关联分析中寻找频繁项集的FP-growth方法
关联分析是数据挖掘中常用的分析方法。一个常见的需求比如说寻找出经常一起出现的项目集合。
引入一个定义,项集的支持度(support),是指所有包含这个项集的集合在所有数据集中出现的比例。
规定一个最小支持度,那么不小于这个最小支持度的项集称为频繁项集(frequent item set)。
如何找到数据集中所有的频繁项集呢?
最简单的方法是对所有项集进行统计,可以通过逐渐增大项集大小的方式来遍历所有项集。比如说下面的数据集,先统计所有单个元素集合的支持度,{z} 的支持度为5 (这里把项目出现次数作为支持度,方便描述),然后逐渐增大项集大小,比如{z,r} 的支持度为1
| 数据集ID | 数据 |
| 001 | r, z, h, j, p |
| 002 | z, y, x, w, v, u, t, s |
| 003 | z |
| 004 | r, x, n, o, s |
| 005 | y, r, x, z, q, t, p |
| 006 | y, z, x, e, q, s, t, m |
显然这样的方式,计算量很大,当项目增多,项集的数目是指数增长的。当然我们也可以应用一些规律
1)如果一个项集是频繁项集,那么它的子集都是频繁项集
2)如果一个项集不是频繁项集,那么它的超集也不是频繁项集
Apriori算法就是应用了这些方法可以减少寻找频繁项集的计算。而FP-Growth算法则另辟蹊径,它在遍历数据的时候构造一个树结构,当树构造完成,每个节点记录的值就是这个节点到根节点路径上的项集的支持度。
首先对数据集中的数据按单个元素的支持度进行重排
| 数据集ID | 数据 | 按单元数支持度重排后的数据 |
| 001 | r, z, h, j, p | z, r |
| 002 | z, y, x, w, v, u, t, s | z, x, y, s, t |
| 003 | z | z |
| 004 | r, x, n, o, s | x, s, r |
| 005 | y, r, x, z, q, t, p | z, x, y, r, t |
| 006 | y, z, x, e, q, s, t, m | z, x, y, s, t |
然后把每一行数依次拿来构建FP树。把重排后每一行数据从左到右入树。从空集开始,如果树中已存在现有元素,则增加现有元素的值;如果现有元素不存在,则向树添加一个分支。
树构造完成后,以{x:3}这个节点为例,它表示了从这个节点到根节点路径上集合{x,z}的支持度为3。
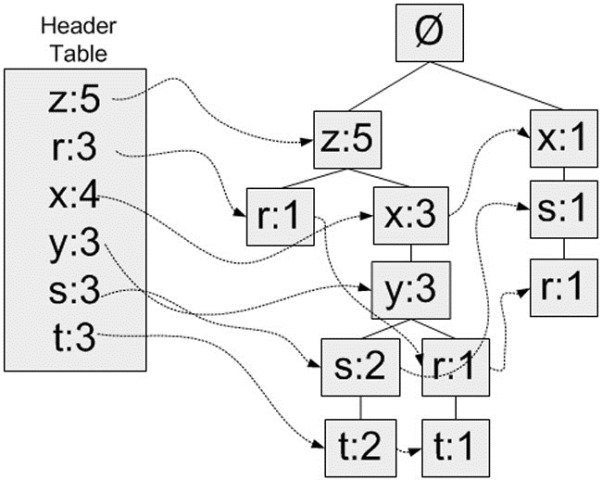
那么问题来了,我们如何保证我们能获得所有的频繁项集,即支持度大于最小支持度的项集。是找出节点值大于最小支持度就够了吗?比如设最小支持度为3,从树上可以看出{z,x,y}的支持度为3,但是仔细观察{z,x,y,t}这个项集的支持度也是为3,如何做呢?
首先为每个元素的找到所有前缀路径,一条前缀路径,是指元素父节点到根节点的路径
| 单元素 | 前缀路径 |
| z | {}: 5 |
| r | {x, s}: 1, {z, x, y}: 1, {z}: 1 |
| x | {z}: 3, {}: 1 |
| y | {z, x}: 3 |
| s | {z, x, y}: 2, {x}: 1 |
| t | {z, x, y, s}: 2, {z, x, y, r}: 1 |
然后对每个元素的所有前缀路径再执行一次FP树的构造过程,这样看到去除这个元素后能得到什么样的频繁项集。如下可以顺利得出{z,x,y} + {t}是一个支持度为3的频繁项集。
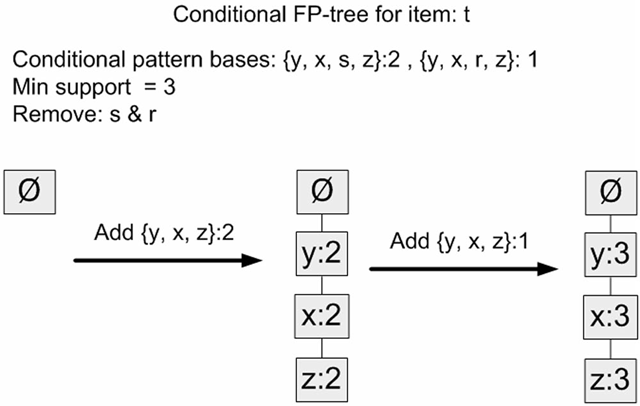
据此,FP-Growth方法就可以算出数据集中最小支持度为3的频繁项集:{z},{z,x},{z,x,y},{z,x,y,t}
参考:
1. https://www.cnblogs.com/qwertWZ/p/4510857.html
关联分析中寻找频繁项集的FP-growth方法的更多相关文章
- 使用 FP-growth 算法高效挖掘海量数据中的频繁项集
前言 对于如何发现一个数据集中的频繁项集,前文讲解的经典 Apriori 算法能够做到. 然而,对于每个潜在的频繁项,它都要检索一遍数据集,这是比较低效的.在实际的大数据应用中,这么做就更不好了. 本 ...
- 第十五篇:使用 FP-growth 算法高效挖掘海量数据中的频繁项集
前言 对于如何发现一个数据集中的频繁项集,前文讲解的经典 Apriori 算法能够做到. 然而,对于每个潜在的频繁项,它都要检索一遍数据集,这是比较低效的.在实际的大数据应用中,这么做就更不好了. 本 ...
- R_Studio(时序)Apriori算法寻找频繁项集的方法
应用ARIMA(1,1,0)对2015年1月1日到2015年2月6日某餐厅的销售数量做为期5天的预测 setwd('D:\\dat') #install.packages("forecast ...
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:非hash方法
http://blog.csdn.net/pipisorry/article/details/48914067 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 机器学习实战 - 读书笔记(12) - 使用FP-growth算法来高效发现频繁项集
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第12章 - 使用FP-growth算法来高效发现频繁项集. 基本概念 FP-growt ...
- FP-Growth算法之频繁项集的挖掘(python)
前言: 关于 FP-Growth 算法介绍请见:FP-Growth算法的介绍. 本文主要介绍从 FP-tree 中提取频繁项集的算法.关于伪代码请查看上面的文章. FP-tree 的构造请见:FP-G ...
- FP-growth算法发现频繁项集(一)——构建FP树
常见的挖掘频繁项集算法有两类,一类是Apriori算法,另一类是FP-growth.Apriori通过不断的构造候选集.筛选候选集挖掘出频繁项集,需要多次扫描原始数据,当原始数据较大时,磁盘I/O次数 ...
- 关联规则—频繁项集Apriori算法
频繁模式和对应的关联或相关规则在一定程度上刻画了属性条件与类标号之间的有趣联系,因此将关联规则挖掘用于分类也会产生比较好的效果.关联规则就是在给定训练项集上频繁出现的项集与项集之间的一种紧密的联系.其 ...
- 海量数据挖掘MMDS week2: Association Rules关联规则与频繁项集挖掘
http://blog.csdn.net/pipisorry/article/details/48894977 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
随机推荐
- Prometheus安装和配置node_exporter监控主机
Node_exporter是可以在* Nix和Linux系统上运行的计算机度量标准的导出器. Node_exporter 主要用于暴露 metrics 给 Prometheus,其中 metrics ...
- BeetleX之WebSocket详解
对于BeetleX来说编写WebSocket服务是一件非常简单的事情,当你实现一个Web Api应用的同时这些API方法也是WebSocket服务方法.接下来主要讲解如何通过JavaScript调用B ...
- 高性能消息队列NSQ
前言 最近我再网上寻找使用golang实现的mq,因为我知道golang一般实现的应用部署起来很方便,所以我就找到了一个叫做nsq的mq,其实它并不能完全称为队列,但是它的轻量和性能的高效,让我真的大 ...
- Cortex-M 实现互斥操作的三种方法
注:本文仅针对Cortex-M3/4 系列进行讲述. 在传统的ARM处理器架构中,常使用SWP指令来实现锁的读/写原子操作,但从ARM v6开始,读/写访问在独立的两条总线上进行,SWP指令已无法在此 ...
- .Net Core 根据配置文件动态发布至服务器
前言 一个软件的开发周期需要经历开发.测试.上线三个基本的阶段,同理我们在开发过程中会需要经常切换不同的运行环境..NetCore可以通过配置文件以及写入系统环境变量来自动识别站点的运行环境,保证了数 ...
- 了解spring
一.spring简介 Spring是一个JavaEE轻量级的一站式的开发框架(spring的可插拔特性,企业用于整合其他框架)轻量级:使用最少的代码启动程序,根据所需选择功能选择模块使用一站式:提供了 ...
- Android为TV端助力 listview与recyclerview上下联动
首先是主布局fragment里面的xml文件 <?xml version="1.0" encoding="utf-8"?><RelativeL ...
- Android 系统服务的获取与创建
在Android系统中,有一群很厉害的“家伙”,如果把Android系统比喻成一个大帮派,那么这群“家伙”的地位就像那各个分堂的堂主一样,所有的应用就像是各个小马哥,他们要做什么事情,都要堂主审批,审 ...
- Python笔记-IO编程
IO在计算机中是指input和output(数据输入与输出),涉及到数据交换(磁盘.网络)的地方就需要IO接口. 输入流input stream是指数据从外面(磁盘.网络服务器)流入内存:输出流out ...
- Python使用Plotly绘图工具,绘制甘特图
今天来讲一下如何使用Python 的绘图工具Plotly来绘制甘特图的方法 甘特图大家应该了解熟悉,就是通过条形来显示项目的进度.时间安排等相关情况的. 我们今天来学习一下,如何使用ployly来绘制 ...