一致性哈希(附带C++实现)
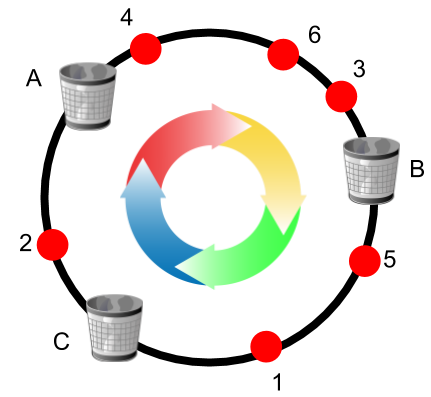
在分布式集群中,对机器的添加删除,或者机器故障后自动脱离集群这些操作是分布式集群管理最基本的功能。如果采用常用的hash(object)%N算 法,那么在有机器添加或者删除后,就需要大范围的移动原有数据,这种大规模的移动数据在大规模的分布式集群中是不可被接受的,因为移动过程中造成的‘抖动’或者可能出现的数据读写问题,都会大大降低集群的可用性。谷歌前一段(17年4月)时间对一致性哈希做了简单改进,即对每个节点最大连接数做限制,新来的请求如果发现目标节点达到最大限制,就会顺时针方向寻找下一个连接数没达到最大的节点,相关论文如下
Consistent Hashing with Bounded Loads



|
|
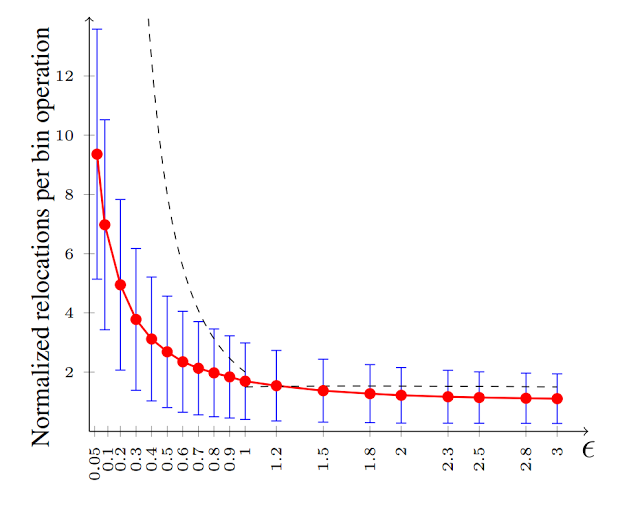
The distribution of loads for several values of ε. The load distribution is nearly uniform covering all ranges of loads from 0 to (1+ε) times average, and many bins with load equal to (1+ε) times average.
|
#include <iostream>
#include <algorithm>
#include <fstream>
#include <vector>
#include <map>
#include <list>
#include <random> #include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h> /*
* === FUNCTION ======================================================================
* Name: add_key
* Description: 找出ip地址对应的node,并存储到node对应的ip列表
* =====================================================================================
*/
void add_key(const std::map<uint32_t, std::string> &node_info, std::string ip, std::map<uint32_t, std::vector<uint32_t>> &info)
{
if (ip.empty() || node_info.empty())
return; /* key映射的hash函数(简单的对ip地址取模) */
auto value = inet_addr(ip.c_str());
auto hash_value = value % 16384; auto it = node_info.begin();
auto right_value = it->first;
uint32_t left_value = right_value;
while (it != node_info.end()) {
left_value = right_value;
right_value = it->first; /* 如果当前key在最小的node左边或者两个node之间就进行处理 */
if (hash_value <= left_value || hash_value <= right_value) {
/* 查看key要访问的node是否存在与映射表中 */
auto itr = info.find(right_value);
if (itr == info.end()) {
std::vector<uint32_t> cli;
cli.push_back(value);
info.emplace(right_value, cli);
}
else {
itr->second.push_back(value);
}
break;
} it++;
} /* 由于是环形0-16383范围,所以当没有找到比当前key大的node,就需要绕回,将其映射到node值最小的node上 */
if (it == node_info.end()) {
auto itr = info.find(node_info.begin()->first);
if (itr == info.end()) {
std::vector<uint32_t> cli;
cli.push_back(value);
info.emplace(right_value, cli);
}
else {
itr->second.push_back(value);
}
}
} /*
* === FUNCTION ======================================================================
* Name: del_key
* Description: 删除node映射表中的key
* =====================================================================================
*/
bool del_key(std::map<uint32_t, std::vector<uint32_t>> &info, const std::string &ip)
{
if (ip.empty() || info.empty())
return false; /* hash函数取值 */
auto value = inet_addr(ip.c_str());
uint32_t hash_value = value % 16384; auto it = info.begin();
auto right_value = it->first;
uint32_t left_value = right_value;
while (it != info.end()) {
left_value = right_value;
right_value = it->first; if (hash_value <= left_value || hash_value <= right_value) {
auto target = std::find(it->second.begin(), it->second.end(), hash_value);
if (target != it->second.end())
it->second.erase(target);
std::cout << "delete " << ip << " from node " << right_value << std::endl; break;
} it++;
} if (it == info.end()) {
it = info.begin();
auto target = std::find(it->second.begin(), it->second.end(), hash_value);
if (target != it->second.end())
it->second.erase(target);
std::cout << "delete " << ip << " from node " << right_value << std::endl;
} } /*
* === FUNCTION ======================================================================
* Name: add_node
* Description: node列表中新增一个node,如果原有node映射表中有数据的话需要将新加node
* 之前范围内的key数据从node后面的node映射表中迁移到新加node中
* =====================================================================================
*/
bool add_node(std::map<uint32_t, std::string> &node_info, std::map<uint32_t, std::vector<uint32_t>> &info, const std::string &node_name)
{
/* 验证node_name是否已经存在 */
for (const auto &ele : node_info) {
if (ele.second == node_name)
return false;
} /* c++11 provides random class */
std::random_device rd;
std::mt19937 gen(rd());
/* 获取0-16383范围内的随机数 */
std::uniform_int_distribution<> dis(0, 16383); /* 利用随机数来作为hash函数 */
auto node_key = dis(gen);
node_info.emplace(node_key, node_name); std::vector<uint32_t> cli; if (info.empty())
return true; auto it = info.begin();
auto right_value = it->first;
uint32_t left_value = right_value;
while (it != info.end()) {
left_value = right_value;
right_value = it->first; if (node_key < left_value || node_key < right_value) {
if (it->second.empty())
return true; /* 如果新node要插入的区间中有数据,需要进行数据迁移 */
auto ip_arr = it->second;
for (auto itr = ip_arr.begin(); itr != ip_arr.end(); itr++) {
if (*itr > node_key && *itr <= right_value)
continue; cli.push_back(*itr);
itr = ip_arr.erase(itr);
}
break;
} it++;
} info.emplace(node_key, cli); return true;
} /*
* === FUNCTION ======================================================================
* Name: del_node
* Description: 将node删除,如果node上有映射数据,需要将数据迁移到顺时针方向上的下一个
* =====================================================================================
*/
bool del_node(std::map<uint32_t, std::string> &node_info, std::map<uint32_t, std::vector<uint32_t>> &info, const std::string &node_name)
{
auto key_itr = node_info.begin();
while (key_itr->second != node_name)
key_itr++; if (key_itr == node_info.end())
return false; if (info.empty()) {
node_info.erase(key_itr);
return true;
} auto target = info.find(key_itr->first);
if (target == info.end()) {
node_info.erase(key_itr);
return true;
} /* 如果删除的是最后一个node,则将数据迁移到第一个node上 */
target++; /* 因为map的迭代器不是随机迭代器,因此只能用++或者--,而不能用+、- */
if (target == info.end()) {
target--;
auto &ip_arr = info.begin()->second;
ip_arr.insert(ip_arr.end(), target->second.begin(), target->second.end());
}
else {
auto &ip_arr = target->second;
target--;
ip_arr.insert(ip_arr.end(), target->second.begin(), target->second.end());
}
info.erase(target); node_info.erase(key_itr); return true;
} int main(int argc, char *argv[])
{
std::vector<std::string> addrs = {"192.168.54.1#1", "192.168.54.1#2","192.168.54.1#3","192.168.54.2#1","192.168.54.2#2","192.168.54.2#3","192.168.54.3#1","192.168.54.3#2","192.168.54.3#3"}; std::cout << "convert 192.168.1.1 to long is " << inet_addr("192.168.1.1") % 16384 << std::endl; std::map<uint32_t, std::string> nodes;
std::map<uint32_t, std::vector<uint32_t>> info;
for (const auto & ele : addrs) {
add_node(nodes, info, ele);
} std::string ip;
std::ifstream ifs;
ifs.open("conf"); while (!ifs.eof()) {
ifs >> ip;
if (ip.empty())
break;
std::cout << "Get ip addr " << ip << std::endl;
add_key(nodes, ip, info);
ip.clear();
} del_node(nodes, info, "192.168.54.1#2");
del_key(info, "100.64.6.225"); return EXIT_SUCCESS;
} /* ---------- end of function main ---------- */
一致性哈希(附带C++实现)的更多相关文章
- .net的一致性哈希实现
最近在项目的微服务架构推进过程中,一个新的服务需要动态伸缩的弹性部署,所有容器化示例组成一个大的工作集群,以分布式处理的方式来完成一项工作,在集群中所有节点的任务分配过程中,由于集群工作节点需要动态增 ...
- 一致性哈希算法与Java实现
原文:http://blog.csdn.net/wuhuan_wp/article/details/7010071 一致性哈希算法是分布式系统中常用的算法.比如,一个分布式的存储系统,要将数据存储到具 ...
- 五分钟理解一致性哈希算法(consistent hashing)
转载请说明出处:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法 ...
- 每天进步一点点——五分钟理解一致性哈希算法(consistent hashing)
转载请说明出处:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT) ...
- memcache 的内存管理介绍和 php实现memcache一致性哈希分布式算法
1 网络IO模型 安装memcached需要先安装libevent Memcached是多线程,非阻塞IO复用的网络模型,分为监听主线程和worker子线程,监听线程监听网络连接,接受请求后,将连接描 ...
- 一致性哈希算法以及其PHP实现
在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin).哈希算法(HASH).最少连接算法(Least Connection).响应速度算法(Respons ...
- Java_一致性哈希算法与Java实现
摘自:http://blog.csdn.net/wuhuan_wp/article/details/7010071 一致性哈希算法是分布式系统中常用的算法.比如,一个分布式的存储系统,要将数据存储到具 ...
- Memcached 笔记与总结(8)Memcached 的普通哈希分布算法和一致性哈希分布算法命中率对比
准备工作: ① 配置文件 config.php ② 封装 Memcached 类 hash.class.php,包含普通哈希算法(取模)和一致性哈希算法 ③ 初始化 Memcached 节点信息 in ...
- 一致性哈希算法(consistent hashing)【转】
一致性哈希算法 来自:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希 ...
随机推荐
- java学习总结之文件操作--ByteArrayOutputStream的用法
ByteArrayOutputStream类是在创建它的实例时,程序内部创建一个byte型别数组的缓冲区, 然后利用ByteArrayOutputStream和ByteArrayInputStream ...
- Python解析JSON详解
JSON 函数 使用 JSON 函数需要导入 json 库:import json. 函数 描述 json.dumps 将 Python 对象编码成 JSON 字符串 json.loads 将已 ...
- 2017-07-08( bzip2 bunzip mount)
.bz2 压缩格式 不能压缩目录 bzip2 源文件 (不保留源文件) bzip2 -k 源文件 (保留源文件) bzip2 -d 压缩文件名 (-k保留压缩文件) bunzip 压缩文 ...
- ssm打印sql语句
在mybatis配置文件中添加<setting name="logImpl" value="STDOUT_LOGGING"/> <?xml v ...
- Servlet--HttpSessionBindingListener接口,HttpSessionBindingEvent类
HttpSessionBindingListener 接口 定义 public interface HttpSessionBindingListener 这个对象被加入到 HTTP 的 session ...
- Tomcat服务器的Web安全的解决方法
.概述 在任何一种WEB应用开发中,不论大中小规模的,每个开发者都会遇到一些需要保护程序数据的问题,涉及到用户的LOGIN ID和PASSWORD.那么如何执行验证方式更好呢?实际上,有很多方式来实现 ...
- 易趣:使用MongoDB创建关键业务的多数据中心应用
eBay:使用MongoDB创建关键业务的多数据中心应用 作为全球前十的零售品牌,eBay的活跃用户有一亿七千多万,并拥有跨越全世界190个市场的10亿购物清单,这样的规模下,eBay绝对不允许出现宕 ...
- Android原生代码与html5交互
一.首先是网页端,这个就是一些简单的标签语言和JS函数: <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN&q ...
- Centos系统下硬盘扩容
装好CentOS后,发现空间太小,怎样才能增加硬盘容量?那就是再建一个硬盘: 打开虚拟经济的设置添加硬盘 查看现有的磁盘空间 fdisk -l [root@localhost ~]# fdisk -l ...
- WebService学习------小实例开发(号码归属地查询)
1.WebService简介: WebService是一种跨平台,跨语言的,可以接收从Internet或者Intranet上的其它系统中传递过来的请求,轻量级的独立的通讯技术.通过SOAP在Web上提 ...