懵懂oracle之存储过程3--JOB详解
在前面学习了存储过程的开发、调试之后,我们现在就需要来使用存储过程了。简单的使用,像上篇《懵懂oracle之存储过程2》中提到的存储过程调用,我们可以将写好的存储过程在另一个PL/SQL块亦或是另一个存储过程中调用执行,而很多情况下,我们往往需要定时执行这个存储过程,那么我们就需要使用到Oracle的JOB,让我们的数据库可以定期的执行特定的任务。
下面就让我们来了解下JOB的方方面面:
在Oracle 10g以前,Oracle提供了dbms_job系统包来实现job,到Oracle 10g时,就多出了dbms_scheduler包来实现job,它比dbms_job拥有更强大的功能和更灵活的机制,在本文暂只介绍dbms_job的知识,所用的数据库版本Oracle 11g。
1 初始化
1.1 初始化权限
使用dbms_job包如果遇到权限问题,那么需要使用管理员账号给此用户赋予权限:
grant execute on dbms_job to 用户;
1.2 初始化参数
重点关注job_queue_processes参数,它告诉了数据库最多可创建多少个job进程来运行job,可通过下面语句查询改参数值情况:
select name, value, display_value from v$parameter where name in ('spfile', 'job_queue_processes');
当job_queue_processes参数对应的value为0时,则代表所有创建的job都不会运行,因此我们需将此参数值根据各自需要修改至n(1~1000):
- 当上述语句未查询出spfile参数时,则表示数据库以pfile启动,该文件默认位置为%ORACLE_HOME%\database目录下的init<sid>.ora文件(sid-->数据库实例名)。此时若要修改参数值,则需打开此文件进行增加或修改下行信息,而后重启数据库才能生效:
JOB_QUEUE_PROCESSES=n
当上述语句可查询出spfile参数时,则表示数据库以spfile启动,该文件的位置可从value值中得到。此时若要修改参数值,则可通过在数据库执行下列语句进行修改:
alter system set job_queue_processes=n;
/*
alter system 参数名=值 [scope=应用范围];
scope需知:
scope=both,表示修改会立即生效且会修改spfile文件以确保数据库在重启后也会生效如果(以spfile启动此项为缺省值);
scope=memory,表示修改会立即生效但不会修改spfile文件,因此重启后失效(以pfile启动此项为缺省值,且只可设置这个值);
scope=spfile,表示只修改spfile文件,在重启数据库后才生效(对应静态参数则只可设置此项值,设置其它值会报错:
ORA-02095: specified initialization parameter cannot be modified)。
*/
2 dbms_job包分析(可在数据库中查看此包获取相关信息,暂未分析包内user_export存过的用法)
2.1 内部存过参数汇总
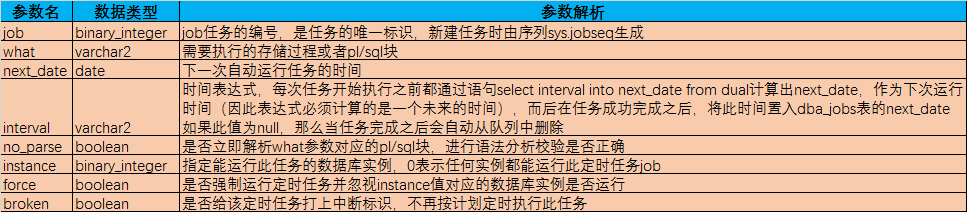
2.2 内部存过详解
create or replace procedure sp_test_hll_170726 AUTHID CURRENT_USER as
v_flag number;
begin
select count(1)
into v_flag
from user_tables
where table_name = 'TEST_TABLE_170726';
if v_flag = 0 then
execute immediate 'create table test_table_170726(id number, create_time date default sysdate)';
end if;
select count(1)
into v_flag
from user_sequences
where sequence_name = 'SEQ_TEST_TABLE_170726_ID';
if v_flag = 0 then
execute immediate 'create sequence seq_test_table_170726_id';
end if;
execute immediate 'insert into test_table_170726(id) values(seq_test_table_170726_id.nextval)';
commit;
end sp_test_hll_170726;
/
新建存过sp_test_hll_170726以作后面测试使用
1) submit:用于新建一个定时任务
- 定义:
procedure submit(job out binary_integer,
what in varchar2,
next_date in date default sysdate,
interval in varchar2 default 'null',
no_parse in boolean default false,
instance in binary_integer default 0,
force in boolean default false); - 范例1:
declare
jobno number;
begin
dbms_job.submit(
jobno,--定义的变量作为submit存过的出参,submit内部调用序列生成此值
'sp_test_hll_170726;' , --job要执行的工作(范例为要执行的存储过程,必须加分号,格式如:存过1;存过2;存过3;……)
sysdate,--设置下次运行时间为当前系统时间,以使job在提交后立马运行(因为之后的系统时间>=此时的'sysdate')
'sysdate+10/(24*60*60)' --设置定时周期为10秒运行一次
);
dbms_output.put_line(jobno);--输出以供查看本次创建的job的编号,或查看dba_jobs/all_jobs/user_jobs视图中最新行亦可
commit;--请记得提交,提交之后才会生效并按计划执行此项定时任务
end;
/ - 范例2(存过sp_hll_test_20170415见《懵懂oracle之存储过程》):
declare
jobno number;
begin
dbms_job.submit(jobno,
'declare
a number;
b date;
c varchar2(20);
d number;
status user_tables.status%type;
e varchar2(200);
begin
sp_hll_test_20170415(a, b, c, d, status, e);
a := 3;
sp_hll_test_20170415(a, to_date(''2017-6-16'', ''yyyy-mm-dd''), ''我是常量C'', d, '''', e);
insert into test_table_170726(id,create_time) values (seq_test_table_170726_id.nextval,to_date(''2017-6-16'', ''yyyy-mm-dd''));
commit;
end;', --job要执行的工作(范例为要执行的PL/SQL块,块内单引号处理成双单引号)
case
when sysdate > trunc(sysdate) +
(11 * 60 * 60 + 11 * 60 + 11) / (24 * 60 * 60) then
trunc(sysdate + 1) +
(11 * 60 * 60 + 11 * 60 + 11) / (24 * 60 * 60)
else
trunc(sysdate) + (11 * 60 * 60 + 11 * 60 + 11) / (24 * 60 * 60)
end, --设置下次运行时间为接下来最近的一次11点11分11秒
null --设置为单次运行,一般用于需单次运转的耗时较长的任务,在成功完成后job记录会自动删除掉
);
dbms_output.put_line(jobno);
commit;
end;
/ - 备注:
1. what参数,用于定时任务执行的具体内容:
格式 ==> 存过1;存过2;存过3;…… | '处理过单引号的PL/SQL块'
建议使用后者,如果是前者情况,也用begin end进行包裹,如 begin 存过1;存过2;存过3;…… end; ,否则少数情况下会出现一些莫名其妙的问题……暂无实例。
2. interval参数,用于设置定时任务时间间隔:
格式 ==> null | '处理过单引号的时间表达式'
设置为null表示单次运行,在成功完成后会从JOB任务队列中删除此JOB。
时间表达式:通过 select 时间表达式 from dual; 可得到一个未来时间点,每次任务开始执行之前都获取这个未来时间点作为下次运行任务的时间,然后在任务执行完成后,才会把此时间更新至JOB任务队列的next_date字段中,等待下次sysdate >= next_date时再次执行此任务。之所以“>=”而不是“=”,是因为存在后面几种情况:
-1-创建定时任务时,next_date就小于系统时间;
-2-单次任务执行的时间超过任务开始执行时计算出的next_date,以致next_date小于任务执行完成后的系统时间,此时任务会立马进行再一轮的执行;
-3-参数job_queue_processes的限制或者数据库性能的限制或数据库关闭等,导致next_date=当时的sysdate时,任务无法按时开始执行。
由于上面第三种情况的存在,因此对于interval参数设置大致可分两种情况:
-1 时间定隔循环,不考虑时间点的精确性,则只需使用sysdate即可,例如 interval = 'sysdate + 数值' ,数值(1=1天,1/24=1小时,1/(24*60)=1分钟,1/(24*60*60)=1秒钟),数值为1时实现每隔一天执行一次这样的简单循环。
-2 时间定点循环,需确保每次执行的时间点精确性,则一般需配合trunc函数进行处理,例如 interval = 'trunc(sysdate,''dd'') + 数值' ,数值为1/24时实现每天1点执行此任务这样精确的循环,以消除每次执行定时任务时的时间飘移的积累,以致时间点越来越不正确,同时由他人手工调用dbms_job.run对某定时任务进行手动执行,导致取手动运行任务时的系统时间作为sysdate计算下次的时间会产生更大的时间差异,也会使执行的时间和当初计划的时间不符的现象出现,因此用trunc等函数处理来保证时间点的精确性。
常用函数trunc、numtoyminterval、numtoyminterval、add_months、next_day、last_day介绍:select sysdate, trunc(sysdate), trunc(sysdate,'MON') from dual;
/*
trunc(date, [format]):
format可取值汇总(不区分大小写):
本世纪第一天 ==> CC,SCC
本年第一天 ==> SYYYY, YYYY, YEAR, SYEAR, YYY, YY, Y
本ISO年第一天(每个星期从星期一开始,每年的第一个星期包含当年的第一个星期四(并且总是包含1月4日)) ==> IYYY, IY, I
本季度第一天 ==> Q
本月第一天 ==> MONTH, MON, MM, RM
本周第一天 ==> WW(按年度1月1日的第一天为每周第一天),
IW(星期一为每周第一天),
W(按月份1日的第一天作为每周第一天),
DAY, DY, D(星期日为每周第一天)
本日(零点零分)(缺省值) ==> DDD, DD, J
本小时(零分零秒) ==> HH, HH12, HH24
本分钟(零秒) ==> MI
*/ select sysdate + numtoyminterval(-5, 'year') 五年前,
sysdate + numtodsinterval(-10, 'day') 十天前,
sysdate + numtodsinterval(-2, 'hour') 两小时前,
sysdate + numtodsinterval(1, 'minute') 一分钟前,
sysdate + numtodsinterval(10, 'second') 十秒后,
sysdate + numtoyminterval(3, 'month') 三月后
from dual;
/*
numtodsinterval(num, format):
num可取整数(正整数表示加,负整数表示减);
format可取值汇总(不区分大小写):DAY,HOUR,MINUTE,SECOND numtoyminterval(num, format):
num可取整数(正整数表示加,负整数表示减);
format可取值汇总(不区分大小写):YEAR,MONTH
*/ select sysdate 现在, add_months(sysdate, -12) 一年前, add_months(sysdate, 3) 三月后 from dual;
/*
add_months(date, num):
date为具体时间,经add_months处理不会变动时分秒,日期年月进行加减;
num可取整数(正整数表示加,负整数表示减);
*/ select next_day(sysdate,
case value
when 'SIMPLIFIED CHINESE' then
'星期六'
else
'SAT'
end) 下周一此时此分此秒, next_day(sysdate, 1) 下周日此时此分此秒
from v$parameter
where name = 'nls_date_language';
/*
next_day(date, format) :
date为具体时间,经next_day处理不会变动时分秒,日期被处理至下个周一~周日;
format可取值汇总(不区分大小写):
星期一~星期日(对应字符集NLS_DATE_LANGUAGE = SIMPLIFIED CHINESE)
Monday~Sunday 或者 Mon~Sun(对应字符集NLS_DATE_LANGUAGE = AMERICAN)
1~7(1为周日)
*/ select to_date('2017-2-1 11:11:11', 'yyyy-mm-dd hh24:mi:ss') "2017/2/1 11:11:11",
last_day(to_date('2017-2-1 11:11:11', 'yyyy-mm-dd hh24:mi:ss')) "17年2月末此时此分此秒"
from dual;
/*
last_day(date) :
date为具体时间,经last_day处理不会变动时分秒,日期被处理至月底最后一天
*/3. instance、force参数,用于设置定时任务于数据库实例的关联性:
在Oracle RAC环境下,多个数据库实例并发使用同一个数据库,是Oracle9i新版数据库中采用的一项新技术,解决了传统数据库应用中面临的一个重要问题:高性能、高可伸缩性与低价格之间的矛盾!但是在涉及到我们的定时任务时,如果是RAC环境,它是怎么运行的呢?有多台机器这个定时任务这次到底会在哪个机器上运行呢?instance参数就可配置指定机器对应的数据库实例,如不修改默认此值为0,表示就是所有数据库实例都可运行此项定时任务,每次这个任务执行时就可能在a机器,也可能在b机器,一般我们也是不指定此值的。当遇到需要指定此值时,需关注下面查询的情况,取instance_name作为instance参数值。select inst_id,instance_number,instance_name,host_name,
utl_inaddr.get_host_address(host_name) public_ip,status,version
from gv$instance;同时force参数在设置为true时,也能达到和instance=0时一样的效果,解除JOB执行和数据库实例的关联性,它的默认值是false,表示按照instance值的情况进行判断数据库实例的关联性。
4. what、interval参数都需注意内部单引号处理成双单引号,可用 select 参数值 from dual; 查询得到实际对应的存过或PL/SQL块或时间表达式,来判断是否设置正确。
2) isubmit:用于新建一个定时任务同时指定JOB编号
- 定义:
procedure isubmit(job in binary_integer,
what in varchar2,
next_date in date,
interval in varchar2 default 'null',
no_parse in boolean default false); - 范例:
begin
dbms_job.isubmit(23, --指定job编号,不可用已有job的编号,否则报违反唯一约束的异常
'declare
a number;
b date;
c varchar2(20);
d number;
status user_tables.status%type;
e varchar2(200);
begin
sp_hll_test_20170415(a, b, c, d, status, e);
a := 3;
sp_hll_test_20170415(a, to_date(''2017-6-16'', ''yyyy-mm-dd''), ''我是常量C'', d, '''', e);
insert into test_table_170726(id,create_time) values (seq_test_table_170726_id.nextval,to_date(''2017-6-16'', ''yyyy-mm-dd''));
commit;
end;',
sysdate,
'trunc(sysdate + numtoyminterval(1,''year''),''yyyy'')+1/24' --每年一月一号一点执行
);
commit;
end;
/ - 备注:
除job为入参需指定外,其它使用情况与submit相同,指定job编号时,不可用已存在job的编号,否则导致异常 ORA-00001: 违反唯一约束条件 (SYS.I_JOB_JOB) 。
3) remove:用于从JOB任务队列中移除一个JOB(不会中断仍在运行的JOB)
- 定义:
procedure remove(job in binary_integer);
- 范例:
begin
dbms_job.remove(23);
commit;
end;
/ - 备注:
移除需移除已存在JOB,否则导致异常 ORA-23421: 作业编号111在作业队列中不是一个作业 。
4) what:用于修改what参数值
- 定义:
procedure what(job in binary_integer, what in varchar2);
- 范例:
declare
jobno number;
begin
select job into jobno from user_jobs where what like '%sp_test_hll_170726%';
dbms_job.what(jobno, 'begin sp_test_hll_170726; end;'); --修改成pl/sql块形式
commit;
end;
/
5) next_date:用于修改next_date参数值
- 定义:
procedure next_date(job in binary_integer, next_date in date);
- 范例:
declare
jobno number;
begin
select job into jobno from user_jobs where what like '%sp_test_hll_170726%';
dbms_job.next_date(jobno, trunc(sysdate + 1)); --修改最近一次待执行的时间至明天凌晨
commit;
end;
/
6) interval:用于修改interval参数值
- 定义:
procedure interval(job in binary_integer, interval in varchar2);
- 范例:
declare
jobno number;
begin
select job into jobno from user_jobs where what like '%sp_test_hll_170726%';
dbms_job.interval(jobno, 'sysdate + 1'); --修改为每隔一天运行一次
commit;
end;
/
7) instance:用于修改instance、force参数值
- 定义:
procedure instance(job in binary_integer,
instance in binary_integer,
force in boolean default false); - 范例:
declare
jobno number;
begin
select job into jobno from user_jobs where what like '%sp_test_hll_170726%';
dbms_job.instance(jobno, 1); --修改为数据库实例1才能运行此定时任务
commit;
end;
/ - 备注:
请勿修改已在运行的JOB的数据库实例,根据网络搜索得知:job会不再运行,并出现等待事件:enq: TX - row lock contention,执行的sql是 update sys.job$ set this_date=: where job=: ,也就是在更新sys的sys.job$表,最后只能杀掉此会话,才消除此等待事件。
一般情况下,建立不要指定JOB在特定实例运行,通常都默认为0。
下面change也需注意此处备注。
8) change:用于修改what、next_date、interval、instance、force参数值
- 定义:
procedure change(job in binary_integer,
what in varchar2,
next_date in date,
interval in varchar2,
instance in binary_integer default null,
force in boolean default false); - 范例:
declare
jobno number;
begin
select job into jobno from user_jobs where what like '%sp_test_hll_170726%';
dbms_job.change(jobno,
'begin sp_test_hll_170726; end;',
sysdate,
'sysdate + 1/24');--实现多参数修改
commit;
end;
/
9) broken:用于给定时任务添加或去除中断标识,将任务挂起或取消挂起(不会中断仍在运行的JOB)
- 定义:
procedure broken(job in binary_integer,
broken in boolean,
next_date in date default sysdate); - 范例:
declare
jobno number;
begin
select job into jobno from user_jobs where what like '%sp_test_hll_170726%';
dbms_job.broken(jobno, true);--挂起
commit;
end;
/ - 备注:
挂起时,会修改JOB任务队列中字段broken='Y',next_date='4000/1/1',next_sec='00:00:00',只要broken='Y',就算next_date<sysdate,此任务也不会执行;
取消挂起时,会修改broken='N',next_date与next_sec安照next_date参数值进行调整,任务查询开始按计划执行。
10) run:用于立即执行此定时任务(被broken挂起的存过也会取消挂起并运行)
- 定义:
procedure run(job in binary_integer, force in boolean default false);
- 范例:
declare
jobno number;
begin
select job into jobno from user_jobs where what like '%sp_test_hll_170726%';
dbms_job.run(jobno);--立即运行
commit;
end;
/ - 备注:
当任务挂起时,会修改broken='N';
当数据库实例不符时也可通过修改force=true以强制在当前数据库实例运行,确保run能一定运行此项任务。
3 JOB任务队列查询处理汇总
3.1 表汇总(SYS.JOB$、DBA_JOBS、ALL_JOBS、USER_JOBS、DBA_JOBS_RUNNING)
在通过上面介绍的dbms_job包对JOB进行的处理,实际上处理的是数据库的任务队列表SYS.JOB$,我们可以通过下面语句查看该表情况:
select t.job, t.lowner, t.powner, t.cowner, t.last_date, t.this_date, t.next_date, t.total, t.interval#, t.failures, t.flag, t.what,
t.nlsenv, t.env, t.charenv, t.field1, t.scheduler_flags, t.xid
/*, t.cur_ses_label, t.clearance_hi, t.clearance_lo
不能查询这三个字段,会报异常ORA-00932: 数据类型不一致: 应为 NUMBER, 但却获得 LABEL
它们的数据类型为MLSLABEL,在TRUSTED ORACLE中用来保存可变长度二进制标签。
*/
from sys.job$ t;
但是它的数据长得不好看,Oracle提供了我们两个视图(DBA_JOBS、USER_JOBS)可以查看:
create or replace view sys.dba_jobs as
select JOB, lowner LOG_USER, powner PRIV_USER, cowner SCHEMA_USER,
LAST_DATE, substr(to_char(last_date,'HH24:MI:SS'),1,8) LAST_SEC,
THIS_DATE, substr(to_char(this_date,'HH24:MI:SS'),1,8) THIS_SEC,
NEXT_DATE, substr(to_char(next_date,'HH24:MI:SS'),1,8) NEXT_SEC,
(total+(sysdate-nvl(this_date,sysdate)))*86400 TOTAL_TIME,
decode(mod(FLAG,2),1,'Y',0,'N','?') BROKEN,
INTERVAL# interval, FAILURES, WHAT,
nlsenv NLS_ENV, env MISC_ENV, j.field1 INSTANCE
from sys.job$ j
where BITAND(j.scheduler_flags, 2) IS NULL OR
BITAND(j.scheduler_flags, 2) = 0 /* don't show jobs with drop flag */;
comment on table SYS.DBA_JOBS is 'All jobs in the database';
comment on column SYS.DBA_JOBS.JOB is 'Identifier of job. Neither import/export nor repeated executions change it.';
comment on column SYS.DBA_JOBS.LOG_USER is 'USER who was logged in when the job was submitted';
comment on column SYS.DBA_JOBS.PRIV_USER is 'USER whose default privileges apply to this job';
comment on column SYS.DBA_JOBS.SCHEMA_USER is 'select * from bar means select * from schema_user.bar ';
comment on column SYS.DBA_JOBS.LAST_DATE is 'Date that this job last successfully executed';
comment on column SYS.DBA_JOBS.LAST_SEC is 'Same as LAST_DATE. This is when the last successful execution started.';
comment on column SYS.DBA_JOBS.THIS_DATE is 'Date that this job started executing (usually null if not executing)';
comment on column SYS.DBA_JOBS.THIS_SEC is 'Same as THIS_DATE. This is when the last successful execution started.';
comment on column SYS.DBA_JOBS.NEXT_DATE is 'Date that this job will next be executed';
comment on column SYS.DBA_JOBS.NEXT_SEC is 'Same as NEXT_DATE. The job becomes due for execution at this time.';
comment on column SYS.DBA_JOBS.TOTAL_TIME is 'Total wallclock time spent by the system on this job, in seconds';
comment on column SYS.DBA_JOBS.BROKEN is 'If Y, no attempt is being made to run this job. See dbms_jobq.broken(job).';
comment on column SYS.DBA_JOBS.INTERVAL is 'A date function, evaluated at the start of execution, becomes next NEXT_DATE';
comment on column SYS.DBA_JOBS.FAILURES is 'How many times has this job started and failed since its last success?';
comment on column SYS.DBA_JOBS.WHAT is 'Body of the anonymous PL/SQL block that this job executes';
comment on column SYS.DBA_JOBS.NLS_ENV is 'alter session parameters describing the NLS environment of the job';
comment on column SYS.DBA_JOBS.MISC_ENV is 'a versioned raw maintained by the kernel, for other session parameters';
comment on column SYS.DBA_JOBS.INSTANCE is 'Instance number restricted to run the job';
DBA_JOBS,所有用户拥有的JOB
create or replace view sys.user_jobs as
select j."JOB",j."LOG_USER",j."PRIV_USER",j."SCHEMA_USER",j."LAST_DATE",j."LAST_SEC",j."THIS_DATE",j."THIS_SEC",j."NEXT_DATE",j."NEXT_SEC",j."TOTAL_TIME",j."BROKEN",j."INTERVAL",j."FAILURES",j."WHAT",j."NLS_ENV",j."MISC_ENV",j."INSTANCE" from dba_jobs j, sys.user$ u where
j.priv_user = u.name
and u.user# = USERENV('SCHEMAID');
comment on table SYS.USER_JOBS is 'All jobs owned by this user';
comment on column SYS.USER_JOBS.JOB is 'Identifier of job. Neither import/export nor repeated executions change it.';
comment on column SYS.USER_JOBS.LOG_USER is 'USER who was logged in when the job was submitted';
comment on column SYS.USER_JOBS.PRIV_USER is 'USER whose default privileges apply to this job';
comment on column SYS.USER_JOBS.SCHEMA_USER is 'select * from bar means select * from schema_user.bar ';
comment on column SYS.USER_JOBS.LAST_DATE is 'Date that this job last successfully executed';
comment on column SYS.USER_JOBS.LAST_SEC is 'Same as LAST_DATE. This is when the last successful execution started.';
comment on column SYS.USER_JOBS.THIS_DATE is 'Date that this job started executing (usually null if not executing)';
comment on column SYS.USER_JOBS.THIS_SEC is 'Same as THIS_DATE. This is when the last successful execution started.';
comment on column SYS.USER_JOBS.NEXT_DATE is 'Date that this job will next be executed';
comment on column SYS.USER_JOBS.NEXT_SEC is 'Same as NEXT_DATE. The job becomes due for execution at this time.';
comment on column SYS.USER_JOBS.TOTAL_TIME is 'Total wallclock time spent by the system on this job, in seconds';
comment on column SYS.USER_JOBS.BROKEN is 'If Y, no attempt is being made to run this job. See dbms_jobq.broken(job).';
comment on column SYS.USER_JOBS.INTERVAL is 'A date function, evaluated at the start of execution, becomes next NEXT_DATE';
comment on column SYS.USER_JOBS.FAILURES is 'How many times has this job started and failed since its last success?';
comment on column SYS.USER_JOBS.WHAT is 'Body of the anonymous PL/SQL block that this job executes';
comment on column SYS.USER_JOBS.NLS_ENV is 'alter session parameters describing the NLS environment of the job';
comment on column SYS.USER_JOBS.MISC_ENV is 'a versioned raw maintained by the kernel, for other session parameters';
comment on column SYS.USER_JOBS.INSTANCE is 'Instance number restricted to run the job';
USER_JOBS,当前用户拥有的JOB
同时通过下面语句我们可以知道,还有一个同义词ALL_JOBS:
select *
from all_objects t
where t.object_name in ('DBA_JOBS', 'ALL_JOBS', 'USER_JOBS');
select *
from sys.all_synonyms
where synonym_name in ('DBA_JOBS', 'ALL_JOBS', 'USER_JOBS');
ALL_JOBS,USER_JOBS的同义词
我们通过下面语句都能查询我们建立好的JOB的信息:
select * from dba_jobs;
select * from all_jobs;
select * from user_jobs;
DBA_JOBS/ALL_JOBS/USER_JOBS各字段的含义如下:
字段(列) 数据类型 描述
JOB NUMBER 任务的唯一标示号
【Identifier of job. Neither import/export nor repeated executions change it.】
LOG_USER VARCHAR2(30) 提交任务时登录的用户
【USER who was logged in when the job was submitted】
PRIV_USER VARCHAR2(30) 任务默认权限对应的用户
【USER whose default privileges apply to this job】
SCHEMA_USER VARCHAR2(30) 对任务作语法分析的用户模式(查询bar表代表查询schema_user.bar表)
【select * from bar means select * from schema_user.bar】
LAST_DATE DATE 最后一次成功运行任务的时间
【Date that this job last successfully executed】
LAST_SEC VARCHAR2(32) 长度为8的HH24:MI:SS格式的LAST_DATE
【Same as LAST_DATE. This is when the last successful execution started.】
THIS_DATE DATE 正在运行任务的开始时间,如果没有运行任务则为null
【Date that this job started executing (usually null if not executing)】
THIS_SEC VARCHAR2(32) 长度为8的HH24:MI:SS格式的THIS_DATE
【Same as THIS_DATE. This is when the last successful execution started.】
NEXT_DATE DATE 下一次定时运行任务的时间
【Date that this job will next be executed】
NEXT_SEC VARCHAR2(32) 长度为8的HH24:MI:SS格式的NEXT_DATE
【Same as NEXT_DATE. The job becomes due for execution at this time.】
TOTAL_TIME NUMBER 数据库用于执行此任务的总秒数统计
【Total wallclock time spent by the system on this job, in seconds】
BROKEN VARCHAR2(1) 中断标识,Y表示任务中断,不再尝试执行此任务
【If Y,no attempt is being made to run this job. See dbms_jobq.broken(job).】
INTERVAL VARCHAR2(200) 用于计算下此运行时间的时间表达式
【A date function, evaluated at the start of execution, becomes next NEXT_DATE】
FAILURES NUMBER 自最后一次成功之后任务运行失败的总次数
【How many times has this job started and failed since its last success?】
WHAT VARCHAR2(4000) 任务执行的匿名PL/SQL块
【Body of the anonymous PL/SQL block that this job executes】
NLS_ENV VARCHAR2(4000) 任务运行的NLS会话设置
【alter session parameters describing the NLS environment of the job】
MISC_ENV RAW(32) 任务运行的其他一些会话参数
【a versioned raw maintained by the kernel, for other session parameters】
INSTANCE NUMBER 任务执行时限制关联的数据库实例
【Instance number restricted to run the job】
同时,Oracle还提供了DBA_JOBS_RUNNING视图供我们查询正在运行的任务:
create or replace view sys.dba_jobs_running as
select v.SID, v.id2 JOB, j.FAILURES,
LAST_DATE, substr(to_char(last_date,'HH24:MI:SS'),1,8) LAST_SEC,
THIS_DATE, substr(to_char(this_date,'HH24:MI:SS'),1,8) THIS_SEC,
j.field1 INSTANCE
from sys.job$ j, v$lock v
where v.type = 'JQ' and j.job (+)= v.id2;
comment on table SYS.DBA_JOBS_RUNNING is 'All jobs in the database which are currently running, join v$lock and job$';
comment on column SYS.DBA_JOBS_RUNNING.SID is 'Identifier of process which is executing the job. See v$lock.';
comment on column SYS.DBA_JOBS_RUNNING.JOB is 'Identifier of job. This job is currently executing.';
comment on column SYS.DBA_JOBS_RUNNING.FAILURES is 'How many times has this job started and failed since its last success?';
comment on column SYS.DBA_JOBS_RUNNING.LAST_DATE is 'Date that this job last successfully executed';
comment on column SYS.DBA_JOBS_RUNNING.LAST_SEC is 'Same as LAST_DATE. This is when the last successful execution started.';
comment on column SYS.DBA_JOBS_RUNNING.THIS_DATE is 'Date that this job started executing (usually null if not executing)';
comment on column SYS.DBA_JOBS_RUNNING.THIS_SEC is 'Same as THIS_DATE. This is when the last successful execution started.';
comment on column SYS.DBA_JOBS_RUNNING.INSTANCE is 'The instance number restricted to run the job';
DBA_JOBS_RUNNING,数据库中所有正在运行的JOB,关联v$lock和job$表
通过下面语句可简单查询该表情况:
select * from dba_jobs_running;
DBA_JOBS_RUNNING各字段含义如下:
字段(列) 数据类型 描述
SID NUMBER 正在运行任务的会话ID
【Identifier of process which is executing the job. See v$lock. 】
JOB NUMBER 正在运行任务的唯一标示号
【Identifier of job. This job is currently executing.】
FAILURES NUMBER 自最后一次成功之后任务运行失败的总次数
【How many times has this job started and failed since its last success?】
LAST_DATE DATE 最后一次成功运行任务的时间
【Date that this job last successfully executed】
LAST_SEC VARCHAR2(32) 长度为8的HH24:MI:SS格式的LAST_DATE
【Same as LAST_DATE. This is when the last successful execution started.】
THIS_DATE DATE 正在运行任务的开始时间,如果没有运行任务则为null
【Date that this job started executing (usually null if not executing)】
THIS_SEC VARCHAR2(32) 长度为8的HH24:MI:SS格式的THIS_DATE
【Same as THIS_DATE. This is when the last successful execution started.】
INSTANCE NUMBER 任务执行时限制关联的数据库实例
【Instance number restricted to run the job
3.2 JOB的失败重试
当JOB实现失败时,数据库会自动安排重新执行,此时JOB执行时间按下面情况来定:
1) 如果sysdate>=next_date,则直接执行;
2) 第i次失败,等待2i分钟后开始第i+1次数据库自动安排的重新执行,当2i>分钟时,时间固定为分钟;
3) 重试次数达次时,JOB不再自动执行(用户还是可手动执行再失败的),标记中断标识,broken='Y',next_date='4000/1/1',next_sec='00:00:00'。
3.3 停止正在运行的JOB
由于remove、broken都只是影响任务后续的执行情况,并不会对正在运行的任务造成影响,而有些情况下,由于存储过程的问题或者数据之间的影响等各种原因导致JOB执行异常,我们需要终止正在运行的异常JOB;也可能是JOB执行时间过长,人为需要停止正在运行的JOB。在这个时候我们需要按下面步骤进行处理:
/*** 第一步:查询JOB情况得到需要停止的JOB的编号 ***/
select * from user_jobs;
select * from dba_jobs_running; /*** 第二步:将需要停止的JOB标记中断,以避免停止后又运行 ***/
begin
dbms_job.broken(job编号, true);
commit;
end;
/ /*** 第三步:查询JOB运行情况,并选择适当语句杀会话,甚至杀进程(谨慎操作) ***/
select /*b.sid, -- session的id
c.serial#, -- session的序列号
d.spid, -- 操作系统进程ID*/
b.job, -- JOB编号
a.what, -- 任务内容
b.failures, -- 失败次数
b.this_date, -- 开始时间
floor(sysdate - b.this_date) || '天' ||
to_char(trunc(sysdate, 'dd') + (sysdate - b.this_date), 'hh24:mi:ss') this_total, -- 当前耗时
(select f.sql_fulltext
from v$locked_object e, v$sql f
where e.session_id = c.sid
and f.hash_value = c.sql_hash_value
and rownum = 1) sql_fulltext, -- 如果锁对象,则获取当前sql
c.inst_id, -- 数据库实例ID
c.status, --会话状态
'alter system kill session ''' || b.sid || ',' || c.serial# ||
''' immediate;' 普通环境杀会话, -- session级杀会话
'alter system kill session ''' || b.sid || ',' || c.serial# || ',@' ||
c.inst_id || ''' immediate;' RAC环境杀会话, -- RAC环境session级杀会话
/*
kill session语句并不实际杀死会话,只相当于让会话自我清除,在某些情况下,例如等待远程数据库应答或
回滚当前事务时,都会等待这些操作完成,这时就将会话状态标记为"marked for kill",数据库会尽快将它杀掉,
如果加上immediate,那么则会要求将控制权立即返回给当前会话
*/
'alter system disconnect session ''' || b.sid || ',' || c.serial# ||
''' post_transaction或immediate;' 数据库杀进程,
'alter system disconnect session ''' || b.sid || ',' || c.serial# || ',@' ||
c.inst_id || ''' post_transaction或immediate;' 数据库RAC环境杀进程,
/*
disconnect是在数据库中从操作系统层面清除服务器进程,
post_transaction表示清除前需等待正在进行的事务完成,
而immediate则表示立即清除并回滚正在进行的事务,
两者必须有其一,都有时,post_transaction优先级高,忽视immediate子句。
用disconnect我们就不用切换到操作系统层面用下面语句去清除进程了
*/
g.host_name || '==>' || utl_inaddr.get_host_address(g.host_name) "机器==>IP", -- 机器及IP
'orakill ' || g.instance_name || ' ' || d.spid "Windows杀进程",
'kill ' || d.spid "UnixORLinux杀进程1",
'kill -9 ' || d.spid "UnixORLinux杀进程2" -- 用1杀不掉就加-9
/*
不管是在数据库用disconnect还是上面到操作系统上面敲kill命令,都是杀的进程,
杀掉操作系统进程是一件危险的事情,千万不得误杀,请务必谨慎操作,严格确认。
*/
from user_jobs a,
dba_jobs_running b,
gv$session c,
gv$process d,
gv$instance g
where a.job = b.job
and b.sid = c.sid
and c.paddr = d.addr
and g.inst_id = c.inst_id; /*** 第四步:恢复JOB,使其继续执行 ***/
-- 如果JOB未修复好,可不执行此步操作
begin
dbms_job.broken(job编号, false);
-- dbms_job.broken(job编号, false, 可加个参数修改接来下运行的时间原默认为sysdate);
commit;
end;
/
作者:滚雪球俱乐部-何理利
出处: http://www.cnblogs.com/snowballed/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出 原文链接。
如有疑问, 可邮件(he.lili1@ztesoft.com)咨询。
懵懂oracle之存储过程3--JOB详解的更多相关文章
- 懵懂oracle之存储过程
作为一个oracle界和厨师界的生手,笔者想给大家分享讨论下存储过程的知识,因为在我接触的通信行业中,存储过程的使用还是占据了一小块的地位. 存储过程是什么?不得不拿下百度词条的解释来:"存 ...
- oracle中的dual表详解
oracle中的dual表详解 1.DUAL表的用途 Dual 是 Oracle中的一个实际存在的表,任何用户均可读取,常用在没有目标表的Select语句块中 --查看当前连接用户 SQL> s ...
- oracle数据库exp/imp命令详解
转自http://wenku.baidu.com/link?url=uD_egkkh7JtUYJaRV8YM6K8CLBT6gPJS4UlSy5WKhz46D9bnychTPdgJGd7y6UxYtB ...
- oracle正则表达式regexp_like的用法详解
oracle正则表达式regexp_like的用法详解 /*ORACLE中的支持正则表达式的函数主要有下面四个:1,REGEXP_LIKE :与LIKE的功能相似2,REGEXP_INSTR :与IN ...
- 懵懂oracle之存储过程2
上篇<懵懂oracle之存储过程>已经给大家介绍了很多关于开发存储过程相关的基础知识,笔者尽最大的努力总结了所有接触到的关于存储过程的知识,分享给大家和大家一起学习进步.本篇文章既是完成上 ...
- Oracle中的substr()函数 详解及应用
注:本文来源于<Oracle中的substr()函数 详解及应用> 1)substr函数格式 (俗称:字符截取函数) 格式1: substr(string string, int a, ...
- Oracle 查询优化的基本准则详解
注:报文来源:想跌破记忆寻找你 < Oracle 查询优化的基本准则详解 > Oracle 查询优化的基本准则详解 1:在进行多表关联时,多用 Where 语句把单个表的结果集最小化, ...
- 【转载】MyBatis JdbcType 与Oracle、MySql数据类型对应关系详解
[原文链接]:MyBatis JdbcType 与Oracle.MySql数据类型对应关系详解 1. Mybatis JdbcType与Oracle.MySql数据类型对应列表 2. Mybatis ...
- Oracle排名函数(Rank)实例详解
这篇文章主要介绍了Oracle排名函数(Rank)实例详解,需要的朋友可以参考下 --已知:两种排名方式(分区和不分区):使用和不使用partition --两种计算方式(连续,不连续),对应 ...
随机推荐
- js中替换字符串(replace方法最简单的应用)
replace方法的语法是:stringObj.replace(rgExp, replaceText) 其中stringObj是字符串(string),reExp可以是正则表达式对象(RegExp)也 ...
- spring4 之 helloworld
1.从官网下载相关JAR包 spring-framework-4.2.1.RELEASE-dist(下载地址:http://maven.springframework.org/release/org/ ...
- sharepoint rest api 创建文档库 文件夹
function createFolder() { var requestHeaders = { "Accept": "application/json;odata=ve ...
- 1000行代码徒手写正则表达式引擎【1】--JAVA中正则表达式的使用
简介: 本文是系列博客的第一篇,主要讲解和分析正则表达式规则以及JAVA中原生正则表达式引擎的使用.在后续的文章中会涉及基于NFA的正则表达式引擎内部的工作原理,并在此基础上用1000行左右的JAVA ...
- iOS10 相关的隐私设置,
最近下载了几个demo,总是一运行就崩,看了下崩溃日志,有几个是因为没在plist里设置因此权限,而现在iOS 10 开始对隐私权限更加严格, 如需使用隐私权限需要在工程的info.plist文件中声 ...
- Pycharm创建的virtualenv环境缺失pip.exe的问题(Windows系统)
Windows环境: 1. Python安装在d:\Python\Python35下, Python新版本安装时默认会勾选pip功能 2. PyCharm的Settings中Create Virtua ...
- 【LeetCode】122. Best Time to Buy and Sell Stock II
题目: Say you have an array for which the ith element is the price of a given stock on day i. Design a ...
- 【Android Developers Training】 102. 序言:让你的应用获知地点
注:本文翻译自Google官方的Android Developers Training文档,译者技术一般,由于喜爱安卓而产生了翻译的念头,纯属个人兴趣爱好. 原文链接:http://developer ...
- 6.javaweb之respose对象
1.respose的生成的outer对象要优先于内置的out对象输出 response.setContentType("text/html;charaset=utf-8");//设 ...
- Hugo快速搭建Blog
以往我们搭建blog要么学习一个编程语言+Web开发框架,要么使用现成的blog系统(如WordPress).其实我们还可以使用Hugo.Hugo是由Go语言实现的静态网站生成器,它不需要数据库,所以 ...