抓取百万知乎用户信息之HttpHelper的迭代之路
 点击我前往Github查看源代码
点击我前往Github查看源代码本项目github地址:https://github.com/wangqifan/ZhiHu
什么是Httphelper?
httpelpers是一个封装好拿来获取网络上资源的工具类。因为是用http协议,故取名httphelper。
httphelper出现的背景
使用WebClient可以很方便获取网络上的资源,例如
WebClient client = new WebClient();
string html= client.DownloadString("https://www.baidu.com/");
这样就可以拿到百度首页的的源代码,由于WebClient封装性太强,有时候不大灵活,需要对底层有更细致的把控,这个时候就需要打造自己的网络资源获取工具了;
HttpHelper初级
现在着手打造自己的下载工具,刚开始时候长这样
public class HttpHelp
{
public static string DownLoadString(string url)
{
string Source = string.Empty;
HttpWebRequest request= (HttpWebRequest)WebRequest.Create(url);
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
using (Stream stream = response.GetResponseStream())
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
return Source;
}
}
程序总会出现各种异常的,这个时候加个Try catch语句
public class HttpHelp
{
public static string DownLoadString(string url)
{ string Source = string.Empty;
try{
HttpWebRequest request= (HttpWebRequest)WebRequest.Create(url);
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
using (Stream stream = response.GetResponseStream())
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
}
catch
{
Console.WriteLine("出错了,请求的URL为{0}", url);
}
return Source;
}
}
请求资源是I/O密集型,特别耗时,这个时候需要异步
public static async Task<string> DownLoadString(string url)
{
return await Task<string>.Run(() =>
{
string Source = string.Empty;
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
using (Stream stream = response.GetResponseStream())
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
}
catch
{
Console.WriteLine("出错了,请求的URL为{0}", url);
}
return Source;
}); }
HttpHelper完善
为了欺骗服务器,让服务器认为这个请求是浏览器发出的
request.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:49.0) Gecko/20100101 Firefox/49.0";
有些资源是需要权限的,这个时候要伪装成某个用户,http协议是无状态的,标记信息都在cookie上面,给请求加上cookie
request.Headers.Add("Cookie", "这里填cookie,从浏览器上面拷贝")
再完善下,设定个超时吧
request.Timeout = 5;
有些网站提供资源是GZIP压缩,这样可以节省带宽,所以请求头再加个
public static string DownLoadString(string url)
{
string Source = string.Empty;
try{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:49.0) Gecko/20100101 Firefox/49.0"; request.Headers.Add("Cookie", "这里是Cookie"); request.Headers.Add("Accept-Encoding", " gzip, deflate, br");
request.KeepAlive = true;//启用长连接 using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{ using (Stream dataStream = response.GetResponseStream())
{ if (response.ContentEncoding.ToLower().Contains("gzip"))//解压
{
using (GZipStream stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
else if (response.ContentEncoding.ToLower().Contains("deflate"))//解压
{
using (DeflateStream stream = new DeflateStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
} }
}
else
{
using (Stream stream = response.GetResponseStream())//原始
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{ Source = reader.ReadToEnd();
}
}
} }
}
request.Abort();
}
catch
{
Console.WriteLine("出错了,请求的URL为{0}", url); }
return Source;
} 请求态度会被服务器拒绝,返回429。这个时候需要设置代理,我们的请求会提交到代理服务器,代理服务器会向目标服务器请求,得到的响应由代理服务器返回给我们。只要不断切换代理,服务器不会因为请求太频繁而拒绝掉程序的请求
var proxy = new WebProxy(“Adress”,);//后面是端口号
request.Proxy = proxy;//为httpwebrequest设置代理
原理是
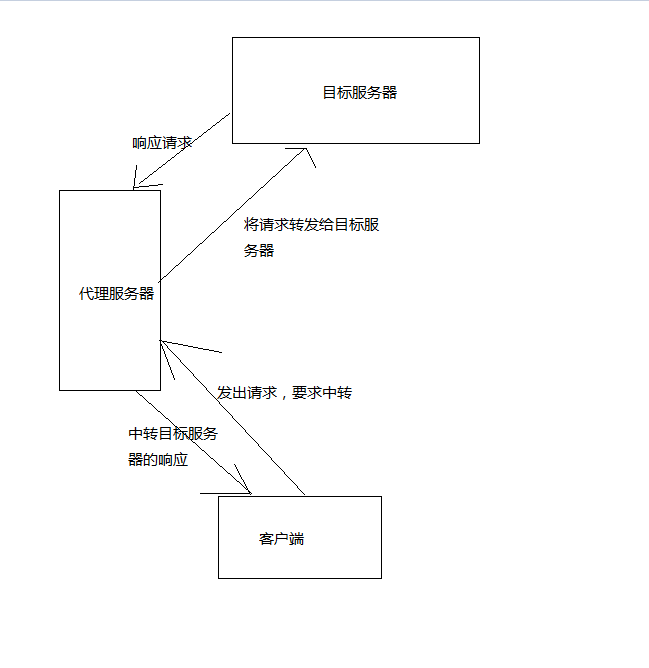
我使用的是一家叫阿布云的服务商,提供的服务比较稳定优质,就是有点贵,根据阿布云官网的示例代理,我将httphelp修改成了
public static string DownLoadString(string url)
{
string Source = string.Empty;
try
{
string proxyHost = "http://proxy.abuyun.com";
string proxyPort = "";
// 代理隧道验证信息
string proxyUser = "H71T6AMK7GREN0JD";
string proxyPass = "D3F01F3AEFE4E45A"; var proxy = new WebProxy();
proxy.Address = new Uri(string.Format("{0}:{1}", proxyHost, proxyPort));
proxy.Credentials = new NetworkCredential(proxyUser, proxyPass); ServicePointManager.Expect100Continue = false; Stopwatch watch = new Stopwatch();
watch.Start();
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:49.0) Gecko/20100101 Firefox/49.0"; request.Headers.Add("Cookie", "q_c1=17d0e600b6974387b1bc3a0117d21c50|1483348502000|1483348502000; l_cap_id=\"NjVhNGM1ODhmZWJlNDE4MDk1OTRlMDU0NTRmMmU3NzY=|1483348502|ce7951227c840cde8d8356526547cfeddece44a8\"; cap_id=\"Y2QyODU3MTg0NTViNDIwZTk4YmRhMTk5YWI5MTY1MGQ=|1483348502|892544d61b1d04265cad1ad172a5911eaf47ebe2\"; d_c0=\"AEAC7iaxFwuPToc2DY_goP_H5QnNPxMReuU=|1483348504\"; r_cap_id=\"ODA5ZDI5YTQ1M2E2NDc1OWJlMjk0Nzk1ZWY4ZjQ1NTU=|1483348505|00d0a93219de27de0e9dfa2c2a6cbe0cbf7c0a36\"; _zap=ea616f49-be5d-4f94-98d8-fdec8f7d277b; __utma=51854390.2059985006.1483348508.1483348508.1483416071.2; __utmz=51854390.1483416071.2.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmv=51854390.100-1|2=registration_date=20160110=1^3=entry_date=20160110=1; login=\"ZDczZTgyMmUzZjY1NDQ1YTkzMDk2MTk5MTNjMDIxMTM=|1483348523|f1e570e14ceed6b61720c413dd8663527aea78fc\"; z_c0=Mi4wQUJCS0c2ZmVTUWtBUUFMdUpyRVhDeGNBQUFCaEFsVk5LNmVSV0FEc1hkcFV2YUdOaDExVjBTLU1KNVZ6OFRYcC1n|1483416083|3e5d60bef695bd722a95aea50f066c394cfcba9d; _xsrf=87b1049f227fe734a9577ec9f76342b3; __utmb=51854390.0.10.1483416071; __utmc=51854390");
request.Headers.Add("Upgrade-Insecure-Requests", "");
request.Headers.Add("Cache-Control", "no-cach");
request.Accept = "*/*";
request.Method = "GET";
request.Referer = "https://www.zhihu.com/";
request.Headers.Add("Accept-Encoding", " gzip, deflate, br");
request.KeepAlive = true;//启用长连接
request.Proxy = proxy;
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{ using (Stream dataStream = response.GetResponseStream())
{ if (response.ContentEncoding.ToLower().Contains("gzip"))//解压
{
using (GZipStream stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
else if (response.ContentEncoding.ToLower().Contains("deflate"))//解压
{
using (DeflateStream stream = new DeflateStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
} }
}
else
{
using (Stream stream = response.GetResponseStream())//原始
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{ Source = reader.ReadToEnd();
}
}
} }
}
request.Abort();
watch.Stop();
Console.WriteLine("请求网页用了{0}毫秒", watch.ElapsedMilliseconds.ToString());
}
catch
{
Console.WriteLine("出错了,请求的URL为{0}", url); }
return Source;
}
抓取百万知乎用户信息之HttpHelper的迭代之路的更多相关文章
- scrapy爬取全部知乎用户信息
# -*- coding: utf-8 -*- # scrapy爬取全部知乎用户信息 # 1:是否遵守robbots_txt协议改为False # 2: 加入爬取所需的headers: user-ag ...
- Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- Python之爬虫(二十) Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- Python之爬虫(二十一) Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- 基于webmagic的爬虫小应用--爬取知乎用户信息
听到“爬虫”,是不是第一时间想到Python/php ? 多少想玩爬虫的Java学习者就因为语言不通而止步.Java是真的不能做爬虫吗? 当然不是. 只不过python的3行代码能解决的问题,而Jav ...
- python3编写网络爬虫22-爬取知乎用户信息
思路 选定起始人 选一个关注数或者粉丝数多的大V作为爬虫起始点 获取粉丝和关注列表 通过知乎接口获得该大V的粉丝列表和关注列表 获取列表用户信息 获取列表每个用户的详细信息 获取每个用户的粉丝和关注 ...
- scrapy 知乎用户信息爬虫
zhihu_spider 此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo,下载这些数据感觉也没什么用,就当为大家学习scrapy提供一个例子吧.代码地 ...
- 如何有效抓取SQL Server的BLOCKING信息
原文:如何有效抓取SQL Server的BLOCKING信息 转自:微软亚太区数据库技术支持组 官方博客 http://blogs.msdn.com/b/apgcdsd/archive/2011/12 ...
随机推荐
- order by 与 group by 区别
order by 排序查询.asc升序.desc降序 示例: select * from 学生表 order by 年龄 ---查询学生表信息.按年龄的升序(默认.可缺省.从低到高)排列显示 也可以多 ...
- iOS系列 基础篇 02 StoryBoard 故事板文件
iOS基础 02 StoryBoard 故事板文件 目录: 1. 故事板的导航特点 2. 故事板中的Scene和Segue 3. 本文最后 在上篇HelloWorld工程中有一个Main.storyb ...
- 树莓派3B更新软件
因为软件是要不断更新的,所以半个月或者一个月要升级一下软件 升级软件非常简单 在终端或者SSH里输入 sudo apt-get update && apt-get upgrade -y ...
- “会”和 "好”纯粹是两个概念
你会吗? 如果我现在问下大家你会OOP 吗?你会OOD吗? 你知道SOLID吗?你会在实际工作中运用这些原则吗? 你知道模式吗,你会在实际项目中适时引入合理的设计模式来解决项目中的代码坏味吗? 你知道 ...
- windows系统下fis3安装教程
注意:在安装fis3前必须安装node和npm,详情请见官网http://nodejs.org node版本要求 0.8.x,0.10.x, 0.12.x,4.x,6.x,不在此列表中的版本不予支持. ...
- java url encoder 的一个问题
@RequestMapping(value = {"/search"}) public String errorPath(HttpServletResponse response, ...
- angular学习笔记(二十八-附1)-$resource中的资源的方法
通过$resource获取到的资源,或者是通过$resource实例化的资源,资源本身就拥有了一些方法,$save,$delete,$remove,可以直接调用来保存该资源: 比如有一个$resour ...
- Less:优雅的写CSS代码
css是不能够定义变量的,也不能嵌套.它没有编程语言的特性.在项目开发中,常常发现有很多css代码是相同的,但我们通常都是复制然后粘贴. 举个例子:假设h5应用里主题色是#FF3A6D,可能用于文字或 ...
- 21-Python-Django进阶补充篇
1. 路由部分补充 1.1 默认值 url: url(r'^index/', views.index, {'name': 'root'}), views: def index(request,name ...
- AppBox_v2.0完整版免费下载,暨AppBox_v3.0正式发布!
文章更新: AppBox v6.0中实现子页面和父页面的复杂交互 AppBox 是基于 FineUI 的通用权限管理框架,包括用户管理.职称管理.部门管理.角色管理.角色权限管理等模块. AppBox ...