无忧代理免费ip爬取(端口js加密)
起因
为了训练爬虫技能(其实主要还是js技能…),翻了可能有反爬的网站挨个摧残,现在轮到这个网站了:http://www.data5u.com/free/index.shtml
解密过程
打开网站,在免费ip的列表页查看元素选一个端口,发现表示端口的元素class属性上有可疑的东西(代理ip类网站的反爬总是这么没有创意…):
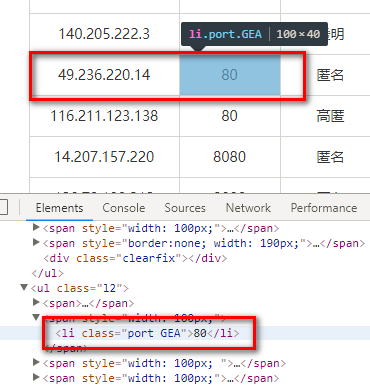
上面的“GEA”很像是密文存储的东西,怀疑端口号是页面加载完再用js计算出来填充上的,要证明的话也很简单,只需要对照下这个元素当前的值和刚下载下来的时候值是否一致,在控制台查看元素看到的是内存中元素的当前状态,查看页面源代码的才是页面被下载来那一刻的状态,右键-->查看网页源代码。搜索“49.236.220.14”,发现端口号果然不一样,页面被下载下来时是8916,现在显示的却是80.

解密逻辑在这个js中:http://www.data5u.com/theme/data5u/javascript/pde.js?v=1.0,原始的js进行了压缩,使用之前写过的展开eval的方法进行eval展开并格式化(注意需要eval展开两次):
var _$ = ['\x2e\x70\x6f\x72\x74', "\x65\x61\x63\x68", "\x68\x74\x6d\x6c", "\x69\x6e\x64\x65\x78\x4f\x66", '\x2a', "\x61\x74\x74\x72", '\x63\x6c\x61\x73\x73', "\x73\x70\x6c\x69\x74", "\x20", "", "\x6c\x65\x6e\x67\x74\x68", "\x70\x75\x73\x68", '\x41\x42\x43\x44\x45\x46\x47\x48\x49\x5a', "\x70\x61\x72\x73\x65\x49\x6e\x74", "\x6a\x6f\x69\x6e", ''];
$(function() {
$(_$[0])[_$[1]](function() {
var a = $(this)[_$[2]]();
if (a[_$[3]](_$[4]) != -0x1) {
return
};
var b = $(this)[_$[5]](_$[6]);
try {
b = (b[_$[7]](_$[8]))[0x1];
var c = b[_$[7]](_$[9]);
var d = c[_$[10]];
var f = [];
for (var g = 0x0; g < d; g++) {
f[_$[11]](_$[12][_$[3]](c[g]))
};
$(this)[_$[2]](window[_$[13]](f[_$[14]](_$[15])) >> 0x3)
} catch(e) {}
})
})
上面这段js仍然是不可读的,可以看到一些关键词被抽取出来放到了一个字典数组中,字典数组中的字面值还被十六进制编码了,所以接下来需要写点js将其转换为可读形式,下面是转换的代码:
<html>
<head></head>
<body>
<script type="text/code-template" id="functionBody">
$(function() {
$(_$[0])[_$[1]](function() {
var a = $(this)[_$[2]]();
if (a[_$[3]](_$[4]) != -0x1) {
return
};
var b = $(this)[_$[5]](_$[6]);
try {
b = (b[_$[7]](_$[8]))[0x1];
var c = b[_$[7]](_$[9]);
var d = c[_$[10]];
var f = [];
for (var g = 0x0; g < d; g++) {
f[_$[11]](_$[12][_$[3]](c[g]))
};
$(this)[_$[2]](window[_$[13]](f[_$[14]](_$[15])) >> 0x3)
} catch(e) {}
})
})
</script>
<script type="text/javascript"> var _$ = ['\x2e\x70\x6f\x72\x74', "\x65\x61\x63\x68", "\x68\x74\x6d\x6c", "\x69\x6e\x64\x65\x78\x4f\x66", '\x2a', "\x61\x74\x74\x72", '\x63\x6c\x61\x73\x73', "\x73\x70\x6c\x69\x74", "\x20", "", "\x6c\x65\x6e\x67\x74\x68", "\x70\x75\x73\x68", '\x41\x42\x43\x44\x45\x46\x47\x48\x49\x5a', "\x70\x61\x72\x73\x65\x49\x6e\x74", "\x6a\x6f\x69\x6e", ''];
let functionBody = document.getElementById("functionBody").innerHTML;
let readableFunctionBody = functionBody.replace(/_\$\[[0-9]+\]/g, x => "'" + eval(x) + "'");
document.write(readableFunctionBody); </script>
</body>
</html>
转换并格式化:
$(function() {
$('.port')['each'](function() {
var a = $(this)['html']();
if (a['indexOf']('*') != -0x1) {
return
};
var b = $(this)['attr']('class');
try {
b = (b['split'](' '))[0x1];
var c = b['split']('');
var d = c['length'];
var f = [];
for (var g = 0x0; g < d; g++) {
f['push']('ABCDEFGHIZ' ['indexOf'](c[g]))
};
$(this)['html'](window['parseInt'](f['join']('')) >> 0x3)
} catch(e) {}
})
})
可以看到解密逻辑已经很清晰了,就是把端口元素上第二个class(假定从1开始),也就是那个奇怪的字符串拿出来,然后在'ABCDEFGHIZ'中找其位置,最后把找到的位置坐标按顺序拼接并转为数字然后除以8,即得到最终的端口号,根据解密逻辑写出java代码:
private static int decodePort(String rawContent) {
String rawNum = Stream.of(rawContent.split(""))
.map("ABCDEFGHIZ"::indexOf)
.map(Object::toString)
.collect(Collectors.joining());
return Integer.parseInt(rawNum) >> 3;
}
一个简单的抓取demo:
package org.cc11001100.t1; import javaslang.Tuple;
import javaslang.Tuple2;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements; import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLEncoder;
import java.util.Collections;
import java.util.List;
import java.util.Objects;
import java.util.stream.Collectors;
import java.util.stream.Stream; import static java.util.stream.Collectors.toList; /**
* 这个网站的代理: http://www.data5u.com/free/index.shtml
* 端口有加密
*
* @author CC11001100
*/
public class Data5UProxyGrab { private static int decodePort(String rawContent) {
String rawNum = Stream.of(rawContent.split(""))
.map("ABCDEFGHIZ"::indexOf)
.map(Object::toString)
.collect(Collectors.joining());
return Integer.parseInt(rawNum) >> 3;
} private static List<Tuple2<String, Integer>> parse(String url) {
try {
Document document = Jsoup.parse(new URL(url), 3000);
return document.select(".wlist ul li[style=text-align:center;] ul.l2")
.stream()
.map(elt -> {
String ip = elt.select("span").first().text();
Elements portElt = elt.select(".port");
if (!portElt.isEmpty() && !portElt.html().contains("*")) {
String[] ss = portElt.attr("class").split("\\s+");
if (ss.length >= 2) {
return Tuple.of(ip, decodePort(ss[1]));
}
}
return null;
})
.filter(Objects::nonNull)
.collect(toList());
} catch (IOException e) {
e.printStackTrace();
}
return Collections.emptyList();
} /**
* 按照国家抓取
*/
public static List<Tuple2<String, Integer>> grabByCountry() throws IOException {
String url = "http://www.data5u.com/free/country/%s/index.html";
return Jsoup.parse(new URL(String.format(url, urlEncode("中国"))), 3000)
.select("#areaDist ul.bigr span")
.stream()
.map(elt -> elt.attr("title"))
.flatMap(countryName -> parse(String.format(url, urlEncode(countryName))).stream())
.distinct()
.collect(toList());
} private static String urlEncode(String raw) {
try {
return URLEncoder.encode(raw, "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return "";
} public static void main(String[] args) throws IOException {
grabByCountry().forEach(System.out::println);
} }
更省力的方案
上面都太麻烦了,只是为了锻炼一下js技能,其实观察一下发现这个网站的功能设计得很奇怪,比如ip列表提供的筛选功能,下面被圈起来的都是可以作为筛选条件的:

但是偏偏没有端口,鼠标移动到端口上点击是没有反应的,这是因为他要做端口加密啊,让你知道了端口不白做了,然而木用…
下面是分别使用几种过滤条件时地址栏中显示的url:
http://www.data5u.com/free/anoy/匿名/index.html
http://www.data5u.com/free/type/https/index.html
http://www.data5u.com/free/country/中国/index.html
http://www.data5u.com/free/area/云南/index.html
http://www.data5u.com/free/isp/电信/index.html
根据以上已知基本可推出端口过滤的话可能是类似于下面这种:
http://www.data5u.com/free/port/80/index.html
然后试了一下,只一次就成功了 …
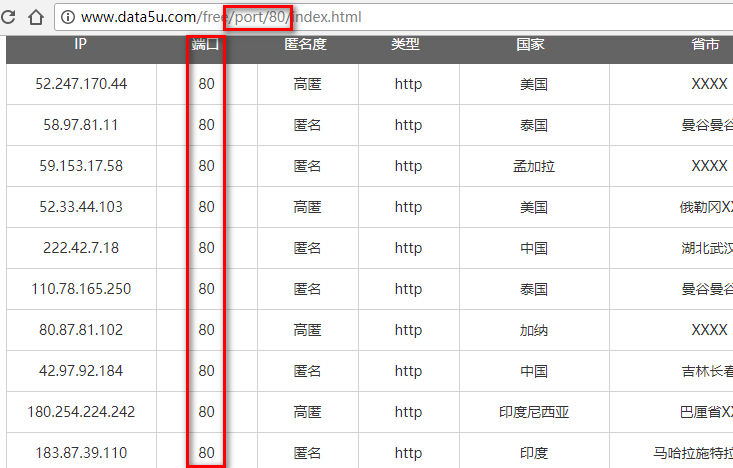
不知道作者怎么想的,这点不如蚂蚁代理了,蚂蚁代理也支持端口号筛选,不过它普通的情况下是这样的:
端口号是用图片显示的,按照端口筛选是这样的:
因为发请求的人已经知道端口号了,所以再图片显示端口号也没用了,不如干脆将ip地址的一部分按图片显示,这种设计还是比较好的,因为反爬虫对对方已知信息增加获取难度没有意义,应该对其未知信息设计获取门槛。
不过没卵用,下一篇写破解蚂蚁代理的反爬。
无忧代理免费ip爬取(端口js加密)的更多相关文章
- 全网代理公开ip爬取(隐藏元素混淆+端口加密)
简述 本次要爬取的网站是全网代理,貌似还是代理ip类网站中比较有名的几个之一,其官网地址: http://www.goubanjia.com/. 对于这个网站的爬取是属于比较悲剧的,因为很久之前就写好 ...
- requests 使用免费的代理ip爬取网站
import requests import queue import threading from lxml import etree #要爬取的URL url = "http://xxx ...
- 代理IP爬取和验证(快代理&西刺代理)
前言 仅仅伪装网页agent是不够的,你还需要一点新东西 今天主要讲解两个比较知名的国内免费IP代理网站:西刺代理&快代理,我们主要的目标是爬取其免费的高匿代理,这些IP有两大特点:免费,不稳 ...
- 代理IP爬取,计算,发放自动化系统
IoC Python端 MySQL端 PHP端 怎么使用 这学期有一门课叫<物联网与云计算>,于是我就做了一个大作业,实现的是对代理IP的爬取,计算推荐,发放给用户等任务的的自动化系统.由 ...
- 蚂蚁代理免费代理ip爬取(端口图片显示+token检查)
分析 蚂蚁代理的列表页大致是这样的: 端口字段使用了图片显示,并且在图片上还有各种干扰线,保存一个图片到本地用画图打开观察一下: 仔细观察蓝色的线其实是在黑色的数字下面的,其它的干扰线也是,所以这幅图 ...
- 酷伯伯实时免费HTTP代理ip爬取(端口图片显示+document.write)
分析 打开页面http://www.coobobo.com/free-http-proxy/,端口数字一看就不对劲,老规律ctrl+shift+c选一下: 这就很悲剧了,端口数字都是用图片显示的: 不 ...
- 爬虫 selenium+Xpath 爬取动态js页面元素内容
介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如 ...
- 爬虫05 /js加密/js逆向、常用抓包工具、移动端数据爬取
爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 目录 爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 1. js加密.js逆向:案例1 2. js加密.js逆向:案例2 3 ...
- 爬取西刺ip代理池
好久没更新博客啦~,今天来更新一篇利用爬虫爬取西刺的代理池的小代码 先说下需求,我们都是用python写一段小代码去爬取自己所需要的信息,这是可取的,但是,有一些网站呢,对我们的网络爬虫做了一些限制, ...
随机推荐
- ICC_lab总结——ICC_lab5:布线&&数字集成电路物理设计学习总结——布线
字丑,禁止转载! 这里将理论总结和实践放在一起了. 布线的理论总结如下所示: 下面是使用ICC进行实践的流程: 本次的布线实验主要达成的目标是: ·对具有时钟树布局后的设计进行可布线性检查 ·完成布线 ...
- Properties文件中文属性读取是乱码问题
项目当中遇到了需要从Properties文件中读取配置属性的需求,本来是存储的中文转码后的属性,但是考虑到后期更改问题就变成java代码中进行转码,代码如下: Properties pros = ne ...
- 基于UDP协议的控制台聊天程序(c++版)
本博客由Rcchio原创,转载请告知作者 ------------------------------------------------------------------------------- ...
- Java中如何实现j并发更新数据库同一条数据
分情况来说:普通单应用并发.多应用或多台服务器并发 情况一:普通单应用并发 使用关键字synchronized就可实现. 情况二:多应用或多台服务器并发 因多个应用之间并非同一个jvm(应用)内,因此 ...
- php过滤表单提交的html等危险代码
表单提交如果安全做得不好就很容易因为这个表单提交导致网站被攻击了,下面我来分享两个常用的php过滤表单提交的危险代码的实例,各位有需要的朋友可参考. PHP过滤提交表单的html代码里可能有被利用引入 ...
- ST-LINK V2 DIY笔记(一)
最近一段时间调试STM32板子的时候,都是用JLINK+杜邦线,或者拿官方板子当STLINK用,可以用,但是体积比较大,有时候觉得比较麻烦.正好前一阵手头项目少,就想DIY一个STLINK. 图是网上 ...
- Flume报 Space for commit to queue couldn't be acquired. Sinks are likely not keeping up with sources, or the buffer size is too tight
报这个错误 需要一个是flume堆内存不够.还有一个就是把channel的容器调大 在channel加配置 type - 组件类型名称必须是memory capacity 100 存储在 Channe ...
- 原生http请求封装
满血复活,今天开始开始更新博客.随着es6的普遍应用,promise属性也随之用之普遍,我们在一些项目中,为了避免引入一些http库,节省空间,就简单将原生http请求做了封装处理,封装代码如下:(其 ...
- 将 Net 项目升级 Core项目经验:(二)修复迁移后Net Standard项目中的错误
修复迁移后Net Standard项目中的错误 接上一章,项目编译结果如下: 解决依赖dll引用 在Net Framework项目的引用如下: 各引用和作用: log4net(1.10.0.0) 用于 ...
- day 1——字典树练习
cojs 173. 词链 ★☆ 输入文件:link.in 输出文件:link.out 简单对比时间限制:1 s 内存限制:128 MB [问题描述]给定一个仅包含小写字母的英文单词表, ...