深度学习 Fine-tune 技巧总结
深度学习中需要大量的数据和计算资源(乞丐版都需要12G显存的GPU - -)且需花费大量时间来训练模型,但在实际中难以满足这些需求,而使用迁移学习则能有效
降低数据量、计算量和计算时间,并能定制在新场景的业务需求,可谓一大利器。
迁移学习不是一种算法而是一种机器学习思想,应用到深度学习就是微调(Fine-tune)。通过修改预训练网络模型结构(如修改样本类别输出个数),选择性载入预训练网络模型权重(通常是载入除最后的全连接层的之前所有层 ,也叫瓶颈层)
再用自己的数据集重新训练模型就是微调的基本步骤。 微调能够快速训练好一个模型,用相对较小的数据量,还能达到不错的结果。
微调的具体方法和技巧有很多种,这里总结了在不同场景下的微调技巧:
1)新数据集比较小且和原数据集相似。因为新数据集比较小(比如<5000),如果fine-tune可能会过拟合;又因为新旧数据集类似,我们期望他们高层特征类似,可以使用预训练网络当做特征提取器,用提取的特征训练线性分类器。
2)新数据集大且和原数据集相似。因为新数据集足够大(比如>10000),可以fine-tune整个网络。
3)新数据集小且和原数据集不相似。新数据集小,最好不要fine-tune,和原数据集不类似,最好也不使用高层特征。这时可是使用前面层的特征来训练SVM分类器。
4)新数据集大且和原数据集不相似。因为新数据集足够大,可以重新训练。但是实践中fine-tune预训练模型还是有益的。新数据集足够大,可以fine-tine整个网络。
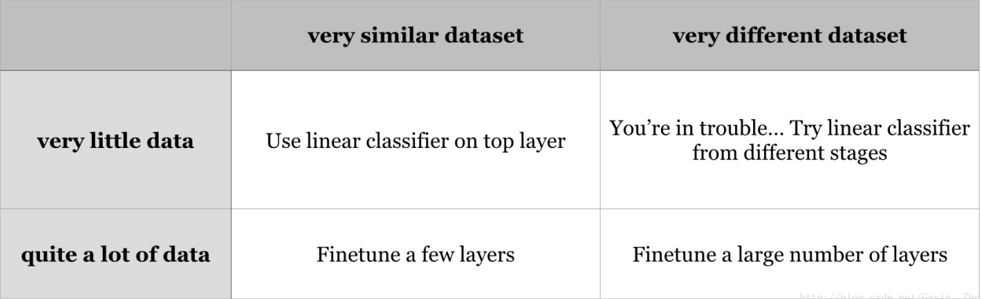
fine-tune实践建议:
1)预训练模型的限制。使用预训练模型,受限于其网络架构。例如,不能随意从预训练模型取出卷积层。但是因为参数共享,可以输入任意大小的图像;卷积层和池化层对输入数据大小没有要求;全连接层对输入大小没有要求,输出大小固定。
2)学习率。与重新训练相比,fine-tune要使用更小的学习率。因为训练好的网络模型权重已经平滑,我们不希望太快扭曲(distort)它们(尤其是当随机初始化线性分类器来分类预训练模型提取的特征时)。
深度学习 Fine-tune 技巧总结的更多相关文章
- 深度学习模型训练技巧 Tips for Deep Learning
一.深度学习建模与调试流程 先看训练集上的结果怎么样(有些机器学习模型没必要这么做,比如决策树.KNN.Adaboost 啥的,理论上在训练集上一定能做到完全正确,没啥好检查的) Deep Learn ...
- 【深度学习Deep Learning】资料大全
最近在学深度学习相关的东西,在网上搜集到了一些不错的资料,现在汇总一下: Free Online Books by Yoshua Bengio, Ian Goodfellow and Aaron C ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)---#####注:机器学习资料[篇目一](https://github.co ...
- Deep Learning Tutorial 李宏毅(一)深度学习介绍
大纲 深度学习介绍 深度学习训练的技巧 神经网络的变体 展望 深度学习介绍 深度学习介绍 深度学习属于机器学习的一种.介绍深度学习之前,我们先大致了解一下机器学习. 机器学习,拿监督学习为例,其本质上 ...
- Python深度学习读书笔记-1.什么是深度学习
人工智能 什么是人工智能.机器学习与深度学习(见图1-1)?这三者之间有什么关系?
- 【深度学习系列】关于PaddlePaddle的一些避“坑”技巧
最近除了工作以外,业余在参加Paddle的AI比赛,在用Paddle训练的过程中遇到了一些问题,并找到了解决方法,跟大家分享一下: PaddlePaddle的Anaconda的兼容问题 之前我是在服务 ...
- 吴恩达深度学习 反向传播(Back Propagation)公式推导技巧
由于之前看的深度学习的知识都比较零散,补一下吴老师的课程希望能对这块有一个比较完整的认识.课程分为5个部分(粗体部分为已经看过的): 神经网络和深度学习 改善深层神经网络:超参数调试.正则化以及优化 ...
- 深度学习与CV教程(6) | 神经网络训练技巧 (上)
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- Deep Learning(深度学习)学习笔记整理
申明:本文非笔者原创,原文转载自:http://www.sigvc.org/bbs/thread-2187-1-3.html 4.2.初级(浅层)特征表示 既然像素级的特征表示方法没有作用,那怎样的表 ...
随机推荐
- MySQL搭建主从数据库 实现读写分离
首先声明,实际生产中,网站为了提高用户体验,性能等,将数据库实现读写分离是有必要的,我们让主数据库去写入数据,然后当用户查询的时候,然后在从数据库读取数据,故能减轻数据库的压力,实现良好的用户体验! ...
- php的格式化数字函数
php格式化数字:位数不足前面加0补足 php格式化数字:位数不足前面加0补足 感谢:http://www.cnblogs.com/xiaochaohuashengmi/archive/2011/12 ...
- 新特性GTID
什么是GTID 每提交一个事务,当前的执行过程都会拿到一个唯一的标识符,此标识符不仅对其源mysql 实列是唯一的而在给定的复制环境中的所有mysql 实列也是唯一的,所哟的事务与其GTID 之间都是 ...
- wordpress怎么禁止文章复制
登陆你的网站后台--点击菜单栏的"外观"--点击"编辑"--在右侧,找到footer.php,打开它--在</body>之前加入以下代码: 1.禁止 ...
- Docker加速器(阿里云)
1. 登录阿里开发者平台: https://dev.aliyun.com/search.html,https://cr.console.aliyun.com/#/accelerator,生成专属链接 ...
- SpringCloud的DataRest(一)
一.概念与定义 Spring Data Rest 基于Spring Data的repository,可以把 repository 自动输出为REST资源, 这样做的好处: 可以免去大量的 contro ...
- Angular 学习笔记 ( CDK - Layout )
简单说就是 js 的 media query. 1. BreakpointObserver const layoutChanges = this.breakpointObserver.observe ...
- 新概念英语(1-69)The car race
新概念英语(1-69)The car race Which car was the winner in 1995 ? There is car race near our town every ye ...
- .NET:持续进化的统一开发平台
阅读文本大概需要 8 分钟. 标题使用的是进化这个词语,是因为 .NET 在不断的努力,也在不断的重构. 这篇文章的更多目的和意义在于科普,俗称"传教". # 持续进化的 .NET ...
- HTML mate标签
META标签分两大部分:HTTP标题信息(http-equiv)和页面描述信息(name). http-equiv http-equiv类似于HTTP的头部协议,它回应给浏览器一些有用的信息,以帮助正 ...