shell:正则表达式和文本处理器
1、什么是正则
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。
生活中处处都是正则:
比如我们描述:4条腿
你可能会想到的是四条腿的动物或者桌子,椅子等
继续描述:4条腿,活的
就只剩下四条腿的动物这一类了
在linux中,通配符是由shell解释的,而正则表达式则是由命令解释的,下面我们就为大家介绍三种文本处理工具/命令:grep、sed、awk,它们三者均可以解释正则。
2、grep
参数
-n 显示行号
-o 只显示匹配内容
-q 静默模式,没有任何输出,得用$?来判断执行成功没有,jiy有没有过滤到想要的内容
-l 如果匹配成功,则只将文件名打印出来,失败则不打印,通常-rl一起用,grep -rl 'root' /etc/passwd
-A 如果匹配成功,则将匹配行及其后n行一起打印出来,grep -A 2 'root' /etc/passwd
-B 如果匹配成功,则将匹配行及其前n行一起打印出来
-C 如果匹配成功,则将匹配行及其前后n行一起打印出来
-c 如果匹配成功,则将匹配到的行数打印出来,grep -c 'root' /etc/passwd
-E 等于egrep,扩展,统一都用egrep不会出错
-i 忽略大小写
-v 取反,不匹配
-w 匹配单词
正则介绍
^ 行首,egrep '^root' /etc/passwd
$ 行尾,egrep 'bash$' /etc/passwd,egrep 'ab{3}$' a.txt
. 除了换行符以外的任意单个字符,egrep '^b.n' /etc/passwd
* 前导字符的零个或多个,egrep 'ab*' a.txt
+ 前导字符的一个或多个,egrep 'ab+' a.txt
{} 规定前导字符的个数,egrep 'ab{3}' a.txt,egrep 'ab{2,5}' a.txt,egrep 'ab{3,}' a.txt
? 前导字符的0个或1个,egrep 'ab?' a.txt
.* 所有字符
[] 字符组内的任一字符,egrep '[sdfag-]' a.txt,egrep 'r[a-zA-Z]t' a.txt
[^] 对字符组内的每个字符取反(不匹配字符组内的每个字符)
^[^] 非字符组内的字符开头的行
[a-z] 小写字母
[A-Z] 大写字母
[a-Z] 小写和大写字母
[0-9] 数字
\< 单词头 单词一般以空格或特殊字符做分隔,连续的字符串被当做单词
\> 单词尾
补充: egrep 'compan(y|ies)' a.txt
posix定义的字符分类
[:alnum:] Alphanumeric characters.
匹配范围为 [a-zA-Z0-9]
[:alpha:] Alphabetic characters.
匹配范围为 [a-zA-Z]
[:blank:] Space or tab characters.
匹配范围为 空格和TAB键
[:cntrl:] Control characters.
匹配控制键 例如 ^M 要按 ctrl+v 再按回车 才能输出
[:digit:] Numeric characters.
匹配所有数字 [0-9]
[:graph:] Characters that are both printable and visible. (A space is print-
able, but not visible, while an a is both.)
匹配所有可见字符 但不包含空格和TAB 就是你在文本文档中按键盘上能用眼睛观察到的所有符号
[:lower:] Lower-case alphabetic characters.
小写 [a-z]
[:print:] Printable characters (characters that are not control characters.)
匹配所有可见字符 包括空格和TAB
能打印到纸上的所有符号
[:punct:] Punctuation characters (characters that are not letter, digits, con-
trol characters, or space characters).
特殊输入符号 +-=)(*&^%$#@!~`|\"'{}[]:;?/>.<,
注意它不包含空格和TAB
这个集合不等于^[a-zA-Z0-9]
[:space:] Space characters (such as space, tab, and formfeed, to name a few).
[:upper:] Upper-case alphabetic characters.
大写 [A-Z]
[:xdigit:] Characters that are hexadecimal digits.
16进制数 [0-f]
使用方法:
[root@seker ~]# grep --color '[[:alnum:]]' /etc/passwd
3、sed(最终的目的是编辑,先sed -r ' ' a.txt确保无误后再sed -ri ' ' a.txt >> b.txt)
流编辑器 stream editer,是以行为单位的处理程序
sed 流编辑器 stream editer
语法:sed [options] 'command' in_file[s]
options 部分
-n 静默模式
-e 可以指定多个规则和grep相同,sed -e '' -e '' -e ''
-i 加上-i可以直接对文件更改
-f
command 部分
'[地址1,地址2] [函数] [参数(标记)]'
定址的方法 1.数字 2.正则
数字
十进制数
1 单行
1,3 范围 从第一行到第三行
2,+4 匹配行后若干行
4,~3 从第四行到下一个3的倍数行
2~3 第二行起每间隔三行的行
$ 尾行
1! 除了第一行以外的行
正则
正则必须用//包裹起来
扩展正则需要用 -r 参数或转义 以后用的时候就用sed -r '' 原理同egrep
数字定址:sed -n '1p' /etc/passwd
正则定址:sed -n '/ / ' /etc/passwd
sed '3d' test 删除第3行
sed '1,3d' test 删除1-3行
sed '1d;3d' test 删除第1行和第3行
sed '3p' test 打印第3行(运行结果会全打印出来有两个第3行)
sed -n '3p' test 只打印第3行
sed '3c 11111' test 替换第3行为11111
sed '3a 11111' test 在第3行后追加一行11111
sed '3i 11111' test 在第3行前插入一行11111
sed '/^root/d' /etc/passwd 删除root开头的行
sed '/bash$/d' /etc/passwd 删除bash结尾的行
sed '/.*sb.*/d' a.txt 删除所有带sb的行
sed '/^s/c 111111' /etc/passwd 把该文件中以s开头的行改为11111
sed 's/sb/SB/' a.txt 把所有sb换成SB,没有定址就是全部,但是此命令一行当中如果出现多个sb只会换第一个,要想全部改的话命令应为sed 's/sb/SB/g' a.txt
sed '/alex/s/sb/SB/g' a.txt 把alex所在的那行的所有sb换成SB,这使用正则定址sed '/ /s/ / /g'
sed -r '/^[0-9]([a-Z]+)$/s/sb/SB/g' 同上
sed -r 's/^([a-Z]+)([^a-Z])/ /g' /etc/passwd 将passwd文件中每行的第一个单词和冒号删掉,也就是替换为空
sed -r 's/^([a-Z]+)([^a-Z])/\2/g' /etc/passwd 每个()内的内容代表一部分,这里是留第二部分删第一部分,即只删除每行的第一个单词,冒号还在
sed -r 's/^([a-Z]+)([^a-Z])/\2\1/g' /etc/passwd 调换1和2的位置,即调换第一个单词和冒号的位置
sed -r 's/^([^a-Z]+)([a-Z]+)$/\1/g' /etc/passwd 删除最后一个单词
sed -r 's/()()()()()/\5\4\3\2\1/g';sed -r 's/()()()()()/\5\1\3\4\2/g'
sed -r 's/^(.)(.*)$/\2/' /etc/passwd 删除每行的第一个字符
正则介绍
^ 行首
$ 行尾
. 除了换行符以外的任意单个字符
* 前导字符的零个或多个
.* 所有字符
[] 字符组内的任一字符
[^] 对字符组内的每个字符取反(不匹配字符组内的每个字符)
^[^] 非字符组内的字符开头的行
[a-z] 小写字母
[A-Z] 大写字母
[a-Z] 小写和大写字母
0-9] 数字
\< 单词头 单词一般以空格或特殊字符做分隔,连续的字符串被当做单词
\> 单词尾
扩展正则 加 -r 参数 或转义
sed -n '/roo\?/p' /etc/passwd
sed -rn '/roo?/p' /etc/passwd
? 前导字符零个或一个
+ 前导字符一个或多个
abc|def abc或def
a(bc|de)f abcf 或 adef
x\{m\} x出现m次
x\{m,\} x出现m次至多次(至少m次)
x\{m,n\} x出现m次至n次
函数
增删改
a 后插
c 替换
i 前插
d 删除
输入输出
p 打印匹配的行 一般和 -n 参数连用,以屏蔽默认输出
r 从文件中读入
w 写入到文件中
控制流
! 命令取反 例: 1!d 删除第一行以外的行
{} 命令组合 命令用分号分隔 {1h;G} 可以理解为 -e 参数的另一种写法
= 打印行号(输入行的号码,而非处理的次数行号) 例如: sed -n '2{=;p}' infile
n 读入下一行到模式空间 例:'4{n;d}' 删除第5行
N 而是追加下一行到模式空间,再把当前行和下一行同时应用后面的命令
4、awk(可以处理有格式的文件,-F可以指定分隔符)
数字定址和行定址
awk -F: '{print $1} ' /etc/passwd 指定以:为分隔符,该命令结果是去除所有行以:为分隔符的第一部分
awk -F: '{print $0}' /etc/passwd $0代表取所有
awk -F: '{print $1,NF}' /etc/passwd 输出每一行内容的第一段和段数,NF 就表示段数
awk -F: '{print $1,$NF}' /etc/passwd 打印出每一行的第一段和最后一段内容
awk -F: '{print NR,$1}' /etc/passwd 打印出行号和每行的第一段内容
awk -F: 'NR==1{print NR,$1}' /etc/passwd 只打印第一行的行号和第一段内容
awk -F: 'NR<=3{print NR,"------",$1}' /etc/passwd 打印前三行行号和第一段内容,并且行号和内容之间有-------
awk -F: 'NR>=3 && NR<=5{print NR,$1}' /etc/passwd 打印第三行到第五行的行号和第一段内容
awk -F: 'NR<=3 || NR>=5{print NR,$1}' /etc/passwd 打印第三行之前和第五行之后的行号和第一段内容
正则定址 awk -F: '//{}' /etc/passwd
awk -F: '/nologin$/{print $1} ' /etc/passwd 这是用行匹配正则,打印以nologin结尾的行的第一段内容
awk -F: '$1~/^r.*t$/{print $3}' /etc/passwd ~表示$1即第一段匹配正则(在这里也就是用户名匹配正则),这条命令是,打印第一段以r开头t结尾的 行的 第三段
awk -F: '$1~/^r.*t$/{print NR,$3}' /etc/passwd 就比上边多了个行号
awk -F: '$1=="root"{print NR,$3}' /etc/passwd $1不仅能够匹配正则还能匹配内容
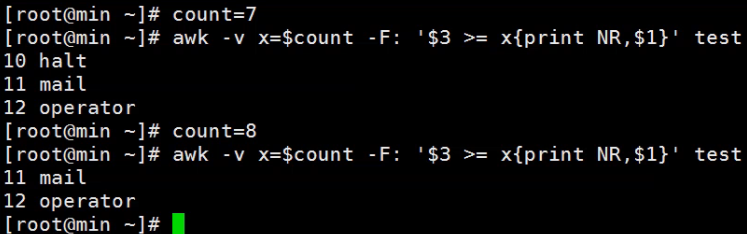
awk -F: '$3>=7{print NR,$3}' /etc/passwd 打印出uid大于等于7的行号和uid
awk -v -v 定义变量并赋值 也可以借用次方式从shell变量中引入
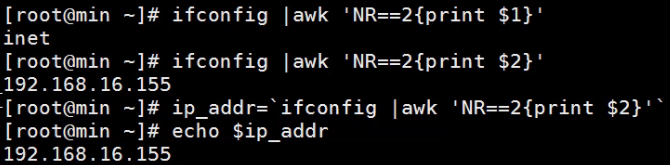
ifconfig |awk 'NR==2{print $1}' 当awk后面不加-F时,默认以空格为分隔符,所以该命令是取ifconfig命令输出结果中的第二行的第一段内容
ifconfig |awk 'NR==2{print $2}' 取ifconfig命令输出结果中的ip地址
awk详细
语法
awk [options] 'commands' files
option
-F 定义字段分隔符,默认的分隔符是连续的空格或制表符
使用option中的-F参数定义间隔符号
用$1,$2,$3等的顺序表示files中每行以间隔符号分隔的各列不同域
NF变量表示当前记录的字段数
-v 定义变量并赋值 也可以借用次方式从shell变量中引入
command
读前处理 行处理 读后处理
1.读前处理 BEGIN{awk_cmd1;awk_cmd2}
2.行处理:定址 命令
定址方法: 正则,变量,比较和关系运算
正则需要用//包围起来
^ 行首
$ 行尾
. 除了换行符以外的任意单个字符
* 前导字符的零个或多个
.* 所有字符
[] 字符组内的任一字符
[^] 对字符组内的每个字符取反(不匹配字符组内的每个字符)
^[^] 非字符组内的字符开头的行
[a-z] 小写字母
[A-Z] 大写字母
[a-Z] 小写和大写字母
[0-9] 数字
\< 单词头 单词一般以空格或特殊字符做分隔,连续的字符串被当做单词
\> 单词尾
扩展正则 加 -r 参数 或转义
sed -n '/roo\?/p' /etc/passwd
sed -rn '/roo?/p' /etc/passwd
? 前导字符零个或一个
+ 前导字符一个或多个
abc|def abc或def
a(bc|de)f abcf 或 adef
x\{m\} x出现m次
x\{m,\} x出现m次至多次(至少m次)
x\{m,n\} x出现m次至n次
NR变量定址
NR 表示AWK读入的行数
FNR表示读入行所在文件中的行数
# awk '{print NR,FNR,$1}' file1 file2
1 1 aaaaa
2 2 bbbbb
3 3 ccccc
4 1 dddddd
5 2 eeeeee
6 3 ffffff
#
逻辑运算 可直接引用域进行运算
== >= <= != > < ~ !~
# awk 'NR==1 {print}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
#
3.命令 {print $0}
4.读后处理 END {awk_cmd1;awk_cmd2;}
AWK变量
NR 当前记录的个数(全部文件连接后的统计)
FNR 当前记录的个数(仅为当前文件的统计,非全部)
FS 字段分隔符 默认为连续空格或制表符,可以使用多个不同的符号做分隔符 -F[:/]
OFS 输出字符的分隔符 默认是空格
# awk -F: 'OFS="=====" {print $1,$2}' /etc/passwd
root=====x
NF 当前读入行的字段个数
ORS 输出记录分隔符 默认是换行
# awk -F: 'ORS="=====" {print $1,$2}' /etc/passwd
root x=====bin x=====
FILENAME 当前文件名
引用shell变量的方法
# a=root
# awk -v var=$a -F: '$1 == var {print $0}' /etc/passwd
或者 把整个命令拆开传递,让shell变量外露,
# awk -F: '$1 == "'$a'" {print $0}' /etc/passwd
# a=NF
# awk -F: '{print $'$a'}' /etc/passwd
操作符
赋值
= += -= /= *=
逻辑与 逻辑或 逻辑非
&& || !
匹配正则或不匹配,正则需要用 /正则/ 包围住
~ !~
关系 比较字符串时要把字符串用双引号引起来
< <= > >= != ==
字段引用
$ 字段引用需要加$,而变量引用直接用变量名取
运算符
+ - * / % ++ --
转义序列
\\ \自身
\$ 转义$
\t 制表符
\b 退格符
\r 回车符
\n 换行符
\c 取消换行
5、其他命令
cat a.txt |sort sort会将所有重复的行排列在一起
cat a.txt |sort |uniq uniq是去重,此命令是排序加去重
cat a.txt |sort |uniq -c 可以查看去重数
cat test |cut -d: -f1 -d指定以:为分割符,-f1取第一部分 取test文件以:为分割符的每行的第一段
cat test |cut -d: -f1 取test文件以:为分割符的每行的第一段和第三段
du -sh /boot/ 查看文件或目录的大小
find / -type f 找根目录下得普通文件
find / -name "*.txt" 找跟下的txt文件
find / -size +30M 找出根下大于30M的文件
find / -size +10M -size -30M 找出根下大于10M小于30M的文件
find / -size +2M -type f -name \*.txt 找出根下的大于2M的.txt格式的普通文件
dd if=/dev/zero of=/a.txt bs=20M count=1 将a.txt中1个20M的block块写到硬盘上,该命令是不专业的测试硬盘读写速度命令
gcc hello.c -o hello 将C语言编译好的文件解释为二进制格式
shell:正则表达式和文本处理器的更多相关文章
- Linux 正则表达式与文本处理器 三剑客
Linux 正则表达式与文本处理器 三剑客 一.正则表达式 正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法.或者说:正则就是用来描述一类事物的规则. 在linu ...
- Shell正则表达式和文本处理工具
作业一:整理正则表达式博客 一.什么是正则 正则就是用一些具有特殊含义的符号组合而成(称为正则表达式)来描述字符或者字符串的方法.或者说:正则就是用来描述一类事物的规则. 通配符是由shell解释得. ...
- 文本处理三剑客与shell正则表达式
文本处理三剑客 提到对于文本的处理上,除了vim这个强大的编辑器之外,还有使用命令的形式去处理你要处理的文本,而不需要手动打开文本再去编辑.这样做的好处是能够以shell命令的形式将编辑和处理文本的工 ...
- linux shell 正则表达式(BREs,EREs,PREs)差异比较
linux shell 正则表达式(BREs,EREs,PREs)差异比较 则表达式:在计算机科学中,是指一个用来描述或者匹配一系列符合某个句法规则的字符 串的单个字符串.在很多文本编辑器或其他工具里 ...
- linux shell 正则表达式(BREs,EREs,PREs)的比较
原文 : linux shell 正则表达式(BREs,EREs,PREs)差异比较 在使用 linux shell的实用程序,如awk,grep,sed等,正则表达式必不可少,他们的区别是什么 ...
- shell(shell函数、shell正则表达式)
本章内容 shell函数 shell正则表达式 1.shell函数 linux shell 可以用户定义函数,然后在shell脚本中可以随便调用. 格式: funname () { CMD #函数体 ...
- Shell 正则表达式详解
Shell 正则表达式 什么是正则表达式? 正则表达式在每种语言中都会有,功能就是匹配符合你预期要求的字符串. 为什么要学正则表达式? 在企业工作中,我们每天做的linux运维工作中,时刻都会面对大量 ...
- 我们一起来学Shell - 正则表达式
文章目录 什么是正则表达式 正则表达式元字符 正则表达式应用举例 POSIX 方括号表达式 POSIX 字符集列表: 我们一起来学Shell - 初识shell 我们一起来学Shell - shell ...
- jquery正则表达式显示文本框输入范围 只能输入数字、小数、汉字、英文字母的方法
正则表达式限制文本框只能输入数字 许多时候我们在制作表单时需要限制文本框输入内容的类型,下面我们用正则表达式限制文本框只能输入数字.小数点.英文字母.汉字等各类代码.1.文本框只能输入数字代码(小数点 ...
随机推荐
- 什么是IPFS?(一)
写在前面: 今天先写到这里, 关于IPFS的所有事情小编都想快点告诉大家, 但毕竟精力有限, 小编尽量抽出时间提供更多的关于IPFS的信息. ----------------------------- ...
- 标准mysql(x64) Windows版安装过程
mysql x64不提供安装器,不提供安装器,不提供安装器-- 每次查英文文档有点慢,不够简. 5.7.6以后的64位zip包下载后解压是没有data目录的. 进入解压后的bin目录:(我用的powe ...
- MySQL——delete 和 truncate 以及 drop 区别
delete 和 truncate 以及 drop 区别 (个人理解,如有错误,请指出) delete < truncate < drop 删除方式: truncate 只删除数据.逐条 ...
- 基于JavaMail向邮箱发送邮件
参考:http://blog.csdn.net/ghsau/article/details/17839983 http://blog.csdn.net/never_cxb/article/detail ...
- 简述Java三大特性
1.面向对象有三大特性,分别是:封装.继承和多态.2.封装:面向对象的封装就是把描述一个对象的属性和行为的代码封装在一个类中,有些属性是不希望公开的,或者说被其他对象访问的,所以我们使用private ...
- STL --> list用法
List介绍 Lists将元素按顺序储存在链表中.与 向量(vectors)相比, 它允许快速的插入和删除,但是随机访问却比较慢. assign() // 给list赋值 back() // 返回最后 ...
- [jdoj1817]Drainage Ditches_网络流
Drainage Ditches jdoj-1817 题目大意:网络流裸求最大流 注释:n(点数),m(边数)<=200. 想法:裸的网络流求最大流,用bfs+dfs,美其名曰dinic. 没有 ...
- 在Anacoda中管理多个版本Python
win10. 在cmd窗口中输入 conda info --envs 或者 conda env list 查看已经安装的环境,当前活动的环境前会加*号. 在cmd窗口(终端窗口)或anaconda p ...
- Spring Boot 入门教程
Spring Boot 入门教程,包含且不仅限于使用Spring Boot构建API.使用Thymeleaf模板引擎以及Freemarker模板引擎渲染视图.使用MyBatis操作数据库等等.本教程示 ...
- Android破解心得——记学习七少月安卓大型安全公开课
第一课 讲解了关于在安卓破解之中环境的配置及所需要用到的软件,重要的软件是Androidkiller,安卓逆向助手 第二课讲解了java与smali的关系,从smail角度详细的分析了一个简单的Hel ...