的子项目,Nutch的一部分正式引入Apache基金会。2006年3月份,Map-Reduce和Nutch Distributed File System(NDFS)分别被纳入称为Hadoop的项目中
>.Hadoop的名字来源于Doug Cutting儿子的玩具大象;
>.Hadoop就此诞生并迅速发展,标志着大数据时代来临;
3>.Hadoop三大发行版本
Hadoop三大发行版本
>.Apache版本最原始(最基础)的版本,对于入门学习最好
2005年Hadoop作为Lucene的子项目,Nutch的一部分正式引入Apache基金会。2006年3月份,Map-Reduce和Nutch Distributed File System(NDFS)分别被纳入称为Hadoop的项目中。
官网地址:http://hadoop.apache.org/
>.Cloudera是大型企业互联网企业中的较多(按照技术服务收费)
2.1>.2008年成立的Coudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要包括支持,咨询服务,培训;
2.2>.2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support;
2.3>.CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强;
2.4>.Coundera Manager是集群的软件分发及管理监控平台,开源在几个小时内部署好的一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持;
2.5>.Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
>.Hortonworks文档比较好,它是后起之秀起步较晚
3.1>.2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建;
3.2>.公司成立之初最吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop %的代码;
3.3>.雅虎工程副总裁,雅虎Hadoop开发团队负责人Eric Baldeschwieler 出任Hortonworks的首席执行官;
3.4>Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目还包括Ambari,一款开源的安装呵呵管理系统;
3.5>.HCatalog,一个元数据管理系统,Hcatalog现已集成到Facebook开源的Hive中。Hortonworks的Stringer开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒;
3.6>.Hortonworks开发很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Windows Server和Windows Azure在内的Microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元;
官网地址:https://hortonworks.com/products/data-platforms/
下载地址:https://hortonworks.com/downloads/#data-paltform
4>.Hadoop的优势
Hadoop的优势
>.高可靠性
因为Hadoop假设计算元素的和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。
>.高扩展性
在集群间分配任务数据,可方便的扩展数以千计的节点。
>.高效性
在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
>.高容错性
自动保存多个副本数据,并且能够自动将失败的任务重新分配。
5>.Hadoop组成
>.Hadoop概述
1.1>.Hadoop HDFS: 一个高可用,高吞吐量的分布式文件系统,提供数据存储;
1.2>.Hadoop MapReduce:一个分布式的离线并行计算框架;
1.3>.Hadoop YARN:作业调度与集群资源管理的框架,提供资源调度;
1.4>.Hadoop Common:共同模块,支持其他模块的工具模块。 >.HDFS架构概述
2.1>.NameNode(简称nn)
负责存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等等。
2.2>.DataNode(简称dn)
负载在本地文件系统存储文件块数据,以及块数据的校验和。换句话说,它负责存储真实数据。
2.3>.Secondary NameNode(简称2nn)
负责用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。 >.YARN架构概述
3.1>.ResourceManager(简称rm)
负责处理客户端请求,启动/监控ApplicationMaster,监控NodeManager,资源分配与调度。
3.2>.NodeManager(简称nm)
负责单个节点上的资源管理,处理来自ResourceManager的命令,处理来自ApplicationMaster的命令。
3.3>.ApplicationMaster
负责数据切分,为应用程序申请资源,并分配给内部任务,任务监控与容错。
3.4>.Container
负责对任务运行环境的抽象,封装CPU,内存等多位资源以及环境变量,启动命令等任务运行相关的信息。 >.MapReduce架构概述
MapReduce将计算过程分为两个阶段:即Map和Reduce(当然你在跟源码的时候发现其实在Map和Reduce阶段的前后还有很多细节!后期的文章会详细介绍的)
3.1>.Map阶段并行处理输入数据
3.2>.Reduce阶段对Map结构进行汇总
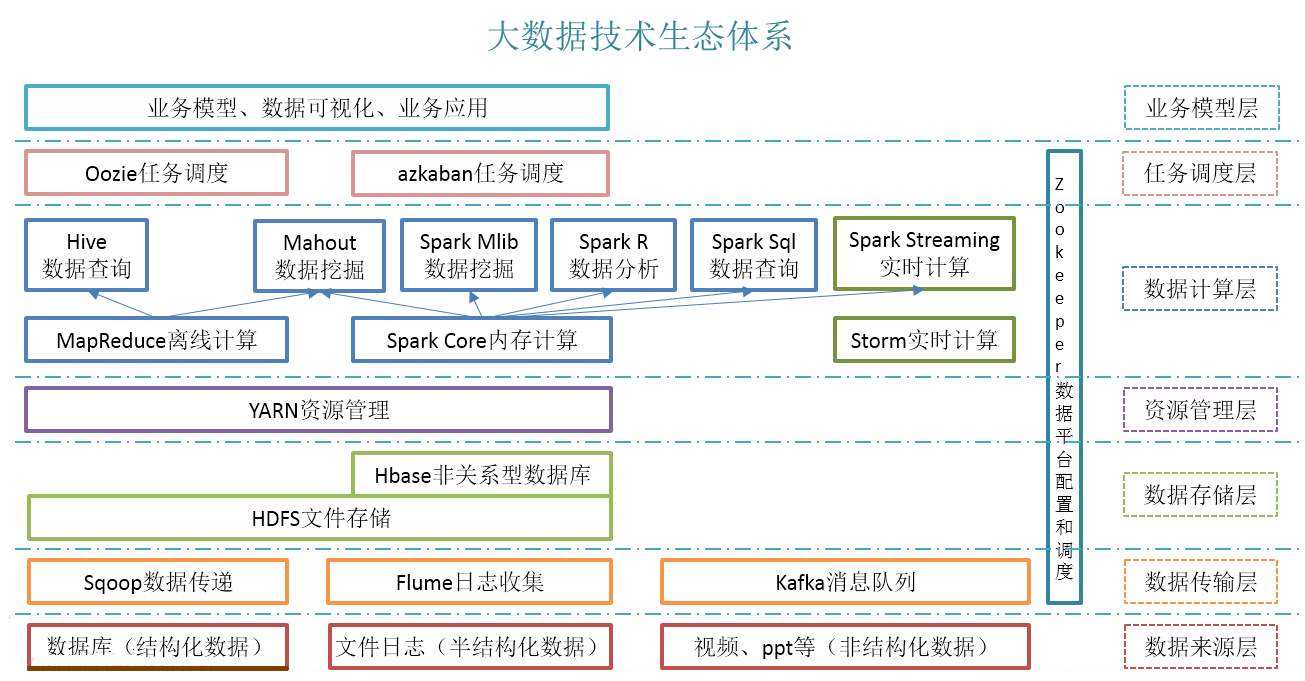
6>.大数据生态体系
Hadoop生态圈-大数据生态体系快速入门篇的更多相关文章
- Hadoop优势,组成的相关架构,大数据生态体系下的模式
Hadoop优势,组成的相关架构,大数据生态体系下的模式 一.Hadoop的优势 二.Hadoop的组成 2.1 HDFS架构 2.2 Yarn架构 2.3 MapReduce架构 三.大数据生态体系 ...
- 基于ambari搭建hadoop生态圈大数据组件
Ambari介绍1Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应.管理和监控.Ambari已支持大多数Hadoop组件,包括HDFS.MapReduce.H ...
- 大数据竞赛平台——Kaggle 入门篇
这篇文章适合那些刚接触Kaggle.想尽快熟悉Kaggle并且独立完成一个竞赛项目的网友,对于已经在Kaggle上参赛过的网友来说,大可不必耗费时间阅读本文.本文分为两部分介绍Kaggle,第一部分简 ...
- [大数据之Spark]——快速入门
本篇文档是介绍如何快速使用spark,首先将会介绍下spark在shell中的交互api,然后展示下如何使用java,scala,python等语言编写应用.可以查看编程指南了解更多的内容. 为了良好 ...
- Hadoop系列002-从Hadoop框架讨论大数据生态
本人微信公众号,欢迎扫码关注! 从Hadoop框架讨论大数据生态 1.Hadoop是什么 1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构 2)主要解决,海量数据的存储和海量数据的 ...
- Hadoop生态圈-Hive快速入门篇之HQL的基础语法
Hadoop生态圈-Hive快速入门篇之HQL的基础语法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客的重点是介绍Hive中常见的数据类型,DDL数据定义,DML数据操作 ...
- Hadoop生态圈-Hive快速入门篇之Hive环境搭建
Hadoop生态圈-Hive快速入门篇之Hive环境搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据仓库(理论性知识大多摘自百度百科) 1>.什么是数据仓库 数据 ...
- 阿里巴巴飞天大数据架构体系与Hadoop生态系统
很多人问阿里的飞天大数据平台.云梯2.MaxCompute.实时计算到底是什么,和自建Hadoop平台有什么区别. 先说Hadoop 什么是Hadoop? Hadoop是一个开源.高可靠.可扩展的分布 ...
- Hadoop! | 大数据百科 | 数据观 | 中国大数据产业观察_大数据门户
你正在使用过时的浏览器,Amaze UI 暂不支持. 请 升级浏览器 以获得更好的体验! 深度好文丨读完此文,就知道Hadoop了! 来源:BiThink 时间:2016-04-12 15:1 ...
随机推荐
- 第三个Sprint冲刺第二天(燃尽图)
- "一个程序员的生命周期"读后感
这篇文章中作者叙述了自己和大多数大学生或许都会面对的问题,即是会走过挺多的歪路,面临很多的困难和压力,但是作者却从未放弃自己真正追求的东西.对于一个过来人的经验之谈,我们应该吸取经验,在大学好好去奋斗 ...
- A11-java学习-二维数组-面向对象概念-类的编写-测试类的编写-创建对象-使用对象-递归
二维数组的内存结构和使用 引用类型的内存结构 栈区.堆区.方法区.数据栈等内存分析和介绍 面向对象.面向过程区别和发展 类型的定义 引用类型.值类型 预定义类型和自定义类型 类型与对象(实例) 对象的 ...
- 解决AJAX应用,会话超时(Session Timeout)的问题,粗略方法(不考虑使用Filter的前提下)
function ajaxPost(url, data) { var async = false; var result = {}; $.ajax({ url : url, async : async ...
- 微信内置浏览器在使用video标签时(安卓)默认全屏的原因及解决办法
根据X5论坛得到的答案是:设计如此. 腾讯真是越来越嚣张了,一家独大后用户体验都不注重了(不给程序员留活路). 听说有个申请加入vdeo白名单的,域名验证后就可以解决默认全屏(反正我是没见过申请入口, ...
- python之小应用:读取csv文件并处理01数据串
目的:读取csv文件内容,把0和1的数据串取出来,统计出现1的连续次数和各次数出现的频率次数 先读取csv文件内容: import csv def csv_read(file): list = [] ...
- nginx-日志统计
#!/bin/bash fd=/tmp/log# pv 点击量echo "###################点击量 --$pv-- #########################&q ...
- BZOJ1827[USACO 2010 Mar Gold 1.Great Cow Gathering]——树形DP
题目描述 Bessie正在计划一年一度的奶牛大集会,来自全国各地的奶牛将来参加这一次集会.当然,她会选择最方便的地点来举办这次集会.每个奶牛居住在 N(1<=N<=100,000) 个农场 ...
- BZOJ3771 Triple(FFT+容斥原理)
思路比较直观.设A(x)=Σxai.先把只选一种的统计进去.然后考虑选两种,这个直接A(x)自己卷起来就好了,要去掉选同一种的情况然后除以2.现在得到了选两种的每种权值的方案数,再把这个卷上A(x). ...
- ef 仓储模式
构建一个仓储模式. Model 大家自己创建就行了,上个图,就不多说了(我是code first) IDAL namespace IDAL { public interface IBaseReposi ...