hbase 预分区与自动分区
我们知道,HBASE在创建表的时候,会自动为表分配一个Region,
当一个Region过大达到默认的阈值时(默认10GB大小),HBase中该Region将会进行split,分裂为2个Region,以此类推。
表在进行split的时候,会耗费大量的资源,频繁的分区对HBase的性能有巨大的影响。
所以,HBase提供了预分区功能,即用户可以在创建表的时候对表按照一定的规则分区。
假设我们初始给它10个Region,那么导入大量数据的时候,就会均衡到10个里面,显然比1个Region要好很多。
可是我们应该创建多少个Region呢?显然没有具体答案,要结合业务,根据表的rowkey进行设计。
一.强制拆分
预分区方法:
1.hbase shell 预分区
建立分区前,要先了解表的rowkey格式,rowkey为:两位随机数+时间戳+客户id
两位随机数的范围从00-99,划分范围:小于10,10-20,20-30,30-40,40-50,50-60,60-70,70-80,90+
hbase(main):001:0> create 'log1', 'cf1', SPLITS => ['10','20','30','40','50','60','70','80','90']
启动webUI
vi hbase-site.xml
添加
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
浏览器中:
http://h201:60010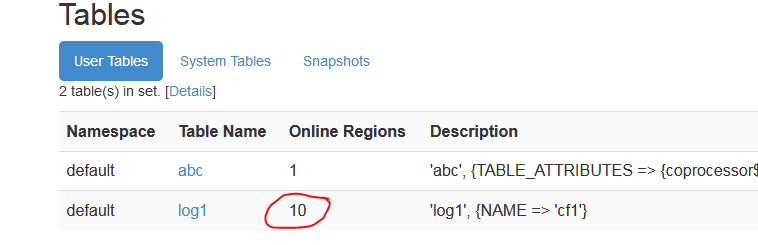
通过配置文件加载
[hadoop@h201 ~]$ cat rs.txt
10
20
30
40
50
60
70
80
90
hbase(main):003:0> create 'log2', 'cf1', SPLITS_FILE =>'/home/hadoop/rs.txt'
2.HBASE API 预分区
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.util.Bytes; public class Cp {
public static void main(String[] args) {
HBaseConfiguration config = new HBaseConfiguration();
config.set("hbase.zookeeper.quorum", "h201,h202,h203");
String tablename = new String("ctest1");
try{
HBaseAdmin admin = new HBaseAdmin(config);
if (admin.tableExists(tablename)) {
admin.disableTable(tablename);
admin.deleteTable(tablename);
} HTableDescriptor tableDesc = new HTableDescriptor(tablename);
tableDesc.addFamily(new HColumnDescriptor("cf1")); byte[][] splitKeys = {
Bytes.toBytes("10"),
Bytes.toBytes("20"),
Bytes.toBytes("30")
}; admin.createTable(tableDesc, splitKeys);
admin.close();
}catch(IOException e) {
e.printStackTrace();
}
}
}
验证:
webUI查看
ctest1有4个 预分区
====================================================
二.自动拆分(Auto splitting)
1.
0.94 版本之前采用的是 ConstantSizeRegionSplitPolicy 策略。
这个策略非常简单,从名字上就可以看出这个策 略就是按照固定大小来拆分Region。它唯一用到的参数是: hbase.hregion.max.filesize, 默认值是 10G, 也就是当 Region 的大小达到 10G 的时候, 会自动拆分成两个 Region.
2.
0.94 版本之后,有了 IncreasingToUpperBoundRegionSplitPolicy 策略。并且默认使用的这种策略。这种策略从名字上就可以看出是限制不断增长的文件尺寸的策略。
这种策略使用的最大store file size依据 Min(R^2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”),R代表同一台Region Server节点上的region的个数。比如,在默认memstore flush size为128MB且默认的max store size为10G时。(R为region的个数)
第一次拆分大小为:min(10G,1*1*128M)=128M
第二次拆分大小为:min(10G,3*3*128M)=1152M
第三次拆分大小为:min(10G,5*5*128M)=3200M
第四次拆分大小为:min(10G,7*7*128M)=6272M
第五次拆分大小为:min(10G,9*9*128M)=10G
第五次拆分大小为:min(10G,11*11*128M)=10G
可以看到,只有在第四次之后的拆分大小才为10G
hbase 预分区与自动分区的更多相关文章
- Hive静态分区和动态分区
一.静态分区 1.创建分区表 hive (default)> create table order_mulit_partition( > order_number string, > ...
- Hbase预分区种子生成
提前生成Hbase预分区种子,在创建Hbase表时也进行相应的预分区,同时设置预分区的个数,预分区的范围对应Hbase监控页面的Region Server的start key与End key,从而使数 ...
- 大数据量场景下storm自定义分组与Hbase预分区完美结合大幅度节省内存空间
前言:在系统中向hbase中插入数据时,常常通过设置region的预分区来防止大数据量插入的热点问题,提高数据插入的效率,同时可以减少当数据猛增时由于Region split带来的资源消耗.大量的预分 ...
- storm自定义分组与Hbase预分区结合节省内存消耗
Hbas预分区 在系统中向hbase中插入数据时,常常通过设置region的预分区来防止大数据量插入的热点问题,提高数据插入的效率,同时可以减少当数据猛增时由于Region split带来的资源消耗. ...
- fedora22切换用户windows分区不能自动挂载
新建立一个用户后,然后登陆后,再次登出,登陆原来的账户windows分区不能自动挂载
- ubuntu server下建立分区表/分区/格式化/自动挂载(转)
link:http://www.thxopen.com/linux/2014/03/30/Linux_parted.html 流程为:新建分区-->格式化分区-->挂载分区 首先弄明白分区 ...
- MySql自动分区
自动分区需要开启MySql中的事件调度器,可以通过如下命令查看是否开启了调度器 show variables like '%scheduler%'; 如果没开启的话通过如下指令开启 ; 1.创建一个分 ...
- 为已有表快速创建自动分区和Long类型like 的方法-Oracle 11G
对上一篇文章进行实际的运用.在工作中遇到有一张大表(五千万条数据),在开始的时候忘记了创建自动分区,导致现在使用非常不方便,查询的速度非常的满,所以就准备重新的分区表,最原始方法是先创建新的分区表,然 ...
- Oracle12c:创建主分区、子分区,实现自动分区插入效果
单表自动单个分区字段使用方式,请参考:<Oracle12c:自动分区表> 两个分区字段时,必须一个主分区字段和一个子分区字段构成(以下代码测试是在oracle12.1版本): create ...
随机推荐
- 【转载】通俗易懂,什么是.NET?什么是.NET Framework?什么是.NET Core?
本文转载自:http://www.cnblogs.com/1996V/p/9037603.html [尊重作者原创,转载说明出处!感谢作者“小曾看世界”分享! ] 什么是.NET?什么是.NET Fr ...
- C#动态调用泛型类、泛型方法
在制作一个批量序列化工具时遇到了如下问题,在此记录一下,仅供参考. 主程序加载另一个程序集,将其中的所有类取出,然后对这些类分别调用泛型类或泛型方法.控制台程序解决方案如下: Main工程:提供Wor ...
- mysql 多实例部署
Centos7.6 部署3个Mariadb 实例 [root@localhost ~]# yum install mariadb-server -y # 创建对应的目录文件 [root@localho ...
- 理解css之position属性
之前css学的一直不精致而且没有细节,为了成为一个完美的前端工作人员,所以决定重新学习css的属性.当然会借鉴MDZ文档(MDZ文档)或其他博主的经验来总结.在这里会注明借鉴或引用文章的出处.侵权即删 ...
- 万马齐喑究可哀-中文编程的又一波"讨论"
刚申诉了自动折叠, 还是把回答转帖一下: 吴烜:假设中国人最先开发电脑和设计程序语言,那么各种程序语言会使用汉字吗? 这种有明显倾向性的问题怎么还有市场呢...不管谁先开发的电脑(就不论算盘之类是不是 ...
- Beanstalkd工作队列
Beanstalkd工作队列Beanstalkd 是什么Beanstalkd是目前一个绝对可靠,易于安装的消息传递服务,主要用例是管理不同部分和工人之间的工作流应用程序的部署通过工作队列和消息堆栈,类 ...
- sqlserver2014无法打开报Cannot find one or more components_修复方案
前言:我跟网上大家的原因基本一样,就是好久没用sqlserver了,中间也对VS进行过卸载升级等,突然有一天发现,打开Sqlserver时打不开了,出了一个弹框:Cannot find one or ...
- 在linux中访问macos 下的分区。
花钱的解决方案是找专业的: Paragon Software 他们家有各种套件,让你在window Linux 都能访问到苹果分区里面的内容. 但是Windows删除了它的驱动之后一开机就蓝屏. ...
- 【Spring源码分析系列】ApplicationContext 相关接口架构分析
[原创文章,转载请注明出处][本文地址]http://www.cnblogs.com/zffenger/p/5813470.html 在使用Spring的时候,我们经常需要先得到一个Applicati ...
- Service Fabric 与 Ocelot 集成
概要 云应用程序通常都需要使用前端网关,为用户.设备或其他应用程序提供同一个入口点. 在 Service Fabric 中,网关可以是任意无状态服务(如 ASP.NET Core 应用程序) . 本文 ...