残差网络resnet学习
Deep Residual Learning for Image Recognition
微软亚洲研究院的何凯明等人
论文地址
https://arxiv.org/pdf/1512.03385v1.pdf
Abstract
更深层次的神经网络训练更加困难。我们提出一个 Residual的学习框架来缓解训练的网比之前所使用的网络深得多。我们提供全面的经验证据显示这些残余网络更容易优化,并可以从显着增加的深度获得准确性。在ImageNet数据集上我们评估深度达152层残留网比VGG网[41]更深,但复杂度仍然较低。这些残留网络的集合实现了3.57%的误差在ImageNet测试集上。这个结果赢得了ILSVRC 2015分类任务第一名。
比赛总结ppt链接
http://image-net.org/challenges/talks/ilsvrc2015_deep_residual_learning_kaiminghe.pdf
ICCV 2015 Tutorial on Tools for Efficient Object Detection链接
http://mp7.watson.ibm.com/ICCV2015/ObjectDetectionICCV2015.html
1. Introduction
学习更好的网络是否容易堆叠更多层?
层次深的问题是梯度消失/爆发[1,9],阻碍了收敛。 这个问题已经通过归一化初始化被很大程度上解决[23,9,37,13]和中间标准化层[16],使具有数十层用于反向传播的随机梯度下降(SGD)的网络开始收敛。
当更深层次的网络能够开始收敛时,退化问题已暴露:随着更深网络层次增加,然后准确度迅速下降。这种退化不是由过度拟合引起的,而是加入更多的层次到合适的深度模型导致更高的训练错误,如[11,42]中所报告,并经过全面验证我们的实验。
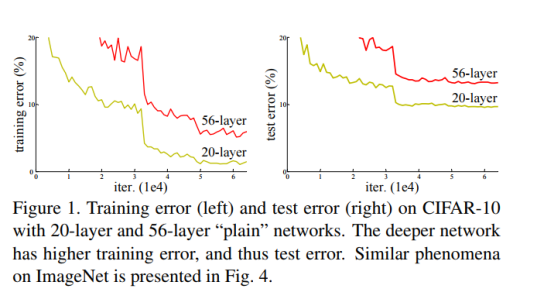
如果我们加入额外的层只是一个 identity mapping,那么随着深度的增加,训练误差并没有随之增加。所以我们认为可能存在另一种构建方法,随着深度的增加,更深层次的模型不应该产生更高的训练误差。
提出一个 deep residual learning 框架来解决这种因为深度增加而导致性能下降问题。

假设我们期望的网络层关系映射为 H(x),我们假设把多增加的那些层拟合另一个映射, F(x):= H(x)-x , 那么原先的映射就是 F(x)+x。假设优化残差映射F(x) 比优化原来的映射 H(x)容易。F(x)+x 可以通过图二shortcut connections前馈神经网络来实现。
在ImageNet上评估此方法,发现更容易优化。并且发现plain nets在网络增加时候有更大的训练误差。我们的方法在深度增加时候比之前的网络更容易获准确提升。
2. Related Work
Residual Representations.VLAD [18]是通过相对于字典的残差向量进行编码的表示,并且Fisher Vector [30]可以被公式化为VLAD的概率版本[18]。他们都是图像检索和分类的强大的浅表示[4,48]。对于矢量量化,编码残差矢量[17]被证明比编码原始矢量更有效。
在低级视觉和计算机图形学中,为了求解部分微分方程(PDE),广泛使用的Multigrid方法[3]将系统重构为多个尺度的子问题,其中每个子问题负责较粗和更细的残余解 规模。 Multigrid的替代方法是层次化基础预处理[45,46],它依赖于代表的变量两个尺度之间的残差向量。 已经显示[3,45,46]这些求解器比没有考虑残差性质的标准求解器收敛得快得多。 这些方法表明,良好的重新配置或预处理可以简化优化。
Shortcut Connections.
Shortcut Connections的实践和理论[2,34,49]已经被研究了很长时间。训练多层感知器(MLP)的早期实践是将从网络输入连接到线路层的输出[34,49]。在[44,24]中,几个中间层直接连接到辅助分类器,用于消除/爆炸梯度。 [39,38,31,47]的论文提出了将层响应,梯度和传播错误对中的应用Shortcut Connections方法。
在[44]中,“初始”层由快捷分支和更深的分支组成。 与我们的工作同时,“highway networks”[42,43]提供了与门控功能的Shortcut Connections[15]。 这些门是数据相关的,并且具有参数,与我们不具参数的identity shortcuts方式相反。门gate当接近0时候关闭,相当于non-residual函数。而本文residual函数是始终存在的。
3. Deep Residual Learning
3.1. Residual Learning
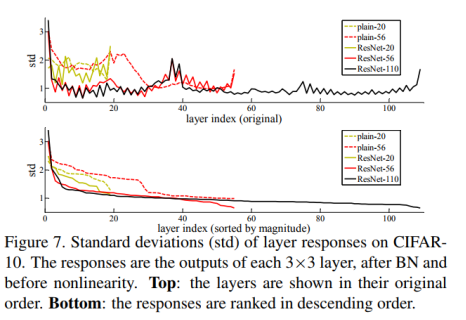
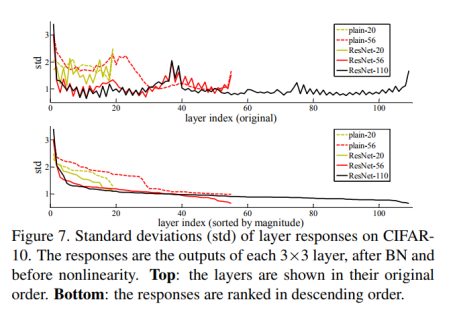
性能退化问题暗示多个非线性网络层用于近似identity mappings 可能有困难。使用残差学习改写问题之后,如果identity mappings 是最优的,那么优化问题变得很简单,直接将多层非线性网络参数趋0。实际中,identity mappings 不太可能是最优的,但是上述改写问题通过实验图7表明可能能帮助预处理问题。如果最优函数接近identity mappings,那么优化将会变得容易些。
3.2. Identity Mapping by Shortcuts

公式(1)中的快捷连接不会引入额外的参数也不计算复杂度。 这不仅仅是我们可以相当比较plain and residual 网络同时拥有相同数量的参数,深度,宽度和计算成本(除了可忽略的元素加法除外)。方程(1)中x和f的尺寸必须相等。如果不是这种情况(例如,当改变输入/输出时通道),我们可以执行linear projection Ws 和shortcut connections匹配维度:
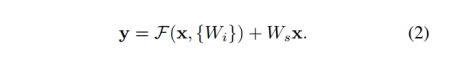
3.3. Network Architectures
Plain Network.
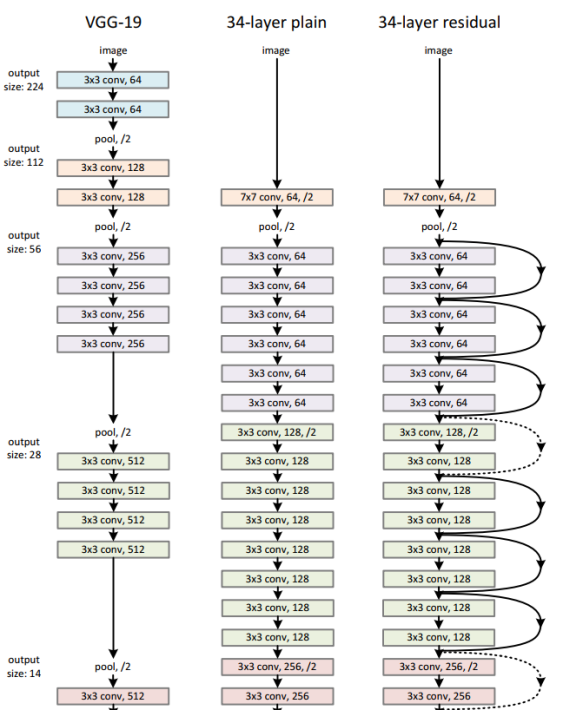
受 VGG 网络启发采用3*3滤波器,遵循两个设计原则:1)对于相同输出特征图尺寸,卷积层有相同个数的滤波器,2)如果特征图尺寸缩小一半,滤波器个数加倍以保持每个层的计算复杂度。通过步长为2的卷积来进行降采样。一共34个权重层。 需要指出,我们这个网络与VGG相比,滤波器比VGG19的18%,复杂度要小例如图3所示。我们推测深层网可能会具有指数低收敛速度,这影响了减少训练误差。这种优化的原因将来会有困难。
Residual Network.
Residual Network.在plain network上每两个3*3filters中加入 shortcut connections,如图三所示。
网络结构:
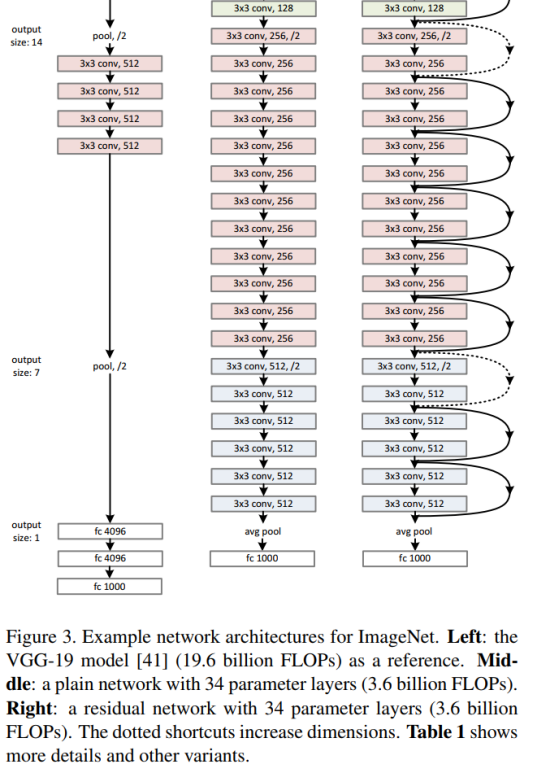
3.4. Implementation
针对 ImageNet网络的实现,我们遵循【21,41】的实践,图像以较小的边缩放至[256,480],这样便于 scale augmentation,然后从中随机裁出 224*224,采用【21,16】文献的方法。
使用[21]中的标准色彩增强。 在每个卷积之后和激活之前,我们采用批量归一化(BN)[16] [16]。 我们按照[13]初始化权重,从头开始训练所有的平原/残留网。 我们用mini-batch为256的SGD。学习率从0.1开始,当偏差平缓时被除以10,并且模型训练高达60×10000迭代。 我们使用0.0001的重量衰减和0.9的动量。 我们不要使用dropout14],遵循[16]的做法。
4. Experiments
4.1. ImageNet Classification
Plain Networks.
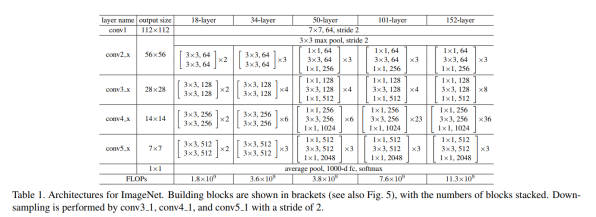
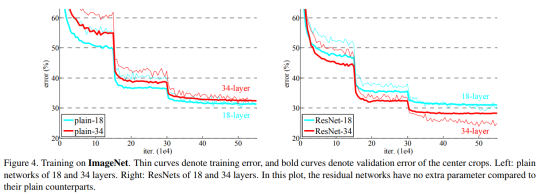
细节结构如table1,具体表现如图4和tables2结果。
Residual Networks.
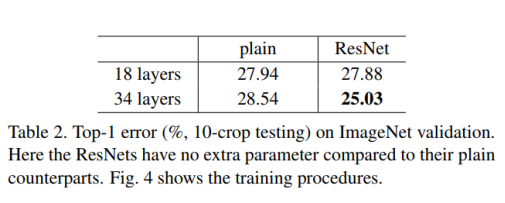
我们对所有shortcut connections和零填充使用identity mapping来增加维度。 所以与plain network相比,它们没有额外的参数。我们有三个重要实验显示table 2和fig 4。Residual learning 34层ResNet优于18层ResNet(下跌百分之二点八)。 更重要的是,34层ResNet展出大大降低了训练误差,可以概括为验证数据。 这表明退化问题在这个设置中得到很好的解决,我们获得在增加的深度获得更好的acc。
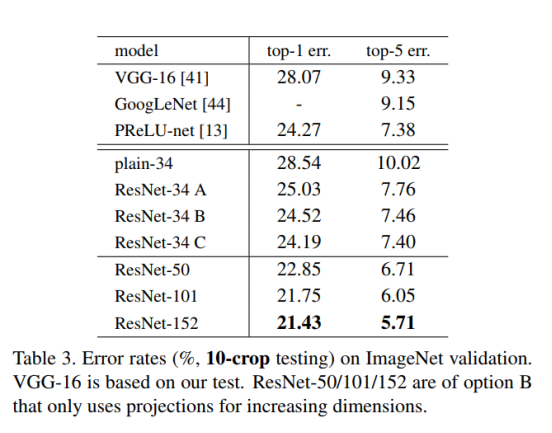
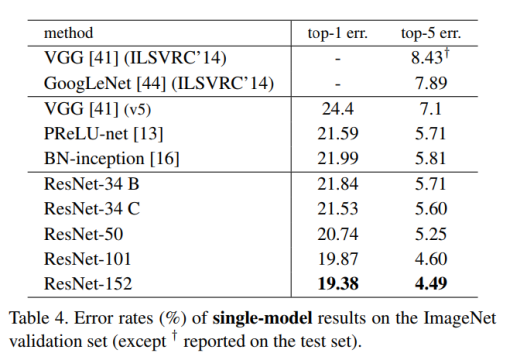
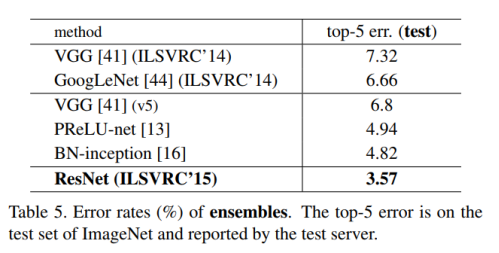
Identity vs. Projection Shortcuts.
实验表明parameter-free, identity shortcuts有利于训练。通过公式2映射shortcuts。Table 3中比较了三个方式,发现projections不是解决degradation问题的关键。Identity shortcuts是特别重要对于不增加bottleneck架构复杂性的情况下。
Deeper Bottleneck Architectures.
接下来我们描述我们更深入的网络网络。 由于考虑训练时间,我们可以将building block修改为bottleneck 设计4。 对于每个残差函数F,我们使用3层而不是2层(图5)。 三层是1×1,3×3和1×1卷积,其中1×1层负责减少然后增加(恢复)尺寸,使bottleneck 的3×3层具有较小输入/输出尺寸,两种设计具有相似的时间复杂性。无参数的Identity shortcuts方式特别重要对于bottleneck 架构。 如果Identity shortcuts方式在图5(右)中可以用投影projections来代替,发现时间复杂度和模型尺寸加倍,因为Identity shortcuts连接到两个高维端。 所以Identity shortcuts方式对于bottleneck 架构是很有效的设计。
50-layer ResNet
101-layer and 152-layer ResNets
Comparisons with State-of-the-art Methods
Table 1 2 3 4 5 对以上三个实验数据结果都有印证。
4.2. CIFAR-10 and Analysis
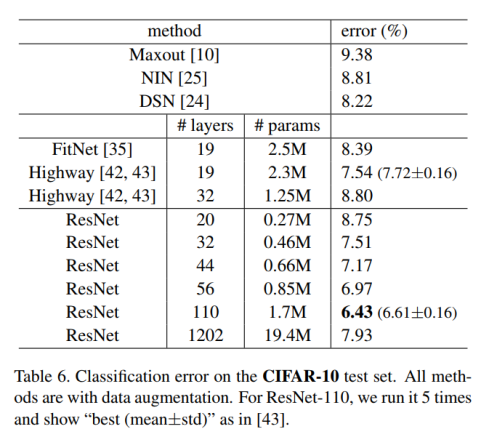
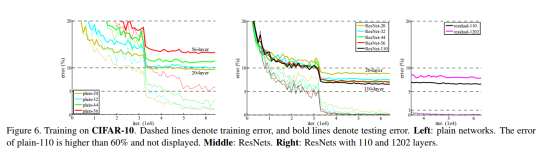
Analysis of Layer Responses
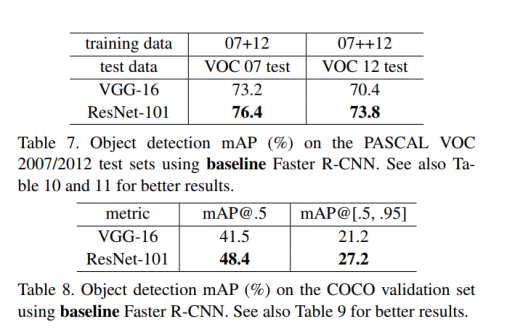
4.3. Object Detection on PASCAL and MS COCO
残差网络resnet学习的更多相关文章
- 深度残差网络——ResNet学习笔记
深度残差网络—ResNet总结 写于:2019.03.15—大连理工大学 论文名称:Deep Residual Learning for Image Recognition 作者:微软亚洲研究院的何凯 ...
- 深度学习——手动实现残差网络ResNet 辛普森一家人物识别
深度学习--手动实现残差网络 辛普森一家人物识别 目标 通过深度学习,训练模型识别辛普森一家人动画中的14个角色 最终实现92%-94%的识别准确率. 数据 ResNet介绍 论文地址 https:/ ...
- 深度残差网络(ResNet)
引言 对于传统的深度学习网络应用来说,网络越深,所能学到的东西越多.当然收敛速度也就越慢,训练时间越长,然而深度到了一定程度之后就会发现越往深学习率越低的情况,甚至在一些场景下,网络层数越深反而降低了 ...
- 从头学pytorch(二十):残差网络resnet
残差网络ResNet resnet是何凯明大神在2015年提出的.并且获得了当年的ImageNet比赛的冠军. 残差网络具有里程碑的意义,为以后的网络设计提出了一个新的思路. googlenet的思路 ...
- 使用dlib中的深度残差网络(ResNet)实现实时人脸识别
opencv中提供的基于haar特征级联进行人脸检测的方法效果非常不好,本文使用dlib中提供的人脸检测方法(使用HOG特征或卷积神经网方法),并使用提供的深度残差网络(ResNet)实现实时人脸识别 ...
- 残差网络ResNet笔记
发现博客园也可以支持Markdown,就把我之前写的博客搬过来了- 欢迎转载,请注明出处:http://www.cnblogs.com/alanma/p/6877166.html 下面是正文: Dee ...
- CNN卷积神经网络_深度残差网络 ResNet——解决神经网络过深反而引起误差增加的根本问题,Highway NetWork 则允许保留一定比例的原始输入 x。(这种思想在inception模型也有,例如卷积是concat并行,而不是串行)这样前面一层的信息,有一定比例可以不经过矩阵乘法和非线性变换,直接传输到下一层,仿佛一条信息高速公路,因此得名Highway Network
from:https://blog.csdn.net/diamonjoy_zone/article/details/70904212 环境:Win8.1 TensorFlow1.0.1 软件:Anac ...
- 残差网络resnet理解与pytorch代码实现
写在前面 深度残差网络(Deep residual network, ResNet)自提出起,一次次刷新CNN模型在ImageNet中的成绩,解决了CNN模型难训练的问题.何凯明大神的工作令人佩服 ...
- 深度残差网络(DRN)ResNet网络原理
一说起“深度学习”,自然就联想到它非常显著的特点“深.深.深”(重要的事说三遍),通过很深层次的网络实现准确率非常高的图像识别.语音识别等能力.因此,我们自然很容易就想到:深的网络一般会比浅的网络效果 ...
随机推荐
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- (转)log4j(六)——log4j.properties简单配置样例说明
一:测试环境与log4j(一)——为什么要使用log4j?一样,这里不再重述 1 老规矩,先来个栗子,然后再聊聊感受 (1)使用配文件的方式,是不是感觉非常的清爽,如果不在程序中读取配置文件就更加的清 ...
- (转)Java并发编程:Callable、Future和FutureTask
Java并发编程:Callable.Future和FutureTask 在前面的文章中我们讲述了创建线程的2种方式,一种是直接继承Thread,另外一种就是实现Runnable接口. 这2种方式都有一 ...
- 【CSS】盒子模型 之 IE 与W3C的盒子模型对比
摘要 主要看这两种盒子模型的优缺点及适用场景 一.区别 标准 W3C 盒子模型的 content 部分不包含其他部分. IE 盒子模型的 content 部分包含了 border 和 padding. ...
- 使用gitLab 或 github 关联本地仓库
要先在git里面注册自己的邮箱 然后: git commit -m 是为本次提交命名 刷新gitLab 发现更新了
- expdp导出文件,ORA-01555: 快照过旧: 回退段号 716
快照号过旧,回退段号过小,信息如下:ORA-31693: 表数据对象 "CZBSDB"."SMS_RESULT_RECORD" 无法加载/卸载并且被跳过, 错误 ...
- MSYS2使用教程
一.安装 官方下载地址 http://www.msys2.org/ 指定好安装路径(一般D根目录即可),一路下一步就好. 二.配置国内镜像 使用[清华大学开源软件镜像站]中的地址,修改\etc\pac ...
- 136. Single Number【LeetCode】异或运算符,算法,java
Given an array of integers, every element appears twice except for one. Find that single one. Note:Y ...
- mysql的内连接,外连接(左外连接,右外连接)巩固
1:mysql的内连接: 内连接(inner join):显示左表以及右表符合连接条件的记录: select a.goods_id,a.goods_name,b.cate_name from tdb_ ...
- 分辨率验证工具 - 【Window Resizer】的使用 - Google扩展工具
# 今天在Firefox上面安装"The Addon Bar"未果,于是转战Google了 # 想说的是http://cn.bing.com/ 简直太好用了 软件名称:Window Resizer 安 ...