ResNet
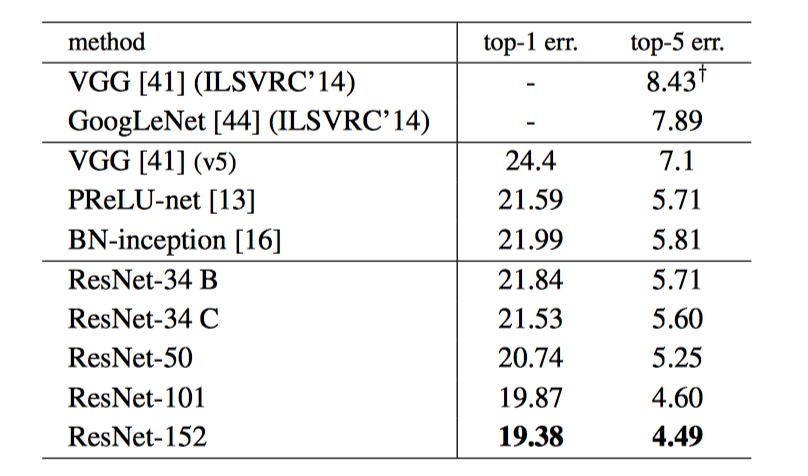 

上图为单个模型
VGGNet, GoogleNet 都说明了深度对于神经网络的重要性. 文中在开始提出: 堆叠越多的层, 网络真的能学习的越好吗? 然后通过神经网络到达足够深度后出现的退化(degradation problem)问题, 从而引出残差学习!
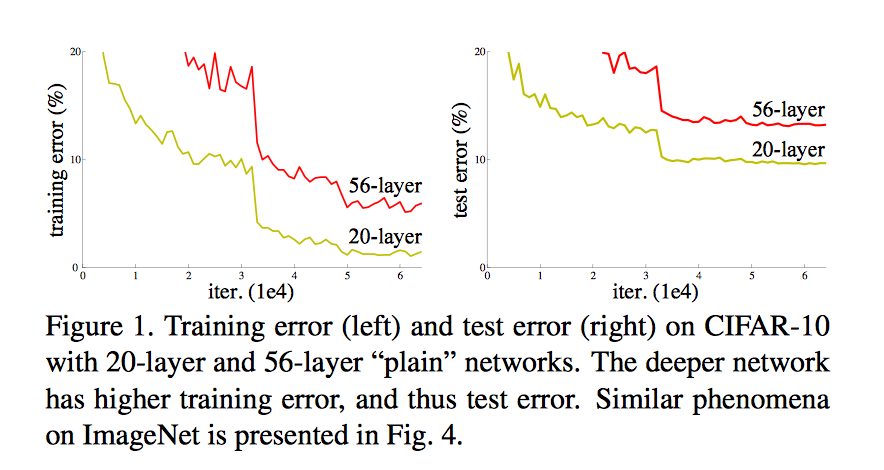 

退化问题有何引起?
臭名昭著的梯度消失和梯度爆炸问题已经通过提出的标准初始化(如 Xavier)和中间层标准化(BN)解决.
退化问题也不是由于 overfitting 造成, 毕竟是由于 training error 在上升. 而不是training error 在下降, testing error 上升
(作者推测,退化问题可能是由于深度传统卷积网络的收敛速度可能呈指数级低, 当前的计算能力没法等到它收敛)
那退化问题有何引起?
于是论文提出:退化问题(of train accuracy)表明并非所有系统都同样易于优化。
让我们考虑一个更浅的架构和更深层次的架构,后者在前者上添加更多层。 在深层模型中存在这样一个优化方案:增加的层是使用恒等映射(identity mapping),其他层是从学习的浅层模型复制的。这种构建解决方案的存在表明,深层模型不应该比浅层模型产生更高的训练误差。 然而, 实验表明,我们目前的求解器(solver)无法找到与构建的解决方案一样好或更好的方案.
于是作者提出, 既然网络不能找到与构建的解决方案相当的方案, 我们就手动在不同层间加入恒等映射, 然后让网络学习残差映射(residual mapping). 并假设网络优化残差映射比优化原始映射要简单, 比如说,就拿极端情况来说, 如果恒等映射是最优的, 让残差(f(x)=0)为零要比让堆叠的几个非线性层去学习恒等映射要简单.
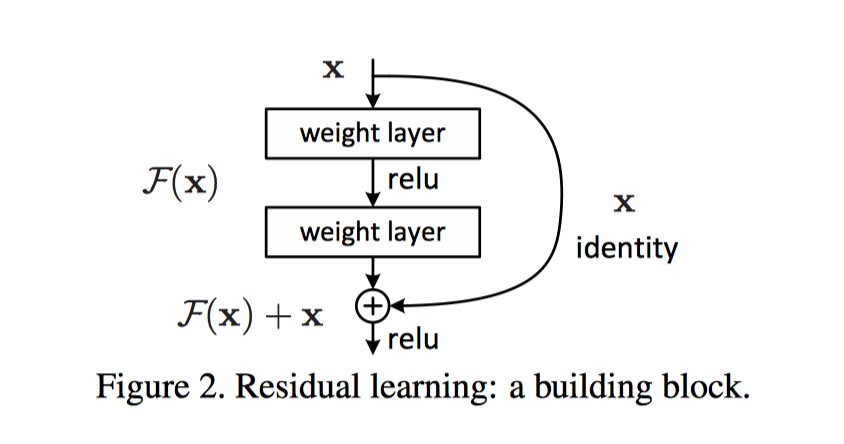 

恒等映射的好处: 既不增加额外的参数也不增加计算复杂度
残差定义: 数理统计上, 残差表示实际观测值与估计值(拟合值)的差, 蕴含模型的重要信息.
残差学习(Residual Learning)
如果假设多个非线性层可以渐近地逼近复杂函数,那么可以假设它们也可以渐近地逼近残差函数,即 H(x)-x(假设输入和输出具有相同的维数)。 因此,不是期望堆叠层接近H(x),我们明确地让这些层接近剩余函数F(x)=H(x)-x。 原始函数因此变成 F(x)+x。 尽管两种形式都应该能够渐近地接近理想的功能(如同假设),但学习的难易可能不同。
实验证据:
在实际情况下,恒等映射不太可能是最优的,但我们的重定义可能有助于预先解决这个问题。 如果最优函数比零映射更接近恒等映射,那么求解器(solver)应该更容易找出参照恒等映射的扰动,而不是将函数学习为新映射。 实验显示,通常所学习的残差函数具有很小的响应,这表明恒等映射提供了合理的预处理。
网络架构
VGGNet 哲学:
- 卷积层主要是 3×3 卷积核(filter)
- 具有有相同的输出特征图(feature maps)大小的层,具有相同数量的 filter
- 如果特征图大小减半, filter 的数量加倍以保持每层的时间复杂度。
网络==直接采用跨度为2的卷积层执行下采样==, 网络以 Global Average Pooling 和具有1000路 softmax 的完全连接层结束。
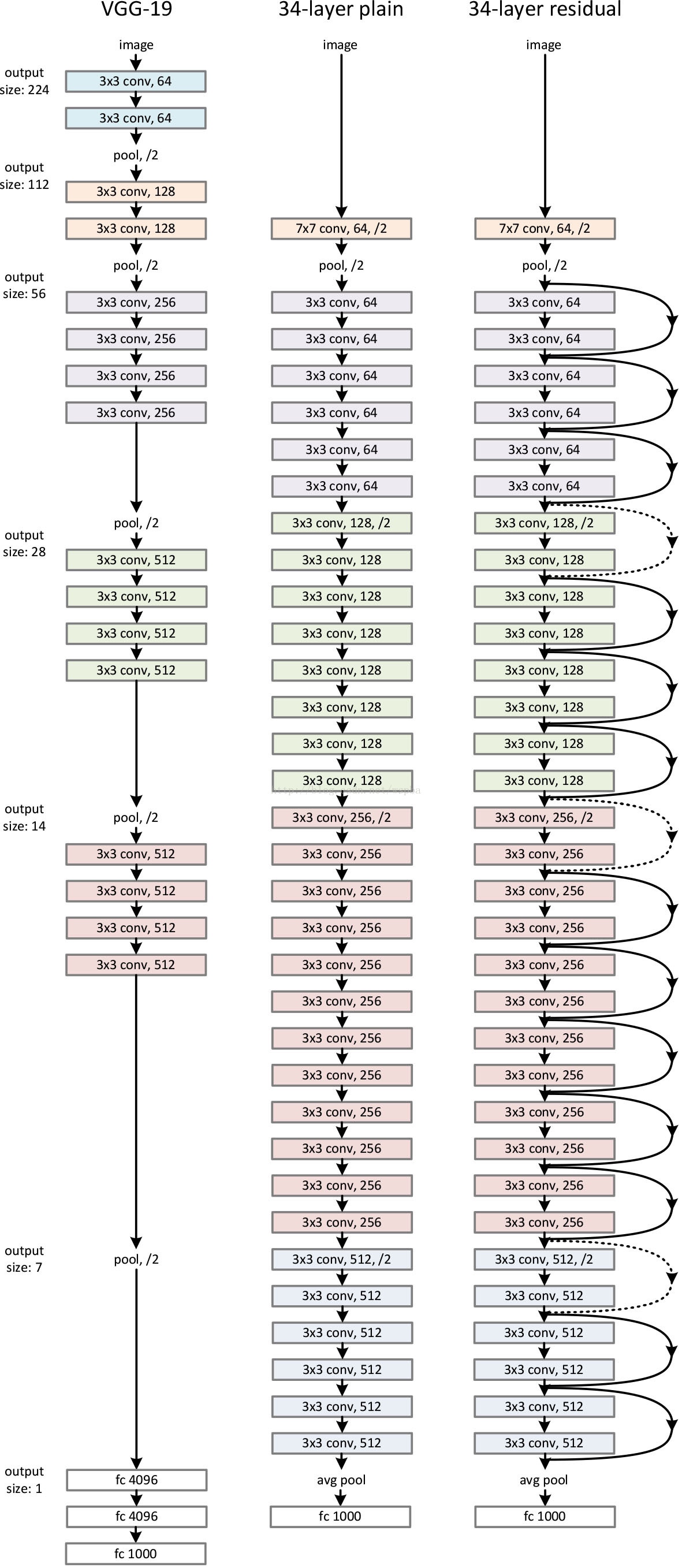 

虚线残差连接为残差块输入输出维度不同. 当维度相同时, 使用恒等映射; 当输出维度升高(stride=2)时, 使用 Zero-Padding 或者 Projection Shortut(通过 1×1 卷积升维)
实现
基础学习率 lr: 0.1, 每次训练到达平原, 除以10
weight decay(L2正则项): 0.0001
momentum: 0.9
 

\(\color{red}{Deeper Bottleneck Architectures}\)
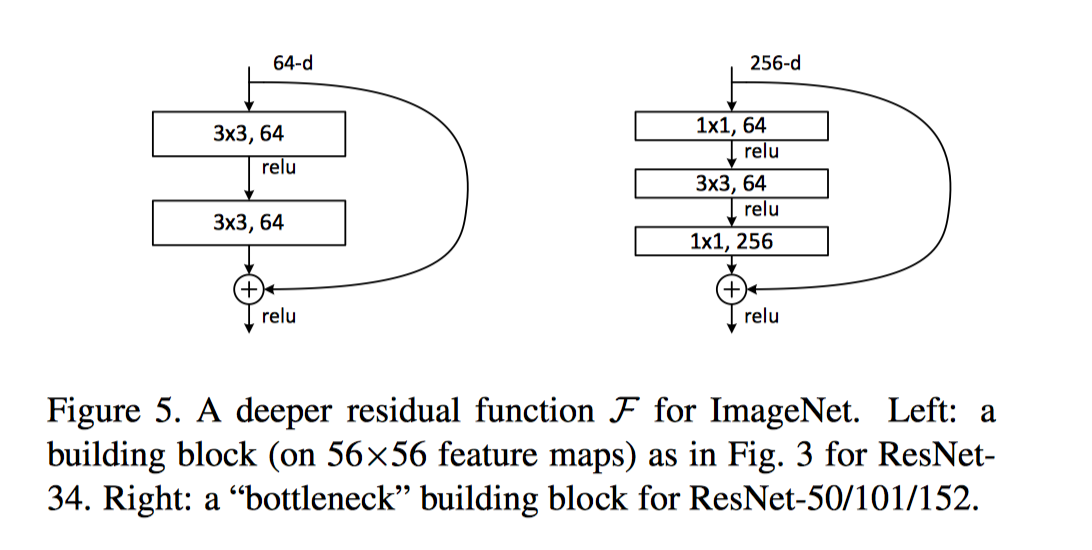 

Identity Mapping
Residual Units 可以表示为如下形式:
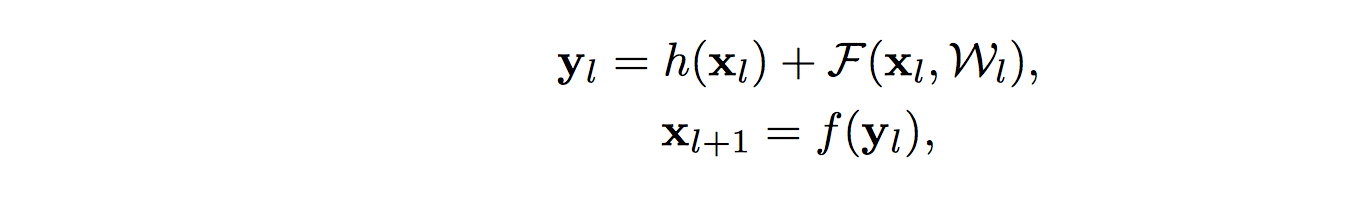 

如果 h(x)和 f(y) 都是恒等映射,则信号可以直接从一个单位传播到任何其他单位,无论是信息前向出还是误差反向传递。 我们的实验证明,当架构更接近上述两个条件时,训练总体上会变得更容易。
pre-activation
定义: To construct an identity mapping f(y) = y, we view the activation functions (BN 和 ReLU) as “pre-activation” of the weight layers, in contrast to conventional wisdom of “post-activation”. 结构如下图, (b)部分
好处:
- 让优化更简单(由于 f 变为了恒等映射), 加快模型训练速度
- 提升模型的正则化. 在原来的 Residual Unit(下图(a)部分) 中, 虽然 BN 标准化了 signal, 不过标准化结果会与 shortcut 相加, 因此合并的 signal 并没有被正则化.
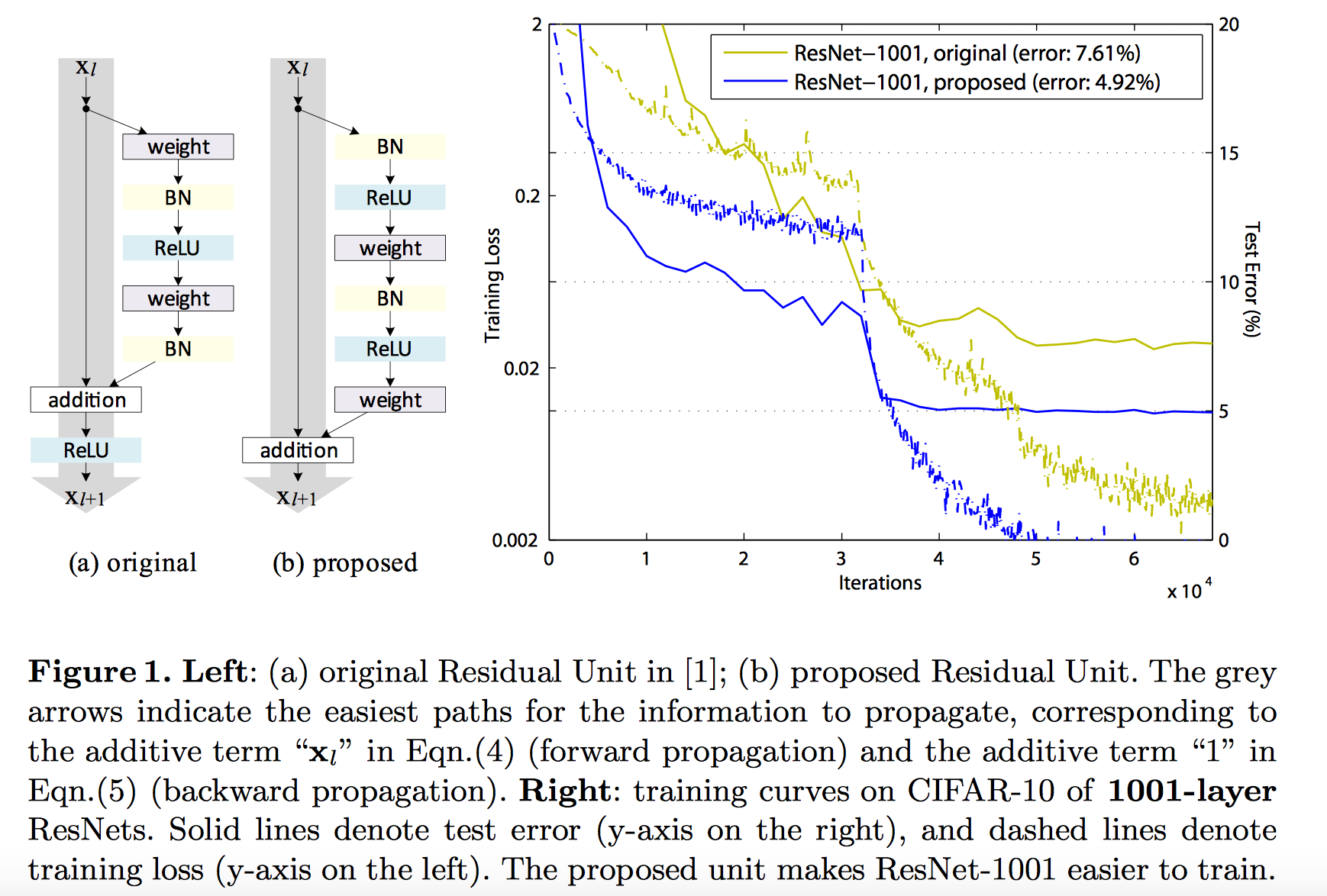 

Identity Skip Connections 的重要性
如果将恒等映射换成一个简单修改版 \(h(x_l) = \lambda_l x_l\), 那么, 梯度传递如下
\[
\begin{align}
x_{l+1} &= \lambda_lx_l + F(x_l, W_l) \\
\frac{\partial L}{\partial x_l} &= \frac{\partial L}{\partial x_L}\left( \prod _{ i=l }^{ L-1 }{ \lambda _{ i } } + \sum _{ i=l }^{L-1 }{ \hat F(x_i, W_i) }\right)
\end{align}
\]
\(\prod _{ i=l }^{ i=L-1 }{ \lambda _{ i } }\) 对于一个极深的网络(L很大),如果对于所有 i,\(λ_i > 1\) ,则该因子可以是指数级大的; 如果对于所有 i,\(λ_i < 1\),则该因子可以呈指数规律地变小并消失,这阻止了从捷径中反向传播的信号并迫使它通过重物层流动。这导致了我们通过实验显示的优化难题。
ResNet的更多相关文章
- #Deep Learning回顾#之LeNet、AlexNet、GoogLeNet、VGG、ResNet
CNN的发展史 上一篇回顾讲的是2006年Hinton他们的Science Paper,当时提到,2006年虽然Deep Learning的概念被提出来了,但是学术界的大家还是表示不服.当时有流传的段 ...
- 残差网络resnet学习
Deep Residual Learning for Image Recognition 微软亚洲研究院的何凯明等人 论文地址 https://arxiv.org/pdf/1512.03385v1.p ...
- 使用dlib中的深度残差网络(ResNet)实现实时人脸识别
opencv中提供的基于haar特征级联进行人脸检测的方法效果非常不好,本文使用dlib中提供的人脸检测方法(使用HOG特征或卷积神经网方法),并使用提供的深度残差网络(ResNet)实现实时人脸识别 ...
- 经典卷积神经网络(LeNet、AlexNet、VGG、GoogleNet、ResNet)的实现(MXNet版本)
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现. 其中 文章 详解卷 ...
- 深度学习——卷积神经网络 的经典网络(LeNet-5、AlexNet、ZFNet、VGG-16、GoogLeNet、ResNet)
一.CNN卷积神经网络的经典网络综述 下面图片参照博客:http://blog.csdn.net/cyh_24/article/details/51440344 二.LeNet-5网络 输入尺寸:32 ...
- 深度学习基础网络 ResNet
Highway Networks 论文地址:arXiv:1505.00387 [cs.LG] (ICML 2015),全文:Training Very Deep Networks( arXiv:150 ...
- 卷积神经网络的一些经典网络(Lenet,AlexNet,VGG16,ResNet)
LeNet – 5网络 网络结构为: 输入图像是:32x32x1的灰度图像 卷积核:5x5,stride=1 得到Conv1:28x28x6 池化层:2x2,stride=2 (池化之后再经过激活函数 ...
- [论文阅读] Deep Residual Learning for Image Recognition(ResNet)
ResNet网络,本文获得2016 CVPR best paper,获得了ILSVRC2015的分类任务第一名. 本篇文章解决了深度神经网络中产生的退化问题(degradation problem). ...
- 学习TensorFlow,调用预训练好的网络(Alex, VGG, ResNet etc)
视觉问题引入深度神经网络后,针对端对端的训练和预测网络,可以看是特征的表达和任务的决策问题(分类,回归等).当我们自己的训练数据量过小时,往往借助牛人已经预训练好的网络进行特征的提取,然后在后面加上自 ...
- 深入解读Resnet
残差网络的设计目的 随着网络深度增加,会出现一种退化问题,也就是当网络变得越来越深的时候,训练的准确率会趋于平缓,但是训练误差会变大,这明显不是过拟合造成的,因为过拟合是指网络的训练误差会不断变小,但 ...
随机推荐
- 【SPOJ】Longest Common Substring II (后缀自动机)
[SPOJ]Longest Common Substring II (后缀自动机) 题面 Vjudge 题意:求若干个串的最长公共子串 题解 对于某一个串构建\(SAM\) 每个串依次进行匹配 同时记 ...
- webpack中hash与chunkhash区别和需要注意的问题
项目发布时,为了解决缓存,需要进行md5签名,这时候就需要用到 hash 和 chunkhash等. 问题一:hash问题 使用 hash 对js和css进行签名时,每一次hash值都不一样,导致无法 ...
- iOS学习——UIPickerView的实现年月选择器
最近项目上需要用到一个选择器,选择器中的内容只有年和月,而在iOS系统自带的日期选择器UIDatePicker中却只有四个选项如下,分别是时间(时分秒).日期(年月日).日期+时间(年月日时分)以及倒 ...
- MySQL增量订阅&消费组件Canal POC
POC的目的:1.与MYSQL的对接方式,配置文档2.订阅的延迟3.订阅后宕机消息会不会丢失4.能不能从指定的点开始重新订阅5.高并发写入的时候,日志的顺序是否还能保持,不考虑消费的情况订阅是否会延迟 ...
- mac 上传本地代码到 Github 教程
网上有很多关于windows系统上传本地代码到github的文章,但是自己用的是mac,在网上也找了相关文章,实践的过程中还是遇到了很多问题,现在把自己的成功实践分享出来,希望能对大家有帮助. 1.首 ...
- 用MATLAB结合四种方法搜寻罗马尼亚度假问题
选修了cs的AI课,开始有点不适应,只能用matlab硬着头皮上了,不过matlab代码全网仅此一份,倒有点小自豪. 一.练习题目 分别用宽度优先.深度优先.贪婪算法和 A*算法求解"罗马利 ...
- JavaScript变量提升的本质
变量提升 先说三句总结性的话: let 的「创建」过程被提升了,但是初始化没有提升. var 的「创建」和「初始化」都被提升了. function 的「创建」「初始化」和「赋值」都被提升了. 所以,我 ...
- Spring OAuth2 GitHub 自定义登录信息
# 原因 最近在做一款管理金钱的网站进行自娱自乐,发现没有安全控制岂不是大家都知道我的工资了(一脸黑线)? 最近公司也在搞 Spring OAuth2,当时我没有时间(其实那时候不想搞)就没做,现在回 ...
- linux学习之路--(六)用户及权限详解
计算机资源 用户 用户的容器,用户组 权限 进程时用户访问计算机的代理,操作文件的时候,文件本身有权限,进程本身也有权限 安全上下文(secure context) 权限: r, w, x 文件: r ...
- 【HTML】 HTML基础知识 表单
html 表单 表单的标签是<form>,用于给网站的后台提交数据.提交的数据格式原本是什么样不太清楚,以python的flask框架来看,我从表单中得到的数据是一个字典(flask.re ...